hadoop系列之基础系列
一、Hadoop基础
1、分布式概念
通过爬虫-->爬到网页存储-->查找关键字
一台机器存储是有限的
Google采用多台机器,使用分布式的概念去存储处理
【关于计算】10TB数据,一台机器无法处理,可以用10台机器处理
每台机器可以处理1TB
Mapreduce额核心思想:分而治之
分为Map和Reduce
每个Map处理的数据是独立
Reduce就是合
10TB的数据“分”1TB,之后将结果“合”在一起存储
【关于存储】HDFS诞生-->分布式文件系统
数据存储在HDFS上,然后MapReduce进行处理HDFS上的数据
【分布式存储】分布式数据库:HBase
Google称它为:BigTable、DFS、MapReduce
【谷歌三驾马车】
2、Hadoop特性
可靠、可扩展、分布式计算框架
【存储的可靠性】:如果存储数据的机器损坏了
HDFS提供了一个策略,给数据提供一个副本数(默认三个)
牺牲了硬盘作为代价,但是是划算的
HDFS存储形式:以块存储
块损坏了,同样提供了一个策略,对每个存储文件会生产一个校验码,之后定期在对它生产一个校验码,进行匹配。如果不匹配,说明块已经损坏
【计算的可靠性】:
【可扩展性】可以添加任意的多台机器,添加配置
3、Hadoop四大核心模块介绍
Hadoop common:支持其他模块的工具类,为Hadoop模块提供基础设置
Hadoop HDFS:分布式文件系统,提供存储
Hadoop YARN:任务调度和集群资源管理
Hadoop MapReduce:分布式离线计算框架
4、Hadoop HDFS构架解析
设计理念,一次写入,多次读取
分布式应用都有主从的构架:
主节点(领导者):namenode
从节点:datanode
HDFS存储的是文件,文件的属性有哪些:
名称、位置、副本数、权限、拥有者(权限)、存储的块....以上这些信息称之为:元数据(命名空间)
元数据给到namenode进行存储
文件具体存储在datanode上
HDFS以块的形式存储,块block,1系列中块的大小为64MB,2系列中默认大小为128MB
500MB的文件,块大小为256MB,第一个块大小为:256MB,第二个块大小为:244MB
对于HDFS文件系统来说
read读
write写
读取流程:
/user/beifeng/mapreduce/input/wc.input
首先需要知道这个文件的位置,需要先去找namenode
“就近原则”
客户端-->namenode
客户端-->datanode
写的过程:
/user/beifeng/mapreduce/onput/part-00000
客户端-->namenode
客户端-->datanode
数据流并没有经过namenode,是客户端直接和对datanode进行交互,缓解namenode 工作的压力
5、YARN构架解析

分布式框架,也是主从框架
主节点:ResourceManager管理整个集群资源
从节点:NodeManger
客户端提交应用给ResourceManager
资源在各个的NodeManager上
YARN如何调度任务
客户端-->submit Job任务-->ResourceManager
任务分为Map和Reduce,一个job有很多任务,如何管理?
每一个应用都有一个APPmstr应用管理者
对于任务进行管理、监控和调度
应用管理者:ApplicationMaster
一个Map是在单独的资源里运行,不会被其他的任务抢走资源
为了实现这样的目的,提出了一个概念【Container容器】:
将任务放在某一个空间里,这个空间就属于某个任务
Map和Reduce所需资源都会放在一个容器中
容器在NodeManager中,任务在容器中运行
小结YARN:通过每个应用的应用管理者去申请资源然后封装在容器中,告诉资源管理者,然后容器中启动任务
Hadoop2系列才有的思想,Hadoop1系列设计比较冗余
二、HDFS
1、文件系统
1)NameNode
-
Namenode 是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间(namespace)以及客户端对文件的访问;
-
副本存放在哪些DataNode上由 NameNode来控制,根据全局情况做出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低带块消耗和读取时延;
-
Namenode 全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
-
-
文件操作,NameNode 负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过NameNode,只会询问它跟那个DataNode联系,否则NameNode会成为系统的瓶颈。
2)DataNode
-
一个数据块在DataNode以文件存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(数据块的长度、校验和、时间戳);
-
DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
-
心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,如果你对大数据开发感兴趣,想系统学习大数据的话,可以加入大数据技术学习交流扣群:458数字345数字782获取学习资源,或删除某个数据块。如果超过10分钟没有收到某个DataNode 的心跳,则认为该节点不可用。
-
集群运行中可以安全加入和退出一些机器
3)Block
-
文件切分成块(默认大小128M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3)
-
NameNode 是主节点,存储文件的元数据如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表以及块所在的DataNode等等
-
DataNode 在本地文件系统存储文件块数据,以及块数据的校验和
-
-
可以创建、删除、移动或重命名文件,当文件创建、写入和关闭之后不能修改文件内容。
4)数据损坏(curruption)处理
-
当DataNode读取block的时候,它会计算checksum
-
如果计算后的checksum与block创建时值不一样,说明该block已经损坏。Client读取其它DN上的block。
-
NameNode标记该块已经损坏,然后复制block达到预期设置的文件备份数
-
DataNode 在其文件创建后三周验证其checksum
2、初始化与启动
1)NameNode初始化(格式化)
-
创建fsimage文件,存储fsimage信息
-
创建edits文件
2)启动
-
NameNode加载fsimage和edits文件(到内存并保留),并生成新的fsimage和一个空的edits文件
-
DataNode向NameNode注册,发送Block Report

安全模式
-
安全模式下,集群属于只读状态。但是严格来说,只是保证HDFS元数据信息的访问,而不保证文件的访问,因为文件的组成Block信 -
息此时NameNode还不一定已经知道了。所以只有NameNode已了解了Block信息的文件才能读到。而安全模式下任何对HDFS有更新的操 -
作都会失败。 -
对于全新创建的HDFS集群,NameNode启动后不会进入安全模式,因为没有Block信息。
3)Secondary NameNode(运行时定期合并edits文件至fsimage,避免意外宕机丢失edits)

3、编程API
-
package org.apache.hadoop.hdfs.crud; -
-
import java.io.BufferedInputStream; -
import java.io.FileInputStream; -
import java.io.IOException; -
-
import org.apache.hadoop.conf.Configuration; -
import org.apache.hadoop.fs.FSDataInputStream; -
import org.apache.hadoop.fs.FSDataOutputStream; -
import org.apache.hadoop.fs.FileStatus; -
import org.apache.hadoop.fs.FileSystem; -
import org.apache.hadoop.fs.Path; -
import org.apache.hadoop.hdfs.DistributedFileSystem; -
import org.apache.hadoop.hdfs.protocol.DatanodeInfo; -
import org.apache.hadoop.io.IOUtils; -
-
-
public class HdfsCrud { -
-
//文件系统连接到 hdfs的配置信息 -
private static Configuration getConf() { -
// 创建配置实例 -
Configuration conf = new Configuration(); -
// 这句话很关键,这些信息就是hadoop配置文件中的信息 -
conf.set("fs.defaultFS", "hdfs://ns1"); -
return conf; -
} -
-
/* -
* 获取HDFS集群上所有节点名称信息 -
*/ -
public static void getDateNodeHost() throws IOException { -
// 获取连接配置实例 -
Configuration conf = getConf(); -
// 创建文件系统实例 -
FileSystem fs = FileSystem.get(conf); -
// 强转为分布式文件系统hdfs -
DistributedFileSystem hdfs = (DistributedFileSystem)fs; -
// 获取分布式文件系统hdfs的DataNode节点信息 -
DatanodeInfo[] dataNodeStats = hdfs.getDataNodeStats(); -
// 遍历输出 -
for(int i=0;i -
System.out.println("DataNode_"+i+"_Name:"+dataNodeStats[i].getHostName()); -
} -
// 关闭连接 -
hdfs.close(); -
fs.close(); -
} -
-
/* -
* upload the local file to the hds -
* 路径是全路径 -
*/ -
public static void uploadLocalFile2HDFS(String s, String d) throws IOException { -
// 创建文件系统实例 -
Configuration conf = getConf(); -
FileSystem fs = FileSystem.get(conf); -
// 创建路径实例 -
Path src = new Path(s); -
Path dst = new Path(d); -
// 拷贝文件 -
fs.copyFromLocalFile(src, dst); -
// 关闭连接 -
fs.close(); -
} -
-
/* -
* create a new file in the hdfs. -
* notice that the toCreateFilePath is the full path -
* and write the content to the hdfs file. -
*/ -
public static void createNewHDFSFile(String toCreateFilePath, String content) throws IOException { -
// 创建文件系统实例 -
Configuration conf = getConf(); -
FileSystem fs = FileSystem.get(conf); -
-
// 创建输出流实例 -
FSDataOutputStream os = fs.create(new Path(toCreateFilePath)); -
// 写入UTF-8格式字节数据 -
os.write(content.getBytes("UTF-8")); -
-
// 关闭连接 -
os.close(); -
fs.close(); -
} -
-
/* -
* 复制本地文件到HDFS(性能与缓存大小有关,越大越好,可设为128M) -
* notice that the toCreateFilePath is the full path -
* and write the content to the hdfs file. -
*/ -
public static void copytoHDFSFile(String toCreateFilePath, String localFilePath) throws IOException { -
// 读取本地文件 -
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(localFilePath)); -
-
// 创建文件系统实例 -
Configuration conf = getConf(); -
FileSystem fs = FileSystem.get(conf); -
// 创建HDFS输出流实例 -
FSDataOutputStream os = fs.create(new Path(toCreateFilePath)); -
-
-
// 两种方式其中的一种一次读写一个字节数组 -
byte[] bys = new byte[128000000]; -
int len = 0; -
while ((len = bis.read(bys)) != -1) { -
os.write(bys, 0, len); -
os.hflush(); -
} -
-
// 关闭连接 -
os.close(); -
fs.close(); -
} -
-
-
/* -
* read the hdfs file content -
* notice that the dst is the full path name -
* 读取文件,返回buffer【需要再print】 -
*/ -
public static byte[] readHDFSFile(String filename) throws Exception { -
// 创建文件系统实例 -
Configuration conf = getConf(); -
FileSystem fs = FileSystem.get(conf); -
-
// 创建路径实例 -
Path readPath = new Path(filename); -
-
// 检查文件是否存在 -
if (fs.exists(readPath)) { -
FSDataInputStream is = fs.open(readPath); -
// 获取文件信息,以便确定buffer大小 -
FileStatus stat = fs.getFileStatus(readPath); -
-
// 创建buffer -
byte[] buffer = new byte[Integer.parseInt(String.valueOf(stat.getLen()))]; -
-
// 读取全部数据,存入buffer -
is.readFully(0, buffer); -
-
// 关闭连接 -
is.close(); -
fs.close(); -
-
// 返回读取到的数据 -
return buffer; -
}else{ -
throw new Exception("the file is not found ."); -
} -
} -
/* -
* 直接读取、打印文件 -
*/ -
public static void read(String fileName)throws Exception { -
// 创建文件系统实例 -
Configuration conf = getConf(); -
FileSystem fs = FileSystem.get(conf); -
-
// 创建路径实例 -
Path readPath = new Path(fileName); -
-
// 读取数据,打开流文件 -
FSDataInputStream inStream = fs.open(readPath); -
-
try{ -
// 读取流文件,打印,缓存4096,操作后不用关闭 -
IOUtils.copyBytes(inStream, System.out, 4096, false); -
}catch(Exception e){ -
e.printStackTrace(); -
}finally{ -
// close steam -
IOUtils.closeStream(inStream); -
} -
} -
-
/* -
* delete the hdfs file -
* notice that the dst is the full path name -
* 删除HDFS文件 -
*/ -
public static boolean deleteHDFSFile(String dst) throws IOException { -
// 创建文件系统实例 -
Configuration conf = getConf(); -
FileSystem fs = FileSystem.get(conf); -
-
// 创建路径实例 -
Path path = new Path(dst); -
-
// 删除文件,并返回是否成功 -
@SuppressWarnings("deprecation") -
boolean isDeleted = fs.delete(path); -
-
// 关闭文件连接 -
fs.close(); -
-
// 返回操作结果 -
return isDeleted; -
} -
-
/* -
* make a new dir in the hdfs -
* the dir may like '/tmp/testdir' -
* 创建目录 -
*/ -
public static void mkdir(String dir) throws IOException { -
// 创建文件系统实例 -
Configuration conf = getConf(); -
FileSystem fs = FileSystem.get(conf); -
-
// 创建路径 -
fs.mkdirs(new Path(dir)); -
-
// 关闭文件连接 -
fs.close(); -
} -
-
/* -
* delete a dir in the hdfs -
* dir may like '/tmp/testdir' -
* 删除目录 -
*/ -
@SuppressWarnings("deprecation") -
public static void deleteDir(String dir) throws IOException { -
// 创建文件系统实例 -
Configuration conf = getConf(); -
FileSystem fs = FileSystem.get(conf); -
-
// 删除目录 -
fs.delete(new Path(dir)); -
-
// 关闭文件连接 -
fs.close(); -
} -
-
/** -
* @Title: listAll -
* @Description: 列出目录下所有文件 -
* @return void 返回类型 -
* @throws -
*/ -
@SuppressWarnings("deprecation") -
public static void listAll(String dir) throws IOException { -
// 创建文件系统实例 -
Configuration conf = getConf(); -
FileSystem fs = FileSystem.get(conf); -
-
// 获取目录列表 -
FileStatus[] stats = fs.listStatus(new Path(dir)); -
// 遍历打印 -
for(int i = 0; i < stats.length; ++i) { -
if (!stats[i].isDir()){ -
// regular file -
System.out.println(stats[i].getPath().toString()); -
}else{ -
// dir -
System.out.println(stats[i].getPath().toString()); -
} -
} -
-
// 关闭文件连接 -
fs.close(); -
} -
-
public static void main(String[] args) throws Exception { -
-
//getDateNodeHost(); -
-
//uploadLocalFile2HDFS("E:/1.txt","/tmp/1.txt");//E盘下文件传到hdfs上 -
-
//createNewHDFSFile("/tmp/create2", "hello"); -
copytoHDFSFile("/tmp/create2", "C://user_visit_action.txt"); -
//System.out.println(new String(readHDFSFile("/tmp/create2"))); -
//readHDFSFile("/tmp/create2"); -
//deleteHDFSFile("/tmp/create2"); -
-
//mkdir("/tmp/testdir"); -
//deleteDir("/tmp/testdir"); -
listAll("/tmp/"); -
} -
-
}
三、YARN资源管理
1、各模块职能

2、内存、CPU资源

目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念,初衷是考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。
集群资源
-
-
yarn.nodemanager.resource.memory-mb -
10240 -
-
-
-
yarn.nodemanager.resource.cpu-vcores -
4 -
任务分配设置
-
-
yarn.scheduler.minimum-allocation-mb -
256 -
-
-
yarn.scheduler.maximum-allocation-mb -
30720 -
-
-
-
yarn.scheduler.minimum-allocation-vcores -
1 -
-
-
yarn.scheduler.maximum-allocation-vcores -
12 -
四、MapReduce编程
1、简介
-
一种分布式计算模型,解决海量数据的计算问题
-
MapReduce将整个并行计算过程抽象到两个函数
-
Map(映射):对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行。
-
Reduce(化简):对一个列表的元素进行合并。
-
一个简单的MapReduce程序只需要指定map()、reduce()、input和output,剩下的事由框架完成。

2、数据类型与编程格式
数据类型都实现Writable接口,以便用这些类型定义的数据可以被序列化进行网络传输和文件存储。
1)基本数据类型
-
BooleanWritable:标准布尔型数值
-
ByteWritable:单字节数值
-
DoubleWritable:双字节数值 FloatWritable:浮点数
-
IntWritable:整型数 LongWritable:长整型数
-
Text:使用UTF8格式存储的文本
-
NullWritable:当
2)程序相关
Writable - value
-
write() 是把每个对象序列化到输出流。
-
readFields()是把输入流字节反序列化。
WritableComparable - key必须要实现
Java值对象的比较:重写 toString()、hashCode()、equals()方法
3)编程格式
MapReduce中,map和reduce函数遵循如下常规格式:
map: (K1, V1) → list(K2, V2)
reduce: (K2, list(V2)) → list(K3, V3)
Mapper的基类:
protected void map(KEY key, VALUE value, Context context) throws IOException, InterruptedException {
}
Reducer的基类:
protected void reduce(KEY key, Iterable values, Context context) throws IOException,InterruptedException {
}
Context是上下文对象

详细代码



}
详细代码源码请在公众号,输入:代码。获取
4)优化项



3、Shuffle与MapReduce的优化
http://blog.csdn.net/shubingzhuoxue/article/details/50241907
1)Shuffle
MapReduce确保每一个reduce的输出都按键排序,系统执行排序的过程---------将map输出作为输入传给reduce--------称为shuffle
Shuffle过程是MapReduce的”心脏”,也被称为奇迹发生的地方

>> 内存
默认情况下:100MB
环形缓冲区
当内存80 MB(80%)默认情况下,将会将数据spill(溢写)到本地磁盘目录中。
>> spill 磁盘
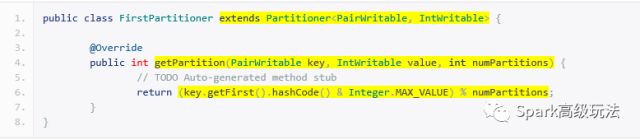
>>> 分区partitioner【默认按hashcode进行分区,可设置更改规则】
决定map输出的数据,被哪个reduce任务进行处理
>>> 排序sorter
依据key
会对分区中的数据进行排序
>>> 溢写spill
将内存数据写到本地磁盘
当map()处理数据结束以后,会输出很多文件,会将spill到本地磁盘的文件进行一次合并(过程中溢写文件超过一定数目也会进行多次合并,具体请参考hadoop权威指南)
>> merge 合并
>>> 将各个文件中各个分区的数据合并在一起
>>> 排序
最后形成一个文件,分区完成的,并且各个分区中的数据已经完成排序。
----(可选)
-
每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
-
写磁盘前,要partition,sort。如果有combiner,combine排序后写数据。
-
partition的意义在于可以分区管理,分类导出数据;例如男女,我需要分成两个文件,我就可以设置partition来区分,reduceTask至少2个来分别运行
-
运行conbiner的意义在于是map输出更紧凑,使得写到本地磁盘和传给reducer的数据更少
-
-
等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
补充:
-
Reducer通过Http方式得到输出文件的分区。
-
TaskTracker为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内存或磁盘。一个Map任务完成,Reduce就开始复制输出。
-
排序阶段合并map输出。然后走Reduce阶段。
2)MapReduce资源参数
-
Map默认CPU一个/内存1G/缓冲区100M/spill临界值0.8,Reduce默认CPU一个/内存1G/缓冲区200M;
-
内存决定生死,CPU决定快慢

