分布式项目-谷粒商城。
分布式项目
一,分布图


二,环境搭建
1.安装linux
2.安装docker
1 卸载系统之前的docker
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
2 设置存储库
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
3 安装DOCKER引擎
sudo yum install docker-ce docker-ce-cli containerd.io
4 启动Docker.
sudo systemctl start docker
5 配置镜像加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://chqac97z.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
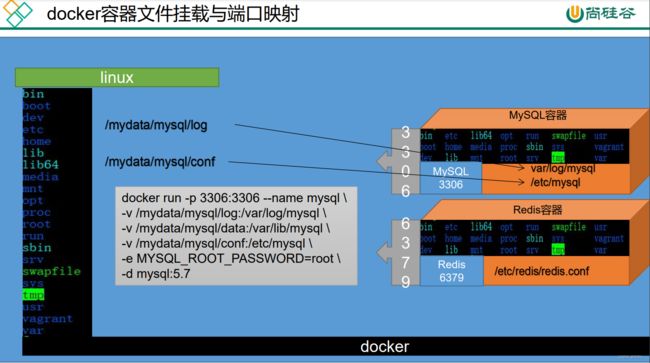
3.安装MySQL
1 拉去mysql镜像
sudo docker pull mysql:8.0
2 启动mysql容器
--name指定容器名字 -v目录挂载 -p指定端口映射 -e设置mysql参数 -d后台运行
docker run -d -p 3306:3306 --privileged=true -v /zzyyuse/mysql/log:/var/log/mysql -v /zzyyuse/mysql/data:/var/lib/mysql -v /zzyyuse/mysql/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 --name mysql mysql:5.7
3 使用su - root(切换为root,这样就不用每次都sudo来赐予了)
su - root
4 进入mysql容器
docker exec -it 容器名称|容器id bin/bash
4.安装redis
1 在docker hub搜索redis镜像
docker search redis
2 拉取redis镜像到本地
docker pull redis:6.0.10
3 修改需要自定义的配置(docker-redis默认没有配置文件,
自己在宿主机建立后挂载映射)
创建并修改/usr/local/redis/redis.conf
bind 0.0.0.0 开启远程权限
appendonly yes 开启aof持久化
4 启动redis服务运行容器
docker run -p 6379:6379 --name redis --privileged=true -v /app/redis/redis.conf:/etc/redis/redis.conf -v /app/redis/data:/data -d redis:6.0.8 redis-server /etc/redis/redis.conf
解释: -v /usr/local/redis/data:/data # 将数据目录挂在到本地保证数据安全
-v /root/redis/redis.conf:/usr/local/etc/redis/redis.conf # 将配置文件挂在到本地修改方便
5 直接进去redis客户端。
docker exec -it redis redis-cli
5.Maven
在maven配置文件配置
配置阿里云镜像
<mirrors>
<mirror>
<id>nexus-aliyunid>
<mirrorOf>centralmirrorOf>
<name>Nexus aliyunname>
<url>http://maven.aliyun.com/nexus/content/groups/publicurl>
mirror>
mirrors>
配置 jdk 1.8 编译项目
<profiles>
<profile>
<id>jdk-1.8id>
<activation>
<activeByDefault>trueactiveByDefault>
<jdk>1.8jdk>
activation>
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<maven.compiler.compilerVersion>1.8maven.compiler.compilerVersion>
properties>
profile>
profiles>
6.安装开发插件(可选-方便开发)
vscoded的插件
Auto Close Tag
Auto Rename Tag
Chinese
ESlint
HTML CSS Support
HTML Snippets
JavaScript (ES6) code snippets
Live Server
open in brower
Vetur
idea
lombok、mybatisx
7.安装git
配置用户名
git config --global user.name "username" //(名字,随意写)
配置邮箱
git config --global user.email "[email protected]" // 注册账号时使用的邮箱
配置ssh免密登录
ssh-keygen -t rsa -C "[email protected]"
三次回车后生成了密钥,也可以查看密钥
cat ~/.ssh/id_rsa.pub
浏览器登录码云后,个人头像上点设置、然后点ssh公钥、随便填个标题,然后赋值
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC6MWhGXSKdRxr1mGPZysDrcwABMTrxc8Va2IWZyIMMRHH9Qn/wy3PN2I9144UUqg65W0CDE/thxbOdn78MygFFsIG4j0wdT9sdjmSfzQikLHFsJ02yr58V6J2zwXcW9AhIlaGr+XIlGKDUy5mXb4OF+6UMXM6HKF7rY9FYh9wL6bun9f1jV4Ydlxftb/xtV8oQXXNJbI6OoqkogPKBYcNdWzMbjJdmbq2bSQugGaPVnHEqAD74Qgkw1G7SIDTXnY55gBlFPVzjLWUu74OWFCx4pFHH6LRZOCLlMaJ9haTwT2DB/sFzOG/Js+cEExx/arJ2rvvdmTMwlv/T+6xhrMS3 [email protected]
测试
ssh -T [email protected]
测试成功
Hi unique_perfect! You’ve successfully authenticated, but GITEE.COM does not provide shell access.
8.新建项目
在IDEA中New Project from version control Git 复制刚才项目的地址,如https://gitee.com/yxj/gulimall.git
创建以下模块
聚合服务gulimall
商品服务product
存储服务ware
订单服务order
优惠券服务coupon
用户服务member
每个模块导入web和openFeign
①聚合工程
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.atguigu.gulimallgroupId>
<artifactId>gulimallartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>gulimallname>
<description>谷粒商城-聚合服务description>
<packaging>pompackaging>
<modules>
<module>gulimall-couponmodule>
<module>gulimall-membermodule>
<module>gulimall-ordermodule>
<module>gulimall-productmodule>
<module>gulimall-waremodule>
modules>
project>
②git提交过滤文件
在maven窗口刷新,并点击+号,找到刚才的pom.xml添加进来,发现多了个root。这样比如运行root的clean命令,其他项目也一起clean了。
修改总项目的.gitignore,把小项目里的垃圾文件在提交的时候忽略掉
target/
pom.xml.tag
pom.xml.releaseBackup
pom.xml.versionsBackup
pom.xml.next
release.properties
dependency-reduced-pom.xml
buildNumber.properties
.mvn/timing.properties
.mvn/wrapper/maven-wrapper.jar
**/mvnw
**/mvnw.cmd
**/.mvn
**/target
.idea
**/.gitignore
**/README.md
9.项目初始化
①在gitee拉取 人人开源的前台和后台项目
人人开源/renren-fast-vue 后台管理系统前端
人人开源/renren-fast 后台管理系统后端 放带idea的gulimall项目中
人人开源/renren-generator 代码生成器 放到idea的gulimall项目中,
②前端环境软件
安装node.js ,配置环境变量 , 配置npm使用淘宝镜像
在项目的cmd窗口 npm install 下载依赖
10.Mybatis-Plus整合
① 导入依赖
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.2.0version>
dependency>
② 配置:
spring:
datasource:
username: root
password: root
url: jdbc:mysql://192.168.56.10:3306/gulimall_pms
driver-class-name: com.mysql.jdbc.Driver
mybatis-plus:
# mapper文件扫描
mapper-locations: classpath*:/mapper/**/*.xml
global-config:
db-config:
id-type: auto # 数据库主键自增
③ 其他:
1.配置数据源:
导入数据库的驱动依赖
在application.yml配置数据源信息
2.配置mybatis-Plus:
使用MapperScan注解
告诉mybatis-Plus,sql映射文件位置,在yml中配置
yml配置主键自增
11.SpringCloud

springcloud依赖:
<spring-boot.version>2.1.8.RELEASEspring-boot.version>
<spring-cloud.version>Greenwich.SR3spring-cloud.version>
在common的pom.xml中加入
下面是依赖管理,相当于以后再dependencies里引spring cloud alibaba就不用写版本号, 全用dependencyManagement进行管理
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-alibaba-dependenciesartifactId>
<version>2.1.0.RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
三,微服务-注册中心、配置中心、网关

1.nacos注册,发现中心
一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。 作为我们的注册中心和配置中心。
1.导入依赖
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId>
dependency>
2.在应用的 /src/main/resources/application.properties 配置文件中配置 Nacos Server 地址和基本配置信息
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
spring.application.name=服务名
server.port=18082
3.使用 @EnableDiscoveryClient 注解开启服务注册与发现功能
@EnableDiscoveryClient
4.下载nacos
2.Openfeign服务远程调用
2.1使用Feign
1.导入依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
dependency>
2.编写一个接口,告诉springcloud这个接口需要调用远程服务
@FeignClient("调用的服务名")
public interface CouponFeign {
@PostMapping("/save")
public R save(@RequestBody SpuBoundTo spuBoundTo);
}
3.调用的主启动类上加服务调用注解
@EnableFeignClients(basePackages = "服务调用的接口的包全路径") 例:com.smile.gulimall.member.feign
2.2 feign在远程调用的问题
①

解决请求头丢失的问题:
加上feign远程调用的请求拦截器。
/**
* Feign配置类
* @author smile
* @date 2022/5/4 9:27
*/
@Configuration
public class GuliFeignConfig {
/**
* 解决 feign远程调用不带请全体
* @return
*/
@Bean("requestInterceptor")
public RequestInterceptor requestInterceptor() {
return new RequestInterceptor() {
@Override
public void apply(RequestTemplate requestTemplate) {
// 1.拿到刚进来的这个请求
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest(); // 老请求
if (request != null) {
// 同步请求头数据,Cookie
// 获取老请求的cookie
String cookie = request.getHeader("Cookie");
// 给新请求同步了老请求的cookie
requestTemplate.header("Cookie", cookie);
}
}
};
}
}
②

解决在每个异步都设置一下主线程的请求信息:
// 获取主线程的请求信息
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
CompletableFuture<Void> getAddressFuture = CompletableFuture.runAsync(() -> {
// 在每个异步线程都共享一下之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
}, executor);
CompletableFuture<Void> cartFuture = CompletableFuture.runAsync(() -> {
// 在每个异步线程都共享一下之前的请求数据
RequestContextHolder.setRequestAttributes(requestAttributes);
}, executor);
2.nacos配置中心
我们还可以用nacos作为配置中心。配置中心的意思是不在application.properties 等文件中配置了,而是放到nacos配置中心公用,这样无需每台机器都改。
1.导入依赖
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-nacos-configartifactId>
dependency>
2.在应用的 /src/main/resources/bootstrap.properties 配置文件中配置 Nacos Config 元数据 (bootstrap优先级高)
# 该配置影响统一配置中心中的dataId
spring.application.name=服务名
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
#名称空间
spring.cloud.nacos.config.namespace=78ccd600-feeb-4202-bfa7-fa509a731677
# 环境设置:dev、test、prod
spring.profiles.active=dev
#分配的分组
spring.cloud.nacos.config.group=xxx
#多配置读取(加载)
spring.cloud.nacos.config.ext-config[0].data-id=xxx.properties
# 开启动态刷新配置,否则配置文件修改,工程无法感知
spring.cloud.nacos.config.ext-config[0].refresh=true
3.在nacos服务器上可以配置相关的配置
创建的命名规则:${prefix} - ${spring.profiles.active} . ${file-extension}
4.动态刷新配置
@RefreshScop:动态刷新并获取
加
@Value("${配置项的名}")
3.Gateway网关
发送请求需要知道商品服务的地址,如果商品服务器有100服务器,1号掉线后,还得改,所以需要网关动态地管理,他能从注册中心中实时地感知某个服务上线还是下线。请求也要加上询问权限,看用户有没有权限访问这个请求,也需要网关。所以我们使用spring cloud的gateway组件做网关功能。网关是请求浏览的入口,常用功能包括路由转发,权限校验,限流控制等。springcloud gateway取到了zuul网关。
三大核心概念:
Route: The basic building block of the gateway. It is defined by an ID, a
destination URI, a collection of predicates断言, and a collection of filters.
A route is matched if the aggregate predicate is true.
发一个请求给网关,网关要将请求路由到指定的服务。路由有id,目的地uri,断言的集合,匹配了断言就能到达指定位置,
Predicate断言: This is a Java 8 Function Predicate. The input type is a Spring
Framework ServerWebExchange. This lets you match on anything from the
HTTP request, such as headers or parameters.就是java里的断言函数,匹配请求里的任何信息,包括请求头等
Filter: These are instances of Spring Framework GatewayFilter that have been
constructed with a specific factory. Here, you can modify requests and
responses before or after sending the downstream request.
过滤器请求和响应都可以被修改。
客户端发请求给服务端。中间有网关。先交给映射器,如果能处理就交给handler
处理,然后交给一系列filer,然后给指定的服务,再返回回来给客户端。
1.导入依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-gatewayartifactId>
dependency>
2.配置文件
spring:
cloud:
gateway:
routes:
- id: test_route
uri: https://www.baidu.com # 转发的地址
predicates:
- Query=url,baidu # 判断条件 ?url=baidu
- id: qq_route
uri: https://www.qq.com
predicates:
- Query=url,qq
- id: admin-route
uri: lb://renren-fast #lb是负载均衡
predicates:
- Path=/api/**
filters:
- RewritePath=/api/(?>.*),/renren-fast/$\{segment} # 重写路径(前面是去除,后面是拼接)
3.跨域请求
@Configuration // gateway
public class GulimallCorsConfiguration {
@Bean // 添加过滤器
public CorsWebFilter corsWebFilter(){
// 基于url跨域,选择reactive包下的
UrlBasedCorsConfigurationSource source=new UrlBasedCorsConfigurationSource();
// 跨域配置信息
CorsConfiguration corsConfiguration = new CorsConfiguration();
// 允许跨域的头
corsConfiguration.addAllowedHeader("*");
// 允许跨域的请求方式
corsConfiguration.addAllowedMethod("*");
// 允许跨域的请求来源
corsConfiguration.addAllowedOrigin("*");
// 是否允许携带cookie跨域
corsConfiguration.setAllowCredentials(true);
// 任意url都要进行跨域配置
source.registerCorsConfiguration("/**",corsConfiguration);
return new CorsWebFilter(source);
}
}
四,前端基础知识
…
1.使用Vue脚手架进行开发
1.全局安装webpack
npm install webpack -g
2.全局安装vue脚手架
npm install -g @vue/cli-init
3 初始化vue项目
vue init webpack appname:vue脚手架使用webpack模板初始化一个appname项目
4 启动vue项目
项目的package.json中有scripts,代表我们能运行的命令
npm start = npm run dev: 启动项目
npm run build:将项目打包
2.使用element-ui
推荐使用 npm 的方式安装,它能更好地和 webpack 打包工具配合使用。
npm i element-ui -S
在 main.js 中写入以下内容:
import ElementUI from ‘element-ui’;
import ‘element-ui/lib/theme-chalk/index.css’;
Vue.use(ElementUI);
五,MyBatis-Plus
1.逻辑删除
① 配置配置文件
mybatis-plus:
mapper-locations: classpath:/mapper/**/*.xml
global-config:
db-config:
id-type: auto #主键自增
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
② 实体类上标记逻辑删除的字段(用注解)
/** * 是否显示[0-不显示,1显示] */
@TableLogic(value = "1",delval = "0")
private Integer showStatus;
2.分页插件
@Configuration
@EnableTransactionManagement // 开启事务
@MapperScan("com.smile.gulimall.product.dao")
public class MyBatisConfig {
/**
* 引入分页插件
* @return
*/
@Bean
public PaginationInterceptor paginationInterceptor() {
PaginationInterceptor paginationInterceptor = new PaginationInterceptor();
// 设置请求的页面大于最大页后操作,true调回到首页吗,false继续请求 默认false
paginationInterceptor.setOverflow(true);
// 设置最大页限制数量,默认500, -1:不限制
paginationInterceptor.setLimit(1000);
return paginationInterceptor;
}
}
五 , SpringMVC
1.视图映射
发送一个请求直接跳转到一个页面 ,springMVC viewcontroller; 将请求和页面映射过来。
/**
SpringMVC 配置文件库
*/
@Configuration
public class GulimallWebConfig implements WebMvcConfigurer {
/**
* 视图映射
* @param registry
*/
@Override
public void addViewControllers(ViewControllerRegistry registry) {
registry.addViewController("/login.html").setViewName("login");
registry.addViewController("/reg.html").setViewName("reg");
}
}
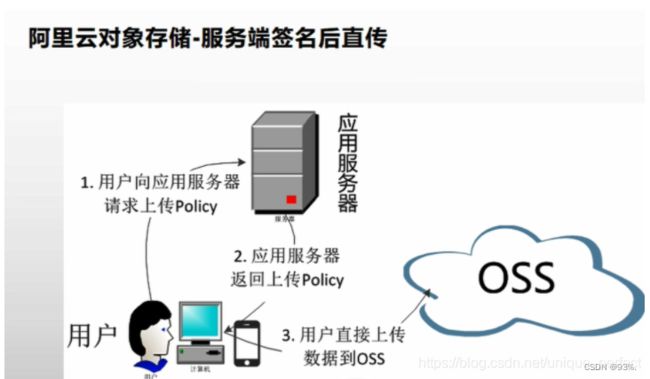
六,对象储存(OSS)
上传的账号信息存储在应用服务器 上传先找应用服务器要一个policy上传策略,生成防伪签名
1.方法一
使用代码上传
查看阿里云关于文件上传的帮助: https://help.aliyun.com/document_detail/32009.html?spm=a2c4g.11186623.6.768.549d59aaWuZMGJ
1 添加依赖包
在Maven项目中加入依赖项(推荐方式)
在 Maven 工程中使用 OSS Java SDK,只需在 pom.xml 中加入相应依赖即可。以 3.8.0 版本为例,在 2 上传文件流 上面代码的信息可以通过如下查找: endpoint的取值:点击概览就可以看到你的endpoint信息,endpoint在 是使用SpringCloud Alibaba 1 添加依赖 2 创建“AccessKey ID”和“AccessKeySecret” 3 yml配置key,secret和endpoint相关信息 4 注入OSSClient并进行文件上传下载等操作 但是这样来做还是比较麻烦,如果以后的上传任务都交给gulimall-product来完 成,显然耦合度高。最好单独新建一个Module来完成文件上传任务。—创建第三方模块 gulimall-third-party 引入pom 配置信息 编写配置文件 bootstrap.properties nacos端新建oss.yml 剩下的看文档 后端 在Java中提供了一系列的校验方式,它这些校验方式在“javax.validation.constraints”包中,提供了如@Email,@NotNull等注解。 里面依赖了hibernate-validator The annotated element must not be null. Accepts any type. 2 @NotEmpty the annotated element must not be null nor empty. 该注解修饰的字段不能为null或"" Supported types are: 支持以下几种类型 CharSequence (length of character sequence is evaluated)字符序列(字符序列长度的计算) The annotated element must not be null and must contain at least one non-whitespace character. Accepts CharSequence. @Valid controller中加校验注解 @Valid,开启校验, BindResult 给校验的Bean后,紧跟一个BindResult,就可以获取到校验的结果。拿到校验的结果,就可以自定义的封装。 这种是针对于该请求设置了一个内容校验,如果针对于每个请求都单独进行配置,显然不是太合适,实际上可以统一的对于异常进行处理。 统一异常处理@ControllerAdvice 可以使用SpringMvc所提供的@ControllerAdvice,通过“basePackages”能够说明处理哪些路径下的异常。 } ① groups 在这种情况下,没有指定分组的校验注解,默认是不起作用的。想要起作用就必须要加groups。 ② @Validated 注解 @Validated的value方法: Specify one or more validation groups to apply to the validation step kicked off by this annotation. JSR-303 defines validation groups as custom annotations which an application declares for the sole purpose of using JSR-303 将验证组定义为自定义注释,应用程序声明的唯一目的是将它们用作类型安全组参数,如 SpringValidatorAdapter 中实现的那样。 Other SmartValidator implementations may support class arguments in other ways as well. 其他SmartValidator 实现也可以以其他方式支持类参数。 3 分组情况下,校验注解生效问题 场景:要校验showStatus的01状态,可以用正则,但我们可以利用其他方式解决 如何做: 添加依赖 1 编写自定义的校验注解 message()错误信息 } 2.该属性值取哪里取呢? 3 编写 自定义的校验器 4 关联校验器和校验注解 一个校验注解可以匹配多个校验器 5 使用实例 简介 基本概念: index索引 名词:相当于mysql的db Type类型 类似于mysql的table,每一种类型的数据放在一起 index库>type表>document文档 Document文档 下载ealastic search(存储和检索)和kibana(可视化检索) 注意版本要统一 配置 es可以被远程任何机器访问 递归更改权限,es需要访问 启动Elastic search 9200是用户交互端口 9300是集群心跳端口 -e指定是单阶段运行 -e指定占用的内存大小,生产时可以设置32G 启动kibana: 查看elasticsearch版本信息: http://192.168.11.129:9200 访问Kibana: http://192.168.56.10:5601/app/kibana ① 创建工程–gulimall-search ② 导入依赖 ③ 在spring-boot-dependencies中所依赖的ES版本位6.8.5,要改掉 ④ 编写配置,给容器中注入一个RestHighLevelClient 1.导pom: 2.关闭 thymeleaf 缓存 3.把静态文件放入 static 文件夹 。把页面放到 templates 文件夹 4.想用thymeleaf的语法需要在html引入名称空间 5.想修改页面不重启服务器实时更新(引入pom) — 修改完页面 ctrl+F9 修改hosts,映射gulimall.com到192.168.56.10(本机地址)。关闭防火墙 修改nginx/conf/nginx.conf,将upstream映射到我们的网关服务 修改nginx/conf/conf.d/gulimall.conf,接收到gulimall.com的访问后,如果是/,转交给指定的upstream,由于nginx的转发会丢失host头,造成网关不知道原host,所以我们添加头信息 配置gateway为服务器,将域名为**.gulimall.com转发至商品服务。配置的时候注意 网关优先匹配的原则,所以要把这个配置放到后面 此时请求接口和请求页面都是gulimall.com 1.Jmeter 下载:https://jmeter.apache.org/download_jmeter.cgi 2.jconsole 与 jvisualvm 监控 jconsole:只要安装了jdk然后在命令行 输入jconsole就可以。 jvisualvm(推荐):只要安装了jdk然后在命令行 输入jvisualvm就可以。 由于动态资源和静态资源目前都处于服务端,所以为了减轻服务器压力,我们将 js、css、img等静态资源放置在Nginx端,以减轻服务器压力 静态文件上传到 mydata/nginx/html/static/index/css,这种格式 修改index.html的静态资源路径,加上static前缀src=“/static/index/img/img_09.png” 修改/mydata/nginx/conf/conf.d/gulimall.conf 如果遇到有/static为前缀的请求,转发至html文件夹 location /static { location / { } 优化代码… 缓存: ①本地缓存:和微服务同一个进程。缺点:分布式时本都缓存不能共享。②分布式缓存:缓存中间件。 哪些数据适合放入缓存?@及时性,数据一致性要求不高的。@访问量大的且更新频率不高的数据(读多,写少) 安装docker-redis product导入依赖 配置redis主机地址 自动注入了RedisTemplate / stringRedisTemplate lettuce堆外内存溢出bug 产生原因: 1)、springboot2.0以后默认使用lettuce作为操作redis的客户端,它使用netty进行网络通信 2)、lettuce的bug导致netty堆外内存溢出。netty如果没有指定堆外内存,默认使 解决方案:由于是lettuce的bug造成,不要直接使用-Dio.netty.maxDirectMemory去调大虚拟机堆外内存,治标不治本。 1)、升级lettuce客户端。但是没有解决的 lettuce和jedis是操作redis的底层客户端,RedisTemplate是再次封装 缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id 解决:缓存空对象、布隆过滤器、mvc拦截器 缓存雪崩是指在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻 解决方案: 规避雪崩:缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。 缓存雪崩和缓存击穿不同的是: 缓存击穿 指 并发查同一条数据。缓存击穿是指缓存中没有但数据库中有的数据 设置热点数据永远不过期。 不好的方法是synchronized(this),肯定不能这么写 ,不具体写了 锁时序问题:之前的逻辑是查缓存没有,然后取竞争锁查数据库,这样就造成多 解决方法:竞争到锁后,再次确认缓存中没有,再去查数据库。 本地缓存问题:每个微服务都要有缓存服务、数据更新时只更新自己的缓存,造 解决方案:分布式缓存,微服务共用 缓存中间件 分布式锁 redis分布式锁的原理:setnx,同一时刻只能设置成功一个 没获取到锁阻塞或者sleep一会 设置好了锁,玩意服务出现宕机,没有执行删除锁逻辑,这就造成了死锁 解决:设置过期时间 解决:锁续期(redisson有看门狗),。删锁的时候明确是自己的锁。如uuid 解决:删除锁必须保证原子性(保证判断和删锁是原子的)。使用redis+Lua脚本 上面第 8 点的lua脚本写法每次用分布式锁时比较麻烦,我们可以采用redisson现有框架 https://redis.io/topics/distlock Redisson Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data 导入依赖 这个用作连续,后面可以使用redisson-spring-boot-starter 开启配置 https://github.com/redisson/redisson/wiki/2.-%E9%85%8D%E7%BD%AE%E6%96%B9%E6%B3%95 分布式锁:github.com/redisson/redisson/wiki/8.-分布式锁和同步器 A调用B。AB都需要同一锁,此时可重入锁就可以重入,A就可以调用B。不可重入锁时,A调用B将死锁 基于Redis的Redisson分布式可重入锁RLock Java对象实现了java.util.concurrent.locks.Lock接口。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。 锁的续期:大家都知道,如果负责储存这个分布式锁的Redisson节点宕机以后, 如果传递了锁的超时时间,就执行脚本,进行占锁; Redisson同时还为分布式锁提供了异步执行的相关方法: RLock对象完全符合Java的Lock规范。也就是说只有拥有锁的进程才能解锁,其他进程解锁则会抛出IllegalMonitorStateException错误。但是如果遇到需要其他进程也能解锁的情况,请使用分布式信号量Semaphore 对象. 基于Redis的Redisson分布式可重入读写锁RReadWriteLock Java对象实现了 分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。 读写锁的好处 保证一定能读到最新数据。写锁是一个排他锁(互斥锁)。写锁是一个共享锁。写锁没释放读锁就必须等待。 总结:只要有写的存在,都必须等待。 上锁时在redis的状态 信号量为存储在redis中的一个数字,当这个数字大于0时,即可以调用acquire()方法增加数量,也可以调用release()方法减少数量,但是当调用release()之后小于0的话方法就会阻塞,直到数字大于0 基于Redis的Redisson的分布式信号量(Semaphore)Java对象RSemaphore采用了与java.util.concurrent.Semaphore相似的接口和用法。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。 基于Redisson的Redisson分布式闭锁(CountDownLatch)Java对象RCountDownLatch采用了与java.util.concurrent.CountDownLatch相似的接口和用法。 以下代码只有offLatch()被调用5次后 setLatch()才能继续执行 双写模式:写数据库后,写缓存 如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。 每次都那样写缓存太麻烦了,spring从3.1开始定义了Cache、CacheManager接 Cache接口的实现包括RedisCache、EhCacheCache、ConcurrentMapCache等 每次调用需要缓存功能的方法时,spring会检查检查指定参数的指定的目标方法 使用Spring缓存抽象时我们需要关注以下两点: 1、确定方法需要缓存以及他们的缓存策略 指定缓存类型并在主配置类上加上注解 在配置文件加配置 第一个方法存放缓存,第二个方法清空缓存 如果要清空多个缓存,用@Caching(evict={@CacheEvict(value=“”)}) 1.读模式 缓存穿透:查询一个null数据。解决方案:缓存空数据,可通过 spring.cache.redis.cache-null-values=true 2.写模式:(缓存与数据库一致) 读写加锁。 常规数据(读多写少,即时性,一致性要求不高的数据,完全可以使用Spring-Cache): 写模式(只要缓存的数据有过期时间就足够了) 特殊数据:特殊设计 ① 继承Thread ② 实现Runable ③ 实现Callable接口 + FutureTask (可以拿到返回结果,可以处理异常) ④ 线程池 // 我们以后在业务代码里面,以上三种启动线程的方式都不用。【将所有的多线程异步任务都交给线程池执行】 方式一: 方式二:原生创建线程池。 总结: 方式1和2:主线程无法获取线程的运算结果,不适合当前场景。 方式3 :主线程可以获取线程的运算结果,但是不利于控制服务器中的线程资源,可以导致服务器资源耗尽。 方式4:通过如下两种方式初始化线程池 没有返回结果的 可以获取返回结果的 方法完成后的感知 方法执行完成后的处理 通过 阿里云-云市场 购买短信服务,根据提供的API文档使用。 MD5 & MD5 盐值加密。 可逆(可以从密文转到明文); 不可逆(不可以从密文转到明文); 带盐值加密:随机值。 spring家的加密器(推荐使用): 上面社交登录的流程就是OAuth协议 OAuth(开放授权)是一个开放标准,允许用户授权第三方移动应用访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三方移动应用或分享他们数据的所有内容,OAuth2.0是OAuth协议的延续版本,但不向后兼容OAuth 1.0即完全废止了OAuth1.0。 1、使用Code换取AccessToken,Code只能用一次 session要能在不同服务和同服务的集群的共享 https://spring.io/projects/spring-session-data-redis https://docs.spring.io/spring-session/docs/2.4.2/reference/html5/#modules 通过SpringSession修改session的作用域 会员服务、订单服务、商品服务,都是去redis里存储session 依赖: 配置: 添加注解(主启动类): 但是现在还有一些问题: 把这个配置放到每个微服务下 就是分析@EnableRedisHttpSession, SessionRepositoryFilter,每个请求都要经过该filter 前面我们@Bean注入了sessionRepositoryFilter,他是一个过滤器,那我们需要知道他过滤做了什么事情: 原生的获取session时是通过HttpServletRequest获取的 这里对request进行包装,并且重写了包装request的getSession()方法 上面解决了同域名的session问题,但如果 去百度了解下:https://www.jianshu.com/p/75edcc05acfd 最终解决方案:都去中央认证器 spring session已经解决不了不同域名的问题了。无法扩大域名 记住一个核心思想:建议一个公共的登陆点server,他登录了代表这个集团的产品就登录过了 上图是CAS官网上的标准流程,具体流程如下:有两个子系统app1、app2 用户访问app1系统,app1系统是需要登录的,但用户现在没有登录。 用户访问app2系统,app2系统没有登录,跳转到SSO。 SSO系统登录后,跳回原业务系统时,带了个参数ST,业务系统还要拿ST再次访问SSO进行验证,觉得这个步骤有点多余。如果想SSO登录认证通过后,通过回调地址将用户信息返回给原业务系统,原业务系统直接设置登录状态,这样流程简单,也完成了登录,不是很好吗? 其实这样问题时很严重的,如果我在SSO没有登录,而是直接在浏览器中敲入回调的地址,并带上伪造的用户信息,是不是业务系统也认为登录了呢?这是很可怕的。 server:登录服务器、8080 、ssoserver.com 3个系统即使域名不一样,想办法给三个系统同步同一个用户的票据; .中央认证服务器 消息队列是典型的:生产者、消费者模型。生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,这样就实现了生产者和消费者的解耦。 结合前面所说的问题: 商品服务对商品增删改以后,无需去操作索引库,只是发送一条消息,也不关心消息被谁接收。 MQ是消息通信的模型,并不是具体实现。现在实现MQ的有两种主流方式:AMQP、JMS。 两者间的区别和联系: docker下载 注: 15672 – 管理界面ui端口 在web浏览器中输入地址:http://虚拟机ip:15672/ 输入默认账号: guest : guest overview:概览 connections:无论生产者还是消费者,都需要与RabbitMQ建立连接后才可以完成消息的生产和消费,在这里可以查看连接情况 channels:通道,建立连接后,会形成通道,消息的投递获取依赖通道。 Exchanges:交换机,用来实现消息的路由 Queues:队列,即消息队列,消息存放在队列中,等待消费,消费后被移除队列。 端口: 5672: rabbitMq的编程语言客户端连接端口 15672:rabbitMq管理界面端口 25672:rabbitMq集群的端口 创建 Exchange(交换器),Queue(队列),Binding(绑定),消息发送,消息接收, ①配置开启确认 ② 设置确认回调 例子: 面试题:如何避免消息丢失? 消息的丢失,在MQ角度考虑,一般有三种途径: 1.生产者确认发送到MQ服务器(生产者确认机制) 生产者/消费者保证消息不丢失有两种实现方式: 1.开启事务模式 开启事务会大幅降低消息发送及接收效率,使用的相对较少,因此我们生产环境一般都采取消息确认模式,我们只是讲解消息确认模式及消息持久化 1.生产者的ACK机制。有时,业务处理成功,消息也发了,但是我们并不知道消息是否成功到达了rabbitmq,例如:由于网络等原因导致业务成功而消息发送失 败,此时可以使用rabbitmq的发送确认功能,要求rabbitmq显式告知我们消息是否已成功发送。 分布式事务:最大的问题。网络问题+分布式机器 注: 7种,我只列2种常用的。 同一个对象内事务方法互调默认失效,原因 绕过了代理对象,事务使用代理对象来控制的。 解决:使用代理对象来调用事务方法: 1),引入 spring-boot-starter-aop ;里面引入了 aspectjweaver 2),主启动类上开启 aspectjweaver 动态代理功能。以后所有的动态代理都是 aspectjweaver 创建的(即使没有接口也可以创建动态代理) 3),用代理对象本类互调 分布式系统经常出现的异常:机器宕机,网络异常,消息丢失,消息乱序,数据错误,不可靠的TCP,储存数据丢失… 分布式系统中实现一致性的 raft 算法(可视化动态图):http://thesecretlivesofdata.com/raft/ 2PC 模式 柔性事务-TCC事务补偿型方案 柔性事务-最大努力通知型方案 柔性事务-可靠消息+最终一致性方案(异步确保型) **Seata是什么?:**是分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata将为用户提供了 AT ,TCC, SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案 *** 这个 seata AT 方案 只适合 不是高并发*** seata-server:https://github.com/seata/seata/releases ① 导入依赖 spring-cloud-starter-alibaba-seata seata-all-0.7.1 ② 启动seata 服务器 (上面下载的协调器) registry.conf:中修改 registry type=nacos (修改注册中心配置) file.conf:配置文件 ③ ④ 所有想要到分布式事务的微服务使用 seata DataSourceProxy 代理自己的数据源 因为 Seata 通过代理数据源实现分支事务,如果没有注入,事务无法成功回滚 ⑤ 每个微服务 都要导入filer.conf 和 registry.conf 为了 保持 file.conf 的 service.vgroup_mapping 配置必须和 需要 将 vgroup_mapping.my_test_tx_group = “default” 改为 -> vgroup_mapping.当前服务名-fescar-service-group = “default” 解决 下单,关闭订单,锁库存,解锁库存,保证事务的一致性,最终一致性。(如果是高并发的事务 选择这个使用) 收消息 发消息 在库存创建这些 (交换机,队列,绑定) 如何防止消息丢失: 如何防止消息重复: 具体代码查看 gulimall 项目的: gulimall-order的:MyMQConfig,MyRabbitConfig,OrderCloseListener,OrderServiceImpl 的代码 gulimall-ware的:MyRabbitConfig,StockReleaseListener,WareSkuServiceImpl 的代码 当支付成功之后,支付宝要在25小时内发送8条响应数据,我们需要给支付宝回复 success 支付宝才会停止给我们发送。支付宝要给我们发送 消息 需要用内网穿透。不然支付宝是找不到我们的。 对比: 如何使用 Sentinel:https://github.com/alibaba/Sentinel/wiki/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8 下载 https://github.com/alibaba/Sentinel/releases 对应工程依赖的版本。 启动 用 Java -jar xxxx.jar 启动 默认账号密码:sentinel Feign 支持 Sentinel 适配了 Feign 组件。如果想使用,除了引入 配置文件打开 Sentinel 对 Feign 的支持: 加入 1)使用:fallback : 如果这个远程调用有问题就会去调用这个类里面的方法 熔断 调用对应的实现类 2)在sentinel控制台手动指定远程服务的降级策略 远程服务被降级处理,触发我们的熔断回调的方法。 超大浏览的时候,必须牺牲一些远程服务。在服务的提供方(远程服务)指定降级策略; 提供方是在运行。但是不运行自己的业务逻辑,返回的是默认的降级数据(限流的数据)。 @SentinelResource 无论是1,2方法一定要配置被限流以后的默认配置,url请求可以设置统一返回:WebCallbackManager 用新版控制台:1.7.1.jar ① 服务提供者与消费者导入依赖 ② 打开 debug 日志 ① docker 安装 zipkin服务器 ② 全部服务导入依赖 ③ 所有的服务都加上配置 访问 ip:9411 https://blog.csdn.net/hancoder/article/details/107612802 Kubernetes 简称 k8s。是用于自动部署,扩展和管理容器化应用程序的开源系统。https://kubernetes.io/zh/ 开启密码访问 设置好网络 ①关闭防火墙 ②关闭seLinux ③关闭swap ④添加主机名与IP对应关系: 查看主机名: 如果主机名不正确,可以通过“hostnamectl set-hostname :指定新的hostname”命令来进行修改。 将桥接的IPV4流量传递到iptables的链: Kubenetes默认CRI(容器运行时)为Docker,因此先安装Docker。 1、卸载之前的docker 2、安装Docker -CE 3、配置docker加速 启动Docker && 设置docker开机启动 安装 开机启动 查看kubelet的状态: 查看kubelet版本: 在Master节点上,创建并执行master_images.sh 给予这个文件有执行权限 执行创建的文件 master_images.sh 初始化kubeadm 详细部署文档:https://kubernetes.io/docs/concepts/cluster-administration/addons/ token: 在master节点上执行按照POD网络插件 以上地址可能被墙,可以直接获取本地已经下载的flannel.yml运行即可(https://blog.csdn.net/lxm1720161656/article/details/106436252 可以去下载) 也可以 去 /root/k8s/ 的 kube-flannel.yml文件用下面命令运行 查看命名空间: 查看master上的节点信息: 最后再次执行,并且分别在“ 监控pod进度 在node节点中执行,向集群中添加新的节点,执行在kubeadm init 输出的kubeadm join命令; 生成永久 获取所有的资源: kubectl get pods -o wide 可以获取到tomcat部署信息,能够看到它被部署到了k8s-node3上了 查看node3节点上,下载了哪些镜像: 在master上执行 pod的80映射容器的8080;server会带来pod的80 查看服务: 扩容:kubectl scale --replicas=3 deployment tomcat6 扩容了多份,所有无论访问哪个node的指定端口,都可以访问到tomcat6 缩容:kubectl scale --replicas=2 deployment tomcat6 https://blog.csdn.net/hancoder/category_11140481.html https://kubernetes.io/zh/docs/reference/kubectl/overview/ https://kubernetes.io/zh/docs/reference/kubectl/overview/#资源类型 在此示例中,以下命令将单个 pod 的详细信息输出为 YAML 格式的对象: 请记住:有关每个命令支持哪种输出格式的详细信息,请参阅 kubectl 参考文档。 现在我们使用NodePort的方式暴露,这样访问每个节点的端口,都可以访问各个Pod,如果节点宕机,就会出现问题。 前面我们通过命令行的方式,部署和暴露了tomcat,实际上也可以通过yaml的方式来完成这些操作。 修改“tomcat6-deployment.yaml”内容如下: 通过Ingress发现pod进行关联。基于域名访问 可以把ingress理解为nginx,通过域名访问service端口 步骤: 执行“k8s/ingress-controller.yaml”, (2)创建Ingress规则 ingress-tomcat6.yaml 修改本机的hosts文件,添加如下的域名转换规则: 同样网上可以找到yaml:https://gitee.com/CaiJinHao/kubernetesdashboard/tree/v1.10.1/src/deploy/recommended 1)、部署DashBoard 2)、暴露DashBoard为公共访问 默认DashBoard只能集群内部访问,修改Service为NodePort类型,暴露到外部 访问地址:http://NodeIP:30001 3)、创建授权账号 使用输出的token登录dashboard 默认的dashboard没啥用,kubesphere可以打通全部的devops链路,kubesphere集成了很多套件,集群要求比较高 如果不行就去下载压缩包解压 可以去这里下载压缩包 https://github.com/helm/helm/releases/tag/v2.17.0 创建 helm-rabc.yaml 文件 执行 出现这个代表成功了 初始化 查看tiller部署是否成功 初始化 查看tiller部署是否成功 1.先去除污点 ① 查看全部节点信息 ② 查看主节点 是否有污点 ③ 去除污点 2.安装 OpenEBS ① 创建名称空间 ② 安装OpenEBS 如果这个地址找不到就去:https://gitee.com/HanFerm/java-config-files/blob/master/k8s相关文件 找 openebs-operator-1.7.0.yaml 然后: # 设置默认storageclass 注意:此时不要给master加上污点,否者导致后面的pods安装不上(openldap,redis),待kubesphere安装完成后加上污点 这些yaml文件都去 https://gitee.com/HanFerm/java-config-files/blob/master/k8s相关文件 里面找 监控ks安装进度、是否正常 正确输出内容为: 使用 账号admin 密码 P@88w0rd 创建hr用户 用户名:smile-hr 密码:Dayu93%. 去登录ws-manager,创建 企业空间 ws-admin登录之前要使用ws-manager分配给他 登录ws-admin,邀请project-regular(ws-viewer只读命名空间)、project-admin(ws-regular角色 1. 登录project-admin创建devpos,邀请project-regular来开发 剩下的动手实验 具体配置查看:https://blog.csdn.net/hancoder/article/details/118053239 创建的 wordpress 用户名:smile 密码:123456 什么是 DevOs ? 先创建一个Dockerhub账号:smile779 18826292754 创建一个github账号 直接选择 kubeconfig 就行 先找到内置的 SonarQube 暴露的端口 生成一个token 把这个token 填写<dependency>
<groupId>com.aliyun.ossgroupId>
<artifactId>aliyun-sdk-ossartifactId>
<version>3.8.0version>
dependency>
以下代码用于上传文件流:
// Endpoint以杭州为例,其它Region请按实际情况填写。String endpoint = "http://oss-cn-hangzhou.aliyuncs.com";
// 云账号AccessKey有所有API访问权限,建议遵循阿里云安全最佳实践,创建并使用RAM子账号进行API访问或日常运维,请登录 https://ram.console.aliyun.com 创建。
String accessKeyId = "
这里就是上海等地区,如 oss-cn-qingdao.aliyuncs.com
bucket域名:就是签名加上bucket,如gulimall-fermhan.oss-cn-qingdao.aliyuncs.com
accessKeyId和accessKeySecret需要创建一个RAM账号:2.方法二(更简单)
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alicloud-ossartifactId>
<version>2.2.0.RELEASEversion>
dependency>
access-key: xxxxxxx
secret-key: xxxxxx
oss:
endpoint: oss-cn-shanghai.aliyuncs.com
@RunWith(SpringRunner.class)
@SpringBootTest
public class GulimallProductApplicationTests {
@Autowired
OSSClient ossClient;
@Test
public void testUpload() throws FileNotFoundException {
// 上传文件流。
InputStream inputStream = new FileInputStream("C:\\Users\\YAOXINJIA\\Desktop\\soft.png");
ossClient.putObject("gulimall-yaoxinjia", "soft.png", inputStream);
// 关闭OSSClient。
ossClient.shutdown();
System.out.println("上传完成...");
}
}
提醒!!!:
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alicloud-ossartifactId>
dependency>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-alibaba-dependenciesartifactId>
<version>2.1.0.RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
application.ymlserver:
port: 30000
spring:
application:
name: gulimall-third-party
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
logging:
level:
com.yxj.gulimall.product: debug
spring.cloud.nacos.config.name=gulimall-third-party
spring.cloud.nacos.config.server-addr=127.0.0.1:8848
spring.cloud.nacos.config.namespace=9054e55c-b667-428c-b71d-0f2b42a6acff
spring.cloud.nacos.config.extension-configs[0].data-id=oss.yml
spring.cloud.nacos.config.extension-configs[0].group=DEFAULT_GROUP
spring.cloud.nacos.config.extension-configs[0].refresh=true
spring:
cloud:
alicloud:
access-key: xxxxxx
secret-key: xxxxxx
oss:
endpoint: oss-cn-qingdao.aliyuncs.com
七,后端进行表单校验
1.使用 JSR303 数据校验
@NotNull等步骤1:使用校验注解
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-validationartifactId>
dependency>
在非空处理方式上提供了@NotNull,@NotBlank和@NotEmpty
1 @NotNull
注解元素禁止为null,能够接收任何类型
Collection (collection size is evaluated)
集合长度的计算
Map (map size is evaluated)
map长度的计算
Array (array length is evaluated)
数组长度的计算
3 @NotBlank
该注解不能为null,并且至少包含一个非空格字符。接收字符序列。// 可以在添加注解的时候,修改message:
@NotBlank(message = "品牌名必须非空")
步骤2:
@RequestMapping("/save")
public R save(@Valid @RequestBody BrandEntity brand){
brandService.save(brand);
return R.ok();
}
步骤3:
@RequestMapping("/save")
public R save(@Valid @RequestBody BrandEntity brand, BindingResult result){
if( result.hasErrors()){
Map<String,String> map=new HashMap<>();
//1.获取错误的校验结果
result.getFieldErrors().forEach((item)->{
//获取发生错误时的message
String message = item.getDefaultMessage();
//获取发生错误的字段
String field = item.getField();
map.put(field,message);
});
return R.error(400,"提交的数据不合法").put("data",map);
}else {
}
brandService.save(brand);
return R.ok();
}
步骤4:统一异常处理
1 抽取一个异常处理类@Slf4j
@RestControllerAdvice(basePackages = "com.atguigu.gulimall.product.controller")
public class GulimallExceptionControllerAdvice {
@ExceptionHandler(value = Exception.class) // 也可以返回ModelAndView
public R handleValidException(MethodArgumentNotValidException exception){
Map<String,String> map=new HashMap<>();
// 获取数据校验的错误结果
BindingResult bindingResult = exception.getBindingResult();
bindingResult.getFieldErrors().forEach(fieldError -> {
String message = fieldError.getDefaultMessage();
String field = fieldError.getField();
map.put(field,message);
});
log.error("数据校验出现问题{},异常类型{}",exception.getMessage(),exception.getClass());
return R.error(400,"数据校验出现问题").put("data",map);
}
2.分组校验
1 给校验注解,标注上groups,指定什么情况下才需要进行校验
groups里面的内容要以接口的形式显示出来
如:指定在更新和添加的时候,都需要进行校验。新增时不需要带id,修改时必须带id
@NotNull(message = “修改必须定制品牌id”, groups = {UpdateGroup.class})
@Null(message = “新增不能指定id”, groups = {AddGroup.class})
@TableId
private Long brandId;
2 业务方法参数上使用@Validated注解
指定一个或多个验证组以应用于此注释启动的验证步骤。
them as type-safe group arguments, as implemented in SpringValidatorAdapter.@RequestMapping("/save")
public R save(@Validated(AddGroup.class) @RequestBody BrandEntity brand) {
brandService.save(brand);
return R.ok();
}
@RequestMapping("/delete")
//@RequiresPermissions("${moduleNamez}:brand:delete")
public R delete(@RequestBody Long[] brandIds) {
brandService.removeByIds(Arrays.asList(brandIds));
return R.ok();
}
3 默认情况下,在分组校验情况下,没有指定指定分组的校验注解,将不会生效,它只会在不分组的情况下生效。3.自定义校验
复杂场景。比如我们想要下面的场景/**
* 显示状态[0-不显示;1-显示]
*/
@NotNull(groups = {AddGroup.class, UpdateStatusGroup.class})
@ListValue(vals = {0,1}, groups = {AddGroup.class, UpdateGroup.class, UpdateStatusGroup.class})
private Integer showStatus;
<dependency>
<groupId>javax.validationgroupId>
<artifactId>validation-apiartifactId>
<version>2.0.1.Finalversion>
dependency>
必须有3个属性
groups()分组校验
payload()自定义负载信息@Documented
// 指定校验器,可以自己创建一个校验器(可以指定多个不同的适配器,l)
@Constraint(validatedBy = { ListValueConstraintValidator.class})
@Target({ METHOD, FIELD, ANNOTATION_TYPE, CONSTRUCTOR, PARAMETER, TYPE_USE })
@Retention(RUNTIME)
public @interface ListValue {
// 使用该属性去Validation.properties中取
String message() default "{com.atguigu.common.valid.ListValue.message}";
Class<?>[] groups() default { };
Class<? extends Payload>[] payload() default { };
int[] value() default {};
common创建文件 ValidationMessages.properties 里面写上com.atguigu.common.valid.ListValue.message=必须提交指定的值 [0,1]
public class ListValueConstraintValidator implements ConstraintValidator<ListValue,Integer> {
private Set<Integer> set=new HashSet<>();
// 初始化方法
@Override
public void initialize(ListValue constraintAnnotation) {
int[] value = constraintAnnotation.value();
for (int i : value) {
set.add(i);
}
}
// 判断是否校验成功
@Override
public boolean isValid(Integer value, ConstraintValidatorContext context) {
// contains 判断包不包含
return set.contains(value);
}
}
@Constraint(validatedBy = { ListValueConstraintValidator.class})
/**
* 显示状态[0-不显示;1-显示]
*/
@ListValue(value = {0,1},groups ={AddGroup.class})
private Integer showStatus;
八,Elasticsearch 全文检索
mysql用作持久化存储,ES用作检索
在index中,可以定义一个或多个类型
保存在某个index下,某种type的一个数据document,文档是json格式的,
document就像是mysql中的某个table里面的内容。每一行对应的列叫属性1.dokcer中安装elastic search
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2
mkdir -p /usr/local/elasticsearch/plugins
mkdir -p /usr/local/elasticsearch/config
mkdir -p /usr/local/elasticsearch/data
echo "http.host: 0.0.0.0" >/usr/local/elasticsearch/config/elasticsearch.yml
chmod -R 777 /usr/local/elasticsearch
sudo docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /usr/local/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /usr/local/elasticsearch/data:/usr/share/elasticsearch/data \
-v /usr/local/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
2.安装kibana(可视化界面)
docker pull kibana:7.4.2
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.124.132:9200 -p 5601:5601 -d kibana:7.4.2
3.测试
4.SpringBoot整合ElasticSearch
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.4.2version>
dependency>
<properties>
<java.version>1.8java.version>
<elasticsearch.version>7.4.2elasticsearch.version>
properties>
@Configuration
public class GuliESConfig {
/**
* 请求测试项,比如es添加了安全访问规则,访问es需要添加一个安全头,就可以通过requestOptions设置
* 官方建议把requestOptions创建成单实例
*/
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
}
public RestHighLevelClient esRestClint() {
RestClientBuilder builder = null;
builder = RestClient.builder(new HttpHost("192.168.124.132", 9200, "http"));
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
}
4.简单使用 es
@Autowired
private RestHighLevelClient client;
@Override
public SearchResult search(SearchParam param) {
// 1.动态构建出查询需要的DSL语句
SearchResponse search = null;
// 1.准备检索请求
SearchRequest searchRequest = new SearchRequest();
// 2.构造检索条件
// 指定DSL,检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
...
searchRequest.source(searchSourceBuilder);
try {
// 2.执行检索请求
search = client.search(searchRequest, GuliESConfig.COMMON_OPTIONS);
} catch (IOException e) {
e.printStackTrace();
}
return search;
}
九,前台页面
引入模板引擎 – thymeleaf
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
thymeleaf:
cache: false
xmlns:th="http://www.thymeleaf.org"
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<optional>trueoptional>
dependency>
十,Nginx+网关
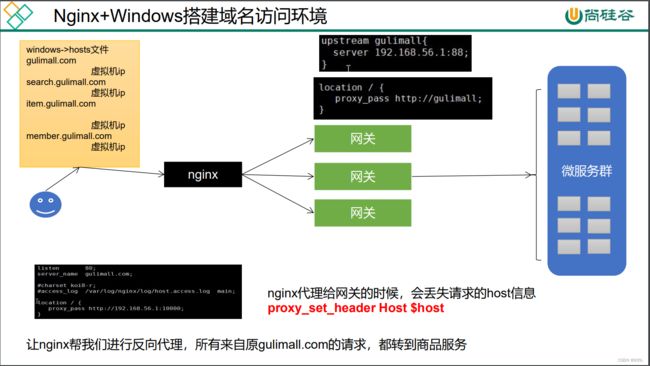
upstream gulimall{
# 88是网关
server 192.168.56.1:88;
}
location / {
proxy_pass http://gulimall;
proxy_set_header Host $host;
}
- id: gulimall_host_route
uri: lb://gulimall-product
predicates:
- Host=**.gulimall.com
十一,压力测试
2.动静分离
root /usr/share/nginx/html;
}
proxy_pass http://gulimall;
proxy_set_header Host $host;3.优化三级分类
4.分布式锁redisson 与 缓存
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
spring:
redis:
host: 192.168.56.11
port: 6379
5.内存溢出问题!!!
当进行压力测试时后期后出现堆外内存溢出OutOfDirectMemoryError
用Xms的值,可以使用-Dio.netty.maxDirectMemory进行设置
2)、切换使用jedis<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
<exclusions>
<exclusion>
<groupId>io.lettucegroupId>
<artifactId>lettuce-coreartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
dependency>
6.缓存失效
①缓存穿透
为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导
致数据库压力过大。②缓存雪崩
同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同缓存数据库中。
设置热点数据永远不过期。
出现雪崩:降级 熔断
事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
事后:利用 redis 持久化机制保存的数据尽快恢复缓存③缓存击穿
(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,
又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
加互斥锁:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效
的时候(判断拿出来的值为空),不是立即去load db去数据库加载,而是先使用
缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache
的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设
缓存;否则,就重试整个get缓存的方法。7,缓存击穿:加锁
次查数据库。8.分布式缓存
成缓存数据不一致
分布式项目时,但本地锁只能锁住当前服务,需要分布式锁
前提,锁的key是一定的,value可以变
业务还没执行完锁就过期了,别人拿到锁,自己执行完去删了别人的锁
判断uuid对了,但是将要删除的时候锁过期了,别人设置了新值,那删除了别人
的锁
完成,脚本是原子的9.redisson框架 分布式锁
https://github.com/redisson/redisson
Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服
务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue,
BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong,
CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring
cache, Executor service, Live Object service, Scheduler service) Redisson提供
了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的
关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处
理业务逻辑上。①环境搭建
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.13.4version>
dependency>
@Configuration
public class MyRedisConfig {
@Value("${ipAddr}")
private String ipAddr;
// redission通过redissonClient对象使用 // 如果是多个redis集群,可以配置
@Bean(destroyMethod = "shutdown")
public RedissonClient redisson() {
Config config = new Config();
// 创建单例模式的配置
config.useSingleServer().setAddress("redis://" + ipAddr + ":6379");
return Redisson.create(config);
}
}
②redisson使用
(2) 可重入锁(Reentrant Lock)
// 参数为锁名字 1,获取一把锁,只要锁的名字一样,就是同一把锁
RLock lock = redissonClient.getLock("CatalogJson-Lock");//该锁实现了JUC.locks.lock接口
// 2.加锁
lock.lock();//阻塞等待
try {
System.out.println("加锁成功,执行业务");
} finally {
// 解锁放到finally // 如果这里宕机:有看门狗,不用担心
lock.unlock();
}
而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情
况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实
例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间
是30秒钟(每到20s就会自动续借成30s,是1/3的关系),也可以通过修改
Config.lockWatchdogTimeout来另行指定。// 加锁以后10秒钟自动解锁,看门狗不续命
// 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
如果没传递锁时间,使用看门狗的时间,占锁。如果返回占锁成功future,调用future.onComplete();
没异常的话调用scheduleExpirationRenewal(threadId);
重新设置过期时间,定时任务;
看门狗的原理是定时任务:重新给锁设置过期时间,新的过期时间就是看门狗的默认时间;
锁时间/3是定时任务周期;RLock lock = redisson.getLock("anyLock");
lock.lockAsync();
lock.lockAsync(10, TimeUnit.SECONDS);
Future<Boolean> res = lock.tryLockAsync(100, 10, TimeUnit.SECONDS);
public Map<String, List<Catalog2Vo>> getCatalogJsonDbWithRedisson() {
Map<String, List<Catalog2Vo>> categoryMap=null;
RLock lock = redissonClient.getLock("CatalogJson-Lock");
lock.lock();
try {
Thread.sleep(30000);
categoryMap = getCategoryMap();
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
lock.unlock();
return categoryMap;
}
}
(3) 读写锁(ReadWriteLock)
java.util.concurrent.locks.ReadWriteLock接口。其中读锁和写锁都继承了RLock
接口。RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock");
// 最常见的使用方法
rwlock.readLock().lock();
// 或
rwlock.writeLock().lock();
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// 或
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// 或
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();
HashWrite-Lock
key:mode value:read
key:sasdsdffsdfsdf… value:1(4) 信号量(Semaphore)
RSemaphore semaphore = redisson.getSemaphore("semaphore");
semaphore.acquire();
//或
semaphore.acquireAsync();
semaphore.acquire(23);
semaphore.tryAcquire();
//或
semaphore.tryAcquireAsync();
semaphore.tryAcquire(23, TimeUnit.SECONDS);
//或
semaphore.tryAcquireAsync(23, TimeUnit.SECONDS);
semaphore.release(10);
semaphore.release();
//或
semaphore.releaseAsync();
@GetMapping("/park")
@ResponseBody
public String park() {
RSemaphore park = redissonClient.getSemaphore("park");
try {
park.acquire(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "停进2";
}
@GetMapping("/go")
@ResponseBody
public String go() {
RSemaphore park = redissonClient.getSemaphore("park");
park.release(2);
return "开走2";
}
(5) 闭锁(CountDownLatch)
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(5); // 等待多少个
latch.await();
// 在其他线程或其他JVM里
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown(); // 计数减一
缓存和数据库一致性
问题:并发时,2写进入,写完DB后都写缓存。有暂时的脏数据
失效模式:写完数据库后,删缓存
问题:还没存入数据库呢,线程2又读到旧的DB了
解决:缓存设置过期时间,定期更新
解决:写数据写时,加分布式的读写锁。
解决方案:
如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式
缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心脏数据,允许临时脏数据可忽略);
总结:
我们不应该过度设计,增加系统的复杂性
遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。十二,SpringCache简化缓存开发
口来统一不同的缓存技术。并支持使用JCache(JSR-107)注解简化我们的开发
是否已经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就
调用方法并缓存结果后返回给用户。下次调用直接从缓存中获取。
2、从缓存中读取之前缓存存储的数据1) 依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-cacheartifactId>
dependency>
2) 配置
@EnableCaching
# #指定缓存类型为redis
spring.cache.type=redis
# 默认使用jdk进行序列化(可读性差),默认ttl为-1永不过期,自定义序列化方式需要编写配置类(毫秒)
spring.cache.redis.time-to-live=3600000
# 如果指定了前缀就用我们指定的前缀,如果没有就默认使用缓存的名字作为前缀
#spring.cache.redis.key-prefix=CHCHE_
# 是否设置前缀
spring.cache.redis.use-key-prefix=true
# 是否缓存空值,防止缓存穿透。
spring.cache.redis.cache-null-values=true
3)注释用法:
@Cacheable // 触发将数据保存到缓存的操作
@CacheEvict // 触发将数据从缓存删除的操作
@CachePut // 不影响方法执行更新缓存
@Caching // 组合以上多个操作
@CacheConfig // 在类级别共享缓存的相同配置
4) @Cacheable使用:
/**
* 1. 每一个需要缓存的数据我们都来指定要放到哪个名字的缓存。【缓存分区(按照业务类型分)】
* 2.@Cacheable({"category"}) // 代表当前方法的结果需要缓存,如果缓存中有,方法都不用调用。如果缓存中没有,会调用方法,最后将结果放到缓存中。
*
* 3.默认行为
* 1) 如果缓存中有,方法不用调用。
* 2) key默认自动生成 : 缓存的名字::SimpleKeyp[](自动生成的key值)。
* 3) 缓存的value的值,默认使用jdk序列化机制,将序列化后的数据保存得到redis
* 4) 默认ttl过期时间 -1(永不过期)
*
* 自定义:
* 1) 指定生成的缓存使用的key : key属性指定,接受一个spEL ---> key = "#root.methodName"
* 2) 指定缓存的数据的存活时间 : 配置文件写 spring.cache.redis.time-to-live=3600000
* 3) 将数据保存为 json 格式 : 需要自定义 RedisCacheConfiguration 配置。
*
* 底层原理:
* CacheAutoConfiguration -> RedisCacheConfiguration ->
* 自动配置了 RedisCacheManager ->初始化所有的缓存 -> 每个缓存决定使用什么配置
* -> 如果 RedisCacheConfiguration 有就用已有的,没有就用默认配置
* -> 想改变缓存的配置,只需要给容器中放一个 RedisCacheConfiguration 即可
* -> 就会应用到当前 RedisCacheManager 管理的所有缓存分区中
* @return
*/
// sync表示该方法的缓存被读取时会加锁 // value等同于cacheNames // key如果是字符串"''" // #root.methodName是当前方法名
@Cacheable(value = {"category"}, key = "#root.methodName")
@Override
public List<CategoryEntity> getLeve1Categorys() {
System.out.println("getLeve1Categorys...");
List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", 0));
return categoryEntities;
}
5)配置类 (解决json格式)
@Configuration
public class MyCacheConfig {
/**
* 配置文件中的东西没有用上:
*
* 1.原来和配置文件绑定的配置类是这样的
* @ConfigurationProperties(prefix = "spring.cache")
* public class CacheProperties {}
*
* 2.要让他生效
* ① @EnableConfigurationProperties(CacheProperties.class)
* ② CacheProperties cacheProperties -> CacheProperties.Redis redisProperties = cacheProperties.getRedis();
* @return
*/
@Bean
RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
// 指定缓存序列化方式为json
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
// 将配置文件中所有配置都生效
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
//设置配置文件中的各项配置,如过期时间
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
6) 缓存使用@Cacheable@CacheEvict
// 调用该方法时会将结果缓存,缓存名为category,key为方法名
// sync表示该方法的缓存被读取时会加锁 // value等同于cacheNames // key如果是字符串"''"
@Cacheable(value = {"category"},key = "#root.methodName",sync = true)
public Map<String, List<Catalog2Vo>> getCatalogJson() {
return getCategoriesDb();
}
//调用该方法会删除缓存category下的所有cache,如果要删除某个具体,用key="''"
@Override
@CacheEvict(value = {"category"},allEntries = true)
public void updateCascade(CategoryEntity category) {
this.updateById(category);
if (!StringUtils.isEmpty(category.getName())) {
categoryBrandRelationService.updateCategory(category);
}
}
7)SpringCache原理与不足
缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方案:加锁 ? 默认是无加锁的; 使用sync = true来解决击穿问题
缓存雪崩:大量的key同时过期。解决:加随机时间。加上过期时间:spring.cache.redis.time-to-live=3600000
引入Canal,感知到MySQL的更新去更新Redis
读多写多,直接去数据库查询就行
3.总结:十三,异步,线程池(复习)
1.初始化线程的4种方式
public class ThreadTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main...start...");
Thread thread = new Thread01();
thread.start();
System.out.println("main...end...");
}
public static class Thread01 extends Thread {
@Override
public void run() {
System.out.println("当前线程:" + Thread.currentThread().getId());
int i = 10 / 2 ;
System.out.println("运行结果:" + i);
}
}
}
public class ThreadTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main...start...");
Runable01 runable01 = new Runable01();
new Thread(runable01).start();
System.out.println("main...end...");
}
public static class Runable01 implements Runnable {
@Override
public void run() {
System.out.println("当前线程" + Thread.currentThread().getId());
int i = 10 / 2 ;
System.out.println("运行结果:" + i);
}
}
}
public class ThreadTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main...start...");
FutureTask<Integer> integerFutureTask = new FutureTask<>(new Callable01());
new Thread(integerFutureTask).start();
// 阻塞等待整个线程执行完成,获取返回结果
Integer integer = integerFutureTask.get();
System.out.println(integer);
System.out.println("main...end...");
}
public static class Callable01 implements Callable<Integer>{
@Override
public Integer call() throws Exception {
System.out.println("当前线程" + Thread.currentThread().getId());
int i = 10 / 2 ;
System.out.println("运行结果:" + i);
return i;
}
}
}
public class ThreadTest {
public static ExecutorService executorService = Executors.newFixedThreadPool(10);
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main...start...");
executorService.execute(new Runable01());
System.out.println("main...end...");
}
public static class Runable01 implements Runnable {
@Override
public void run() {
System.out.println("当前线程" + Thread.currentThread().getId());
int i = 10 / 2 ;
System.out.println("运行结果:" + i);
}
}
}
public class ThreadTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main...start...");
/**
* 七大参数:
* int corePoolSize:核心池大小[一直存在,除非(allowCoreThreadTimeOut)];线程池,创建好以后准备就绪的线程数量,就等待来接收异步任务。
* int maximumPoolSize:最大线程数量;控制资源
* long keepAliveTime:存活时间;如果当前的线程数量大于core数量。
* 释放空闲的线程(maximumPoolSize-corePoolSize)。只要线程空闲大于指定的keepAliveTime;
* TimeUnit unit:时间单位;
* BlockingQueue区别:
1,2 不能得到返回值,3可以获取返回值。
1,2,3 都不能控制资源。
4 可以控制资源,性能稳定。
2.CompletableFuture 异步编排
①.创建异步对象
public static ExecutorService executorService = Executors.newFixedThreadPool(10);
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main...start...");
/**
* 1.runxxx都是没有返回结果的
* 2.可以传入自定义的线程池,否则就使用默认的线程池
*/
CompletableFuture<Void> voidCompletableFuture = CompletableFuture.runAsync(() -> {
System.out.println("当前线程:" + Thread.currentThread().getId());
int i = 10 / 2;
System.out.println("运行结果:" + i);
}, executorService);
System.out.println("main...end...");
}
public static ExecutorService executorService = Executors.newFixedThreadPool(10);
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main...start...");
/**
* 1.supplyxxx都是可以获取返回结果的
* 2.可以传入自定义的线程池,否则就使用默认的线程池
*/
CompletableFuture<Integer> integerCompletableFuture = CompletableFuture.runAsync(() -> {
System.out.println("当前线程:" + Thread.currentThread().getId());
int i = 10 / 2;
System.out.println("运行结果:" + i);
return i;
}, executorService);
System.out.println("main...end...");
}
/**
* 方法完成后的感知
*/
CompletableFuture<Integer> integerCompletableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程:" + Thread.currentThread().getId());
int i = 10 / 0;
System.out.println("运行结果:" + i);
return i;
}, executorService).whenComplete((result,excption)->{
// 虽然能得到异常信息,但是没法修改返回数据。
System.out.println("异步任务完成了...结果是:"+result+";异常是:"+excption);
}).exceptionally(throwable -> {
// 可以感知异常,同时返回默认值。
// R apply(T t);
return 10;
});
/**
* 方法执行完成后的处理
*/
CompletableFuture<Integer> integerCompletableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程:" + Thread.currentThread().getId());
int i = 10 / 2;
System.out.println("运行结果:" + i);
return i;
}, executorService).handle((reslut,thr)->{
if (reslut != null) {
return reslut*2;
}
if (thr != null) {
return 0;
}
return 0;
});
② 线程串行化
/**
* 线程串行化
* 1),thenRunAsync: 不能获取到上一次的执行结果,无返回值:
* .thenRunAsync(() -> {
* System.out.println("任务2启动了");
* }, executorService);
*
* 2),thenAcceptAsync:能接受上一步结果,但是无返回值:
* .thenAcceptAsync((result)->{
* System.out.println("任务2启动了," + result);
* } ,executorService);
*
* 3),thenApplyAsync:能接受上一步结果,有返回值:
* .thenApplyAsync((result) -> {
* // R apply(T t);
* return "hello" + result;
* }, executorService);
* System.out.println("最终获取的结果" + stringCompletableFuture.get());
*/
③ 两任务组合,两个都要完成
/**
* 两任务组合 (两个任务必须都完成,触发该任务):
* 1):thenCombine:组合两个future,获取两个future的返回值,并返回当前任务的返回值。
* 2):thenAcceptBoth:组合两个future,获取两个future任务的返回结果,然后处理任务,没有返回值。
* 3):runAfterBoth:组合两个future,不需要获取future的结果,只需两个future处理完任务后,处理该任务。
*/
public static ExecutorService executorService = Executors.newFixedThreadPool(10);
public static void main(String[] args) throws ExecutionException, InterruptedException {
System.out.println("main...start...");
CompletableFuture<Integer> future01 = CompletableFuture.supplyAsync(() -> {
System.out.println("任务-1-当前线程:" + Thread.currentThread().getId());
int i = 10 / 2;
System.out.println("任务-1-运行结果:" + i);
return i;
}, executorService);
CompletableFuture<String> future02 = CompletableFuture.supplyAsync(() -> {
System.out.println("任务-2-当前线程:" + Thread.currentThread().getId());
System.out.println("任务-2-运行结束:");
return "hello";
}, executorService);
// 1)
/* future01.runAfterBothAsync(future02, ()->{
System.out.println("任务-3-开始");
}, executorService);*/
// 2)
/* future01.thenAcceptBothAsync(future02, (result1,result2)->{
// void accept(T t, U u);
System.out.println("任务-3-开始" + result1 + "-->" +result2);
}, executorService);*/
// 3)
CompletableFuture<String> future03 = future01.thenCombineAsync(future02, (result1, result2) -> {
// void accept(T t, U u);
// System.out.println("任务-3-开始" + result1 + "-->" +result2);
return result1 + ":" + result2 + "-> haha";
}, executorService);
System.out.println(future03.get());
}
④ 两个任务组合,一个完成
/**
* 两个任务组成,一个完成
* 当两个任务中,任意一个future任务完成的时候,执行任务。
*
* 1)applyToEither: 两个任务有一个执行完成,获取它的返回值,处理任务并有新的返回值。
* 2)acceptEither: 两个任务有一个执行完成,获取它的返回值,处理任务,没有新的返回值。
* 3)runAfterEither: 两个任务有一个执行完成,不需要获取future的结果,处理任务,也没有返回值。
*/
// 1)
future01.runAfterEitherAsync(future02, ()->{
System.out.println("任务-3-开始");
}, executorService);
// 2)
future01.acceptEitherAsync(future02, (result)->{
System.out.println("任务-3-开始" + result);
}, executorService);
// 3)
CompletableFuture<String> stringCompletableFuture = future01.applyToEitherAsync(future02, (result) -> {
System.out.println("任务-3-开始");
return result.toString() + "-> 嘻嘻";
}, executorService);
System.out.println("最后执行的结果" + stringCompletableFuture.get());
⑤多任务组合
/**
* 多任务组合
* 1)public static CompletableFuture allOf(CompletableFuture... cfs):等待所有任务完成。
* 2)public static CompletableFuture anyOf(CompletableFuture... cfs):只要有一个任务完成。
*/
CompletableFuture<String> futureImg = CompletableFuture.supplyAsync(() -> {
System.out.println("查询商品的图片信息");
return "hello.jpg";
}, executorService);
CompletableFuture<String> futureAttr = CompletableFuture.supplyAsync(() -> {
System.out.println("查询商品的属性");
return "黑色+256G";
}, executorService);
CompletableFuture<String> futureDesc = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(3000);
System.out.println("查询商品的介绍");
} catch (InterruptedException e) {
e.printStackTrace();
}
return "华为";
}, executorService);
// 1)
/*CompletableFuture3.springBoot自定义线程池
/**
* 自定义线程池
* @author smile
* @date 2022/4/25 15:11
*/
@Configuration
public class MyThreadConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor(ThreadPoolConfigProperties pool) {
return new ThreadPoolExecutor(pool.getCoreSize(),
pool.getMaxSize(),
pool.getKeepAliveTime(),
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100000),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
}
}
/**
* @author smile
* @date 2022/4/25 15:17
*/
@ConfigurationProperties(prefix = "gulimall.thread")
@Component
@Data
public class ThreadPoolConfigProperties {
private Integer coreSize;
private Integer maxSize;
private Integer keepAliveTime;
}
#自定义线程的属性
gulimall.thread.core-size=20
gulimall.thread.max-size=200
gulimall.thread.keep-alive-time=10
// 在哪里需要用线程池就注入
@Autowired
ThreadPoolExecutor threadPoolExecutor;
十四,短信服务
十五,密码加密储存
// 密码的加密储存
BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
// 对明文密码进行加密
String encode = passwordEncoder.encode(密码);
// 对密文进行判断是否一样
BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
boolean matches = passwordEncoder.matches(明文, 密文);
十六,社交登录(OAuth2.0)
(1) OAuth2.0
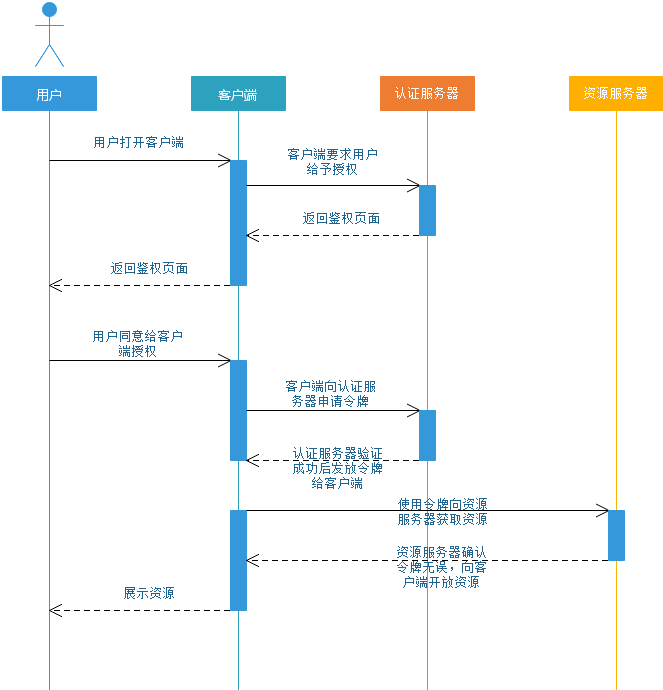
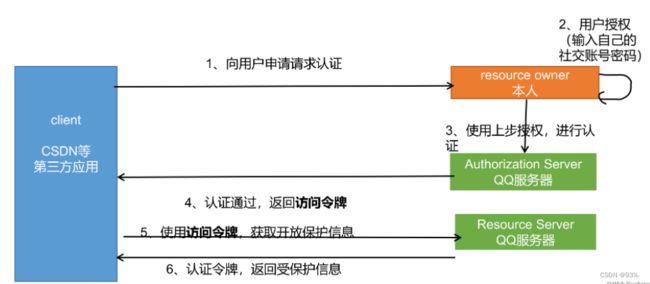
2、同一个用户的accessToken一段时间是不会变化的,即使多次获取十七,分布式Session



1)SpringSession整合redis
<dependency>
<groupId>org.springframework.sessiongroupId>
<artifactId>spring-session-data-redisartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
spring.session.store-type=redis
server.servlet.session.timeout=30m
spring.redis.host=192.168.124.132
@EnableRedisHttpSession
2) 扩大session作用域
@Configuration
public class GulimallSessionConfig {
@Bean // redis的json序列化
public RedisSerializer<Object> springSessionDefaultRedisSerializer() {
return new GenericJackson2JsonRedisSerializer();
}
@Bean // cookie
public CookieSerializer cookieSerializer() {
DefaultCookieSerializer serializer = new DefaultCookieSerializer();
serializer.setCookieName("GULISESSIONID"); // cookie的键
serializer.setDomainName("gulimall.com"); // 扩大session作用域,也就是cookie的有效域
return serializer;
}
}
3)SpringSession核心原理
/**核心原理:
1),@EnableRedisHttpSession 导入 RedisHttpSessionConfiguration配置
1.给容器中添加了一个组件
SessionRepository =>> 【RedisOperationsSessionRepository】=>> redis操作session。session 增删改查
2.SessionRepositoryFilter =>> Filter: session‘储存过滤器;每个请求过来都必须经过filter’
1.创建的时候,就自动从容器中获取到了SessionRepository;
2.在 SessionRepositoryFilter 的方法 doFilterInternal 中原始的request,response都被包装 成 -》
SessionRepositoryRequestWrapper,SessionRepositoryResponseWrapper
3.以后获取session。request.getSession();
4.wrappedRequest.getSession();===> SessionRepository 中获取的。
此行为称为 : 装饰者模式
*/
@Import({RedisHttpSessionConfiguration.class})
@Configuration( proxyBeanMethods = false)
public @interface EnableRedisHttpSession {
public class RedisHttpSessionConfiguration
extends SpringHttpSessionConfiguration // 继承
implements 。。。{
// 后面SessionRepositoryFilter会构造时候自动注入他
@Bean // 操作session的方法,如getSession() deleteById()
public RedisIndexedSessionRepository sessionRepository() {
public class SpringHttpSessionConfiguration
implements ApplicationContextAware {
@Bean
public <S extends Session> SessionRepositoryFilter<? extends Session> springSessionRepositoryFilter(SessionRepository<S> sessionRepository) { // 注入前面的bean
SessionRepositoryFilter<S> sessionRepositoryFilter = new SessionRepositoryFilter(sessionRepository);
sessionRepositoryFilter.setHttpSessionIdResolver(this.httpSessionIdResolver);
return sessionRepositoryFilter;
}
@Override // SessionRepositoryFilter.java
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain) {
request.setAttribute(SESSION_REPOSITORY_ATTR, this.sessionRepository);
//对原生的request、response进行包装
// SessionRepositoryRequestWrapper.getSession()
SessionRepositoryRequestWrapper wrappedRequest = new SessionRepositoryRequestWrapper(
request, response, this.servletContext);
SessionRepositoryResponseWrapper wrappedResponse = new SessionRepositoryResponseWrapper(
wrappedRequest, response);
try {
filterChain.doFilter(wrappedRequest, wrappedResponse);
}
finally {
wrappedRequest.commitSession();
}
}
十八,单点登录(SSO)
taobao.com和tianmao.com这种不同的域名也想共享session呢?sso思路

跳转到CAS server,即SSO登录系统,以后图中的CAS Server我们统一叫做SSO系统。 SSO系统也没有登录,弹出用户登录页。
用户填写用户名、密码,SSO系统进行认证后,将登录状态写入SSO的session,浏览器(Browser)中写入SSO域下的Cookie。
SSO系统登录完成后会生成一个ST(Service Ticket),然后跳转到app1系统,同时将ST作为参数传递给app1系统。
app1系统拿到ST后,从后台向SSO发送请求,验证ST是否有效。
验证通过后,app系统将登录状态写入session并设置app域下的Cookie。
至此,跨域单点登录就完成了。以后我们再访问app系统时,app就是登录的。接下来,我们再看看访问app2系统时的流程。
由于SSO已经登录了,不需要重新登录认证。
SSO生成ST,浏览器跳转到app2系统,并将ST作为参数传递给app2。
app2拿到ST,后台访问SSO,验证ST是否有效。
验证成功后,app2将登录状态写入session,并在app2域下写入Cookie。
这样,app2系统不需要走登录流程,就已经是登录了。SSO,app和app2在不同的域,它们之间的session不共享也是没问题的。SSO-Single Sign On
web-sample1:项目1 、8081 、client1.com
web-sample2:项目1 、8082 、client2.com
.其他系统都去【中央认证服务器】登录,登录成功后跳转回原服务
.一个系统登录,都登录;一个系统登出,都登出
.全系统统一一个sso-sessionId1.访问服务:SSO客户端发送请求访问应用系统提供的服务资源。
2.定向认证:SSO客户端会重定向用户请求到SSO服务器。
3.用户认证:用户身份认证。
4.发放票据:SSO服务器会产生一个随机的Service Ticket。
5.验证票据:SSO服务器验证票据Service Ticket的合法性,验证通过后,允许客户端访问服务。
6.传输用户信息:SSO服务器验证票据通过后,传输用户认证结果信息给客户端。
7.单点退出:用户退出单点登录。
十九,登录拦截器
/**
* c拦截器
* 在执行目标方法之前,判断用户的登录状态,并封装传递给controller目标请求
* @author smile
* @date 2022/4/29 14:13
*/
public class CartInterceptor implements HandlerInterceptor {
public static ThreadLocal<UserInfoTo> threadLocal = new ThreadLocal<>();
/**
* 业务执行之前
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
UserInfoTo userInfoTo = new UserInfoTo();
HttpSession session = request.getSession();
MemberRespVo memberRespVo = (MemberRespVo) session.getAttribute(AuthServerConstant.LOGIN_USER);
if (memberRespVo != null) {
// 用户登录
userInfoTo.setUserId(memberRespVo.getId());
}
Cookie[] cookies = request.getCookies();
if (cookies != null && cookies.length > 0) {
for (Cookie cookie : cookies) {
// user-key
String name = cookie.getName();
if (name.equals(CartConstant.TEMP_USER_COOKIE_NAME)) {
userInfoTo.setUserKey(cookie.getValue());
userInfoTo.setTempUser(true);
}
}
}
// 如果没有临时用户一定分配一个临时用户
if (StringUtils.isEmpty(userInfoTo.getUserKey())) {
String uuid = UUID.randomUUID().toString();
userInfoTo.setUserKey(uuid);
}
// 目标执行之前
threadLocal.set(userInfoTo);
return true;
}
/**
* 业务执行之后
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
UserInfoTo userInfoTo = threadLocal.get();
// 判断浏览器是否带有这个cookie,如果没有临时用户一定保存一个临时用户
if (!userInfoTo.isTempUser()) {
// 创建一个cookie
Cookie cookie = new Cookie(CartConstant.TEMP_USER_COOKIE_NAME, userInfoTo.getUserKey());
// 设置cookie的作用域
cookie.setDomain("gulimall.com");
// 设置cookie的过期时间
cookie.setMaxAge(CartConstant.TEMP_USER_COOKIE_TIMEOUT);
response.addCookie(cookie);
}
}
}
@Configuration
public class GulimallWebConfig implements WebMvcConfigurer {
/**
* 添加拦截器
* @param registry
*/
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new CartInterceptor()).addPathPatterns("/**"); // 这里创建了一个加入了上面的拦截器
}
}
二十,消息队列-MQ
1.MQ概述
搜索服务服务接收消息,去处理索引库。
如果以后有其它系统也依赖商品服务的数据,同样监听消息即可,商品服务无需任何代码修改。
1.2. AMQP和JMS

1.3. 常见MQ产品

2.RabbitMQ概述





2.1.安装RabbitMQ
docker run -d --name rabbitmq -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 25672:25672 -p 15671:15671 -p 15672:15672 rabbitmq:management
4369 – erlang发现口
5672 --client端通信口
25672 – server间内部通信口2.2测试

3,SpringBoot整合RabbitMQ
3.1配置
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
/**
* 使用RabbitMQ
* 1,引入amqp场景,RabbitAutoConfiguration就会自动生效
* 2. 给容器中自动配置了:CachingConnectionFactory,RabbitMessagingTemplate,AmqpAdmin
所有的属性都是 spring,rabbitmq
* @ConfigurationProperties(prefix = "spring.rabbitmq")
3.给配置文件中配置:spring.rabbitmq信息
* 4.@EnableRabbit
* 5.监听消息:使用 @RabbitListener;必须有 @EnableRabbit
* @RabbitListener(queues = {"监听队列"}):类+方法上(监听哪些队列)
* @RabbitHanbler:方法上(重载区分不同的消息)
*/
spring.rabbitmq.host=192.168.124.132
spring.rabbitmq.port=5672
spring.rabbitmq.virtual-host=/
/**
* RabbitMQ的配置类
* @author smile
* @date 2022/5/1 15:03
*/
@Configuration
public class MyRabbitConfig {
/**
* 使用JSON序列化机制,进行消息转换
* @return
*/
@Bean
// 1,消息类型转换器
public MessageConverter messageConverter() {
return new Jackson2JsonMessageConverter();
}
}
@EnableRabbit //主启动类上
3.2操作RabbitMQ
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class GulimallOrderApplicationTests {
@Autowired
private AmqpAdmin amqpAdmin;
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 1,如何创建Exchange[hello-java-exchange],Queue,Binding
* 1),使用AmqpAdmin进行创建
* 2.如何发收消息
* 2),RabbitTemplate
*/
/**
* 一。创建交换机(Exchange)
*/
@Test
public void contextLoads() {
// amqpadmin
// 声明一个交换机(Exchange)
/**
* DirectExchange(
* String name,名字
* boolean durable,是否持久化
* boolean autoDelete,是否自动删除
* Map// queues:声明需要监听的所有队列
@RabbitListener(queues = {"hello-java-queue"})
@Service("orderService")
public class OrderServiceImpl{
/**
* 五。消息接收
* 参数可以写一下类型
* 1.Message message:原生消息详细信息。头+体;
* 2.T<发送的消息的类型> OrderReturnReasonEntity entity;
* 3.Channel channel:当前传播数据的通道;
* @param entity
*/
@RabbitHandler
public void recieveMessage(Message messagem, OrderReturnReasonEntity entity, Channel channel) {
System.out.println("接收到的消息" + entity);
// 消息头属性消息
MessageProperties messageProperties = messagem.getMessageProperties();
}
}
4,消息确认机制-可靠抵达


4.1 开启 消息确认机制
/**
* 定制RabbitTemplate
* 1.服务收到消息就回调
* 1.spring.rabbitmq.publisher-confirms=true
* 2.设置确认回调 setConfirmCallback
* 2.消息正确抵达队列进行回调
* 1.spring.rabbitmq.publisher-returns=true
* spring.rabbitmq.template.mandatory=true
* 2.设置确认回调 setReturnCallback
*
* 3.消费者确认(保证每个消息被确认消费,此时才可以brober删除这个消息)。
* 1.默认是自动确认的,只要消息接收到,客户端会自动确认,服务器就会移除这个消息
* 问题:
* 我们收到很多消息,自动回复给客户端ack,只有一个消息处理成功,宕机了,发生消息丢失。
* 解决:
* 消费者手动确认模式。只要我们没有明确告诉MQ,货物被签收了,没有ack,
* 消息就一直是unacked状态。即使Consumer宕机。消息也不会丢失,会重新变为Ready,下次再继续使用。
* 2.如何签收:
* spring.rabbitmq.listener.direct.acknowledge-mode=manual
* channel.basicAck(deliveryTag, false); 签收;业务成功完成就应该签收。
* channel.basicNack(deliveryTag, false, true); 拒签;业务失败,拒签。
*
*/
##开启发送端确认
spring.rabbitmq.publisher-confirms=true
## 开启发送端消息抵达队列的确认
spring.rabbitmq.publisher-returns=true
## 只要抵达队列,以异步发送发送优先回调我们这个returnconfirm
spring.rabbitmq.template.mandatory=true
#手动ack消息(手动收到消息)
spring.rabbitmq.listener.direct.acknowledge-mode=manual
/**
* RabbitMQ的配置类
* @author smile
* @date 2022/5/1 15:03
*/
@Configuration
public class MyRabbitConfig {
@Autowired
RabbitTemplate rabbitTemplate;
/**
* 使用JSON序列化机制,进行消息转换
* @return
*/
@Bean
// 1,消息类型转换器
public MessageConverter messageConverter() {
return new Jackson2JsonMessageConverter();
}
@PostConstruct // MyRabbitConfig对象创建完成以后,执行这个方法
public void initRabbitTemplate() {
// 设置确认回调
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
/**
* @param correlationData 当前消息的唯一关联数据(这个是消息的唯一id)
* @param ack 消息是否成功收到
* @param cause 失败的原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
System.out.println("confirm...correlationData["+correlationData+"]==>ack["+ack+"]==>cause["+cause+"]");
}
});
// 设置消息抵达队列的确认回调(没有传递才执行这个代码)
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
/**
* 只要消息没有投递给指定的队列,就触发这个失败回调
* @param message 投递失败的消息详细信息
* @param replyCode 回复的状态码
* @param replyText 回复的文本内容
* @param exchange 当时这个消息发给哪个交换机
* @param routingKey 当时这个消息用哪个路由键
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("Fill Messaage["+message+"]=>replyCode["+replyCode+"]=>replyText["+replyText+"]=>exchange["+exchange+"]=>routingKey["+routingKey+"]");
}
});
}
}
/**
* 消息获取
*/
@RabbitHandler
public void recieveMessage(Message messagem,
OrderReturnReasonEntity entity,
Channel channel) {
System.out.println("接收到的消息" + entity);
// 消息头属性消息
MessageProperties messageProperties = messagem.getMessageProperties();
// chancel内按顺序自增的。
long deliveryTag = messagem.getMessageProperties().getDeliveryTag();
System.out.println("deliveryTag==>" + deliveryTag);
// 手动签收货物,非批量模式
try {
if (deliveryTag == 1) {
// 收货
// 第二个参数:是否批量签收
channel.basicAck(deliveryTag, false);
} else {
// 退货 requeue=false 丢弃 requeue=true 发回服务器,服务器重新入队。
// long deliveryTag, boolean multiple, boolean requeue
channel.basicNack(deliveryTag, false, true);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
2.MQ服务器不丢数据(消息持久化)
3.消费者确认消费掉消息(消费者确认机制)
2.消息确认模式
2.消费者的ACK机制。可以防止消费者丢失消息。二十一,分布式事务
@Transactional // 本地事务,在分布式系统,只能控制住自己的回滚,控制不了其他服务的回滚。
1.复习 本地事务
① 事务的基本性质

② 事务的隔离级别
该隔离级别的事务会读到其它未提交事务的数据,此现象也称之为脏读。
一个事务可以读取另一个已提交的事务,多次读取会造成不一样的结果,此现象称为不可重复读问题,Oracle 和 SQL Server 的默认隔离级别。
该隔离级别是 MySQL 默认的隔离级别,在同一个事务里,select 的结果是事务开始时时间点的状态,因此,同样的 select 操作读到的结果会是一致的,
但是,会有幻读现象。MySQL的 InnoDB 引擎可以通过 next-key locks 机制来避免幻读。
在该隔离级别下事务都是串行顺序执行的,MySQL 数据库的 InnDB 引擎会给读操作隐式加一把读共享锁,从而避免了脏读,不可重复读和幻读问题。③ 事务的传播行为
④ 本地事务失效问题
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-aopartifactId>
dependency>
@EnableAspectJAutoProxy(exposeProxy = true) //exposeProxy = true:对外暴露代理对象
本类 class = (本类) AopContext.currentProxy();
2.分布式事务
BASE

3.分布式事务4种方案
4.springCloud阿里提供了 seata
1)seata AT 使用说明:
1.每个微服务创建 UNDO_LOG 表:
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2.安装事务协调器:
3.整合使用:
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-seataartifactId>
<version>2.1.0.RELEASEversion>
dependency>
@GlobalTransactional 注解在业务方法上标记为大事务入口;每个远程调用标为小事务 @Transactional@GlobalTransactional // 全局事务
/**
* seata 的配置文件
* @author smile
* @date 2022/5/7 15:02
*/
@Configuration
public class MySeataConfig {
@Autowired
DataSourceProperties dataSourceProperties;
@Bean
public DataSource dataSource(DataSourceProperties dataSourceProperties) {
HikariDataSource dataSource = dataSourceProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build();
if (StringUtils.hasText(dataSourceProperties.getName())) {
dataSource.setPoolName(dataSourceProperties.getName());
}
return new DataSourceProxy(dataSource);
}
}
spring.application.name一致5,延迟队列MQ 场景


简单Bean创建例子:
/**
* 消息队列配置文件
* @author smile
* @date 2022/5/7 16:56
*/
@Configuration
public class MyMQConfig {
/**
* 把 Binding,Queue,Exchange 可以放到 @Bean 都会自动创建 (前提是 RabbitMQ没有)
* RabbitMQ 一旦创建好之后,修改这里的属性是不会发生变化。
*/
/**
* 延迟的队列
* @return
*/
@Bean
public Queue orderDelayQueue() {
/**
* 给队列设置3个属性
* x-dead-letter-exchange:order-event-exchange
* x-dead-letter-routing-key:order.release.order
* x-message-ttl:60000
*/
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange", "order-event-exchange");
arguments.put("x-dead-letter-routing-key", "order.release.order");
arguments.put("x-message-ttl", 60000);
// String name, boolean durable, boolean exclusive, boolean autoDelete, Map@RabbitListener(queues = "order.release.order.queue")
public void listener(OrderEntity entity, Channel channel, Message message) throws IOException {
System.out.println("收到过期信息:准备关闭订单" + entity.getOrderSn());
long deliveryTag = message.getMessageProperties().getDeliveryTag();
channel.basicAck(deliveryTag, false);
}
@ResponseBody
@GetMapping("/test/createOrder")
public String createOrderTest() {
// 下单成功
OrderEntity orderEntity = new OrderEntity();
orderEntity.setOrderSn("1888888");
orderEntity.setModifyTime(new Date());
// 给MQ发送消息
rabbitTemplate.convertAndSend(
"order-event-exchange",
"order.create.order",
orderEntity);
return "Ok";
}
项目案例:
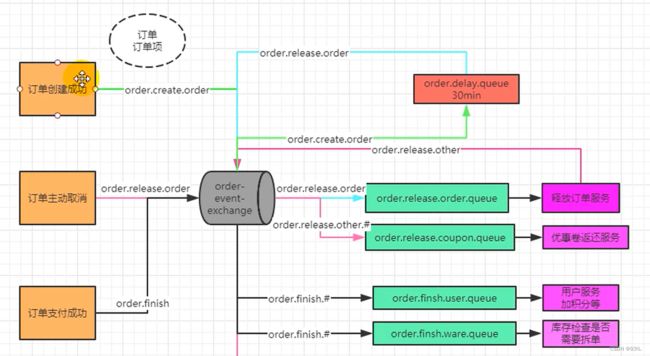



二十二,支付宝支付
使用支付宝开放平台的 沙箱
1.导入依赖
<dependency>
<groupId>com.alipay.sdkgroupId>
<artifactId>alipay-sdk-javaartifactId>
<version>4.9.28.ALLversion>
dependency>
2.配置类
@ConfigurationProperties(prefix = "alipay")
@Component
@Data
public class AlipayTemplate {
//在支付宝创建的应用的id
private String app_id = "2021000119610906";
// 商户私钥,您的PKCS8格式RSA2私钥
private String merchant_private_key = "你的私钥";
// 支付宝公钥,查看地址:https://openhome.alipay.com/platform/keyManage.htm 对应APPID下的支付宝公钥。
private String alipay_public_key = "你的公钥";
// 服务器[异步通知]页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问
// 支付宝会悄悄的给我们发送一个请求,告诉我们支付成功的信息
private String notify_url = "http://yoona.free.idcfengye.com/payed/notify"; // 内网穿透域名
// 页面跳转同步通知页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问
//同步通知,支付成功,一般跳转到成功页
private String return_url = "http://member.gulimall.com/memberOrder.html";
// 签名方式
private String sign_type = "RSA2";
// 字符编码格式
private String charset = "utf-8";
// 支付宝网关; https://openapi.alipaydev.com/gateway.do
private String gatewayUrl = "https://openapi.alipaydev.com/gateway.do";
public String pay(PayVo vo) throws AlipayApiException {
//AlipayClient alipayClient = new DefaultAlipayClient(AlipayTemplate.gatewayUrl, AlipayTemplate.app_id, AlipayTemplate.merchant_private_key, "json", AlipayTemplate.charset, AlipayTemplate.alipay_public_key, AlipayTemplate.sign_type);
//1、根据支付宝的配置生成一个支付客户端
AlipayClient alipayClient = new DefaultAlipayClient(gatewayUrl,
app_id, merchant_private_key, "json",
charset, alipay_public_key, sign_type);
//2、创建一个支付请求 //设置请求参数
AlipayTradePagePayRequest alipayRequest = new AlipayTradePagePayRequest();
alipayRequest.setReturnUrl(return_url);
alipayRequest.setNotifyUrl(notify_url);
//商户订单号,商户网站订单系统中唯一订单号,必填
String out_trade_no = vo.getOut_trade_no();
//付款金额,必填
String total_amount = vo.getTotal_amount();
//订单名称,必填
String subject = vo.getSubject();
//商品描述,可空
String body = vo.getBody();
alipayRequest.setBizContent("{\"out_trade_no\":\""+ out_trade_no +"\","
+ "\"total_amount\":\""+ total_amount +"\","
+ "\"subject\":\""+ subject +"\","
+ "\"body\":\""+ body +"\","
+ "\"product_code\":\"FAST_INSTANT_TRADE_PAY\"}");
String result = alipayClient.pageExecute(alipayRequest).getBody();
//会收到支付宝的响应,响应的是一个页面,只要浏览器显示这个页面,就会自动来到支付宝的收银台页面
System.out.println("支付宝的响应:"+result);
return result;
}
}
3.提交给支付宝的数据:
@Data
public class PayVo {
private String out_trade_no; // 商户订单号 必填
private String subject; // 订单名称 必填
private String total_amount; // 付款金额 必填
private String body; // 商品描述 可空
}
4.提交转到支付页
@Controller
public class PayWenController {
@Autowired
AlipayTemplate alipayTemplate;
@Autowired
OrderService orderService;
/**
* 1。将支付页让浏览器展示。
* 2.支付成功以后,我们要跳到用户的订单列表页。
* @param orderSn
* @return
* @throws AlipayApiException
*/
@ResponseBody
@GetMapping(value = "/payOrder", produces = "text/html")
public String payOrder(@RequestParam("orderSn") String orderSn) throws AlipayApiException {
PayVo payVo = orderService.getOrderPay(orderSn);
// 支付宝给我们返回的是一个页面,将此页面直接交给浏览器就行。
String pay = alipayTemplate.pay(payVo);
// System.out.println(pay);
return pay;
}
}
5.支付成功支付宝响应数据
@ToString
@Data
public class PayAsyncVo {
private String gmt_create;
private String charset;
private String gmt_payment;
private String notify_time;
private String subject;
private String sign;
private String buyer_id;//支付者的id
private String body;//订单的信息
private String invoice_amount;//支付金额
private String version;
private String notify_id;//通知id
private String fund_bill_list;
private String notify_type;//通知类型; trade_status_sync
private String out_trade_no;//订单号
private String total_amount;//支付的总额
private String trade_status;//交易状态 TRADE_SUCCESS
private String trade_no;//流水号
private String auth_app_id;//
private String receipt_amount;//商家收到的款
private String point_amount;//
private String app_id;//应用id
private String buyer_pay_amount;//最终支付的金额
private String sign_type;//签名类型
private String seller_id;//商家的id
}
@RestController
public class OrderPayListener {
@Autowired
OrderService orderService;
@Autowired
AlipayTemplate alipayTemplate;
@PostMapping("/payed/notify")
public String handleAlipayed(PayAsyncVo payAsyncVo, HttpServletRequest request) throws AlipayApiException, UnsupportedEncodingException {
// 只要我们收到了支付宝给我们异步的通知,告诉我们订单支付成功,返回success,支付宝再也不通知。
Map<String, String[]> parameterMap = request.getParameterMap();
for (String s : parameterMap.keySet()) {
String parameter = request.getParameter(s);
System.out.println("参数名:" + s + "===》参数值:" +parameter);
}
// 验签
Map<String,String> params = new HashMap<String,String>();
Map<String,String[]> requestParams = request.getParameterMap();
for (Iterator<String> iter = requestParams.keySet().iterator(); iter.hasNext();) {
String name = (String) iter.next();
String[] values = (String[]) requestParams.get(name);
String valueStr = "";
for (int i = 0; i < values.length; i++) {
valueStr = (i == values.length - 1) ? valueStr + values[i]
: valueStr + values[i] + ",";
}
//乱码解决,这段代码在出现乱码时使用
// valueStr = new String(valueStr.getBytes("ISO-8859-1"), "utf-8");
params.put(name, valueStr);
}
boolean signVerified = AlipaySignature.rsaCheckV1(params, alipayTemplate.getAlipay_public_key(), alipayTemplate.getCharset(), alipayTemplate.getSign_type()); //调用SDK验证签名
if (signVerified) {
// 签名验证成功
System.out.println("支付宝签名验证成功");
String result = orderService.handlePayResult(payAsyncVo);
return result;
} else {
System.out.println("支付宝签名验证失败");
}
return "error";
}
}
二十三,定时任务
1.生成时间表达式:
https://cron.qqe2.com/
2.简单整合springboot:
/**
* 定时任务
* 1.@EnableScheduling 开启定时任务
* 2.@Scheduled 开启一个定时任务(方法上)
* 3.自动配置类:TaskSchedulingAutoConfiguration.class
*
* 异步任务:
* 1.@EnableAsync :开启异步任务功能
* 2.@Async: 给希望异步执行的方法上标注(方法上)
* 3.自动配置类:TaskExecutionAutoConfiguration.class 属性绑定在 TaskExecutionProperties.class
*
* @author smile
* @date 2022/5/11 9:03
*/
@Slf4j
@Component
@EnableAsync
@EnableScheduling
public class HelloSchedule {
/**
* 1,Spring中6位组成,不允许第7位的年
* 2,在周几的位置,1-7代表周一到周日;
* 3,定时任务不应该阻塞。默认是阻塞的。
* 如何让他不进行阻塞:
* 1):可以让业务运行以异步的方式,自己提交到线程池:
* CompletableFuture.runAsync(()->{
* xxxxservice.hello();
* }, executors);
* 2):支持定时任务线程池:在配置文件中修改:spring.task.scheduling.pool.size=5
* 3):让定时任务异步执行:
*
* 解决:使用异步+定时任务来完成定时任务不阻塞的功能。
*/
@Async
@Scheduled(cron = "* * * ? * 3")
public void hello() throws InterruptedException {
log.info("hello...");
Thread.sleep(3000);
}
}
二十四,秒杀系统设计

二十五,SpringCloud Alibaba-Sentinel
1. 熔断 降级 限流

2.Sentinel整合springboot
① 导入依赖
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-sentinelartifactId>
dependency>
② 使用可视化界面
③ 配置控制台信息
spring.cloud.sentinel.transport.dashboard=localhost:8080
spring.cloud.sentinel.transport.port=8719
④ 每一个微服务都导入统计信息
<--信息省记模块-->
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
#暴露信息
management.endpoints.web.exposure.include=*
⑤自定义Sentinel 流控返回数据
/**
* Sentinel的配置类
* @author smile
* @date 2022/5/13 8:32
*/
@Configuration
public class SeckillSentinelConfig {
/**
* 自定义阻塞返回的方法
*/
public SeckillSentinelConfig() {
WebCallbackManager.setUrlBlockHandler(new UrlBlockHandler() {
@Override
public void blocked(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, BlockException e) throws IOException {
// TO_MANY_REQUEST( 10003,"请求流量过大"),
R error = R.error(BizCodeEnume.TO_MANY_REQUEST.getCode(), BizCodeEnume.TO_MANY_REQUEST.getMsg());
httpServletResponse.getWriter().write(JSON.toJSONString(error));
}
});
}
}
⑥ Sentinel来保护feign远程调用:熔断保护
spring-cloud-starter-alibaba-sentinel 的依赖外还需要 2 个步骤:√
#开启feign的sentinel功能
feign.sentinel.enabled=true
spring-cloud-starter-openfeign 依赖使 Sentinel starter 中的自动化配置类生效:√1.调用方
/**
* 远程调用秒杀服务
* @author smile
* @date 2022/5/11 16:43
*/
@FeignClient(value = "gulimall-seckil", fallback = SeckillFeignServiceFallBack.class)
public interface SeckillFeign {
/**
* 查询当前商品秒杀的信息
* @param skuId 商品id
* @return
*/
@GetMapping("/sku/seckill/{skuId}")
R getSkuSeckillInfo(@PathVariable("skuId") Long skuId);
}
/**
* 熔断调用的类
* @author smile
* @date 2022/5/13 9:33
*/
@Slf4j
@Component
public class SeckillFeignServiceFallBack implements SeckillFeign {
@Override
public R getSkuSeckillInfo(Long skuId) {
log.info("熔断方法调用...getSkuSeckillInfo");
// TO_MANY_REQUEST( 10003,"请求流量过大"),
return R.error(BizCodeEnume.TO_MANY_REQUEST.getCode(),BizCodeEnume.TO_MANY_REQUEST.getMsg());
}
}
2.远程服务
⑦ 自定义受保护的资源
1)方式一:代码
try (Entry entry = SphU.entry("SeckillSkus")) {
// 业务逻辑
} catch (BlockException e) {
log.error("资源被限流,{}", e.getMessage());
}
2)方式二:注解
// 如果下面的方法限流就调用这个方法
public List<SeckillSkuRedisTo> blockHandler(BlockException e) {
log.error("getCurrentSeckillSkusResource被限流了...");
return null;
}
/**
* blockHandler 函数会在原方法被限流/降级/系统保护的时候调用,而 fallback 函数会针对所有类型的异常。
*/
@SentinelResource(value = "getCurrentSeckillSkusResource", blockHandler = "blockHandler")
public void test() {
...
}
⑧ 网关流控
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-alibaba-sentinel-gatewayartifactId>
<version>2.1.0.RELEASEversion>
dependency>
二十六,Sleuth+Zipkin 服务链路追踪


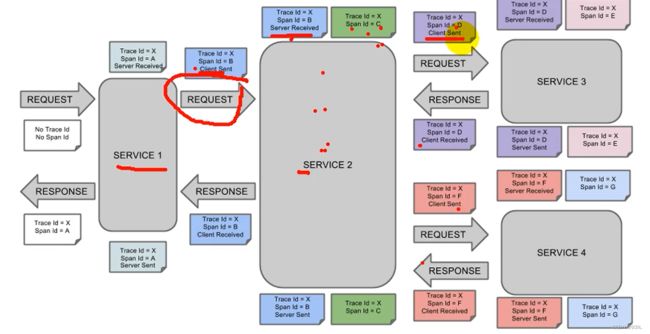
1. 整合 Sleuth
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
dependency>
#开启debug日志
logging.level.org.springframework.cloud.openfeign=debug
logging.level.org.springframework.cloud.sleuth=debug
2. 整合 zipkin 可视化观察
docker run -d -p 9411:9411 openzipkin/zipkin
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
# zipkin 配置
# zipkin服务器的地址
spring.zipkin.base-url=h192.168.124.132:9411/
# 关闭服务发现,否则spring cloud 会把zipkin的url当作服务名称
spring.zipkin.discovery-client-enabled=false
# 设置使用http的方式传输数据
spring.zipkin.sender.type=web
# 设置抽样采集器为100% 默认是0.1 即10%
spring.sleuth.sampler.probability=1
---------------------集群----------------------
一,k8s
1.创建3个虚拟机
vi /etc/ssh/sshd_config
下的
PasswordAuthentication no 改为 yes
重启:
2.设置linux环境
systemctl stop firewalld
systemctl disable firewalld
# linux默认的安全策略
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
swapoff -a #临时关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久关闭
free -g #验证,swap必须为0
hostname
添加主机名与ip对应关系
vi /etc/hosts
10.0.2.15 k8s-node1
10.0.2.7 k8s-node2
10.0.2.8 k8s-node3
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
然后应用:
sysctl --system
3.所有节点安装docker、kubeadm、kubelet、kubectl
1)安装Docker
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
#1.
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
# 2.设置docker repo的yum位置
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
# 3.安装docker,docker-cli
yum -y install docker-ce docker-ce-cli containerd.io
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://ke9h1pt4.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
systemctl enable docker
2) 添加阿里与Yum源
cat > /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
3)安装kubeadm,kubelet和kubectl
yum list|grep kube
yum install -y kubelet-1.17.3 kubeadm-1.17.3 kubectl-1.17.3
systemctl enable kubelet && systemctl start kubelet
systemctl status kubelet
[root@k8s-node2 ~]# kubelet --version
Kubernetes v1.17.3
4.部署k8s-master
1) master节点初始化
chmod 700 master_images.sh
#!/bin/bash
images=(
kube-apiserver:v1.17.3
kube-proxy:v1.17.3
kube-controller-manager:v1.17.3
kube-scheduler:v1.17.3
coredns:1.6.5
etcd:3.4.3-0
pause:3.1
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
done
kubeadm init\
--apiserver-advertise-address=10.0.2.15\
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers\
--kubernetes-version v1.17.3\
--service-cidr=10.96.0.0/16\
--pod-network-cidr=10.244.0.0/16
2) 测试Kubectl(主节点执行)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubeadm join 10.0.2.15:6443 --token 4rwjat.fvyisocnlww2xjtw \
--discovery-token-ca-cert-hash sha256:bbe377d1d35fe7e0663c0e9cbeab7e37ca356cded8798993c792543abee96585
5.安装POD网络插件(CNI)
kubectl apply -f \
https://raw.githubusercontent.com/coreos/flanne/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
kubectl get ns
kubectl get pods --all-namespaces
kubectl get nodes
k8s-node2”和“k8s-node3”上也执行这里命令:kubeadm join 192.168.124.131:6443 --token 5gh0fp.8ntr1y3cv8jf72w0 \
--discovery-token-ca-cert-hash sha256:911ade5fc04afab46ac746f237d20529f34655ab3796d904d4a820dcd7aa2245
# 在master执行
watch kubectl get pod -n kube-system -o wide
6. 加入kubenetes的Node节点
确保node节点成功:
token过期怎么办:kubeadm token create --print-join-command
kubeadm token create --ttl0 --print-join-command
7.入门操作kubernetes集群
1) 在主节点上部署一个tomcat
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8
kubectl get all
kubectl get pods -o wide
docker images
2) 暴露nginx访问
# tomcat镜像端口8080,转发到pod的80端口上,然后转发到虚拟机的XXX端口上(自动生成)
kubectl expose deployment tomcat6 --port=80 --target-port=8080 --type=NodePort
kubectl get svc
kubectl get svc -o wide
3) 动态扩容测试
kubectl get deployment
kubectl scale --replicas=3 deployment tomcat6
kubectl scale --replicas=2 deployment tomcat6
4)删除
kubectl delete deploye/nginx
kubectl delete service/nginx-service
8. K8s细节
1)、yaml输出
kubectl get pod web-pod-13je7 -o yaml
2).使用yaml暴露一个服务
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tomcat6
name: tomcat6
spec:
replicas: 3
selector:
matchLabels:
app: tomcat6
template:
metadata:
labels:
app: tomcat6
spec:
containers:
- image: tomcat:6.0.53-jre8
name: tomcat
kubectl apply -f tomcat6-deployment.yaml
kubectl expose deployment tomcat6 --port=80 --target-port=8080 --type=NodePort --dry-run -o yaml
1)、Ingress
通过Ingress controller实现POD负载均衡
支持TCP/UDP 4层负载均衡和HTTP 7层负载均衡
(1)部署Ingress controllerkubectl apply -f ingress-controller.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web
spec:
rules:
- host: tomcat6.kubenetes.com
http:
paths:
- backend:
serviceName: tomcat6
servicePort: 80
vi ingress-tomcat6.yaml
kubectl apply -f ingress-tomcat6.yaml
192.168.124.131 tomcat6.kubenetes.com
9、安装kubernetes可视化界面——DashBoard
kubectl apply -f kubernetes-dashboard.yaml
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 3001
selector:
k8s-app: kubernetes-dashboard
$ kubectl create serviceaccount dashboar-admin -n kube-sysem
$ kubectl create clusterrolebinding dashboar-admin --clusterrole=cluter-admin --serviceaccount=kube-system:dashboard-admin
$ kubectl describe secrets -n kube-system $( kubectl -n kube-system get secret |awk '/dashboard-admin/{print $1}' )
10.安装kubernetes
1) 安装helm
curl -L https://git.io/get_helm.sh|bash
tar xf helm-v2.17.0-linux-amd64.tar.gz
cp linux-amd64/helm /usr/local/bin
cp linux-amd64/tiller /usr/local/bin
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
kubectl apply -f helm-rbac.yaml
serviceaccount/tiller unchanged
clusterrolebinding.rbac.authorization.k8s.io/tiller created
helm init --service-account tiller --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.17.0 --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
kubectl get pods --all-namespace
serviceaccount/tiller unchanged
clusterrolebinding.rbac.authorization.k8s.io/tiller created
helm init --service-account tiller --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.17.0 --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
kubectl get pods --all-namespaces
2)安装 OpenEBS
kubectl get node -o wide
kubectl describe node k8s-node1 | grep Taint
kubectl taint nodes k8s-node1 node-role.kubernetes.io/master:NoSchedule-
kubectl create ns openebs
kubectl apply -f https://openebs.github.io/charts/openebs-operator-1.5.0.yaml
# 我记得这个版本会影响kubeSphere的版本,自己注意下就行,这个文件我那放了
kubectl apply -f openebs-operator-1.7.0.yaml
kubectl get sc
# 显示false和Delete正常
kubectl patch storageclass openebs-hostpath -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
11.安装kubesphere
kubectl apply -f kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
# 可以编辑devops为true
如果kubernetes版本是1.17.3就用下面这个下载:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
#使用如下命令监控
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
Start installing monitoring
Start installing multicluster
Start installing openpitrix
Start installing network
Start installing devops
**************************************************
Waiting for all tasks to be completed ...
task multicluster status is successful (1/5)
task network status is successful (2/5)
task openpitrix status is successful (3/5)
task devops status is successful (4/5) # 我自己开启了devops
task monitoring status is successful (5/5)
**************************************************
Collecting installation results ...
#####################################################
### Welcome to KubeSphere! ###
#####################################################
Console: http://192.168.56.100:30880
Account: admin
Password: P@88w0rd
NOTES:
1. After you log into the console, please check the
monitoring status of service components in
"Cluster Management". If any service is not
ready, please wait patiently until all components
are up and running.
2. Please change the default password after login.
#####################################################
https://kubesphere.io 2021-10-09 05:30:34
#####################################################
kubectl get pod --all-namespaces,查看所有 Pod 在 KubeSphere 相关的命名空间运行是否正常。如果是,请通过以下命令检查控制台的端口(默认为 30880),安全组需放行该端口定制选装组件
admin 身份登录控制台。点击左上角的平台管理 ,然后选择集群管理clusterconfiguration,点击搜索结果进入其详情页面。ks-installer 右侧的三个点,然后选择编辑 YAML。enabled 的 false 更改为 true,以启用要安装的组件。完成后,点击更新以保存配置。创建用户

创建项目
创建devops
二,DevOs


1.创建凭证
1.1 创建 dockerhub 凭证
1.2 创建 github 凭证
1.3 创建 kubeconfig 凭证

1.4 创建 SonarQube 凭证
kubectl get svc --all-namespaces # 获取所有名称空间的server


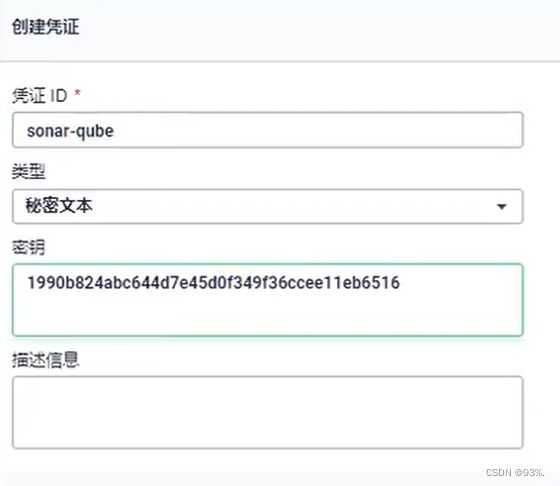
1.5