基于ZYNQ移动机器人控制器设计(3)控制器硬件方案选型
本章介绍控制器硬件的方案选型,首先回答为什么选择 ZYNQ 平台来进行移动机器
人控制器方案设计,分析 ZYNQ 的架构与我们提出的控制器设计方案有哪些与生俱来的
契合。接着花了较多的篇幅来阐释锁定 ZYNQ 的前提下,将会使用到那些关键技术,以
及在运用这些关键技术的同时,应该遵循的,贯穿全程的设计方法论是怎样。

在本论文中我们选用嵌入式处理器领域的新星,被定义为下一代嵌入式处理器典范
的 Xlinx Zynq-7000 AP(All Programmable) Soc 作为实现平台,是基于以下原因:
(1)优越的性能
由于嵌入式设计领域不断追求提高性能、降低功耗、缩小外形、增加灵活性等,已
经有很多需求无法被现有的产品包括单个 ASIC(Application Specific Integrated Circuit,
是一种为专门目的而设计的集成电路)、ASSP(Application Specific Standard Parts,专用
标准产品,是为在特殊应用中使用而设计的集成电路)、单个处理器或者单纯的 FPGA
方案,甚至这些方案的组合所满足。
为了满足下一代应用处理需要,也是呼应越来越高涨的市场需求。Xilinx 定义了
Zynq-7000 系列产品。该系列四款新型器件分别是:7010,7020,7030 和 7045。它们将 ARM
Cortex™-A9 多核处理器与低功耗 FPGA 紧密集成在一起,成为一个完整的 SOC 方案。
同时解决单处理器信号处理能力不足,ASIC 复用性不高,单片的通用处理器和单片的
FPGA 混合方案体积过大、通信容易成为瓶颈等众多关键问题,汇集高性能、低功耗、
灵活可扩展等众多优点与一身。
(2)与生俱来的契合
ZYNQ 的上述优点只能说明它是一款看似优越的处理器,这些优点如果用来决定其
作为我们的移动机器人控制器的实现平台,则显得不够具有说服力。ZYNQ 之所以能够
完胜市场上的其他处理器而成为我们的最优方案,是因为其体系架构和工作模式与我们
要设计的机器人控制器有着与生俱来的契合。
首先从体系架构上来看,ZYNQ 是一个异构的处理平台。ZYNQ 分为 PS 和 PL 两
部分,其中 PS 的主体是多核的 ARM Cortex A9 处理器;PL 的主体是 Xilinx 的 7 系列
FPGA,二者通过片内的高速 AXI 总线相连。在 ZYNQ 中,PS 是中心,它可以独立 PL
而工作,也可以使用 PL 作为外设或者协处理硬件加速器。ZYNQ 这样的体系架构有利
于控制器系统的任务划分,我们可以把是适合通用处理器的控制任务放入 PS 中软件实
现 , 把 适 合 可 编 程逻 辑 的 任 务 放 入 PL 以 硬 件 IP 实 现 。 ZYNQ 这 样 独 有 的CPU0+CPU1+FPGA 的 TPA 架构(Triple Planar Architecture)使得控制器可以:(1)最
大程度地发挥异构多核处理器的优势;(2)更加拓宽了系统的优化空间;(3)具有更好
的灵活性。
其 次 从 工 作 模 式 上 , ZYNQ 得 天 独 厚 的 异 步 多 核 处 理 系 统 ( Asymmetric
Messultiprocing system ,AMP)工作模式使得 CPU0 和 CPU1 可以被配置为同时运行各自
独立的软件栈。这样的工作模式可以使得我们在本文第二章按照任务对移动机器人控制
器系统的三级分层方案落地,使得抽象的概念顺利找到合适的途径,成为实际的系统。
具体如图 3-1 所示[18]:
综上所述,ZYNQ 作为一款优秀的处理平台,因其独有的体系架构和工作模式与本
论文提出的移动机器人控制器方案有着天然的契合,因此能够在方案选型中击败其他处
理芯片,成为我们当之无愧的最优选择。
在锁定了 ZYNQ 平台之后,选择开发板则是随之而来的工作。在市场上现有的基于Zynq-700 的开发板中,信迈科技的ZYNQ开发板最终进入了我们的视野。

我们来简单地看一下 XM_ZYNQ7020作为一款优秀的开发板的主要特点和硬件资源:
处理器:
ZynqTM-7000 AP SoC XC7Z020-CLG484-1
存储:
512MB DDR;
256Mb Quad-SPI Flash;
4GB SD Card;
通信接口:
板上 USB-JTAG Programming 口;
10/100/1000 以太网;
USB OTG 2.0 和 USB-UART 口;
扩展接口:
FMC-LPC connector (68 single-ended or 34 differential I/Os);
5 Pmod™ compatible headers (2x6);
Agile Mixed Signaling (AMS) header;
时钟:
33.33333MHz PS 时钟源;
100MHz PL 晶振;
显示:
HDMI 输出(1080p60 with 16-bit, YCbCr, 4:2:2 mode color);
VGA 输出(12-bit resolution color);
128*32 OLED 显示屏;
配置和调试:
板上 USB-JTAG interface;
Xilinx Platform Cable JTAG 口;
通用 IO:
8 个用户 LED;
7 个 puSh 按钮;
8 个 DIP 开关;
关于 PS(Processing System),PL(Programmable Logic),EMIO 等的概念,本章
在接下来的内容中会有相对详细的介绍。
3.1 ZYNQ 的关键技术
Zedboard 使用的主芯片 Zynq 的全称是 Zynq AP Soc,即 Zynq All Programmable Soc。
它被 Xilinx 公司定义为下一代嵌入式处理器的范畴,具有很多以往任何嵌入式处理器都
不具备的新特点,因此本文有必要花一定的篇幅对其进行展示和归结。本节主要介绍
Zynq AP Soc 平台的 ARM+FPGA 体系结构、工作模式和接口技术。
如图 3-3 所示,左上角的方块为 ARM 部分,在 Zynq AP Soc 平台里我们称其为
Processing System,简称 PS。外面包着 PS 的部分,就是 FPGA,我们称其为 Programmable
Logic,简称 PL。
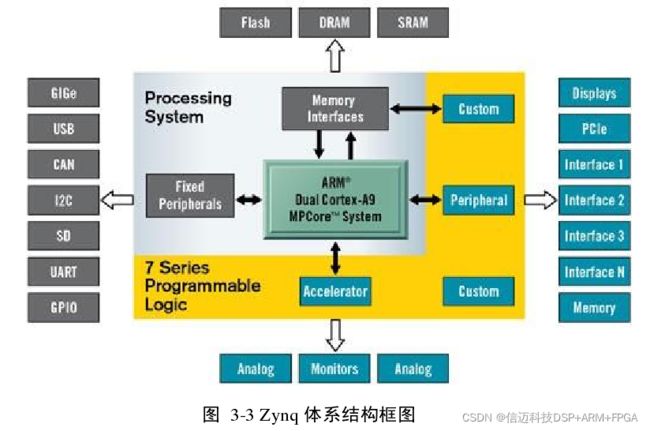
Zynq-7000 体系结构由明显的亮点和优势,使得它不同于以往任何一款多芯片方案
或单纯的 FPGA 方案。它包含了完整的 ARM 处理子系统,并以该子系统为 ZYNQ 的
中心,即使脱离 FPGA,处理子系统也可以依靠本身集成的内存控制器和大量外设独立
工作,这一点是以往的任何 FPGA 处理器都不具备的[20]。在此前提下,通过专门的总线
设备,可编程逻辑部分与 ARM 的处理单元紧密结合,浑然一体。
除了高性能 ARM CrotexTM-A 系列 CPU 之外,Zynq AP Soc 平台出色整合了 Xilinx 7
系列的 FPPGA,该系列采用了极先进的 28nm 工艺,其中 Z-7010 和 Z-7020 面向低端应
用,使用 Xilinx Artix-7,而 Z-7030 和 Z-7045 面向高端应用,使用 Xilinx Kintex-7 。位
于 Zynq-700 AP SOC 中 PL 部分的 FPGA 用来扩展子系统,它拥有强大的可扩展能力,
可以支持超过 3000 个内部互联,连接资源可谓非常丰富,并可以提供 100Gb/s 以上的
内部带宽。此外,在 I/O 接口方面,用户可以充分自定义。此外 FPGA 部分集成了高速
串行口(Multi Gigabit Transceiver)和数模转换器 XDC。本论文选用的 信迈XM_ZYNQ7020开发板,其上面的芯片就是 Z-7020。
接下来我们对 Zynq 中关于应用处理单元、通用外设、数字逻辑设计的部分技术细
节与参数进行较为详细的介绍,而对设计方案并未涉及而对其他部分,因此笔者在此进
行了详略取舍,不再赘述。
3.1.1 Processing System
ZYNQ 体系结构分为处理器系统(Processing System)与可编程逻辑(Programmable
Logic),本节介绍的应用处理单元(Application Processing Unit, APU)就位于 PS 端。其
详细的体系架构细节如下图 3-4 所示:
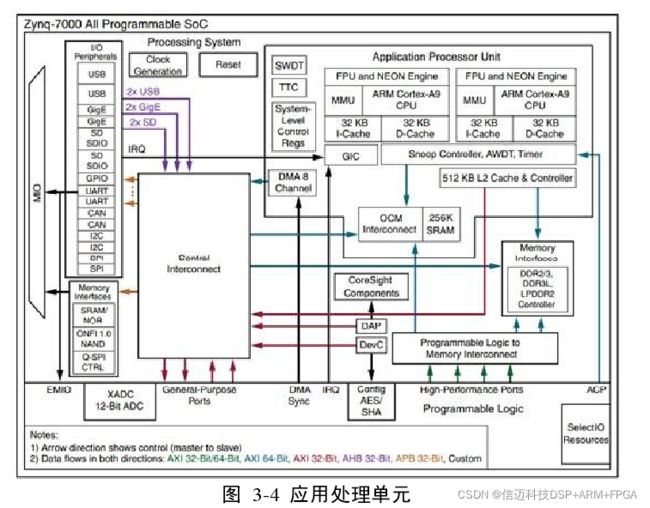
APU 中包含了两个 ARM CortexTM-A9 处理器与两个 Neon 协处理器,他们共享
512KB 大小的 L2 缓存。每个处理器都有一个高性能,低功耗的内核,而且独立拥有 32KB
的 L1 级指令与数据缓存。ARM CortexT
M-A9 是基于 ARMv7-A 架构的处理器,支持了
虚拟内存,目前可以执行 32 位 ARM 指令、16 与 32 位 Thumb 指令及 Jazelle 状态下的
8 位 JavaTM字节代码。Neon 协处理器的媒体和信号处理架构增加了对音频、视频、图
像和语音的处理能力,甚至专门对 3D 图形做了目标指令优化。这些先进的单指令多数
据(Single Instruction Multiple Data, SIMD)指令可以在 ARM 和 Thumb 状态下执行。出
于篇幅考虑,本文只对 APU 的得天独厚的地方展开一定程度的详述,而对于属于
CortexTM-A9 的技术细节,则不再赘述。
(1) 侦听控制单元
侦听控制单元(Snoop Control Unit,SCU)模块是 Zynq-7000 应用处理单元的一大
特色。它与两个 CortexTM-A9 处理器及其内存子系统相连。用于保证两个处理器之间,
以及与来自 PL 的 ACP 接口一致性。可以智能地管理两个处理器与 L2 共享高度缓存之
间的数据一致性。此模块负责为处理器管理互连仲裁、通信、缓存、系统内存之间的传
输以及高速缓存之间的数据一致性。同时 APU还提供了一个在 PL端实现的系统加速器,
通过“加速器一致性端口”(Accelerator Coherence Port, ACP)与 SCU 模块进行相连。该
接口允许 PL 端共享和访问处理器的高速缓存。如此由独立硬件管理单元提供的系统一
致性管理,不仅提高了性能而且降低了软件的复杂性,最大的优势是保持了软件在不同
的操作系统中驱动程序的一致性。
SCU 模块通过高速缓存一致性总线( Cache Coherency BuS, CCB )与每个
CortexTM-A9 处理器进行通信。SCU 支持 MESI(Modified、ExcluSive、Shared、Invalid)
监测,通过避免进行不必要的系统访问以获得更高的效率和性能。SCU 模块在 L1 数据
高速缓存中实现了 4 路重复关联的 RAM 标签作为本地目录,来检查数据的相关性。该
目录允许 SCU 模块在不中断处理器的情况下以极快的速度检查数据是否在 L1 高速缓存
中。此外,SCU 模块可以将访问过滤到提供共享数据的处理器当中。
SCU 模块也可以从一个处理器缓存中复制“干净”的数据到另一个处理器的缓存中,
而不需要主内存来参与这个过程。此外,它还可以在处理器之间移动“脏”数据,同时避
免了共享写回操作造成的延迟。举个例子来说:处理器写存储时,只是写在了缓存里,
没有进主存,如果第二个 A9 读操作,涉及到第一个写脏了的数据段, SCU 要保证第
二个 A9 的缓存里是最新的数据。 如果第二个 A9 写同样数据段的数据,需要在第一
个中体现出写的内容。SCU 的存在,才使得两个核成互相联系的“双核”,才能成为 MPsoc
(Multi Processor System on Chip)。
在本论文所采取的方案中,CPU0 和 CPU1 通过共享 OCM 来进行通信,既然涉及
共享资源,就一定要有相关的措施来预防资源共享过程中可能造成的冲突,笔者在规划
该部分的策略时,就通过 SCU 对 OCM 相应缓存进行了相关限制,具体表现为 CPU0
先启动,其上面搭载的 linux 系统先 disable 通过 L2 进行的 fluShing,而 CPU1 在逻辑
启动时,也会在 BSP 中做类似的限制,详见论文第五章的内容。
(2) APU 接口
APU 是系统重最关键的部件,它将 PS、PL 内所实现的 IP、外部存取器和外设这样
的板级设备连在一起。如上图所示,APU 通过 L2 控制器的两个接口和一个到 OCM 的
接口(OCM 和 L2 高速缓存并列),APU 和系统剩余的部分进行通信。而在 APU 中,
有两类最重要的接口,一种是处理器中常见的中断接口,而另一种则是 Zynq-7000 非常
独特的加速一致性端口,PL 中 FGPA 可以通过此借口,实现对 APU 的硬件加速。ACP
接口在 APU 中的位置如上图左上角所示,在此,我们对这种比较比较特殊的稍作介绍:
加速一致性端口(Accelerator Coherence Port, ACP)是一个 64 位的从接口。它是这
样的一种端口:
1) 提供了一个异步缓存一致性的接入点,可以直接从 PL 端访问到 CortexTM-A9
MP-core 处理器的 SCU 端。PL 端可以使用该接口访问整个 APU 的高速缓存和
内存系统,从而简化软件软件实现,提高系统性能。
2) 该接口作为标准的 AXI 从设备,支持所有标准的读和写操作,而无需添加任何
Programable Logic 组件。
3) 这是一种在 PL 端加速器与 PS 端之间的,比传统的 Cache fluShiing 和 Cache
loading 更低的途径。
ZYNQ 芯片的存储体系是常见的多级存储体系,笔者在此并不对此多加赘述。然而
在对存储体系进行的访问操作上又体现出了 ZYNQ 的与众不同之处,对此我们在上文
SCU 的介绍中亦有简单提起过。ACP 接口也不例外,观察上图显示的 APU 内部模块连
接关系发现,ACP 接口也是通过 SCU 模块与各级存储设备相连的。事实上,任何通过
ACP 接口来读取一个连续内存区域块儿的操作,都不可能绕过 SCU 模块,而必须经过
这样的一个逻辑:SCU 模块会检查所需的信息是否已经存储到 L1 高速缓存(32KB 大
小)中。如果已经存在,则命中,数据将被直接返回;而如果未命中,即数据不在 L1
高速缓存中,则仍然有机会在下一级 L2 高速缓存(512KB 大小)中命中,如果都没有
命中,那么最终将会被转发到主存储器中。而对于通过 ACP 接口进行的写操作来说,
当执行写连续性的内存区域时,SCU 在写转入内存系统前将保持一致性。写操作可以被
有选择性地放入 L2 高速缓存中,以降低非必要时候写入片外存储器中带来的增加功耗
和降低性能的影响。
对于 APU 中另外一种接口:中断接口,鉴于它跟常见的处理器中断端口差别不大,
限于篇幅原因,本论文不再赘述。
3.1.2 ZYNQ 的 Programmable Logic
事实上,在 Zynq-7000 之前,高性能的通用处理器和 FPGA 这种大规模可重配置设备结合使用的需求已经出现。一方面,FPGA 的可重配置功能在很多领域,尤其是是信号处理领域,能提供可媲美 ASIC 的性能,另一方面,通用处理器技术已经很成熟,不仅能提供丰富的控制功能,同时也很容易使用 C 语言进行编程。二者的结合,使得应用程序能够分别根据 CPU 和 FPGA 所擅长的地方进行划分,从而达到开发期望的同时发挥各自的优势的结果。然而,在 ZYNQ 出现之前,二者只能通过片下的方式进行联合,即 CPU 把需要密集计算的部分 offload 到 FPGA 上实现,两者通过某种片外的接口相连,完成数据交互,而无法成为一个片上的系统(System on Chip)。
我们在上文中已经讲到,ZYNQ 使得高性能的通用处理器和 FPGA 成功成为一个片上系统,二者之间的通信不再是瓶颈,SoC 相应出现了一种全新的混合架构。这就为嵌入式开发提供了很多新的可能,在这种混合的架构上,通用处理器支持运行一个标准的操作系统,意味着旧有的软件可以无障碍地移植到 ZYNQ 的一个核上去,继续方便地实
现编程和交互;于此同时,可编程逻辑 Programmable Logic 的存在,提供了更多灵活的
用户接口,当程序中出现大量的并行行为或可并行转化的串行行为的时候,在 FPGA 上
实现该部分是再合适不过了。
本小节我们对论文中涉及可编程逻辑 Programmable Logic 的关键点们进行相应介
绍,包括 PL 的资源特性,PL 在 ZYNQ 中的地位和用例,以及本文实现的移动机器人
控制器方案所采用的,ZYNQ 独特的“平面模式”(Planar Pattern)。
Programmable Logic 可编程逻辑的资源特性
Zynq-7000 系列中的每个器件包含相同的 PS,然后每个期间内的 PL 和 I/O 资源有
所不同。两个容量较小的 Z-7010 和 Z-7020 的 PL 基于 Artix-7 FPGA,相对应两个容量
较大的 Z-7030 和 Z-7045 的 PL 基于 Kintex-7 FPGA。
通过使用多个接口和超过 3000 个中央互联结构,PL 和 PS 可以或松散或紧密地耦
合。PL 内创建的硬件加速器可以和其他功能进行高效地集成,处理器可以访问他们,
同时他们也可以访问 PS 内的存储器资源。
ZYNQ 总是最先启动位于 PS 中的通用处理器(通常是 CPU0),然后使用比特流对
PL 进行配置。对 PL 的配置可以作为系统启动的一部分,或者在将来的某个阶段对其进
行配置,既可以全部重新配置,也可以在使用的时候动态地部分重新配置(Partial
Reconfiguration, PR),例如更新系数或者用替换算法来实现分时复用 PL 资源。后者类
似于软件开发中动态地加载和卸载模块。PL 的配置数据是比特流文件,以.bit 后缀的文
件代表。
PL 提供了丰富的可供用户灵活配置的资源,再次我们仅仅介绍一下与本论文相关
的可配置逻辑块(CLB)、36Kb 块 RAM 等,这些是 ZYNQ 特有的资源。
1) CLB、Slice 和 LUT
CLB、Slice 和 LUT 是 FPGA 中特有的概念,也是常用来衡量程序耗费了多少资源
的性能指标。
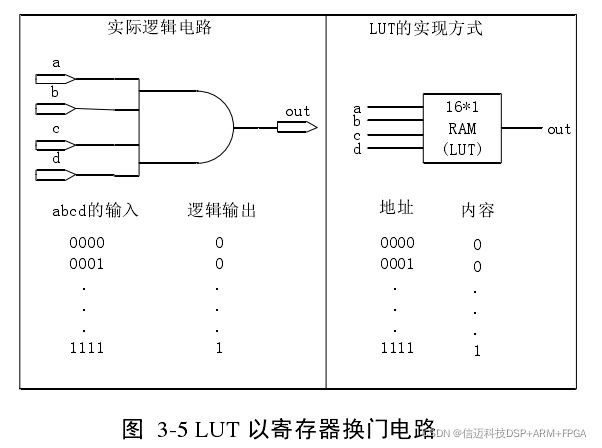
LUT 是 FPGA 中可编程逻辑的最小单元。图 3-5 所示是 LUT 以存储器换门电路的
原理图。Zynq-7000 内的 LUT 可以配置为一个带有 1 输出 6 输入 LUT(64 位 ROM)或
者带有独立输出和公共地址/逻辑输入的两个 5 输入 LUT(32 位 ROM)。一个 Slice 由 4
个这样的 LUT、8 个触发器、多路复用器和算术进位逻辑构成。两个 Slice 构成一个 CLB。
在一个设计重耗费了多少个 LUP,使用了多少个 CLB 常常是用来衡量程序是否简洁高
效的的指标。
2) 块 RAM
块 RAM 也是 FPGA 中特有的概念,称为 Block RAM,简称 BRAM。每个 Zynq-7000
有 60~465 个 BRAM,每个容量为 36Kb。每个 BRAM 有两个独立的端口。其关键特性
包括:
(1) 双端口
(2) 最大 72 位宽度
(3) 可配置为双 18Kb
(4) 可编程的 FIFO 逻辑和内建的 FIFO 逻辑
PL 在 ZYNQ 混合架构中的地位和用例
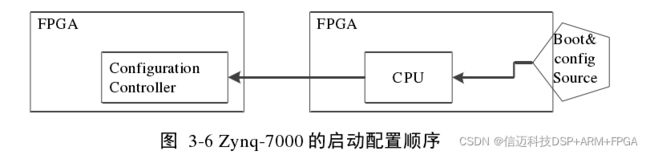
本文在该部分介绍 PL 在 ZYNQ 混合架构中的地位和用例。在 Zynq-7000 中,PL
总是后于 PS 启动,PS 使用比特流文件来配置 PL。如图 3-6 所示,这一点和其竞争对手
Altera 公司的竞品,同样作为混合架构的 FPGA/CPU 解决方案不同,后者的的 CPU 与
FPGA 的启动没有严格的顺序,FPGA 既可以后于 CPU 启动和配置,也可以先于 CPU
启动和配置,甚至 FPGA 和 CPU 可以分别独立地启动和配置[18]。
根据PL在Zynq中的功能地位不同,PL的常见用例主要有以下三种类型,如图3-7A、
B、C 所示:
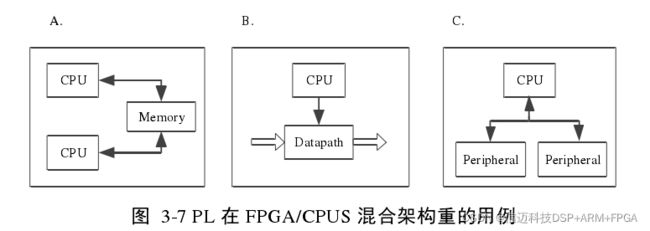
图 A 展示了一种 PL 和 PS 的结合方式[
18],即 FPGA 作为通用处理器的硬件加速器,
在这种情况下,计算密集的操作(常常是大量并行的行为或是可以转化为并行的串行行
为)会被分配到可编程逻辑 PL 中,以提高系统的性能。常见的应用有诸如在 PL 中设
计和放置 DSP 逻辑。
除了在 PL 中设计专用逻辑以实现硬件加速之外,PL 也可以作为一个伺服子系统来
使用,图 B 展示了另一种 PL 和 PS 的结合方式[18],在这种情况下,把实时任务放在 PL
中执行,而把非实时性任务放在 PS 中执行。这种分配策略构建了一种 ZYNQ 独有的“多
面结构”,这种结构中共存高速路径和低速路径。举个例子,在开发网络应用的时候,
高速路径负责包转发,低速路径负责一些控制功能。此时这种“多面结构”就是十分适合
的。
除了上述的两种用例之外,还有其他的情况,上图 C 展示了 PL 和 PS 结合的第三
种可能[18]。在该情况下,PL 用来扩展 PS 的外设接口,在 PS 中有一些资源紧张,放不
下的接口,可以通过在 PL 中添加相应的 IP 而引出而供用户使用,由于 FPGA 有丰富的
门电路资源(Z-7020 大约有 130 万门),因此大大扩展了 PS 的接口能力,我们在这里
可以添加 UART、IIC、CAN、USB、Ethernet 等常见的各种外设。在本论文中,CPU1
向Arduino 发送动作命令,进而驱动电机使机器人能够运动,就是在 PL中添加了 Uart_lite
IP 核。
3.1.3 ZYNQ 的工作模式
上文 PL 在 ZYNQ 的 FPGA/CPUS 的混合架构中的第二种用例已经讲过,CPU 和FPGA 作为两个子系统,可以无缝地连接,由于二者各有所长,那么我们就可以通过对
应用程序进行合理地划分,把适合 CPU 作的任务放在 PS 中,把适合 FPGA 做的任务放
在 PL 中,从而实现性能的优化。本文在该部分详细地介绍 ZYNQ 独有的 TPA 架构(Triple
Planar Architecture),这也是我们在实现自己的移动机器人控制器的时候,所采用的方案。
如图 3-8 所示,信迈科技XM_ZYNQ7020为我们提供了这样一个平台:双核的 ARM CortexTM A9 处理器+7 系列 FPGA 的混合体系结构,这样的体系结构可以被划分为三个“面”,这样的划
分称为“三面架构”或“多面架构”(Triple Planar Architecture,TPA),为了实现这样的架
构,处理器 CPU 要被配置成异步多核心处理系统[
18](Asymmetric Multiprocessing system ,AMP),而不是同步多核心处理系统(Symmetric Multiprocessing system ,SMP)。
在 AMP 模式下,CPU 的每个核可以独立地运行不同的操作系统,以适应不同的需
求,举个例子,可以在负责实时任务的“面”上运行实时操作系统 RTOS。AMP 模式通常
用于通讯系统/遥控系统,在这种场景下,CPU 的一个核心可以用来控制信息通道,并
对获得的信息进行处理,而剩下的 CPU 核心可以用来负责实现一些高性能的需求,如
报文的转发。
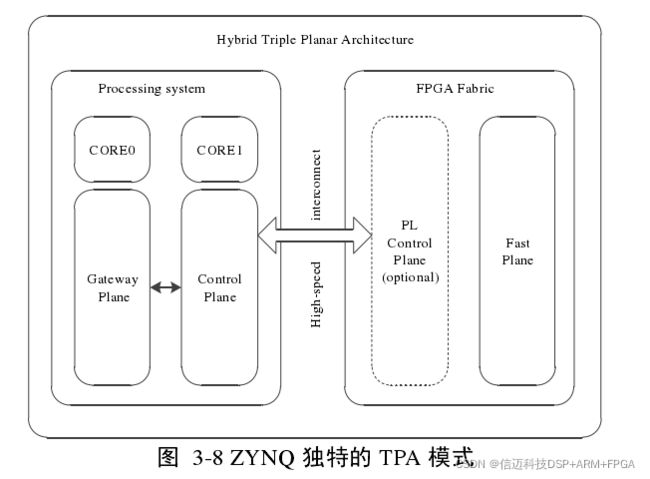
在该“三面架构”中,使用一个 CPU 核心负责和使用者进行交互(图中的 Gateway
Plane),用来接受用户的命令,另外一个 CPU 核心用来接收 Fast Plane 传来的信息,并
向其发送命令。它在描述的是类似这样的场景:传感器位于 Fast Plane 从获得了数据,
当获得了传感数据后,首先发送给 control plane,在此处完成数据格式的转换,然后被
发送给 gateway plane,通过 gateway plane 展示给用户。Gateway palne 再次把数据转化
为适合通信的格式(如 Ethernet 等)。如果 PL 中还需要实现控制乃至调度性较强的任务,
还可以选择性地在 FPGA 中加入软核,如著名的 MicroBlaze 和 Nios II,这要看实际需求。
本论文在实现自己的移动机器人控制器的时候,就使用了这种“三面架构”,在我们
自己的系统中,CPU0 负责实现人机的交互等高性能任务,在上面搭载 Linux 操作系统,
它接受 CPU1 传来的数据信息,并通过 http 协议转发给控制界面,用户可以通过控制界
面对机器人当前状态进行监控,并人为地下发动作指令给机器人,相当于上图中的
gateway plane,是系统三层结构中的交互层。CPU1 负责处理实时任务,相当于上图中
的 control plane,它从 fast plane 获得传感器的信息,经过格式转换后转发给 CPU0,同
时向驱动器发送动作指令,对应系统三层结构中的实时控制层。而在 PL 中创建负责触
发和调度 8~16 路超声波传感器的逻辑,PL 将获得传感器实时数据通过 AXI 告诉接口发
送给 CPU1,相当于上图中的 fast plane,对应系统三层结构中的驱动与传感层。