Redis数据结构为什么既省内存又高效?Redis 数据类型 + 数据结构超全指南
Redis数据结构系列文章:
吃透Redis系列(一):redis之SDS字符串,到底高效在哪里?(全面分析)
吃透Redis系列(二):redis之intset整数集合,还是内存优化?
吃透Redis系列(三):redis压缩列表ziplist,内存优化之路?
吃透Redis系列(四):深入分析redis之quicklist,不一样的ziplist使用方式?
吃透Redis系列(五):深入分析redis之listpack,取代ziplist?
吃透Redis系列(六):redis 字典(dict)深入分析
吃透Redis系列(七):redis zskiplist跳表,性能堪比红黑树?
吃透Redis系列(八):深入分析redis之rax底层原理,前缀树?
吃透Redis系列(九):redis HyperLogLog,看这篇就够了
文章目录
- 前言
- 一、数据结构篇
-
- 基础数据结构
-
- 1、简单字符串 sds
- 2、整数集合 intset
- 3、压缩列表 ziplist
- 4、快速列表 quicklist
- 5、listpack
- 6、hash 字典
- 7、skiplist 跳表
- 其他数据结构
-
- 1、前缀树 rax
- 二、数据类型篇
-
- 基础数据类型
-
- 1、String
- 2、List
- 3、Set
- 4、zset
- 5、Hash
- 高级数据类型
-
- 1、Stream
- 2、HyperLogLog
- 3、BitMap
- 4、Geo
- 写在最后
前言
本文参考源码版本
redis6.2
常见 redis 数据结构全景图:
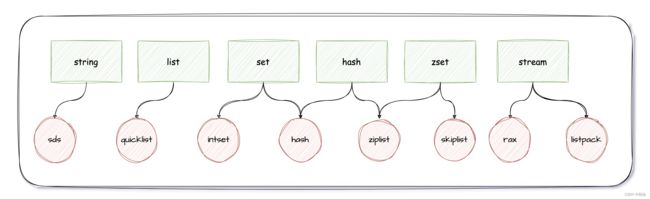
Redis 数据结构为什么既高效又节省内存?
永恒的问题 ------ 空间与时间的较量
1)节省内存:
- 一般通过特定的编码约定,将数据进行压缩,比如 ziplist、quicklist、listpack …,
- 还有,比如一些只包含数字的字符串可以通过 int 来存储(int 通常有 2字节、4字节、8字节) ,对应 redis 的 intset 结构 …
- 另外,把大家可能都有的部分抽取出来公用也是一种手段,比如 radix 前缀树、共享对象 …
- 概率统计,典型的 HyperLogLog 结构,甭管你有多少元素(2^64 内),用 12 Kb 内存就能统计出大致的去重总数量
- …
对内存这般压榨,你懂的,一般需要更多的时间消耗,所以很多这种结构可能都需要限制:单个元素的长度啊、元素个数啊等 …
2)高效(一般是增删查改的效率)
- 空间换时间:比如跳表(skiplist),多一些内存消耗换来二分法 log(N) 的效率
- SDS 结构,string 类型的底层数据结构,sds 在 redis 应用十分广泛,通过记录字符串长度、预分配空间等优化来减少遍历、内存重分配等提升效率
- 计算结果缓存,比如 HyperLogLog,每次计算要扫描12K空间,然后通过一个复杂的公式计算。索性就把计算结果存下来,只要没有更新过,原计算就过就有效。
- …
追求高效性的同时,会牺牲一些空间消耗。
王炸?
为了吸收两者的优点,redis 想了个办法 ------ 将两者组合使用,比如 hash 数据类型,当数量小的时候使用 ziplist 结构,数据多了就用 hashtable 结构 …
redis 内部很多这样的组合方式,以后别人问你 hash 数据类型底层结构是怎样的?就不是回答简答的字典了
一、数据结构篇
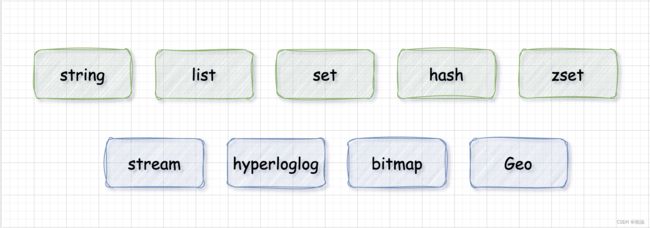
截止目前 redis 底层使用的八种数据结构:
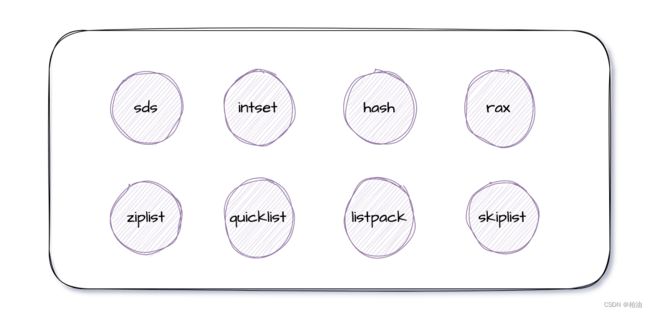
基础数据结构
1、简单字符串 sds
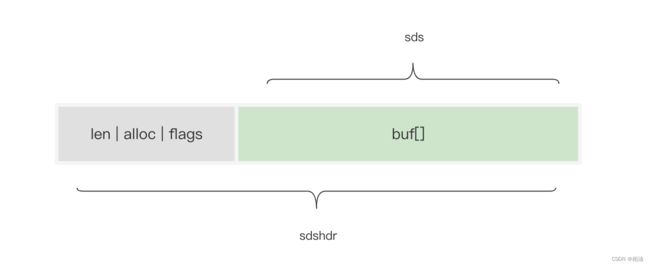
在大多数情况下,redis 使用 SDS(Simple Dynamic String,简单动态字符串)作为字符串表示。
比起 C 字符串,SDS 具有以下优点:
- 常数复杂度获取字符串长度。
- 杜绝缓冲区溢出。
- 减少修改字符串长度时所需的内存重分配次数。
- 二进制安全。
- 兼容部分C字符串函数。
redis之SDS字符串,到底高效在哪里?(全面分析)
2、整数集合 intset
整数集合(intset)是一个有序的、存储整型数据的结构。我们知道 redis 是一个内存数据库,所以必须考虑如何能够高效地利用内存。
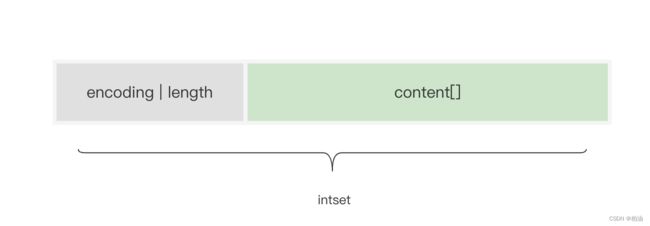
组成字段含义:
-
encoding:编码类型,决定每个元素占用几个字节
- int16_t:每个元素占 2 个字节。
- int32_t:每个元素占 4 个字节。
- int64_t:每个元素占 8 个字节
-
length:元素个数。即一个 intset 中包括多少个元素。
-
contents:存储具体元素。根据 encoding 字段决定多少个字节表示一个元素。
使用条件?
当 redis 集合类型的元素都是整数并且都处在64位有符号整数范围之内时,使用该结构体存储。
redis之intset整数集合,还是内存优化?
3、压缩列表 ziplist
ziplist 的最大特点,是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,以达到节省内存的目的。
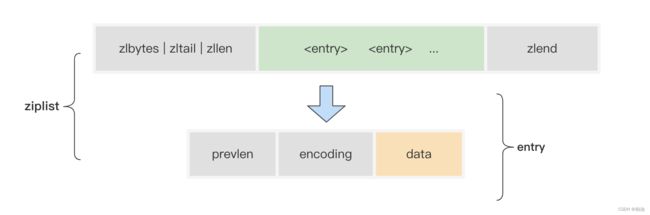
其中,ziplist 组成:
- zlbytes: zl 列表总字节数,32bits
- zltail: zl 列表最后一个 entry 的指针,32bits
- zllen: zl 列表 entry 总数,16bits
- entry: zl 列表元素
- zlend: zl 列表结束标志,8bits
ziplist 中元素 entry 包括三部分内容:
- prevlen:前一项的长度。方便快速找到前一个元素地址,如果当前元素地址是 x,(x-prelen) 则是前一个元素的地址
- encoding:当前项长度信息的编码结果
- data:当前项的实际存储数据
redis压缩列表ziplist,内存优化之路?
4、快速列表 quicklist
quicklist 是 redis 底层最重要的数据结构之一,它是 redis 对外提供的 5 种基本数据结构中 list 的底层实现,在 redis 3.2 版本中引入。
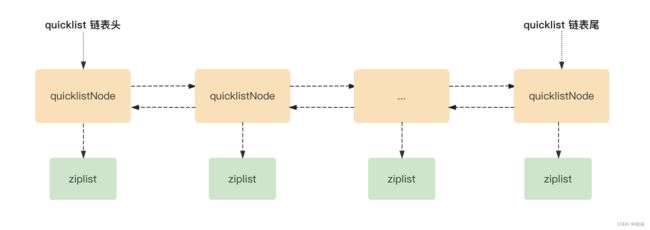
如上图,本质来说,quicklist 是一个链表结构,每一个链表节点都是 ziplist 类型,这就可以避免单个 ziplist 过大的情况,是 ziplist 结构的进一步演变.
在引入 quicklist 之前,redis 采用压缩链表(ziplist)以及双向链表(linked-list)作为 list 的底层实现。
- 当元素个数比较少并且元素长度比较小时,redis 采用 ziplist 作为其底层存储。
- 当任意一个条件不满足时,redis 采用 linked-list 作为底层存储结构。
这么做的主要原因是,当元素长度较小时,采用 ziplist 可以有效节省存储空间,但 ziplist 的存储空间是连续的,当元素个数比较多时,修改元素时,必须重新分配存储空间,这无疑会影响 redis 的执行效率,故而采用一般的双向链表。
quicklist 是综合考虑了时间效率与空间效率引入的新型数据结构,它的出现,逐渐替代了双端列表,在 redis 的较高版本中,双端列表已经不再使用。
深入分析redis之quicklist,不一样的ziplist使用方式?
5、listpack
从 ziplist 到 quicklist,再到 listpack 结构,你可以看到,其初衷都是设计一款能够高效使用内存的数据结构。
ziplist 设计出的紧凑型数据块可以有效利用内存,但在更新上,由于每一个 entry 都保留了前一个 entry 的 prevlen 长度,因此在插入或者更新时可能会出现连锁更新,这是一个影响效率的大问题。
因此,接着又设计出 「链表 + ziplist」组成的 quicklist 结构来避免单个 ziplist 过大,可以有效降低连锁更新的影响面。
但 quicklist 本质上不能完全避免连锁更新问题,因此,又设计出与 ziplist 完全不同的内存紧凑型结构 listpack。
listpack 也叫紧凑列表,它的特点就是用一块连续的内存空间来紧凑地保存数据,同时为了节省内存空间,listpack 列表项使用了多种编码方式,来表示不同长度的数据,这些数据包括整数和字符串。
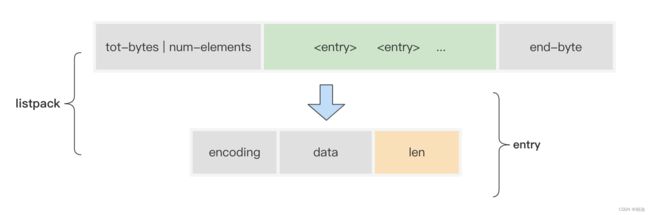
listpack 由 4 部分组成:total Bytes、Num Elem、Entry 以及 End
- Total Bytes 为整个 listpack 的
空间大小,占用 4 个字节,每个 listpack 最多占用4294967295 Bytes。 - Num Elem 为 listpack 中的
元素个数,即 Entry 的个数,占用 2 个字节,值得注意的是,这并不意味着 listpack 最多只能存放 65535 个Entry,当 Entry 个数大于等于 65535 时,Num Elem 被设置为 65535,此时如果需要获取元素个数,需要遍历整个 listpack。 - Entry 为每个具体的元素。
- End 为 listpack 结束标志,占用 1 个字节,内容为 0xFF。
每一个 entry 包含三部分内容:
- encoding:当前元素的编码类型(encoding)
- data:元素数据 (data)
- len:编码类型和元素数据这两部分的长度 (len)。
redis 源码对于 listpack 的解释为 A lists of strings serialization format,一个序列化格式的字符串列表,也就是将一个字符串列表进行序列化存储。redis listpack 可用于存储字符串或者整型。
深入分析redis之listpack,取代ziplist?
6、hash 字典
字典又称散列表,是用来存储键值(key-value)对的一种数据结构,在很多高级语言中都有实现,如 PHP 的数组。
但是 C 语言没有这种数据结构,Redis 是 K-V 型数据库,整个数据库是用字典来存储的,对 Redis 数据库进行任何增、删、改、查操作,实际就是对字典中的数据进行增、删、改、查操作。
redis 字典实现依赖的数据结构主要包含了三部分:字典、hash表、hash表节点。
字典中嵌入了两个 hash 表,hash 表中的 table 字段存放着 hash 表节点,hash 表节点对应存储的是键值对。
整体结构如下:
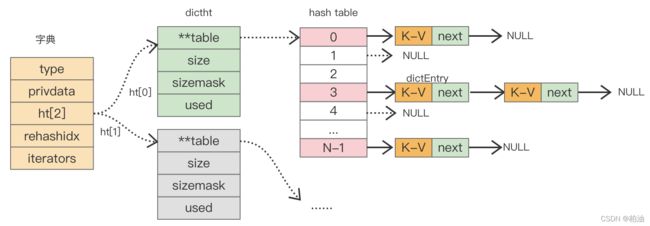
更多细节分析参考下方链接:
redis 字典(dict)深入分析
7、skiplist 跳表
跳表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单,所以有不少程序都使用跳跃表来代替平衡树。
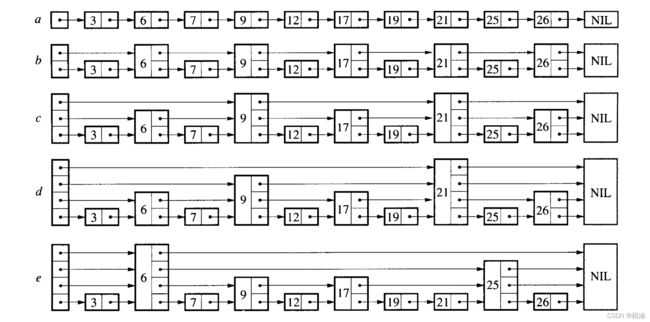
以上 a、b、c、d、e 跳表的五种形态;当然,远不止这几种情况;因为,它的结构在实现上有随机性。
跳表插入路径图(搜索):
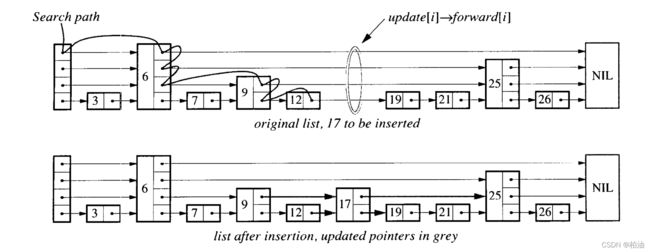
redis zskiplist跳表,性能堪比红黑树?
其他数据结构
1、前缀树 rax
Radix Tree 是属于前缀树的一种类型。前缀树也称为 Trie Tree,其特点是,保存在树上的每个 key 会被拆分成单字符,然后逐一保存在树上的节点中。
前缀树的根节点不保存任何字符,而除了根节点以外的其他节点,每个节点只保存一个字符。当把从根节点到当前节点的路径上的字符拼接在一起时,就可以得到相应 key 的值了。
rax 在前缀树上做了一些优化,每个节点上可以存储一串字符串,从而减少空间的浪费。
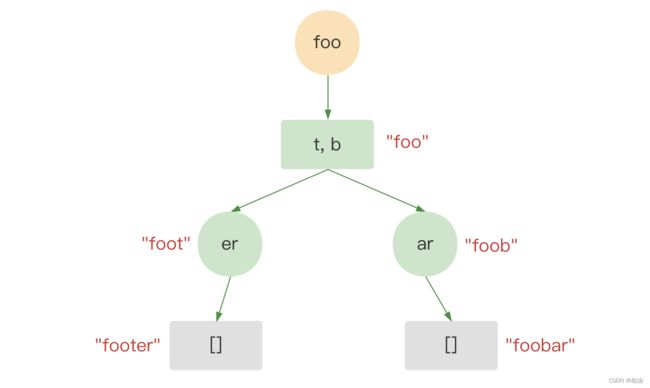
如上图,rax 最大的特点是会对前缀树做压缩,避免空间浪费。
深入分析redis之rax底层原理,前缀树?
二、数据类型篇
redis 有五大常用数据类型,分别是 string、list、set、zset 和 hash,除此之外,你还知道哪些?
基础数据类型
1、String
String 类型是最常用也是最基本的数据类型,你可以存储 连续的字节、文本、序列化对象,甚至是二进制数组等。
另外,还支持一些额外的附加操作,比如 你可以用来计数、位操作 …
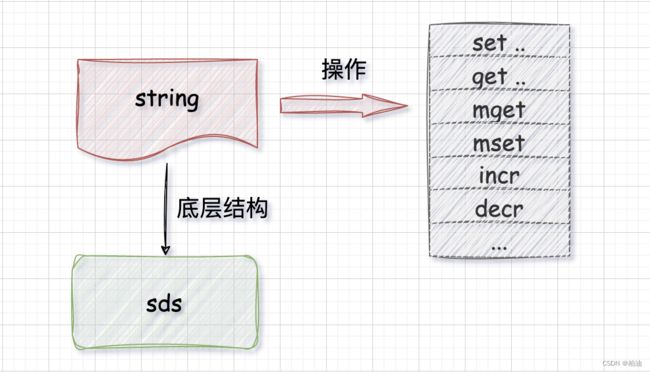
✍️ 例子:
- ✅ 存储字符串:
> SET user:1 salvatore
OK
> GET user:1
"salvatore"
- ✅ 存储 JSON 序列化对象:
> SET ticket:27 "\"{'username': 'priya', 'ticket_id': 321}\"" EX 100
- ✅ 计数器递增:
> INCR views:page:2
(integer) 1
> INCRBY views:page:2 10
(integer) 11
限制?
默认情况下,单个 String 长度限制为 512 MB
底层结构?
String 类型底层采用的是 SDS 数据结构。
2、List
redis 常用的数据类型,可以是一个普通列表,也可以把他当成一个队列、栈来使用,具体的表现形态,可以根据不同的操作进行组合。
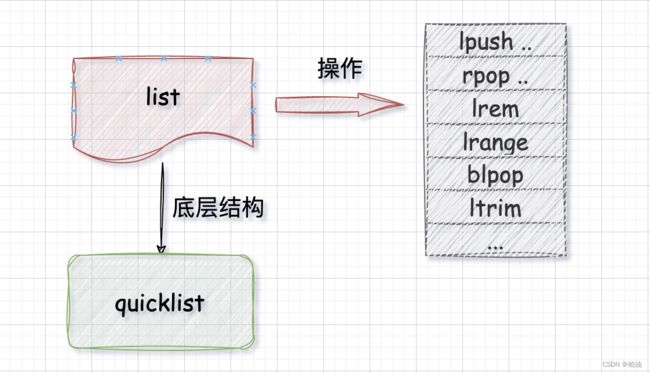
✍️ 例子:
- ✅ 先进先出(FIFO,像一个队列)
> LPUSH work:queue:ids 101
(integer) 1
> LPUSH work:queue:ids 237
(integer) 2
> RPOP work:queue:ids
"101"
> RPOP work:queue:ids
"237"
- ✅ 先进后出(类似于栈结构)
> LPUSH work:queue:ids 101
(integer) 1
> LPUSH work:queue:ids 237
(integer) 2
> LPOP work:queue:ids
"237"
> LPOP work:queue:ids
"101"
- ✅ 队列长度:
> LLEN work:queue:ids
(integer) 0
- ✅ 原子性的从一个列表移动到另一个列表:
> LPUSH board:todo:ids 101
(integer) 1
> LPUSH board:todo:ids 273
(integer) 2
> LMOVE board:todo:ids board:in-progress:ids LEFT LEFT
"273"
> LRANGE board:todo:ids 0 -1
1) "101"
> LRANGE board:in-progress:ids 0 -1
1) "273"
列表长度限制?
最多支持 2^32 - 1 个元素,即 4,294,967,295
底层结构?
redis 早期版本中,使用了双向列表和压缩列表,在笔者使用的版本中(redis6.2)底层只使用了快速列表(quicklist)
3、Set
Set 是一个无序(相对于插入顺序)的去重集合,你可以用它来去重、找交集/并集 …
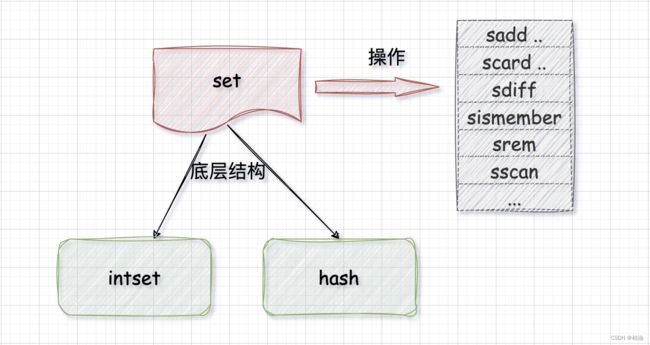
✍️ 例子:
- ✅ 我们先给用户 123、456 分别初始化一个最喜欢看的书籍列表(id):
> SADD user:123:favorites 347
(integer) 1
> SADD user:123:favorites 561
(integer) 1
> SADD user:123:favorites 742
(integer) 1
> SADD user:456:favorites 561
(integer) 1
- ✅ 接着,我们看看用户 123 是否喜欢 742、299 这两本书:
> SISMEMBER user:123:favorites 742
(integer) 1
> SISMEMBER user:123:favorites 299
(integer) 0
- ✅ 然后,我们看看用户 123、456 是否有共同喜欢的书籍:
> SINTER user:123:favorites user:456:favorites
1) "561"
- ✅ 最后,我们看看用户 123 有多少本喜欢的书籍:
> SCARD user:123:favorites
(integer) 3
限制?
最多允许存储 2^32 - 1 个元素,即 4,294,967,295
底层结构?
在空间和效率方面的角逐,底层采用 字典(hash)和 整数集合(intset)
当集合中的元素全是整数(long)时,使用 intset,出现非 long 数据时 将从 intset 转换为 hash 字典。
注:整数类型有 int2、int4、int8 几种,分别占用 2字节、4字节 和 8字节。 一般情况下,使用整形比字符串更加节省空间,比如 65535,用 2字节整型就能存储,而字符串存储的话需要 5字节。
4、zset
全称是 sorted sets,和 Set 类型类似,也是去重集合,从这个角度看,zset 就像是 Set 类型的升级版。
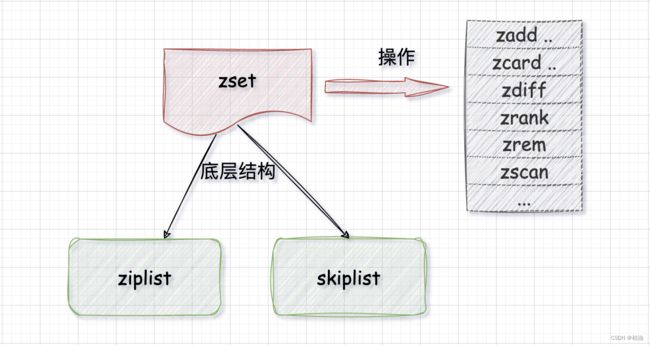
zset 类型最大的特点就是可以根据 score 进行排序,当成员的 score 出现相同时,则按成员的字母顺序。
zset 典型的用法有:
- 延时队列,用时间戳做 score,排在前面的最先过期,也就可以最先处理。
- 限流器:通过 zset 记录请求明细,并通过滑动窗口删除和新增明细来控制流量。
- 排行榜:游戏、竞赛等实时排名大盘
- …
✍️ 例子:
- ✅ 更新游戏玩家排行榜:
> ZADD leaderboard:455 100 user:1
(integer) 1
> ZADD leaderboard:455 75 user:2
(integer) 1
> ZADD leaderboard:455 101 user:3
(integer) 1
> ZADD leaderboard:455 15 user:4
(integer) 1
> ZADD leaderboard:455 275 user:2
(integer) 0
对于 zset 中已经存在的成员,比如 user:2,会更新其 score。
- ✅ 获取排行榜 top:
> ZRANGE leaderboard:455 0 2 REV WITHSCORES
1) "user:2"
2) "275"
3) "user:3"
4) "101"
5) "user:1"
6) "100"
- ✅ 获取用户
user:2的排名:
> ZREVRANK leaderboard:455 user:2
(integer) 0
底层结构?
同样的,在空间和效率之间抉择,zset 底层采用了 跳表(skiplist) 和 压缩列表(ziplist)
zset 底层默认使用 ziplist 结构,当达到一定条件之后,转化为 skiplist 结构,条件如下:
- zset-max-ziplist-entries:128
- zset-max-ziplist-value:64
即当列表元素个数大于 128 或者列表元素 size 大于 64 时,zset 会使用 skiplist 结构;反之会使用 ziplist 结构。
注:压缩列表比较节省空间,在数量少的时候使用非常划算。跳表的重点放在了查询效率上,会牺牲一点空间,比较适合元素较多的场景。
5、Hash
字典,是一种 field - value 的数据组织形式,在 redis 中十分常用。最典型的是 redis 数据库,其本身就是一个大的字典表。
✍️ 例子:
- ✅ 用来记录一个人的基本信息:
> HSET user:123 username martina firstName Martina lastName Elisa country GB
(integer) 4
> HGET user:123 username
"martina"
> HGETALL user:123
1) "username"
2) "martina"
3) "firstName"
4) "Martina"
5) "lastName"
6) "Elisa"
7) "country"
8) "GB"
- ✅ 用作各种指标计数器:
> HINCRBY device:777:stats pings 1
(integer) 1
> HINCRBY device:777:stats pings 1
(integer) 2
> HINCRBY device:777:stats pings 1
(integer) 3
> HINCRBY device:777:stats errors 1
(integer) 1
> HINCRBY device:777:stats requests 1
(integer) 1
> HGET device:777:stats pings
"3"
> HMGET device:777:stats requests errors
1) "1"
2) "1"
效率?
大部分操作都是 O(1),不过也存在一些 O(N)操作,比如 HKEYS、HVALS 以及 HGETALL。
限制?
一个 hash 字典最多允许存储 4,294,967,295 (2^32 - 1) 个 field-value 对,当然,这已经足够大了,通常情况下,你的内存可能最先达到上限。
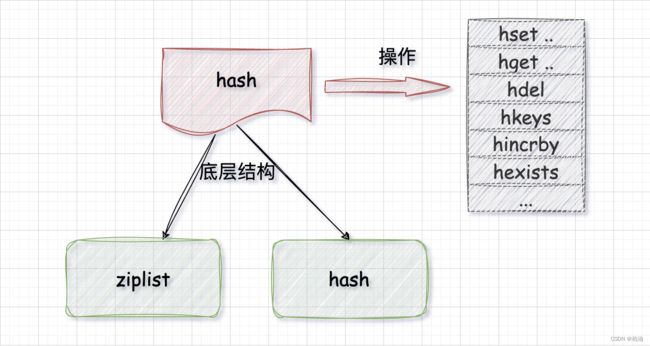
底层结构?
压缩列表(ziplist)和 字典(hash)
hash 数据类型使用 ziplist 结构的条件:
- 数据长度小于 64
- 列表长度小于 512
可以通过 redis.conf 中的 hash-max-ziplist-entries(默认 512)、hash-max-ziplist-value(默认 64) 调整。
高级数据类型
1、Stream
redis 从 5.0 版本开始支持提供 stream 数据类型,它可以用来保存消息数据,进而能帮助我们实现一个带有消息读写基本功能的消息队列,并用于日常的分布式程序通信当中。
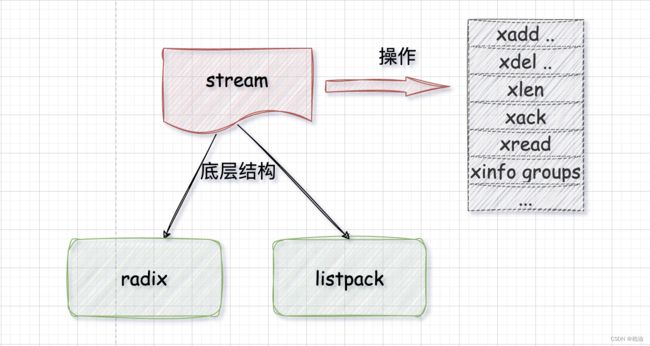
其中,为了节省内存空间,在 stream 数据类型的底层数据结构中,采用了 radix tree 和 listpack 两种数据结构来保存消息。
- listpack 是一个紧凑型列表,在保存数据时会非常节省内存。
- radix tree,这个数据结构的最大特点是适合保存具有相同前缀的数据,从而实现节省内存空间的目标,以及支持范围查询。
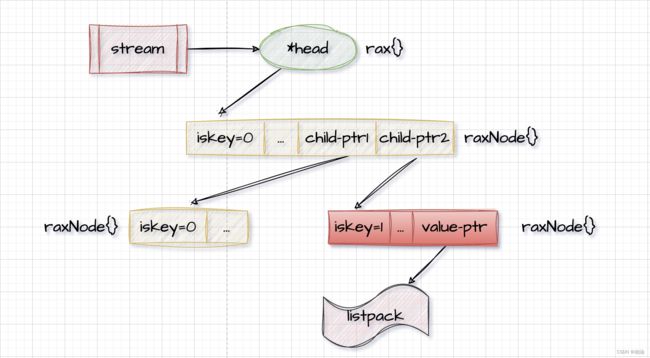
消息 id 使用 rax 存储,消息使用 listpack 存储,所以整个 stream 结构看起来就是一颗 rax 树:
✍️ 例子:
- ✅ 先添加几组消息到 stream 流中:
> XADD temperatures:us-ny:10007 * temp_f 87.2 pressure 29.69 humidity 46
"1658354918398-0"
> XADD temperatures:us-ny:10007 * temp_f 83.1 pressure 29.21 humidity 46.5
"1658354934941-0"
> XADD temperatures:us-ny:10007 * temp_f 81.9 pressure 28.37 humidity 43.7
"1658354957524-0"
- ✅ 读取从 1658354934941-0 开始的两条消息:
> XRANGE temperatures:us-ny:10007 1658354934941-0 + COUNT 2
1) 1) "1658354934941-0"
2) 1) "temp_f"
2) "83.1"
3) "pressure"
4) "29.21"
5) "humidity"
6) "46.5"
2) 1) "1658354957524-0"
2) 1) "temp_f"
2) "81.9"
3) "pressure"
4) "28.37"
5) "humidity"
6) "43.7"
- ✅ 从 stream 消息流尾部监听即将到来的 100 条消息,并指定 300ms 的超时时间:
> XREAD COUNT 100 BLOCK 300 STREAMS temperatures:us-ny:10007 $
(nil)
底层结构:
- 消息ID:采用 radix 结构
- 消息体:采用 listpack 结构
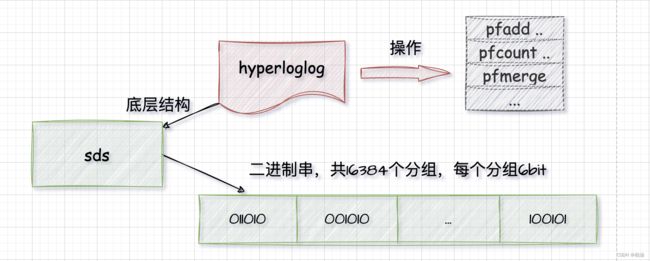
2、HyperLogLog
HyperLogLog,是一种概率性的统计算法,用于估算去重元素总数,每个 HyperLogLog 对象最大占用空间为 12KB,相当节省内存。
✍️ 例子:
- ✅ 添加元素:
> PFADD members 123
(integer) 1
> PFADD members 500
(integer) 1
> PFADD members 12
(integer) 1
- ✅ 预估总的去重数量:
> PFCOUNT members
(integer) 3
限制?
一个 HyperLogLog 结构最多能估算 18,446,744,073,709,551,616 (2^64) 个元素。
性能?
PFADD、PFCOUNT 都是 O(1) 操作,而 PFMERGE 是 O(N) 操作,其中 N 是待合并的 HyperLogLog 数量。
底层结构:
SDS。HyperLogLog 没有采用新的数据结构,而是直接使用 SDS 字符串存储二进制位。
3、BitMap
位图。以二进制位为操作单位,每一个二进制位只有 0 和 1 两种取值。你可以用它来记录你一年 365 天打卡情况、签到记录 …

✍️ 例子:
假设在现场部署了 1000 个传感器,标记为 0-999。你希望快速确定给定的传感器是否在一小时内 ping 通了服务器。
这个时候你就可以考虑位图了。每个时间点就是一个 bitmap,用长度为 1000 个二进制位来表示 0-999,在对应位置上,如果 ping 了服务器就标志为 1,反之为 0。
- ✅ 在
00:00时间点,传感器 123 ping 了服务器:
> SETBIT pings:2024-01-01-00:00 123 1
(integer) 0
- ✅ 获取
00:00时间点,传感器 123 的状态:
> GETBIT pings:2024-01-01-00:00 123
1
- ✅ 然后再看看
00:00时间点,传感器 456 的状态:
> GETBIT pings:2024-01-01-00:00 456
0
性能?
SETBIT 和 GETBIT 都是 O(1) 操作,BITOP 是 O(N) 操作,其中 N 是操作的最长字符串的长度。
底层结构:
和 HyperLogLog 类似,其底层仍然采用 SDS 数据结构。
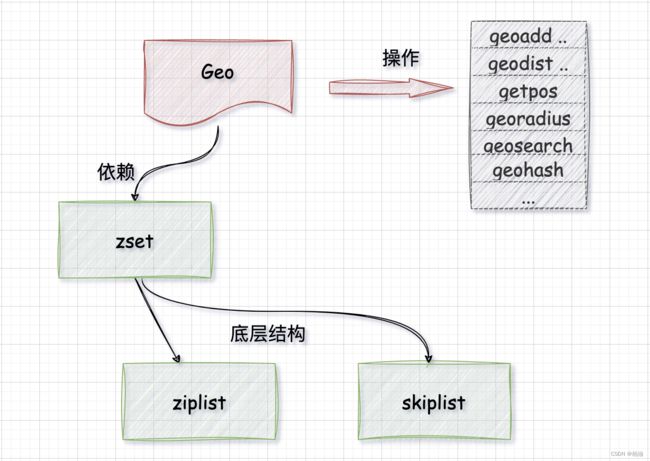
4、Geo
全称 Geospatial,这是一个和地理坐标相关的一个数据结构,你可以用它来找到二维地图上 两个坐标之间的距离、离你最近的人 …
✍️ 例子:
假设你设计了一款移动应用,主要用于搜寻附近离你最近的电子收费站。
- ✅ 首先,将几个收费站坐标添加至地图中:
> GEOADD locations:ca -122.27652 37.805186 station:1
(integer) 1
> GEOADD locations:ca -122.2674626 37.8062344 station:2
(integer) 1
> GEOADD locations:ca -122.2469854 37.8104049 station:3
(integer) 1
- ✅ 搜索附近半径 5公里的收费站,并返回对应的距离:
> GEOSEARCH locations:ca FROMLONLAT -122.2612767 37.7936847 BYRADIUS 5 km WITHDIST
1) 1) "station:1"
2) "1.8523"
2) 1) "station:2"
2) "1.4979"
3) 1) "station:3"
2) "2.2441"
底层结构:
Geo 底层借助于 zset 来完成,因此底层数据结构也就是 ziplist 和 skiplist。
写在最后
本文梳理了截止 redis6.2 中出现的数据类型 + 数据结构,通过这篇文章你大致能掌握 redis 底层的数据组织形式。
当你熟练掌握之后,再使用相关命令操作时,脑海里通常会出现这个命令背后是如何运作画面,是不是很美妙?
如果还想要进一步了解每个数据结构的实现细节,点击文末下方链接一探究竟!