Serverless:基于个性化服务画像的弹性伸缩实践

作者 | zzbtie
导读
云原生环境下业务大规模迭代的成本压力日益增大。我们以Serverless理念为指导,针对百度Feed的后端服务,从弹性、流量、容量角度构建多维度个性化服务画像,并基于画像对服务进行弹性伸缩,随流量波动自适应调整服务容量,有效地降低业务运行成本,本文重点介绍上述相关策略与实践方案。
全文6542字,预计阅读时间17分钟。
01 背景
随着云原生在百度内部各产品线的推进,微服务已成为各业务线的标配,在搜索、推荐、广告这类重策略计算业务场景中,后端通常由很多微服务组成,这些微服务普遍存在如下特点:
-
实例多:每个服务由多个实例组成,微服务间通过rpc通信,服务一般支持横向/纵向扩缩容。
-
计算重:微服务包含比较复杂的业务逻辑,通常服务本地会加载一些策略词典进行复杂的策略计算,服务本身需要的cpu等资源比较多。
-
7*24h:服务通常使用固定的容量提供7*24h在线服务,并且由云原生组件进行定期的容量治理,例如冗余容量回收等。
百度App推荐服务(简称百度Feed)作为典型的推荐业务场景,后端包含众多策略复杂、重计算的微服务,这些后端服务普遍使用固定的容量为数亿级用户提供7*24h的信息流推荐服务。对于百度Feed的后端服务而言,用户流量存在着典型的波峰浪谷现象,而在流量低谷期和高峰期使用相同的容量无疑存在资源浪费,本文介绍百度Feed在后端服务进行Serverless的实践,详细说明基于服务画像的弹性伸缩相关技术方案与实现。
02 思路与目标
业界对Serverless的大规模实践在FaaS侧比较多,通常实例较轻量,容器的生命周期也比较短。而我们面对的是比较“重”的后端服务,这类服务的实例扩容通常包括以下几个阶段:
-
PaaS初始化容器:PaaS根据实例的quota需求(cpu、内存、磁盘等)寻找合适的机器分配容器,并初始化容器。
-
二进制文件与词典文件准备:将服务的二进制文件和词典文件从远程下载到本地,并进行解压。
-
实例启动:实例在本地根据启动脚本启动进程,并将实例信息注册到服务发现。
后端服务实例扩容的时间通常在分钟级,而词典文件的下载与解压一般占整体扩容时间70%以上,对于词典较大的实例则耗时更多,这导致后端服务面对流量变化时无法在极短的时间内(例如秒级)进行伸缩来保障容量稳定。然而这些后端服务的流量通常是周期性地波动,具有明显的潮汐特征,如果我们能对服务的流量进行较为准确的预测,那么面对流量的上涨我们可以适当地提前扩容来保障容量,面对流量下降可以进行一定的缩容来节省资源成本,实现资源按需使用。
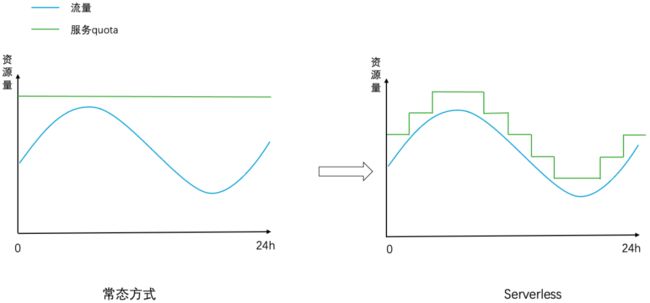
整体而言,我们以云原生组件为基础,为每个服务刻画出多维度的个性化服务画像,包括弹性维度、容量维度、流量维度,在保障服务稳定性的前提下实现服务容量随流量波动的自适应调整。实现效果如下图所示,左图中常态方式下一个服务消耗的资源量是固定的不随着流量波动而变化(资源量需满足峰值流量所需的容量),右图中Serverless模式下服务消耗的资源量随流量波动而动态调整。
03 整体架构
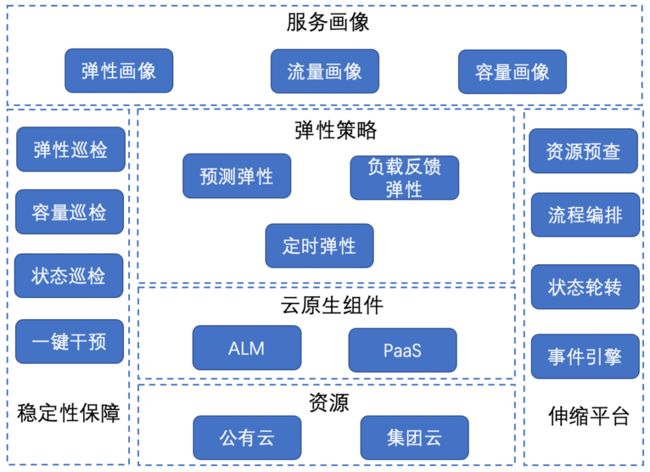
整体的弹性伸缩架构如下图:
-
服务画像:包括弹性画像、流量画像和容量画像,多维度刻画了服务的个性化特征。
-
弹性策略:应对不同场景下的伸缩策略,包括预测弹性、负载反馈弹性和定时弹性,是实现Serverless的基础核心策略。
-
云原生组件:包括PaaS和ALM(app lifecycle managent),其中PaaS负责执行服务的伸缩动作,ALM负责管理所有涉及服务的数据和策略。
-
资源:包括集团云和公有云两类弹性资源,Serverless支持两类云资源相关的服务伸缩。
-
稳定性保障:为弹性伸缩稳定性保驾护航的各类机制,包括弹性巡检、容量巡检、状态巡检和一键干预等。
-
伸缩平台:实现整体策略的支持平台,包括资源预查、流程编排、状态轮转和事件引擎等基础机制。
接下来分别介绍核心的策略和实践,包括服务画像、弹性策略、稳定性保障。
04 服务画像
百度Feed后端包含众多服务,各服务的词典文件大小不同,有些服务的cpu计算比较多,有些则io比较多,各服务在可伸缩性、流量波动情况和负载能力都存在差异。因此我们围绕服务的线上运行数据,从弹性维度、流量维度和负载维度构建个性化的弹性画像、流量画像和容量画像,多维度刻画出每个服务的个性化特点。
4.1 弹性画像
目标:从可伸缩角度刻画服务的伸缩能力。根据云原生指标、服务实例规格、实例部署迁移时间、资源依赖等维度刻画服务的弹性能力,将业务内各服务划分为如下三类:
高弹性能力:完全无状态服务,可随意无损伸缩,伸缩速度较快。
中弹性能力:有一定伸缩能力,但需要较长时间恢复服务状态,伸缩速度一般。
低弹性能力:几乎无伸缩能力,需要较大的代价恢复服务状态,伸缩速度较差。
弹性画像构建:
对各服务从PaaS拿到多条最近实例扩容记录获取实例扩容时间,取中位数作为该服务的实例部署时间,结合该服务的实例quota(cpu、memory、磁盘),是否有状态,是否存在外部依赖,通过简单的规则将所有服务划分为高、中、低弹性能力;同时我们推动服务进行标准化容器改造和存算分离来提升服务弹性。
弹性能力提升:
-
标准化容器改造:之前百度Feed业务内大部分服务实例都是非标准化容器,在端口隔离、资源混部方面存在缺陷,无法支持存算分离,影响服务的整体部署迁移效率;通过推进服务标准化容器改造,各服务已支持跨资源池、跨云调度部署,可充分利用各资源池的碎片化资源,提升了资源交付效率与混部能力,有效改善服务的弹性伸缩能力
-
存算分离:对于词典文件较大的后端服务,服务扩容的耗时集中在词典文件的下载与解压,我们推动该类服务接入云盘共享卷,服务实例部署时可远程读取词典内容加载到内存中,减少词典文件的下载和解压耗时,显著提升了服务的部署和实例迁移时间,有效提升了服务的弹性伸缩能力
4.2 流量画像
目标:
刻画服务的流量变化趋势,预测未来某个时间的流量进而方便根据流量配置对应的容量。
流量画像构建:
-
cpu使用量:虽然流量画像是根据历史流量数据来预测未来流量数据,但是我们不直接采集qps数据,而是使用cpu使用量来代替qps。主要原因是后端服务通常有多个rpc/http接口,不同服务的接口数量不同,而且一个服务内的不同接口的qps、性能存在差异,而单一接口的qps指标无法反应服务整体的资源消耗,这导致使用多接口qps数据和服务的资源消耗之间建立映射存在困难。后端服务主要的资源开销是cpu,而服务的cpu使用量是每个服务的单一通用指标,它直接反应了该服务在处理多接口请求时的整体资源开销,因此该指标相比qps能更直接的刻画出服务的容量需求。
-
时间片:后端服务的流量普遍呈24小时周期性波动,我们将一天24小时划分为多个时间片;对于每个服务,我们统计它的历史数据(例如过去N天在每个时间片对应的流量数据)并根据历史数据来预测未来某个时间片的流量情况。例如将24小时划分为24个时间片,每个时间片对应1个小时,我们想预测某个服务在下午2点~3点对应时间片内的流量情况,那么根据过去7天(N=7)该服务在下午2点~3点的流量数据来进行预测。其中,时间片的大小可配置,时间片配置的越小则对应时间范围越小,对于流量在单位时间变化较大的服务可配置较小的时间片,而流量波动较小的服务可配置较大的时间片。
-
监控采集:对每个服务,周期性地采集它所有实例的负载数据(包括cpu使用量等)汇聚为服务数据,并在对应时间窗口(window大小可配置)对数据进行平滑处理。例如每10s采集一个实例的cpu使用量汇聚为服务的cpu使用量,使用1分钟的时间窗口内服务的cpu使用量均值作为该时间窗口对应的数据。在监控采集和数据处理过程中,使用绝对中位差算法来剔除各类异常离群数据点。
-
画像构建:对每个服务,计算出过去N天每个时间片内各个时间窗口对应的cpu使用量,对一个时间片而言使用滑动窗口取其中最大的K个窗口数据均值作为该时间片的cpu使用量,这样可以得到每个服务在过去N天每个时间片内的cpu使用量数据;同时计算相邻两个时间片的流量增长率,即(下个时间片流量-当前时间片流量)/当前时间片流量。后续预测弹性中会根据时间片流量和流量增长率来预测未来某时间片的流量。
4.3 容量画像
目标:
刻画服务的容量需求,一般用该服务的峰值cpu利用率来代替。例如一个服务在稳定时峰值cpu利用率达60%表示至少为该服务留有40%的cpu buffer来保障其稳定性。
容量画像构建:
-
容量与延迟:假定服务吞吐和流量不变的情况下,该服务的延迟往往与留有的cpu buffer呈反比,即留有的cpu buffer越少,延迟增长的越多。在百度Feed业务线中,非核心链路上的服务即使有少量的延迟上涨,也不会对系统出口延迟有直接影响,因此相比核心链路,非核心链路上的服务可以留有较少的cpu bufffer。
-
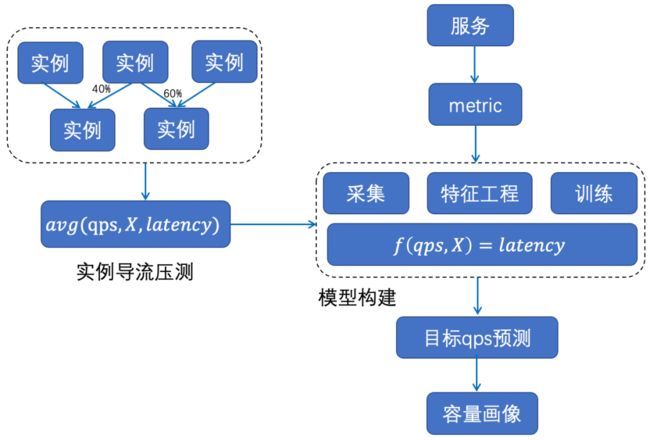
整体方法:不同服务的极限吞吐和对应的峰值cpu利用率是不同的,整体上通过机器学习方法为每个服务构建性能曲线,刻画出每个服务需要留多少cpu buffer合适,整体方法如下图。
-
特征获取:通过实例监控采集+实例导流压测获取不同负载下服务的延迟数据。
-
模型构建:对服务的qps、cpu利用率、机器负载等一系列容器和机器的监控指标与服务延迟关系进行建模:f(qps, X)=latency。
-
画像计算:基于延迟模型,评估各服务在延迟可接受范围内(核心服务延迟不允许上涨,非核心服务延迟允许一定阈值的上涨)的极限吞吐和对应的cpu利用率。
05 弹性策略
为应对不同的业务伸缩场景,我们构建如下三类弹性策略来支撑业务弹性伸缩:
预测弹性:对于弹性较低的服务,根据各时间片内的流量波动,对未来流量进行预测提前对服务容量进行规划调整。
负载反馈弹性:对于弹性较高的服务,根据近实时服务负载变化,及时对服务容量进行伸缩确保服务稳定。
定时弹性:有些服务在流量高峰期变化较大,在非高峰期变化较小,在高峰期需要提供最大容量来保障稳定性,在非高峰期不需要频繁调整容量,通过定时弹性在高峰期来临之前扩容,在高峰期过后进行缩容,高峰期和非高峰期期间容量保持不变。
5.1 预测弹性
目标:
根据服务配置的时间片,在当前时间片内对未来时间片的流量进行预测,根据预测流量对服务进行提前扩容、延迟缩容来应对不同的流量变化。
流量预测:
-
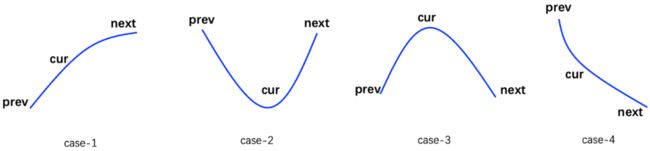
对于当前时间,结合流量画像中上个时间片流量、当前时间片流量和下个时间片流量来计算,其中上个时间片流量、当前时间片流量、下个时间片流量都取过去N天对应时间片的最大流量,分别记为prev、cur和next。
-
针对prev、cur、next的 大小关系,对流量趋势走向分为如下图4种case。
-
case-1:prev < cur < next,整体流量处于上涨趋势中;当前应该为下个时间片的流量上涨做好准备,进行提前扩容
-
case-2:prev > cur < next,整体流量从下降趋势扭转为上涨趋势;当前应该为下个时间片的流量上涨做好准备,进行提前扩容
-
case-3:prev < cur > next,整体流量从上涨趋势扭转为下降趋势,当前时间片处于流量高峰状态,不做任何动作
-
case-4:prev > cur > next,整体流量处于下降趋势,执行缩容动作
扩/缩容策略:
-
对于需要扩缩容的场景(如上case-1、case-2和case-4)分别计算出目标流量,其中目标流量=max(目标流量1,目标流量2)。
-
目标容量1根据上述4类case的流量来计算:
-
对于case-1和case-2,目标流量1等于next(相当于提前扩容)。
-
对于case-4,目标流量1等于cur(这里不是根据下个时间片的流量来缩容,否则容量可能扛不住当前时间片,这里仅根据当前时间片流量来缩容,相当于延迟缩容)。
-
目标流量2=当前流量*(过去N天当前时间片与下个时间片的最大增长率),其中当前流量采集最近K个时间窗口对应的cpu使用量。
-
根据目标流量和服务的容量画像(即该服务需要留多少cpu buffer)计算出目标容量,根据目标容量计算出该服务的目标实例数,联动PaaS对服务进行横向伸缩。
5.2 负载反馈弹性
目标:
根据服务近实时的负载情况,及时调整服务容量以应对流量突增变化。
扩/缩容策略:
-
数据采集:
-
通用监控:采集服务的近实时通用负载,例如cpu使用量,cpu使用率等。
-
自定义监控:支持以Prometheus metric方式自定义业务监控指标,例如服务的延迟指标、吞吐指标等。
-
采集周期可配置,通常使用滑动窗口的方式对监控指标进行聚合判断。
-
扩/缩容决策:根据服务的通用负载数据和自定义负载数据,结合服务的容量画像,计算出服务需要的目标实例数并进行横向扩缩容操作。
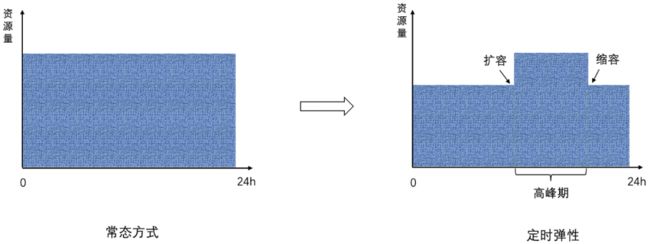
5.3 定时弹性
目标:
某些服务的流量在非高峰期波动较小没必要频繁调整容量,高峰期和非高峰期期望固定但不同的容量。
扩/缩容策略:
-
计算流量画像中高峰期和非高峰期内相应时间片的最大流量。
-
根据最大流量和容量画像计算服务在高峰期和非高峰期对应的目标容量。
-
根据目标容量,在高峰期来临之前定时触发扩容动作(横向扩容),在高峰期过后定时触发缩容动作(横向缩容),整体效果如下图。
5.4 弹性实践
-
上述三类弹性策略可根据配置分开独立使用,也可以按需组合使用:
-
对于弹性较高的function类计算,可使用负载反馈弹性实现FaaS效果,对于弹性较低的后端重计算服务,可三类弹性组合使用;
-
当三类策略组合使用时,由于都对服务的实例数进行调整并同时生效,三类策略之间存在优先级,定时弹性>预测弹性>负载反馈弹性;
-
当负载反馈弹性和预测弹性或定时弹性组合使用时,负载反馈弹性只能执行扩容动作不能进行缩容,缩容交由预测弹性或定时弹性执行。因为当某服务cpu负载比较低时,可能是因为预测弹性提前为下个时间片的流量做准备而进行扩容导致的,此时不能按照负载反馈弹性进行缩容,对定时弹性也是同理。
-
重试机制:
-
预测弹性和定时弹性的执行频率较低,涉及一些策略计算及调用PaaS对服务实例数进行修改,整体操作不是原子性的,需要有重试机制;
-
负载反馈弹性高频执行,可根据服务需求按需进行重试。
-
目标容量校验:上述每个弹性策略修改服务目标实例数都需要进行一定的校验。
-
限制目标实例数在合理区间范围:将目标实例数和每个服务容量画像中配置的实例上下限做比较,超过则平滑至上下限阈值;
-
限制单次扩缩容步长:将目标实例数和当前实例数做对比,限制每次扩缩容的比例,防止单次扩容太多导致资源不足,也防止缩容太多导致单实例流量飙升出现内存oom。
06 稳定性保障
如何在大规模频繁动态调整服务容量的同时保障服务稳定性至关重要,我们从巡检和干预止损的角度来建设相应稳定性能力,通过巡检防患于未然,通过一键干预快速止损。
弹性巡检:周期性地触发服务实例迁移,检验服务的弹性能力,提前暴露词典文件依赖异常等导致的伸缩失败。
容量巡检:为各类服务配置告警策略,周期性地巡检服务各项资源容量,当容量不足时触发告警或一键预案。
状态巡检:检查各服务状态是否正常轮转,防止服务状态异常,例如高峰期和非高峰期对应不同的服务容量状态。
一键干预:提供快速止损能力,定期线上演练防止能力退化,包括一键退出serverless预案、一键打开/关闭实例软硬限预案等。
07 总结
整体工作围绕Serverless展开,通过弹性、流量、容量多维度的服务画像刻画每个服务的个性化特点,基于画像构建多类弹性策略,满足服务各类伸缩场景,有效地实现服务资源按需使用。当前Serverless已落地百度Feed业务线10w服务实例数规模,有效地降低了业务运行成本。
接下来,Serverless将聚焦两个方向:热点事件的容量保障及应用机器学习提升流量画像预测精确度,持续接入更大规模的服务为业务创造价值!
——END——
推荐阅读:
图片动画化应用中的动作分解方法
性能平台数据提速之路
采编式AIGC视频生产流程编排实践
百度工程师漫谈视频理解
百度工程师带你了解Module Federation
巧用Golang泛型,简化代码编写