视频编辑场景下的文字模版技术方案

作者 | Lok’tar ogar
导读
本文根据度咔剪辑APP文字模版开发实践,分享视频编辑场景下,静态文字模版渲染能力的技术方案。作为富文本渲染方案的父集,此技术方案可以扩展到其他需要复杂富文本渲染的场景下。
全文6745字,预计阅读时间17分钟。
先睹为快
文字模版效果展示:

△文字模版在度咔剪辑中的应用
01 背景
视频创作工具的核心竞争力之一是其丰富的素材库,其中包括各种视频素材、音频素材以及贴纸素材等等。其中的文字模版也是不可或缺的一部分。文字模版提供了富文本的编辑功能,使用户能够在视频中添加更多样式优美的文字信息,从而增添了视频素材的多样性。此外,通过预设的样式,用户可以更加方便地选择适合自己的文字模版,节省了素材选择的时间,提升了用户体验。
在度咔的早期版本中,我们并没有提供文字模版这一素材类型。为了提升产品的竞争力和提高素材渗透率,我们进行了一定的研发工作,最终推出了文字模版素材。这些文字模版素材不仅可以满足用户的需求,而且可以为用户提供更多的创作灵感和思路。同时,我们也不断地更新和优化我们的素材库,以确保用户能够获得最新和最优质的素材资源。
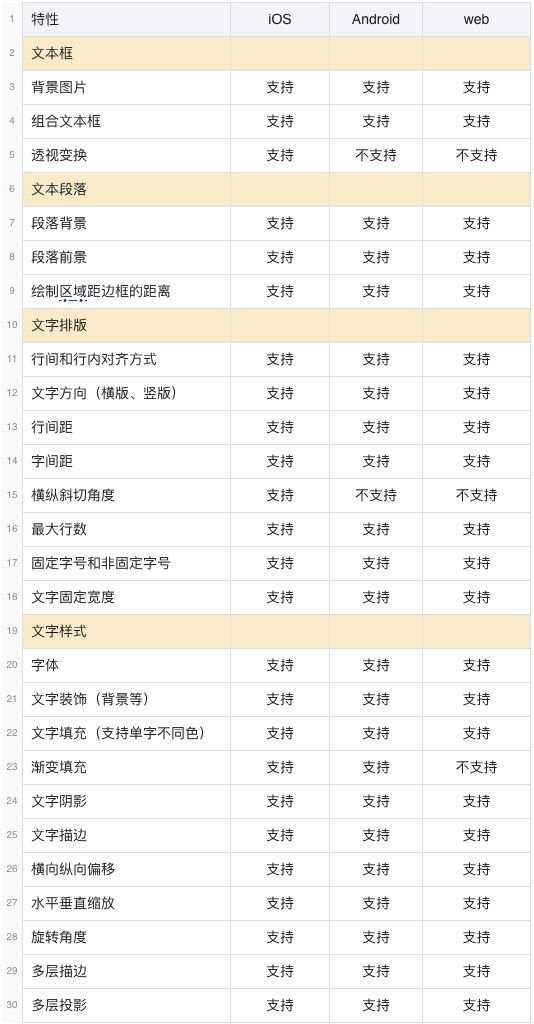
文字模版需要呈现的图文样式较为复杂,度咔文字模版已支持的特性见下面的列表:
02 整体设计
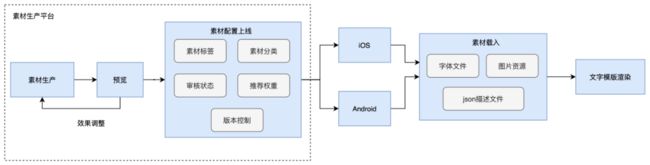
我们基于已建设的素材平台,新增了文字模版这一类型,并且在素材平台提供了素材编辑、预览、配置上线的功能。素材生产和预览相结合,可以在同一界面预览刚刚调整的效果,可以直接匹配度咔的字体库,以及直接修改图片资源。这种素材生产方式具有高可复用性,用一个文字模版,改一个背景图、新增一个描边,就可以直接生产出另一个文字模版。发布这一模版,并导出效果图,即进入待审核队列,审核后可配置上线。

截至目前,我们已上线了361套文字模版,并完成了【素材生产】-【素材平台预览】-【素材下发和客户端载入】-【客户端渲染】的完整链路。
03 功能实现
3.1 素材生产
目前视频编辑行业主流的素材格式通常采用资源文件和配置文件(描述文件)的方式进行。其中,资源文件包括图片资源和字体文件,而配置文件则主要用于描述文字模版的排版属性和渲染参数。这种方式的优点在于,生产端只需要通过特定字段来描述相关特性,就可以在渲染端呈现出来。这种方式灵活度较高,可以根据具体场景需要由简单到复杂地迭代相关特性,同时实现成本也相对较低。不过,缺点在于素材生产形式是自定义的,需要一定的设计学习成本。
除此之外,还有一种生产方式是针对专业设计软件的,以Photoshop(PS)为例。PS有比较成熟的文件格式文档,包含了各类数据结构,可以直接使用PSD文件解析图文属性进行渲染。这种方式的优点在于素材生产方式较为通用,设计几乎没有学习成本。不过,缺点在于我们需要的一些特性无法通过PSD简单地满足,比如多层阴影效果,其是由多个文本框层层叠加得到的效果。在修改文字内容的时候,我们需要同步修改这几个文本框,因此需要把它们作为一个组来处理,逻辑就变得比较复杂。如果用配置文件来描述,则可以直接进行多层绘制,免去复杂的逻辑处理。
考虑到业务ROI和短期上线功能的可行性,我们采用了第一种方式,并借鉴了黄油相机团队的素材生产标准,设计了用于描述排版属性和渲染参数的JSON结构。
3.2 端渲染
在视频编辑场景下,文字的处理需要进行文字排版和文字绘制两个部分的处理。对于文字排版,iOS平台采用了CoreText底层框架来进行排版处理,而Android则可以通过FontMetrics等获取底层FreeType对于字形处理的结果。不论是将一段文字作为整体进行排版处理,还是分别计算每个文字的位置,总的处理的性能消耗是相同的。
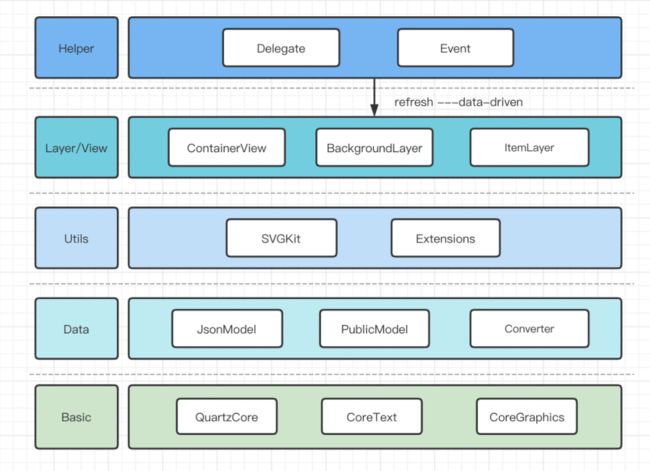
在进行文字绘制方面,需要在性能开销和开发成本之间寻求平衡。最终,iOS采用了QuartzCore框架,Android则使用Canvas来进行文字绘制。这样,在预览时,文字可以直接呈现在视图上,支持实时编辑预览。当需要将视频导出时,我们将其处理为贴纸的形式添加在视频中。以iOS为例,花字组件架构如下:
3.3 描述文件设计
上文提到,我们用json文件描述文字模版的排版属性和渲染参数,资源下发到客户端后,客户端会解析对应参数,来进行文字模版的排版和最终效果呈现。描述文件中会涉及以下内容:
(1)文字排版属性
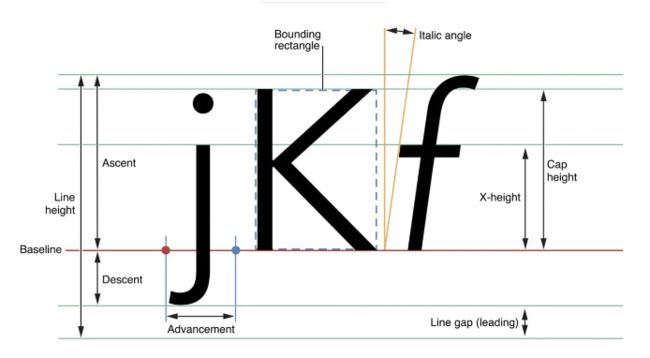
- baseline:字符基线,baseline是虚拟的线
- ascent:字形最高点到baseline的推荐距离
- descent:字形最低点到baseline的推荐距离
- leading:行间距,即前一行的descent与下一行的ascent之间的距离
- advance width:Origin到下一个字形Origin的距离
- left-side bearing:Origin到字形最左边的距离
- right-side bearing:字形最右边到下一个字形Origin的距离
- bounding box:包含字形的最小矩形
- x-height:一般指小写字母x最高点到baseline的推荐距离
- Cap-height:一般指H或I最高点到baseline的推荐距离
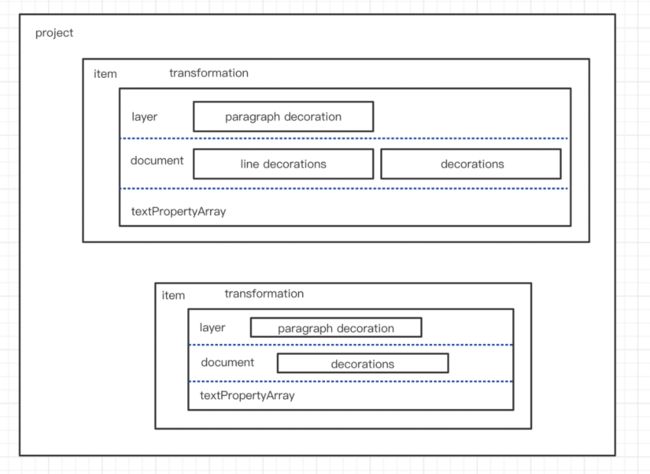
(2)文本对象组合
下图为两个文字绘制区域的组合示例
3.4 排版绘制流程
在我们的文字模版中,排版和绘制是密不可分的,需要在代码逻辑中穿插进行处理。我们的绘制步骤是从底层到顶层逐层绘制,但由于一些绘制过程会消耗大量时间,为了避免阻塞主线程,我们使用了异步绘制的技术。在异步绘制的过程中,我们将一些比较耗时的绘制过程放在了后台线程中进行处理,这样就能够不影响用户的正常使用。同时,在异步绘制的过程中,我们也会进行文字排版的计算,这样能够在后续绘制过程中快速获取到文字的相关信息,进而提高绘制效率。总的来说,我们通过采用异步绘制的方式,能够保证文字模版的排版和绘制过程顺利进行,同时也不会对用户造成太多的干扰。

04 难点与挑战
1、多端效果的对齐
我们的项目支持web、iOS和Android端的渲染,但由于通用的跨端方案需要在底层使用OpenGL渲染,而当时的人力资源限制使得短期内难以实现。因此,我们采用了多端独立渲染的方式,每个平台都有独立的渲染方案。这种方式也带来了一个问题:不同平台的渲染效果会有差异。
为了解决这个问题,我们需要保证多端效果的一致性。由于在技术层面难以抹平差异,我们决定通过规则和标准的统一来实现一致性。在设计json文件的格式时,我们就统一了多端渲染的标准,比如文字装饰相对于文字的初始位置是左上角对齐还是居中对齐,坐标原点的统一等。同时,我们还统一了对应的参数所用的单位,从而最大程度地保证了最终呈现效果的一致性。这样,无论在哪个平台上渲染,我们都能够得到一致的结果,使用户体验更加统一和良好。
2、文字预排版
在文字模版中,我们将字号分为两种类型:固定字号和非固定字号。对于固定字号,我们可以直接进行文字排版计算和绘制。然而,对于非固定字号的字体,我们需要进行预排版的计算,以算出当前文字内容下对应的字号大小。这里有些方案是采用二分法,先定一个较大的字号值,在0到该字号值的范围内逐渐逼近正确值,但这样其实造成了非必要的时间损耗,结合文字排版的基础逻辑和限定条件,我们可以做出时间复杂度接近O(1)的算法:计算最大字高->计算最小字高->计算字数最长行的字高->根据行数算字高->算出最终字高->根据字高算字号。iOS中用CoreText排版技术时,少部分情况会自动裁切填不满的文字,直接用计算出的字号会导致部分文字被裁切,所以要将以上结果作为估算结果,将size逐次减1,直至能填入path。
CGFloat ascent, descent;
UIFont *font = [self.calFont fontWithSize:size];
CTFontRef fontRefMeasure = (__bridge CTFontRef)font;
[attrString addAttribute:(id)kCTFontAttributeName value:(__bridge id)fontRefMeasure range:NSMakeRange(0, attrString.length)];
CTLineRef line = CTLineCreateWithAttributedString((__bridge CFAttributedStringRef)attrString);
CTLineGetTypographicBounds(line, &ascent, &descent, NULL);
//calculate max font size
CGFloat calFontHeight = MIN(height, width);
self.maxFontHeight = calFontHeight;
//calculate min font size
CGFloat maxLine = self.document.maxLine * BDTZBigFontDataOriginScale;
if (maxLine <= 0) {
maxLine = 1;
}
calFontHeight = [self itemWidth] / (maxLine + (maxLine - 1) * (self.leadingRatio * BDTZBigFontDataOriginScale - 1));
self.minFontHeight = MIN(self.maxFontHeight, calFontHeight);
// longest column
int64_t n = 0;
NSArray *strArray = [self.document.content componentsSeparatedByString:@"\n"];
NSString *measureStr = self.document.content;
// 这里是针对多行文本的处理,循环次数为行数,量级较小(一般为1-10行)
for (NSString *str in strArray) {
if (str.length > n) {
n = str.length;
measureStr = str;
}
}
CGFloat fontWidthRatioOrigin = (self.document.fontWidthRatio * BDTZBigFontDataOriginScale);
CGFloat trackingRatio = (self.document.trackingRatio * BDTZBigFontDataOriginScale) * (ascent + descent) / ascent;
CGRect rect = [@"我" boundingRectWithSize:CGSizeMake(CGFLOAT_MAX, CGFLOAT_MAX) options:NSStringDrawingUsesLineFragmentOrigin attributes:@{NSFontAttributeName:self.calFont} context:nil];
CGFloat fontWidthRatio = fontWidthRatioOrigin > 0 ? fontWidthRatioOrigin * (ascent + descent) / ascent : rect.size.width / rect.size.height;
CGFloat fontHeight = width / (n * fontWidthRatio + n * trackingRatio);
if (strArray.count > 1) {
//calculate font size accoring column count
calFontHeight = [self itemWidth] / (strArray.count + (strArray.count - 1) * (self.leadingRatio * BDTZBigFontDataOriginScale - 1));
//take the min value of the above two font sizes
fontHeight = MIN(fontHeight, calFontHeight);
}
if (fontHeight > self.maxFontHeight) {
fontHeight = self.maxFontHeight;
} else if (fontHeight < self.minFontHeight) {
fontHeight = self.minFontHeight;
}
CGFloat calSize = fontHeight;
calFontHeight = [self calculateFontHeightSize:calSize];
calSize = floorf(calSize / (calFontHeight * (ascent + descent) / ascent) * calSize);
//exact value, calculate repeatedly with frame until the path can be filled
//根据估算结果,将size逐次减1,直至能填入path,此处代码省略
if (calSize <= 0) {
return calSize;
}
calFontHeight = [self calculateFontHeightSize:calSize];
self.fontHeight = calFontHeight * (ascent + descent) / ascent;
self.font = [self.calFont fontWithSize:calSize];
3、绘制性能
文字模版的实时预览需要频繁绘制,这会对CPU带来较大的负担,从而导致卡顿。为了解决这个问题,我们必须采用异步绘制的方式。具体来说,我们可以创建一个异步的串行队列,来存储用户每次操作的文字内容状态。每当用户进行修改操作时,我们就将当前状态加入到队列中,等待后台线程进行异步绘制。当前一个状态绘制完成后,我们再从队列中取出下一个待绘制状态,直到所有状态都被绘制完毕。这样,既实现了异步绘制防止卡主线程,又将用户每次修改的结果完整呈现出来。
为了进一步优化文字模版的用户体验,除了异步绘制之外,还可以考虑使用缓存机制来提升渲染性能。在用户对文字模版进行操作时,文字视图会重新进行排版和绘制,如果每次都重新绘制整个模版,不仅会占用大量CPU资源,而且会降低用户体验。因此,我们可以使用缓存来存储已绘制的模版视图,当用户修改文字内容时,只需要重新绘制被修改的部分,而不是整个视图。通过这种方式,我们可以提高渲染性能,同时还能减少资源消耗,提高系统的响应速度。
4、内存优化
我们的文字模版主要用于视频编辑场景,用户需要根据具体情况对文字模版进行放大或缩小。如果使用纯矢量绘制刷新方式,当用户将文字模版放大到一定程度时,内存的占用量将非常高。此外,我们的用户在编辑器中通常会添加许多素材,如贴纸、特效和字幕等,而这些素材中单个占用内存较高,使用一段时间后,内存容易增加到OOM阈值,导致应用崩溃。因此,我们目前将单个文字模版的内存控制在20M以下,并根据不同视频宽高的画幅,计算出文字模版达到预期清晰度所需的宽高阈值,以实现清晰度和占用内存大小的平衡,每个文字模版都有一个不同的平衡参数。尽管这只是一个内存优化的细节,但对于我们控制素材的内存占用以及线上OOM率的控制起到了很大的作用。
05 结语
在视频编辑领域中,富文本渲染是一个相当复杂的过程。就端渲染而言,没有一种万能的解决方案,只有最适合特定场景的解决方案。在设计和实现文字模版渲染方案的过程中,有许多细节需要考虑。同时,还需要深入了解主流设计软件如PS、Figma等的文件格式。
我们团队提供了静态文字模版相关的技术方案,这些方案可以满足较为普遍的富文本渲染场景。整体思路对于文字排版和绘制都是大致类似的。在本文中,我们介绍了基础概念和富文本特性,以帮助读者更好地理解我们的技术方案。
然而,即使是我们提供的方案,实现起来也需要考虑许多细节。我们需要考虑字体的大小、颜色、对齐方式、字距、行距等因素,以确保渲染出来的富文本能够达到预期的效果。
因此,为了实现富文本渲染的最佳效果,需要投入大量时间和精力进行设计和实现。只有深入理解富文本的特性和设计原理,才能为用户提供高质量的视频编辑体验。
——END——
推荐阅读:
浅谈活动场景下的图算法在反作弊应用
Serverless:基于个性化服务画像的弹性伸缩实践
图片动画化应用中的动作分解方法
性能平台数据提速之路
采编式AIGC视频生产流程编排实践
百度工程师漫谈视频理解