【SNA】社会网络分析三 图论与图学习
社会网络分析——三、图论与图学习
中间被很多人转了,我是从机器之心公众号(almosthuman2014)看到的,最初来源应该是 Maël Fabien 大佬的博客,致谢
https://github.com/maelfabien/Machine_Learning_Tutorials
- 目录:
- 第一部分:图介绍
- 图是什么?
- 如何存储图?
- 图的类型和性质
- Python 示例
- 第二部分:图算法
- Pathfinding(寻路)
- Community detection(社群检测)
- Centrality(中心性)
- 第一部分:图介绍
- 背景:
- 图(graph)近来正逐渐变成机器学习的一大核心领域,比如你可以通过预测潜在的连接来理解社交网络的结构、检测欺诈、理解汽车租赁服务的消费者行为或进行实时推荐。
- 涉及到的python包:
- networkx 是一个用于复杂网络的结构、动态和功能的创建、操作和研究的 Python 软件包,选择networkx 2.0 版本。
import numpy as np
import random
import networkx as nx
from IPython.display import Image
import matplotlib.pyplot as plt
1.1 图是什么?
- 概念:图是互连节点的集合。
- 作用:社交网络、网页、生物网络…
- 我们可以在图上执行怎样的分析?
- 研究拓扑结构和连接性、群体检测、识别中心节点、预测缺失的节点、预测缺失的边…
(1)空手道图为例的图构建:
# Load the graph
G_karate = nx.karate_club_graph()
# Find key-values for the graph
pos = nx.spring_layout(G_karate)
# Plot the graph
nx.draw(G_karate, cmap = plt.get_cmap('rainbow'), with_labels=True, pos=pos)
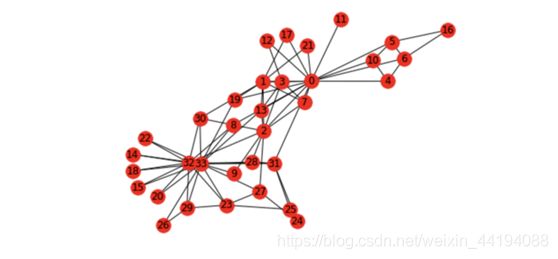
「空手道」图:Wayne W. Zachary 在 1970 到 1972 年这三年中研究的一个空手道俱乐部的社交网络。该网络包含了这个空手道俱乐部的 34 个成员,成员对之间的连接表示他们在俱乐部之外也有联系。在研究期间,管理员 JohnA 与教练 Mr.Hi(化名)之间出现了冲突,导致俱乐部一分为二。一半成员围绕 Mr.Hi 形成了一个新的俱乐部,另一半则找了一个新教练或放弃了空手道。基于收集到的数据,除了其中一个成员,Zachary 正确分配了所有成员在分裂之后所进入的分组。
(2)图的基本表示方法
图 G=(V, E) 由下列要素构成:
- 一组节点(也称为 verticle):V=1,…,n
- 一组边: E⊆V×V
- 边 (i,j) ∈ E 连接了节点 i 和 j
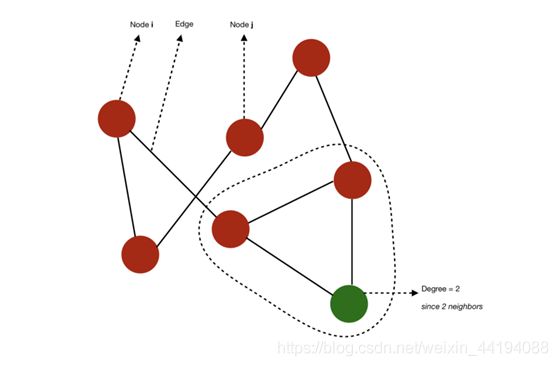
- 相邻节点:i 和 j 被称为相邻节点(neighbor)
- 节点度:节点的度(degree)是指相邻节点的数量
(3)图中常见的概念
- 完备图:如果一个图的所有节点都有 n-1 个相邻节点,则该图是完备的(complete),也就是说所有节点都具备所有可能的连接方式。
- 路径与路径长度:从 i 到 j 的路径(path)是指从 i 到达 j 的边的序列,该路径的长度(length)等于所经过的边的数量。
- 图直径:图的直径(diameter)是指连接任意两个节点的所有最短路径中最长路径的长度。
- 测地路径:测地路径(geodesic path)是指两个节点之间的最短路径。
- 图连通与连通分量:如果所有节点都可通过某个路径连接到彼此,则它们构成一个连通分量(connected component)。如果一个图仅有一个连通分量,则该图是连通的(connected)。
- 有两个不同连通分量的图:
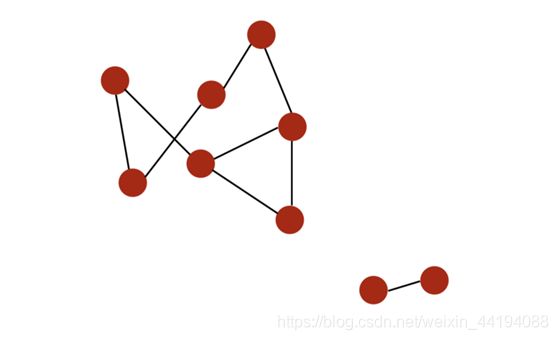
- 有两个不同连通分量的图:
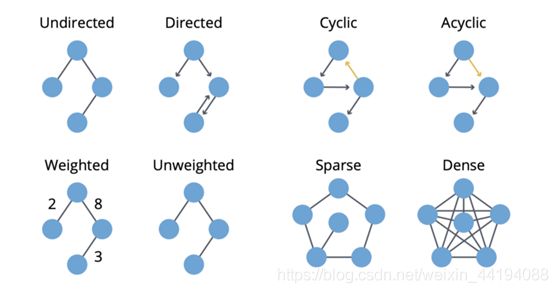
- 有向图,出度与入度:如果一个图的边是有顺序的配对,则该图是有向的(directed)。i 的入度(in-degree)是指向 i 的边的数量,出度(out-degree)是远离 i 的边的数量。
- 有环图与无环图:如果可以回到一个给定节点,则该图是有环的(cyclic)。相对地,如果至少有一个节点无法回到,则该图就是无环的(acyclic)。
- 加权图:图可以被加权(weighted),即在节点或关系上施加权重。
- 稀疏与密集:如果一个图的边数量相比于节点数量较小,则该图是稀疏的(sparse)。相对地,如果节点之间的边非常多,则该图是密集的(dense)。
(4)总结:
- Neo4J 的关于图算法的书给出了清晰明了的总结:
(5)python示例:
n=34
G_karate.degree() # 返回该图的每个节点的度(相邻节点的数量)的列表
''' 结果
DegreeView({0: 16, 1: 9, 2: 10, 3: 6, 4: 3, 5: 4, 6: 4, 7: 4, 8: 5, 9: 2, 10: 3, 11: 1, 12: 2, 13: 5, 14: 2, 15: 2, 16: 2, 17: 2, 18: 2, 19: 3, 20: 2, 21: 2, 22: 2, 23: 5, 24: 3, 25: 3, 26: 2, 27: 4, 28: 3, 29: 4, 30: 4, 31: 6, 32: 12, 33: 17})
'''
# Isolate the sequence of degrees 隔离度
degree_sequence = list(G_karate.degree())
# 计算边的数量,但也计算度序列的度量
nb_nodes = n
nb_arr = len(G_karate.edges())
avg_degree = np.mean(np.array(degree_sequence)[:,1])
med_degree = np.median(np.array(degree_sequence)[:,1])
max_degree = max(np.array(degree_sequence)[:,1])
min_degree = np.min(np.array(degree_sequence)[:,1])
# 打印所有信息:
print("Number of nodes : " + str(nb_nodes))
print("Number of edges : " + str(nb_arr))
print("Maximum degree : " + str(max_degree))
print("Minimum degree : " + str(min_degree))
print("Average degree : " + str(avg_degree))
print("Median degree : " + str(med_degree))
''' 结论:
Number of nodes : 34
Number of edges : 78
Maximum degree : 17
Minimum degree : 1
Average degree : 4.588235294117647 # 平均而言,该图中的每个人都连接了 4.6 个人
Median degree : 3.0
'''
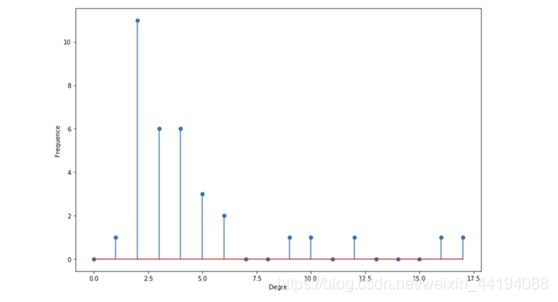
# 绘出这些度的直方图
# 度的直方图相当重要,可用于确定我们看到的图的种类
degree_freq = np.array(nx.degree_histogram(G_karate)).astype('float')
plt.figure(figsize=(12, 8))
plt.stem(degree_freq)
plt.ylabel("Frequence")
plt.xlabel("Degre")
plt.show()
1.2 如何存储图?
存储图的方式有三种,最好的表示方式取决于用法和可用的内存,以及你想用它做什么:
- 边集数组:存储有边连接的每一对节点的 ID。
- 邻接矩阵:通常是在内存中加载的方式,对于图中的每一个可能的配对,如果两个节点有边相连,则设为 1。如果该图是无向图,则 A 是对称的:
- 邻接列表:
- 如
1:[2,3,4]表示与节点1相连的边有2、3、4。
- 如
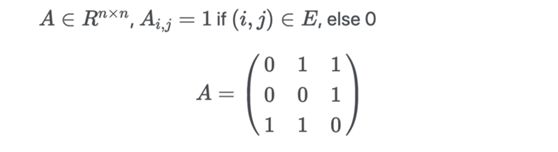
图可能包含一些扩展:
- 加权的边
- 节点/边上加标签
- 加上与节点/边相关的特征向量
1.3 图的类型
两种主要的图类型:
- Erdos-Rényi
- Barabasi-Albert
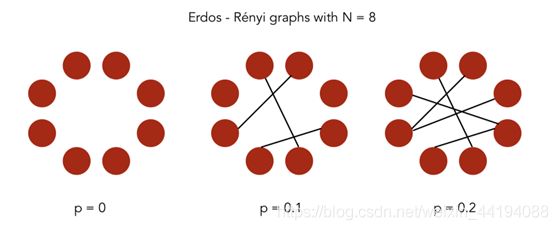
(1)Erdos-Rényi 模型
-
定义
- 在 Erdos-Rényi 模型中,我们构建一个带有 n 个节点的随机图模型。这个图是通过以概率 p 独立地在节点 (i,j) 对之间画边来生成的。因此,我们有两个参数:节点数量 n 和概率 p。
-
python生成 Erdos-Rényi 图的内置函数
# Generate the graph
n = 50
p = 0.2
G_erdos = nx.erdos_renyi_graph(n,p, seed =100)
# Plot the graph
plt.figure(figsize=(12,8))
nx.draw(G_erdos, node_size=10)
- 度分布
- 令 pk 为随机选取的节点的度为 k 的概率。由于图构建所使用的随机方式,这种图的度的分布是二项式的
- 公式: p k = ( n − 1 k ) p k ( 1 − p ) n − 1 − k p_k=\begin{pmatrix}n-1\\k\end{pmatrix}p^k(1-p)^{n-1-k} pk=(n−1k)pk(1−p)n−1−k)
- 每个节点的度数量的分布应该非常接近于均值,观察到高数量节点的概率呈指数下降。
- 令 pk 为随机选取的节点的度为 k 的概率。由于图构建所使用的随机方式,这种图的度的分布是二项式的
degree_freq = np.array(nx.degree_histogram(G_erdos)).astype('float')
plt.figure(figsize=(12, 8))
plt.stem(degree_freq)
plt.ylabel("Frequence")
plt.xlabel("Degree")
plt.show()
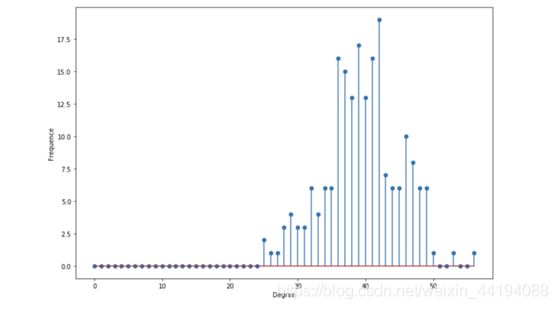
- 描述性统计
- 平均度:n×p(在 p=0.2 和 n=200 时,中心在 40 左右)
- 度期望: (n−1)×p
- 平均值附近的度最多
# Get the list of the degrees
degree_sequence_erdos = list(G_erdos.degree())
nb_nodes = n
nb_arr = len(G_erdos.edges())
avg_degree = np.mean(np.array(degree_sequence_erdos)[:,1])
med_degree = np.median(np.array(degree_sequence_erdos)[:,1])
max_degree = max(np.array(degree_sequence_erdos)[:,1])
min_degree = np.min(np.array(degree_sequence_erdos)[:,1])
esp_degree = (n-1)*p
print("Number of nodes : " + str(nb_nodes))
print("Number of edges : " + str(nb_arr))
print("Maximum degree : " + str(max_degree))
print("Minimum degree : " + str(min_degree))
print("Average degree : " + str(avg_degree))
print("Expected degree : " + str(esp_degree))
print("Median degree : " + str(med_degree))
'''结果:
Number of nodes : 200
Number of edges : 3949
Maximum degree : 56
Minimum degree : 25
Average degree : 39.49
Expected degree : 39.800000000000004
Median degree : 39.5
这里的平均度和期望度非常接近,因为两者之间只有很小的因子
'''
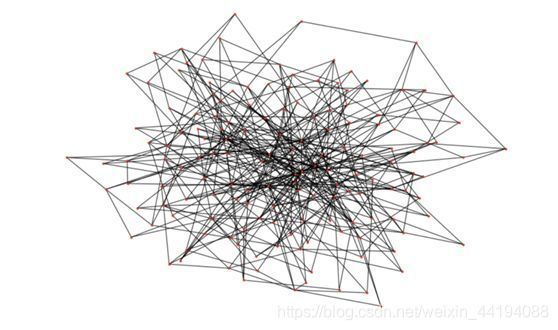
(2)Barabasi-Albert 模型
-
定义
- 在 Barabasi-Albert 模型中,我们构建一个有 n 个节点的随机图模型,其有一个优先连接(preferential attachment)分量。这种图可通过以下算法生成:
- 步骤 1:以概率 p 执行步骤 2,否则执行步骤 3
- 步骤 2:将一个新节点连接到随机均匀选取的已有节点
- 步骤 3:以与 n 个已有节点成比例的概率将这个新节点连接到这 n 个已有节点
- 这个图的目标是建模优先连接(preferential attachment),真实世界网络中常会观察到这一点。(注:优先连接是指根据各个个体或对象已有的量来分配某个量,这通常会进一步加大优势个体的优势。)
- 在 Barabasi-Albert 模型中,我们构建一个有 n 个节点的随机图模型,其有一个优先连接(preferential attachment)分量。这种图可通过以下算法生成:
-
python生成 Barabasi-Albert 图的内置函数
# Generate the graph
n = 150
m = 3
G_barabasi = nx.barabasi_albert_graph(n,m)
# Plot the graph
plt.figure(figsize=(12,8))
nx.draw(G_barabasi, node_size=10)
- 度分布
- 令 pk 为随机选取的节点的度为 k 的概率。则这个度分布遵循幂律
- 公式: p k ∝ k − α p_k\propto k^{-\alpha} pk∝k−α
- 这个分布是重尾分布,其中有很多节点的度都很小,但也有相当数量的节点有较高的度。
- 令 pk 为随机选取的节点的度为 k 的概率。则这个度分布遵循幂律
# 据说这个分布是无标度的(scale-free),平均度不能提供信息
degree_freq = np.array(nx.degree_histogram(G_barabasi)).astype('float')
plt.figure(figsize=(12, 8))
plt.stem(degree_freq)
plt.ylabel("Frequence")
plt.xlabel("Degree")
plt.show()
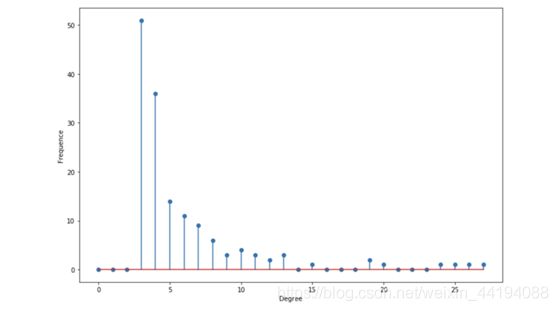
- 描述性统计
- 如果 α≤2,平均度为一个常量,否则就会发散。
- 最大度遵照以下顺序: O ( n 1 α − 1 ) O(n^{\frac{1}{\alpha-1}}) O(nα−11)
# Get the list of the degrees
degree_sequence_erdos = list(G_erdos.degree())
nb_nodes = n
nb_arr = len(G_erdos.edges())
avg_degree = np.mean(np.array(degree_sequence_erdos)[:,1])
med_degree = np.median(np.array(degree_sequence_erdos)[:,1])
max_degree = max(np.array(degree_sequence_erdos)[:,1])
min_degree = np.min(np.array(degree_sequence_erdos)[:,1])
esp_degree = (n-1)*p
print("Number of nodes : " + str(nb_nodes))
print("Number of edges : " + str(nb_arr))
print("Maximum degree : " + str(max_degree))
print("Minimum degree : " + str(min_degree))
print("Average degree : " + str(avg_degree))
print("Expected degree : " + str(esp_degree))
print("Median degree : " + str(med_degree))
''' 结果:
Number of nodes : 200
Number of edges : 3949
Maximum degree : 56
Minimum degree : 25
Average degree : 39.49
Expected degree : 39.800000000000004
Median degree : 39.5
'''
2.1 算法1:寻路和图搜索算法
Pathfinding(寻路):根据可用性和质量等条件确定最优路径。我们也将搜索算法包含在这一类别中。这可用于确定最快路由或流量路由。
- 寻路算法:通过最小化跳(hop)的数量来寻找两个节点之间的最短路径。
- 搜索算法:不是给出最短路径,而是根据图的相邻情况或深度来探索图,可用于信息检索。
(1)搜索算法
- 图搜索算法的分类:
- 宽度优先搜索(BFS):首先探索每个节点的相邻节点,然后探索相邻节点的相邻节点。
- 深度优先搜索(DFS):会尝试尽可能地深入一条路径,如有可能便访问新的相邻节点。
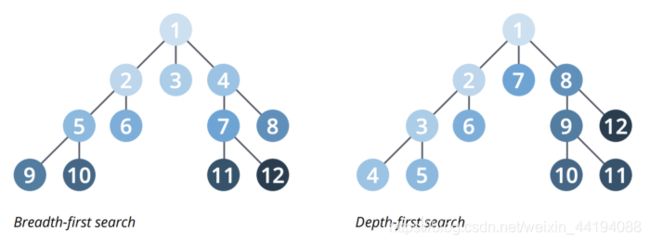
(2)寻路算法1:最短路径
- 定义:
- 计算的是一对节点之间的最短的加权(如果图有加权的话)路径。
- 可用于确定最优的驾驶方向或社交网络上两个人之间的分离程度。
- 计算方法:
- 有SPFA,Dijsktra等,以 Dijkstra 算法为例
- 1、未访问集构建:将图中所有节点标记为未访问。创建一个所有未访问节点的集合,称为未访问集。
- 2、为每个节点分配暂定距离值:将我们的初始节点的该值设置为零,将其它所有节点的该值设置为无穷。将初始起始节点设置为当前节点。
- 3、为每个节点枚举计算新的暂定距离:对于当前节点,考察其所有未被访问过的相邻节点并计算通过当前节点的暂定距离。比较新计算出的暂定距离与当前分配的值,配之以其中更小的值。
- 举例:如果当前节点 A 标记的距离为 6,将其与相邻节点 B 连接的边的长度为 2,则通过 A 到达 B 的距离为 6+2=8。如果 B 之前被标记的距离大于 8,则将其改为 8。否则,保持其当前的值。
- 4、已访问标记:当我们考察完当前节点的所有未访问节点时,将当前节点标记为已访问,并将其移出未访问集。已访问节点不会再次进行检查。
- 5、是否结束询问:如果目标节点已被标记为已访问(当规划两个特定节点之间的路由时)或未访问集中节点之间的最小暂定距离为无穷时(当规划一次完整的遍历时;当初始节点与剩余的未访问节点之间没有连接时才会出现这种情况),那么就停止操作。算法结束。
- 6、新的迭代:否则,选择标记有最小暂定距离的未访问节点,将其设置为新的「当前节点」,然后回到步骤 3。
更多最短路径问题的介绍:https://en.wikipedia.org/wiki/Shortest_path_problem
# Returns shortest path between each node
nx.shortest_path(G_karate) # 返回图中每个节点之间的最小路径的列表
'''结果
{0: {0: [0],
1: [0, 1],
2: [0, 2],
...
'''
- 最短路径分类:
- 单源最短路径(Single Source Shortest Path/SSSP):找到给定节点与图中其它所有节点之间的最短路径,这常用于 IP 网络的路由协议。
- 所有配对最短路径(All Pairs Shortest Path / APSP):找到所有节点对之间的最短路径(比为每个节点对调用单源最短路径算法更快)。该算法通常可用于确定交通网格的不同分区的流量负载。
# Returns shortest path length between each node
list(nx.all_pairs_shortest_path_length(G_karate))
'''结果
[(0,
{0: 0,
1: 1,
2: 1,
3: 1,
4: 1,
...
'''
(3)寻路算法2:最小权重生成树
- 最小权重生成树(minimum spanning tree):是图(一个树)的一个子图,其用权重和最小的边连接了图中的所有节点,应该用于无向图。
from networkx.algorithms import tree
mst = tree.minimum_spanning_edges(G_karate, algorithm='prim', data=False)
edgelist = list(mst)
sorted(edgelist)
'''
[(0, 1),
(0, 2),
(0, 3),
(0, 4),
(0, 5),
(0, 6),
'''
2.2 社群检测
Community detection(社群检测):评估群体聚类的方式。这可用于划分客户或检测欺诈等。
- 定义:社群检测是根据给定的质量指标将节点划分为多个分组。
- 作用:可用于识别社交社群、客户行为或网页主题。
- 概念:
- 社区/社群:指一组相连节点的集合。目前还没有广泛公认的定义,只是社群内的节点应该要密集地相连。
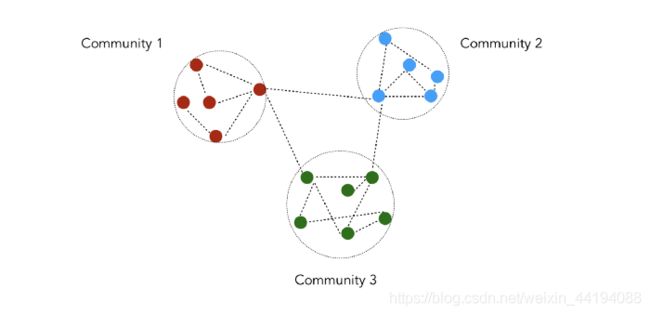
(1)Girvan Newman 算法
- 定义:
- Girvan Newman 算法是一个用于发现社群的常用算法,其通过逐步移除网络内的边来定义社区
- 边居间性(edge betweenness):正比于穿过该边的节点对之间最短路径的数量的值
- 算法步骤:
- 1 计算网络中所有已有边的居间性。
- 2 移除居间性最高的边。
- 3 移除该边后,重新计算所有边的居间性。
- 4 重复步骤 2 和 3,直到不再剩余边。
- 弊端:
- 这个算法没法扩展;如果要运行大规模的图,耗时较大;
from networkx.algorithms import community
k = 1 # k=1 的意思是我们期望得到 2 个社群
comp = community.girvan_newman(G_karate)
for communities in itertools.islice(comp, k):
print(tuple(sorted(c) for c in communities))
''' 得到一个属于每个社群的节点的列表:
([0, 1, 3, 4, 5, 6, 7, 10, 11, 12, 13, 16, 17, 19, 21], [2, 8, 9, 14, 15, 18, 20, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33])
'''
(2)Louvain 算法
- 模块性(modularity)
- 模块性是一个度量,衡量的是分组被划分为聚类的程度
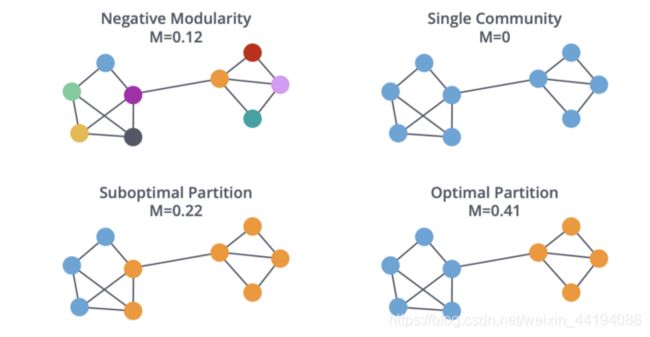
- Louvain 算法:
- 1 首先为每个节点分配一个社群
- 2 创建一个带有相邻节点的新社群,以最大化模块性
- 3 创建一个新的加权图,之前步骤的社群变成图的新节点。
- 4 交替执行步骤1 2,直到收敛
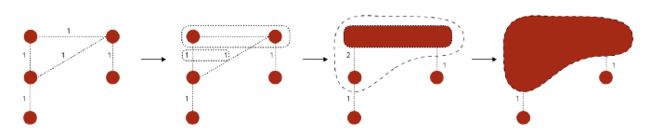
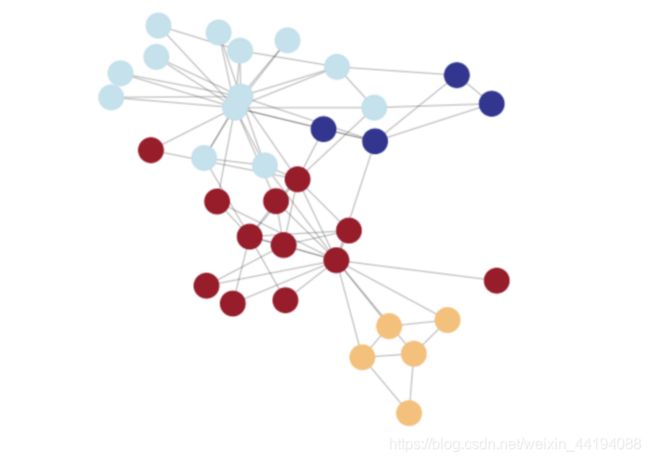
- 算法评估:Louvain 方法没有理论上的保证,但实践效果很好(https://python-louvain.readthedocs.io/en/latest/)
pip install python-louvain # 安装软件包
# 基于 Louvain 方法,计算最佳的划分方式
import community
partition = community.best_partition(G_karate)pos = nx.spring_layout(G_karate)
plt.figure(figsize=(8, 8))
plt.axis('off')
nx.draw_networkx_nodes(G_karate, pos, node_size=600, cmap=plt.cm.RdYlBu, node_color=list(partition.values()))
nx.draw_networkx_edges(G_karate, pos, alpha=0.3)
plt.show(G_karate)
(3)强互连与弱互连的组分算法
- 强互连的组分(Strongly Connected Components /SCC)算法
- 能找到有向图中的互连节点的分组,在同一个分组中,每个节点都必须从任意其它节点从两个方向都到达。
- 弱互连的组分(Weakly Connected Components),也称为并查集(Union Find)算法
- 能找到有向图中的互连节点的集合,在同一个集合中,每个节点都可从任意其它节点到达。
- 区别:
- WCC:需要节点对之间在一个方向上存在一条路径即可
- SCC:需要节点对之间在两个方向都存在路径
- 用途:
- 这通常用在图分析过程的早期阶段,能让我们了解图构建的方式(举例:探索财务报表数据,了解谁拥有什么公司的股份)
# 测试相连的有向图:
nx.is_weakly_connected(G)
nx.is_strongly_connected(G)
# 测试无向图:
nx.is_connected(G_karate)
networkx 文档中有关连接性实现的问题:https://networkx.github.io/documentation/stable/reference/algorithms/component.html
(4)分层聚类
- 分层聚类(hierarchical clustering):构建聚类的层次结构,用树状图的形式表示聚类。
- 核心思想: 以不同的规模分析社群结构。
- 构造:通常自下而上构建树状图,从每个节点一个聚类开始,然后合并两个「最近」的节点
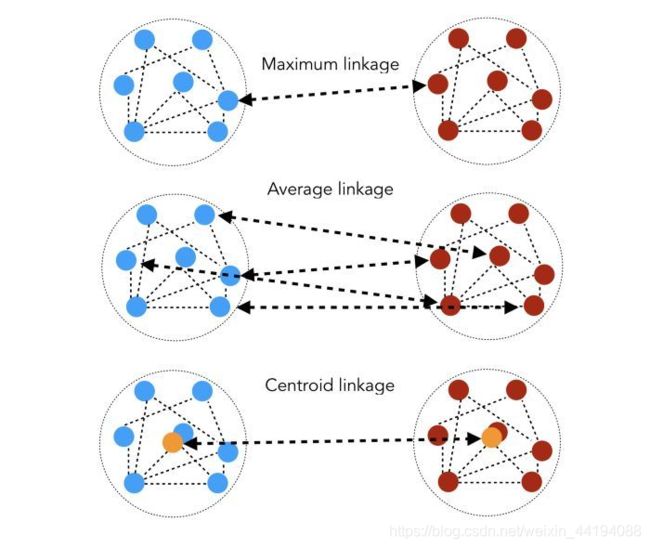
- 衡量聚类是否相近:相似度距离,令 d(i,j) 为 i 和 j 之间的最短路径的长度。
- Maximum linkage: D ( C 1 , C 2 ) = min i ∈ C 1 , j ∈ C 2 d ( i , j ) D(C_1,C_2)=\min_{i\in C_1,j\in C_2}{d(i,j)} D(C1,C2)=mini∈C1,j∈C2d(i,j)
- Average linkage: D ( C 1 , C 2 ) = 1 ∣ C 1 ∣ ∣ C 2 ∣ ∑ i ∈ C 1 , j ∈ C 2 d ( i , j ) D(C_1,C_2)=\frac{1}{|C_1||C_2|}\sum_{i\in C_1,j\in C_2}{d(i,j)} D(C1,C2)=∣C1∣∣C2∣1∑i∈C1,j∈C2d(i,j)
- Centroid linkage: D ( C 1 , C 2 ) = d ( G 1 , G 2 ) D(C_1,C_2)=d(G_1,G_2) D(C1,C2)=d(G1,G2),where G 1 G_1 G1 and G 2 G_2 G2 are the centers of G 1 G_1 G1, G 2 G_2 G2
- 示意图:
# 在应用分层聚类之前,定义每个节点之间的距离矩阵
pcc_longueurs=list(nx.all_pairs_shortest_path_length(G_karate))
distances=np.zeros((n,n)) # distances[i, j] is the length of the shortest path between i and j
for i in range(n):
for j in range(n):
distances[i, j] = pcc_longueurs[i][1][j]
# 使用 sklearn 的 AgglomerativeClustering 函数来确定分层聚类
from sklearn.cluster import AgglomerativeClusteringclustering = AgglomerativeClustering(n_clusters=2,linkage='average',affinity='precomputed').fit_predict(distances)
# 根据聚类结果,用不同颜色绘出所得到的图:
nx.draw(G_karate, node_color = clustering)
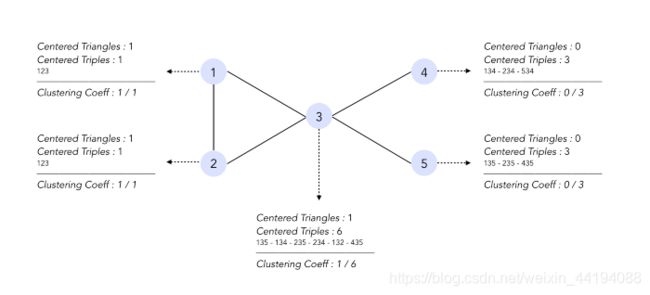
- 聚类系数:两个节点倾向于聚类到一起的程度
- 局部聚类系数:以节点 i 为中心的三角形的数量 与 以节点 i 为中心的三节点的数量 的比,衡量的是节点 i 与其相邻节点接近完备图(complete graph)的程度。
- 公式: C i = T r i a n g l e s i T r i p l e s i C_i=\frac{Triangles_i}{Triples_i} Ci=TriplesiTrianglesi
- 全局聚类系数:衡量的是图中三角形(局部聚类)的密度
- 公式: C C = 1 n ∑ i C i CC=\frac{1}{n}\sum_{i}C_i CC=n1∑iCi
- 特殊图中案例:
- 对于 Erdos-Rényi 随机图: E [ C l u s t e r i n g C o e f f i c i e n t ] = E [ C i ] = p E[Clustering Coefficient]=E[Ci]=p E[ClusteringCoefficient]=E[Ci]=p
- 对于 Baràbasi-Albert 随机图:全局聚类系数根据节点的数量遵循幂律,度为 k 的节点的平均聚类系数正比于 k 的倒数: C ( k ∝ k − 1 ) C(k \propto k^{-1}) C(k∝k−1)
- 度较低的节点连接的是它们社群中的其它节点,度较高的节点连接的是其它社群的节点。
- 局部聚类系数:以节点 i 为中心的三角形的数量 与 以节点 i 为中心的三节点的数量 的比,衡量的是节点 i 与其相邻节点接近完备图(complete graph)的程度。
# 计算局部聚类系数,List of local clustering coefficients
list(nx.clustering(G_barabasi).values())
'''
0.13636363636363635,
0.2,
0.07602339181286549,
0.04843304843304843,
0.09,
0.055384615384615386,
0.07017543859649122,
'''
# 平均这些结果,得到该图的全局聚类系数,Global clustering coefficient
np.mean(list(nx.clustering(G_barabasi).values()))
'''
0.0965577637155059
'''
3.3 中心度算法
Centrality(中心性):确定网络中节点的重要性。这可用于识别社交网络中有影响力的人或识别网络中潜在的攻击目标。
- 中心度(Centrality):衡量节点重要程度
- 游走(walk):可以多次经过同一个节点的路径,根据所考虑的游走类型和统计它们的方式,中心度度量也会各有不同。
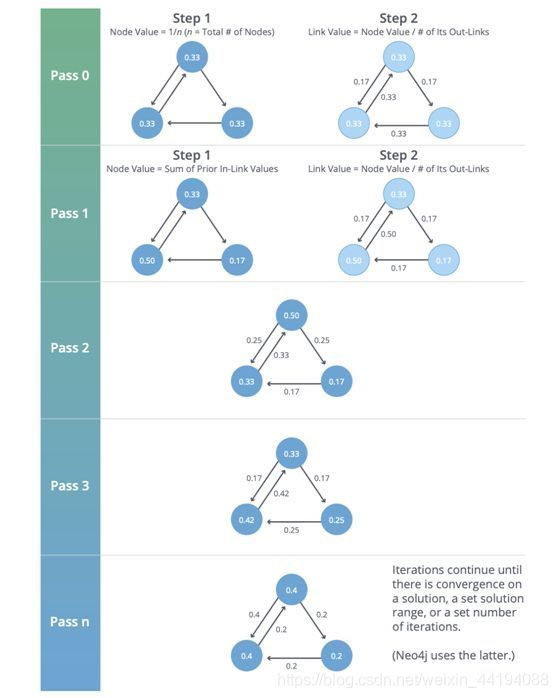
(1)PageRank 算法
-
PageRank 是根据所连接的相邻节点,然后再根据它们各自的相邻节点估计当前节点的重要性
- 计算方法1:通过在相邻节点上迭代地分配节点的秩(原本基于度)
- 计算方法2:通过随机遍历图并统计每次游走期间到达每个节点的频率
-
用途:
- 谷歌的搜索引擎的网页权重评估
- 也能够用于检测任何网络中的高影响力节点,比如可用 在社交网络上进行推荐。
-
Neo4J 对 PageRank 算法的总结
- PageRank 通常是在有向图上计算,但也可通过将有向图中的每条边转换成两条边而在无向图上执行。
-
案例
nx.pagerank(G_karate, alpha=0.9) # alpha 是阻尼参数(默认为 0.85)
''' 返回一个排名列表:
{0: 0.09923208031303203,
1: 0.0543403155825792,
2: 0.05919704684187155,
3: 0.036612460562853694,
'''
(2)度中心度(Degree Centrality)
- 度中心度:终止于节点 i 的、长度为 1 的 游走数量,这能够衡量传入和传出关系,可用于识别社交网络中最有影响力的人。
- 公式: C ( X i ) = d i C(X_i)=d_i C(Xi)=di
c_degree = nx.degree_centrality(G_karate)
c_degree = list(c_degree.values())
(3)特征向量中心度(Eigenvector Centrality)
- 特征向量中心度:终止于节点 i 的、长度为无穷的 游走数量,这能让有很好连接相邻节点的节点有更高的重要度。
- 公式: C ( X i ) = 1 λ ∑ j A i j C ( X j ) C(X_i)=\frac{1}{\lambda}\sum_{j}A_{ij}C(X_j) C(Xi)=λ1∑jAijC(Xj),where λ \lambda λ the largest eigenvalue of A A A
c_eigenvector = nx.eigenvector_centrality(G_karate)
c_eigenvector = list(c_eigenvector.values())
(4)接近度中心度(Closeness Centrality)
- 接近度中心度:反比于到其它节点的最短路径长度的总和。检测的是可以在图中有效传播信息的节点,这可用于识别假新闻账户或恐怖分子,以便隔离能向图中其它部分传播信息的个体。
- 公式: C ( X i ) = 1 ∑ j ≠ i d ( i , j ) C(X_i)=\frac{1}{\sum_{j\ne i}d(i,j)} C(Xi)=∑j=id(i,j)1
c_closeness = nx.closeness_centrality(G_karate)
c_closeness = list(c_closeness.values())
(5)中间中心度(Betweenness Centrality)
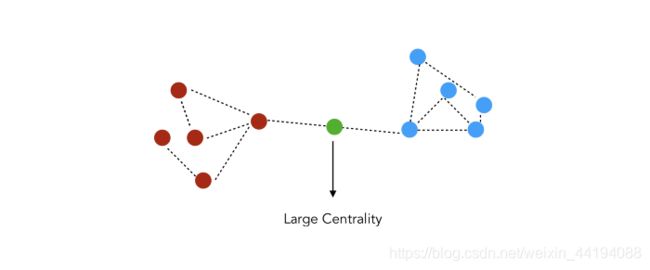
- 中间中心度:检测的是节点在图中的信息流上所具有的影响量,可用于发现用作从图的一部分到另一部分的桥的节点,比如用在电信网络的数据包传递处理器或假新闻传播分析中,衡量的是一个节点用作两个节点之间的桥的次数。
- 公式: C ( X i ) = ∑ j ≠ i , i ≠ k σ j k ( i ) σ j k C(X_i)=\sum_{j\ne i, i\ne k} \frac{\sigma_{jk}(i)}{\sigma_{jk}} C(Xi)=∑j=i,i=kσjkσjk(i)
- σ j k \sigma_{jk} σjk:j 和 k 之间的最短路径的数量
- σ j k ( i ) \sigma_{jk}(i) σjk(i):j 和 k 之间的经过 i 的最短路径的数量
- 公式: C ( X i ) = ∑ j ≠ i , i ≠ k σ j k ( i ) σ j k C(X_i)=\sum_{j\ne i, i\ne k} \frac{\sigma_{jk}(i)}{\sigma_{jk}} C(Xi)=∑j=i,i=kσjkσjk(i)
c_betweenness = nx.betweenness_centrality(G_karate)
c_betweenness = list(c_betweenness.values())
(6)总结
# Plot the centrality of the nodes
plt.figure(figsize=(18, 12))# Degree Centrality
f, axarr = plt.subplots(2, 2, num=1)
plt.sca(axarr[0,0])
nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_degree, node_size=300, pos=pos, with_labels=True)
axarr[0,0].set_title('Degree Centrality', size=16)# Eigenvalue Centrality
plt.sca(axarr[0,1])
nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_eigenvector, node_size=300, pos=pos, with_labels=True)
axarr[0,1].set_title('Eigenvalue Centrality', size=16)# Proximity Centrality
plt.sca(axarr[1,0])
nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_closeness, node_size=300, pos=pos, with_labels=True)
axarr[1,0].set_title('Proximity Centrality', size=16)# Betweenness Centrality
plt.sca(axarr[1,1])
nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_betweenness, node_size=300, pos=pos, with_labels=True)
axarr[1,1].set_title('Betweenness Centrality', size=16)
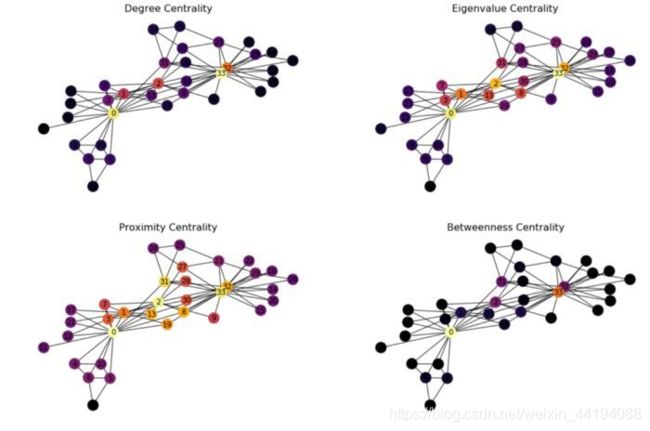
- 不同的中心度度量关注的节点也不同。比如,居间性中心度得到的结果与其它方法的结果非常不同,因为它们衡量的不是同一个指标。
扩展阅读:
- Neo4j 的图算法全面指南,Mark Needham & Amy E. Hodler:https://go.neo4j.com/rs/710-RRC-335/images/Comprehensive-Guide-to-Graph-Algorithms-in-Neo4j-ebook-EN-US.pdf
- Networkx 文档:https://networkx.github.io/documentation/stable/