Redis进阶:图文讲解Redis底层数据结构之embstr,raw,ziplist,quicklist和hashtable (带源码讲解)
1 缘起
最近在补充Redis相关知识,
看到Redis数据库存储的数据对象结构,
发现Redis存储的数据实际类型是通过编码(encoding)标识的,
开发者看到的诸如string、hash、string、set和zset只是显式类型(方便记忆和使用),并不是实际存储类型,
每种显式类型都有对应的隐式实际类型,如embstr、raw、hashtable、ziplist、quicklist和skiplist,
Redis存储的数据是由redisObject结构体构成的,存储数据相关信息,
充分说明,自己动手,丰衣足食,当某种语言不提供需要的数据结构时,可以按需创造。
分享如下,帮助读者进一步了解Redis数据结构。
注意:
Redis版本:6.0.6
2 五种基础数据类型
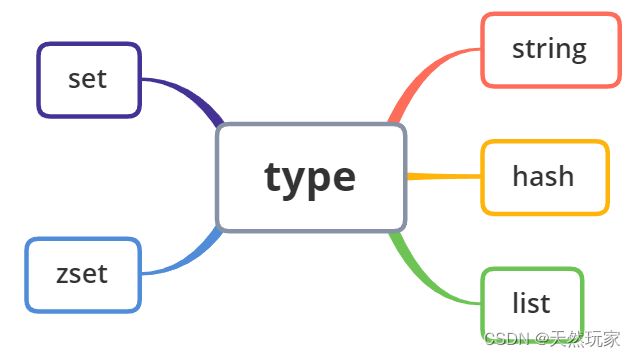
开发者常用的5种基础数据类型如下图所示,
为了方便记忆和使用,显示供给客户端用户使用。
3 redisObject结构体
Redis存储数据不是简单粗暴地直接使用C语言原始基础数据类型,
而是根据自身设计理念自定义存储对象(结构体),
Redis对象源码如下,由源码可知,Redis中的数据由5部分构成,分别为当前数据显式类型(type)、实际编码(encoding)、访问时间(lru,秒)、引用计数(refcount)和指向的实际数据(ptr),共计16字节。
位置:src/server.h
typedef struct redisObject {
unsigned type:4; // 4位=0.5字节
unsigned encoding:4; // 4位=0.5字节
unsigned lru:LRU_BITS; // 24位=3字节
int refcount; // 32位=4字节
void *ptr; // 64位=8字节
} robj;
| 序号 | 属性 | 描述 |
|---|---|---|
| 1 | type:4 | 对象类型 |
| 2 | encoding:4 | 对象编码 |
| 3 | lru:LRU_BITS | 对象最后一次访问时间(秒) |
| 4 | refcount | 引用计数。0:可被垃圾回收 |
| 5 | *ptr | 指向实际的数据存储结构 |
一个robj为16bytes(0.5byte+0.5+3bytes+4bytes+8bytes)
lru是24位,2^24-1=16,777,215
时间(/秒):194天=1942460*60=16,761,600
LRU最大194天一个轮回。
3.1 type
type即显式类型。
| 序号 | 类型 | 描述 |
|---|---|---|
| 1 | string | 字符串 |
| 2 | list | 列表 |
| 3 | hash | 哈希 |
| 4 | set | 集合 |
| 5 | zset | 有序集合 |
3.2 encoding
encoding即数据最终的存储类型,隐式类型。
每种显式类型,会根据不同的阈值在不同的隐式类型中切换。
| 序号 | 类型 | 描述 |
|---|---|---|
| 1 | int | 整数 |
| 2 | embstr | embstr编码的简单动态字符串(SDS) |
| 3 | raw | 简单动态字符串 |
| 4 | ht | 字典 |
| 5 | linkedlist | 双端链表 |
| 5 | ziplist | 压缩列表 |
| 5 | intset | 整数集合 |
| 5 | skiplist | 跳跃链表和字典 |
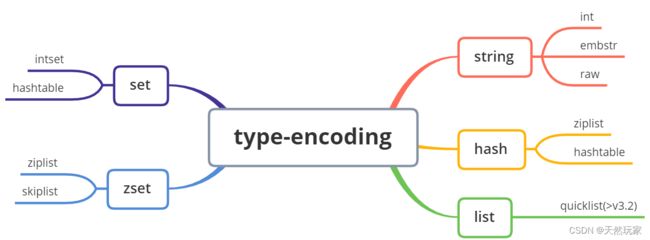
3.3 type与encoding对应关系
5种基础数据类型对应实际编码如下图所示。
3.4 数据转换条件
数据使用不同类型存储是有限制条件的,
不同条件下,使用不同的存储格式,
数据格式及对应条件如下表所示。
| 序号 | type | encoding |
|---|---|---|
| 1 | string | (1)int:值为整型,取值[-2^63-1, 2^63-1] (2)embstr:值不为整型或者整型值不在上述int范围内,且值长度小于等于44个字节 (3)raw:值超过44个字节(64-16-3-1=44) |
| 2 | list | quicklist(3.2版本前对应ziplist linkedlist)3.2版本后,list使用quicklist(ziplist和linkedlist组合) |
| 3 | hash | (1)ziplist:值个数在hash-max-ziplist-entries范围内或者值长度在hash-max-ziplist-value范围内 (2)hashtable:超过上述范围 |
| 4 | set | (1)intset:值为整型,取值[-2^63-1, 2^63-1] (2)hashtable:其他情况 |
| 5 | zset | (1)ziplist:值个数在zset-max-ziplist-entries范围内或者值长度在zset-max-ziplist-value范围内 (2)skiplist:超过上述情况 |
4 encoding类型
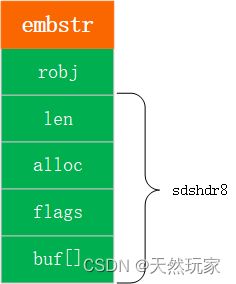
4.1 embstr
存储string类型。分配连续内存,性能较好,结构如下图所示。
4.1.1 sdshdr8源码
位置:src/sds.h
存储字符串数据是使用sdshdr8结构体,具体的数据存储在buf[]。
其中,len占1byte,alloc占1byte,flags占1byte,共3bytes。
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used:1byte */
uint8_t alloc; /* excluding the header and null terminator,1byte */
unsigned char flags; /* 3 lsb of type, 5 unused bits,1byte */
char buf[];
};
4.1.2 embstr转raw
当buf[]存储的数据超过44bytes后,转为raw,
- 计算方式:
44bytes=64bytes(jemalloc)-16bytes(robj)-3bytes(sdshdr8)-1('\0')
其中,jmealloc内存分配的空间为2/4/8/16/32/64bytes,按照64字节计算,留给buf[]的最大空间为44bytes。
由上文知:robj为16bytes,
源码知:sdshdr8固定内存为3bytes,其余留给buf[],
字符串最后一位:‘\0’,1byte。
留给buf[] 44(bytes)=64-16-3-1
- 源码
由源码知,字符串对象小于等于44字节,创建embstr字符串对象,否则,创建raw字符串对象。
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
4.1.3 创建embstr字符串对象源码
位置:src/object.c
由源码知,创建embstr字符串对象只分配一次空间,且是连续的。
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
4.2 raw
string类型。分配两次内存,一次分配robj,一次分配sdshdr8,内存不一定连续,性能低于embstr,但是,按照设计可存储更多的数据。
raw字符串对象结构如下图所示:

4.2.1 创建raw字符串对象源码
由源码可知,创建raw字符串对象调用sdsnewlen,这里会分配sds,所以,是两次内存分配:robj和sdshdr8。
位置:src/object.c
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
4.2.2 createObject源码
创建robj对象,第一次分配内存空间,源码如下。
位置:src/object.c
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution), or
* alternatively the LFU counter. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}
4.2.3 分配sdshdr8内存源码
由源码可知,通过s_malloc(hdrlen+initlen+1)分配sds内存空间,第二次分配内存空间。
位置:src/sds.c
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
sh = s_malloc(hdrlen+initlen+1);
if (sh == NULL) return NULL;
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
return s;
}
4.3 ziplist
ziplist是压缩列表。
可用于存储list(3.2版本之前)、hash和zset类型数据(元素在配置范围内)。
可以有序,也可无序。
存储list(3.2版本之前)和hash类型数据是无序的。
存储zset数据是有序的,元素和score分成两个节点存储,元素在前,score在后。
4.3.1 为什么使用ziplist
(1)节省空间:相对于数组为每个元素分配相同的空间而言,ziplist可以按实际大小分配(entry节点存储);
(2)随机访问效率高;
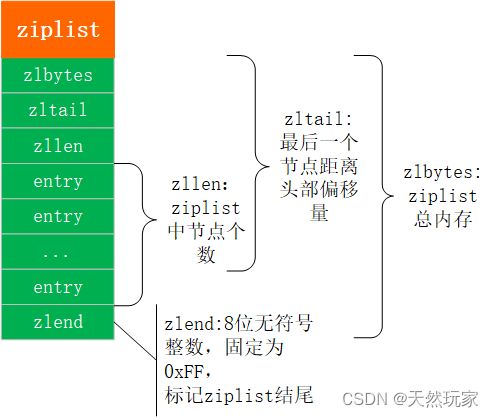
4.3.2 结构
ziplist结构如下图所示。
4.3.3 ziplist结构源码
ziplist上面的结构依据源码ziplist.c注释。
位置:src/ziplist.c
* ZIPLIST OVERALL LAYOUT
* ======================
*
* The general layout of the ziplist is as follows:
*
* <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
* EXAMPLES OF ACTUAL ZIPLISTS
* ===========================
*
* The following is a ziplist containing the two elements representing
* the strings "2" and "5". It is composed of 15 bytes, that we visually
* split into sections:
*
* [0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
* | | | | | |
* zlbytes zltail entries "2" "5" end
4.3.4 ziplist存储元素entry
ziplist中存储数据的结构为zlentry,源码如下,
由源码可知,entry存储空间不是固定的,
可根据存储的数据尺寸动态分配,
在一定程度上节约了内存空间。
位置:src/ziplist.c
typedef struct zlentry {
unsigned int prevrawlensize; /* 记录前一个节点内存(字节),<254字节,prerawlen为1字节,>254字节,prerawlen为5字节,会出现级联更新.*/
unsigned int prevrawlen; /* 前一个节点长度 */
unsigned int lensize; /* 记录当前节点类型/长度内存(字节),如string有1,2或5个字节,int只有1字节.*/
unsigned int len; /* 记录当前节点实际内存(字节). */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* 元素类型编码. */
unsigned char *p; /* 指向具体数据首地址的指针. */
} zlentry;
4.4 quicklist
quicklist是双向链表(linkedlist)和压缩列表(ziplist)组合的列表。
3.2版本之后list使用quicklist存储数据。
4.4.1 为什么使用quicklist
(1)双向链表(linkedlist)实现高效的插入和删除;
(2)压缩列表(ziplist)内存连续,减少内存碎片,访问效率高;
4.4.2 结构
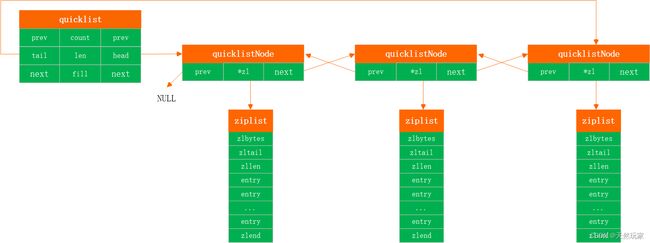
quicklist结构如下图所示。
这里说明:第一个节点的prev指向NULL(C语言中为不被引用的空间0),
quicklist的head指向第一个节点,tail指向最后一个节点,其余节点是双向连接的链表,
每个节点通过zl指向ziplist存储实际的数据。
4.4.3 quicklist源码
quicklist结构依据quicklist.h源码,
由源码可知,quicklist通过head和tail定位头结点和尾节点,
通过count记录当前list指向的ziplist数量。
len记录所有节点数。
位置:src/quiclist.h
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
4.4.4 quicllistNode源码
ziplist中节点结构源码如下,
由源码可知,quicklist的节点是双向链表,
有prev和next指针,
通过zl指针指向具体的数据存储单元ziplist。
位置:src/quicklist.h
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
4.5 hashtable
数组+链表组合。
存储key和value,
第一维:数组;
第二维:链表。
4.5.1 为什么使用
(1)渐进式rehash:保证操作效率;
(2)随机访问、插入和删除效率较高;
(3)对比string相对节约内存;
4.5.2 结构
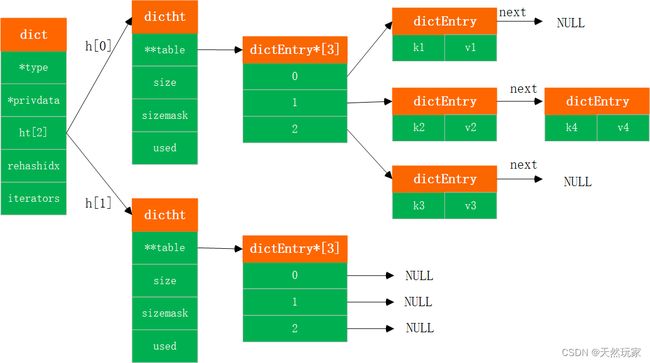
hashtable结构如下图所示,
由图可知,hashtable通过dict实现,
并且,每个dict中有两个hashtable结构,用于rehash,同时保证操作性能。
4.5.3 dict源码
hashtable通过dict实现,dict结构源码如下。
由源码可知,dict中通过数组(dictht)存储hashtable,且有两个hashtable元素,
rehashidx作为rehash标识,-1不进行rehash,0:开始rehash,结束后+1。
位置:src/dict.h
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
4.5.4 dictht源码
dictht存储hashtable数据,
其中,dictEntry是两层结构,第一层为数组,第二层为链表,
当hash(key)出现冲突时,将数据挂在链表上,
但是,数据变更时(避免链表化或者节约内存空间或者扩容),需要对hashtable进行扩缩容,由于Redis是单线程模型,
扩缩容涉及rehash,hashtable采用渐进式rehash,这也是为什么采用数组存储hashtable的原因,
数组中两个hashtable进行rehash轮换,查询时两个hashtable都会进行搜索。
rehash期间,每次对hashtable增删改时,操作h[0]外,同时将h[0]的键值对rehash到h[1]。
位置:src/dict.h
typedef struct dictht {
dictEntry **table;
unsigned long size; // hashtable尺寸
unsigned long sizemask;
unsigned long used; // 已有节点数量
} dictht;
4.5.5 dictEntry源码
hashtable实际的数据存储在dictEntry,源码如下。
位置:src/dict.h
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
4.5.6 缩容
hashtable尺寸大于初始尺寸并且使用率低于10%进行缩容。
- 缩容入口
由注释可知:当hashtable使用率为10%调整hashtable尺寸,以节约内存。
位置:src/server.c
/* If the percentage of used slots in the HT reaches HASHTABLE_MIN_FILL
* we resize the hash table to save memory */
void tryResizeHashTables(int dbid) {
if (htNeedsResize(server.db[dbid].dict))
dictResize(server.db[dbid].dict);
if (htNeedsResize(server.db[dbid].expires))
dictResize(server.db[dbid].expires);
}
- 判断hashtable是否要调整尺寸源码
由源码可知,hashtable尺寸大于初始尺寸并且使用率低于10%进行缩容。
位置:src/server.c
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
- 初始值配置源码
位置:src/dict.h
/* This is the initial size of every hash table */
#define DICT_HT_INITIAL_SIZE 4
- hashtable填充率源码
位置:src/server.h
/* Hash table parameters */
#define HASHTABLE_MIN_FILL 10 /* Minimal hash table fill 10% */
- 缩容次级入口源码
位置:dict.c
/* Resize the table to the minimal size that contains all the elements,
* but with the invariant of a USED/BUCKETS ratio near to <= 1 */
int dictResize(dict *d)
{
unsigned long minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal);
}
4.5.7 扩容
hashtable是否扩容依据配置的阈值判断,
使用空间大于等于总空间且比率(使用空间大于/总空间)大于等于5时扩容。
- 扩展阈值定义源码
位置:src/dict.c
/* Using dictEnableResize() / dictDisableResize() we make possible to
* enable/disable resizing of the hash table as needed. This is very important
* for Redis, as we use copy-on-write and don't want to move too much memory
* around when there is a child performing saving operations.
*
* Note that even when dict_can_resize is set to 0, not all resizes are
* prevented: a hash table is still allowed to grow if the ratio between
* the number of elements and the buckets > dict_force_resize_ratio. */
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5;
- 判断扩容私有方法_dictExpandIfNeeded源码
由源码可知,使用空间大于等于总空间且比率(使用空间大于/总空间)大于等于5时扩容。
位置:src/dict.c
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
- 扩容源码
位置:src/dict.c
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
5 小结
(1)基础数据类型是显式类型,不同的值属性会映射不同的Redis对象;
(2)embstr和raw存储字符串,embstr分配一次内存,raw分配两次内存,性能比raw好;
(3)ziplist压缩列表节省内存空间,但是会有级联更新的问题;
(4)quicklist组合双向链表和压缩列表,高效插入、删除,连续的存储空间,访问效率高;
(5)hashtable渐进式rehash,效率较一次rehash高,并且hashFunction(key)较string节约内存空间;
(6)hashtable缩容:尺寸大于初始尺寸(源码中配置为4)使用率小于10%,扩容:使用量大于总量且比率(使用量/总量)大于5。
【参考文献】
[1]https://github.com/redis/redis/tree/6.0/src
[2]Redis数据结构底层编码转换
[3]Redis底层数据结构之dict、ziplist、quicklist详解
[4]Redis 学习笔记(篇五):对象(RedisObject)
[5]redisObject详解
[6]Redis 内存耗尽的淘汰策略 LRU与LFU算法