面试官:介绍一下 Redis 三种集群模式
小码今天去面试。
面试官:给我介绍一下Redis集群,
小码:啊,平时开发用的都是单机Redis,没怎么用过集群了。
面试官:好的,出门右转不谢。
小码内心困惑:在小公司业务量也不大,单机的 Redis 完全够用,也不会发生宕机问题啊。面试要问到 Redis 集群该怎么办呢?
Redis 为何要有集群
很多小伙伴也有类似的困惑,自己的公司并不大。并发量、访问量要求不高,使用单机 Redis 就能很好的解决数据请求的问题。为啥要使用集群呢?
对于访问量小、并发低的系统,对数据的高可用要求不高的数据,单机部署都能满足需求。但是在大公司,随便一个系统的QPS都是成千上万,对系统的高可用、高并发要求比较高,这个时候就需要要使用Redis集群模式了,Redis有三种集群模式:
- 主从复制模式
- 哨兵模式
- Cluster 模式
主从复制模式
Redis想要不丢失数据,就需要开始持久化,数据会写入到磁盘中,这样即使服务关闭再重启服务器后,数据也能从硬盘加载到内存中。但是如果服务器的硬盘出现故障,也会导致数据丢失。
为了避免硬盘故障问题,需要将数据复制的多个副本上,这样即使一个服务出现故障,其他服务器也能提供数据服务。
Redis提供了主从模式,一个主数据库master绑定多个从数据库slave:

主数据可以读和写,从数据库一般是只读,主从库之间采用读写分离,主数据库数据更新后同步复制给绑定的从数据库,主从数据库的数据保持一致:
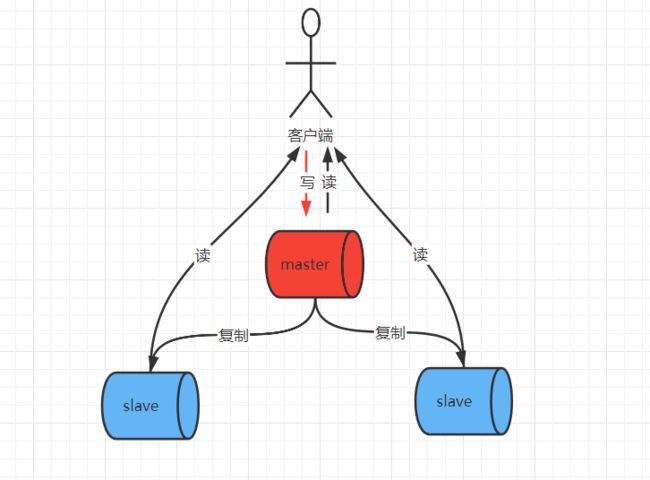
数据主从同步原理
- 从数据库启动后,连接主数据库,发送
SYNC命令。 - 主数据库接收到SYNC命令后,开始执行
BGSAVE命令生成RDB文件并使用缓冲区记录后面执行的所有写命令。 - 主数据库执行完
BGSAVE命令之后,向所有从数据库发送RDB文件。从数据库加载RDB文件。 - 主数据将记录的缓存区所有的写命令发送给从数据库,从数据库执行命令。

SYNC每次从服务重启,都会请求所以的数据。如果服务宕机再重启还是同步所有的数据,就会造成资源的浪费,所以有了PSYNC命令,PSYNC有完整同步和部分同步,其中完整同步和SYNC一致,而部分同步是根据数据偏移量复制数据。
主从复制服务搭建
Redis单机搭建可以查看前面写的的教程
Centos安装单机Redis
首先创建三个文件夹6380、6381、6382:
mkdir 6380
mkdir 6381
mkdir 6382
复制redis.conf到这三个文件夹里:
cp redis.conf 6380/
cp redis.conf 6381/
cp redis.conf 6382/
配置一主两从,6380为主,6381、6382为从。然后修改redis.conf 文件:
| 参数 | maser (6380) | slave1 (6381) | slave2 (6382) |
|---|---|---|---|
| port | 6380 | 6381 | 6382 |
| requirepass | requirepass “xxxx” | requirepass “xxxx” | requirepass “xxxx” |
| slaveof | slaveof 本机ip 6380 | slaveof 本机ip 6380 | |
| masterauth | masterauth ”xxx“ | masterauth ”xxx“ | |
| pidfile | pidfile /redis_6380.pid | pidfile /redis_6381.pid | pidfile /redis_6382.pid |
| logfile | logfile “redis_6380.log” | logfile “redis_6381.log” | logfile “redis_6382.log” |
设置了requirepass,就需要设置masterauth,三台服务器的密码需要一致。
启动服务器:
[root@instance-3 redis]# bin/redis-server 6380/redis.conf
[root@instance-3 redis]# bin/redis-server 6381/redis.conf
[root@instance-3 redis]# bin/redis-server 6382/redis.conf
然后查看进程,如果有以下的显示,说明启动成功了:
[root@instance-3 redis]# ps -ef |grep redis
root 6652 1 0 16:28 ? 00:00:00 bin/redis-server *:6380
root 6665 1 0 16:28 ? 00:00:00 bin/redis-server *:6381
root 6682 1 0 16:28 ? 00:00:00 bin/redis-server *:6382
root 7188 4291 0 16:30 pts/0 00:00:00 grep --color=auto redis
进入Redis客户端,使用info replication命令查看数据库的信息。
master 6380:
[root@instance-3 redis]# bin/redis-cli -p 6380
127.0.0.1:6380> auth xxxx
OK
127.0.0.1:6380> info replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=42,lag=0
slave1:ip=127.0.0.1,port=6382,state=online,offset=42,lag=1
master_replid:19ca382e3c05014988002a295078687dae9bb92e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:42
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:42
role:master表示 6380 是主服务器,slave0和salve1表示绑定的从服务器。
slave 6381:
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_repl_offset:126
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:19ca382e3c05014988002a295078687dae9bb92e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:126
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:126
role:slave表示 6381 是从服务器,master_host和master_port表示绑定对应的主服务器。
slave 6382:
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:476
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:19ca382e3c05014988002a295078687dae9bb92e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:476
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:476
role:slave表示 6382 是从服务器,master_host和master_port表示绑定对应的主服务器。
主服务器添加数据,再从从服务器获取数据。
6380服务器添加数据:
127.0.0.1:6380> set name jeremy
OK
6381服务器获取数据:
127.0.0.1:6381> get name
"jeremy"
经过以上测试,说明主服务器的数据,从服务器也能同步获取。主从服务都搭建成功。
主从模式的优缺点
-
优点
- 主从模式搭建多个服务器,即使单个服务宕机,还能继续服务。
- 读数据压力分解到多个服务器下,大大缓解服务器的压力。
-
缺点
- 主数据库宕机了,宕机后的数据无法同步到从从数据库,导致数据库不一致。
- 主数据库宕机了,无法自动生成新的主机,新的读请求也无法处理。
- 每个服务器都保存相同的信息,比较浪费内存。
- 因为这些问题,
Spring Boot也不支持集成Redis主从模式。
主从模式最大的问题就是无法处理主数据库宕机问题,也就无法保证
Redis的高可用性。这就需要有一个自动的机制处理主数据库宕机问题,这就延伸出下面的模式 —— 哨兵模式。
哨兵模式
当主数据库挂了之后,需要手动设置新的主数据库,其他从数据库都需要重新设置新的主数据。手动切换的成本比较大,还会导致一段时间的服务不可用。这就需要讲上面的手动设置改成自动设置,也就是使用哨兵来配置。
哨兵Redis的高可用解决方案,哨兵监控Redis主服务器和绑定的从服务器,如果主服务器宕机了,自动将某个从服务器升级为新的服务器,然后发送通知给其他从服务器。
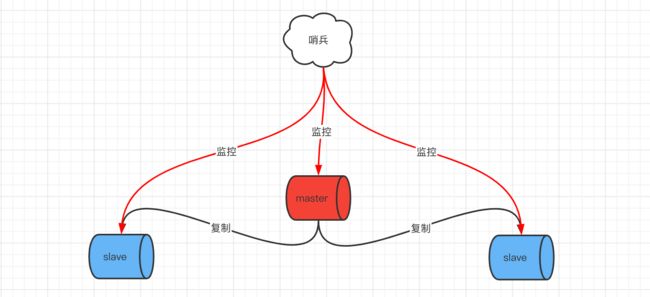
哨兵基本原理
哨兵是一个独立的进程,和Redis一样,它也运行一个实例。主要有三个任务:
- 监控: 周期给所有的主从数据库发送
PING命令,检查主从数据库运行是否正常,在设置down-after-milliseconds毫秒,没有服务响应,就会标记主观下线,当其他哨兵也判断主观下线,判断主观下线的数量达到设置的值后,哨兵之间会进行投票,投票同意后,进行数据库升级。 - 自动切换主从数据库: 当上面的投票同意后,会根据一定的规则选取一个从服务器升级成主服务器。更新
redis.conf配置文件。 - 通知:完成主服务器升级之后,哨兵通过发布订阅会把新主数据库的连接信息发送给其他从数据库,修改对应配置文件的
replicaof命令,和新数据库建立连接,并进行数据复制。
哨兵服务搭建
在上面的主从模式的基础上添加哨兵,首先从解压文件夹复制sentinel.conf到usr/local/redis文件夹中:
cp sentinel.conf /usr/local/redis/
修改sentinel.conf文件,需要修改的部分:
daemonize no改成daemonize yeslogfile ""改成logfile "redis_26379.log"- 添加
sentinel monitor,设置成sentinel monitor mymaster 127.0.0.1 6382 1ip主数据库IPredis-port主数据库端口quorum主从切换需要达到主动下线个数
- 如果数据库有密码,添加
sentinel auth-pass mymaster 123456,表示验证密码mymaster哨兵的名称,需要唯一123456数据库密码,所有主从数据库密码需要设置成一致。
启动服务器:
[root@instance-3 redis]# bin/redis-sentinel sentinel.conf
查看logfile启动日志:

看最后标记的三行,表明哨兵分别监控了主数据库
6380、两个从数据库6381、6382。有上面的日志输出表明哨兵已经成功启动。
模拟主从切换
使用SHUTDOWN命令关闭6380主数据库服务:
[root@instance-3 redis]# bin/redis-cli -p 6380
127.0.0.1:6380> shutdown
(error) NOAUTH Authentication required.
127.0.0.1:6380> a
[root@instance-3 redis]# bin/redis-cli -p 6380
127.0.0.1:6380> auth xxx
OK
127.0.0.1:6380> SHUTDOWN
通过ps -ef |grep redis查看6380已经关闭:
[root@instance-3 redis]# ps -ef |grep redis
root 8822 1 0 Nov21 ? 00:00:58 /usr/local/redis/bin/redis-server *:6379
root 24707 1 0 10:35 ? 00:00:02 bin/redis-server *:6381
root 27500 1 0 10:47 ? 00:00:01 bin/redis-server *:6382
root 29247 1 0 10:54 ? 00:00:03 bin/redis-sentinel *:26379 [sentinel]
root 34131 17210 0 11:16 pts/1 00:00:00 grep --color=auto redis
查看哨兵日志logfile:
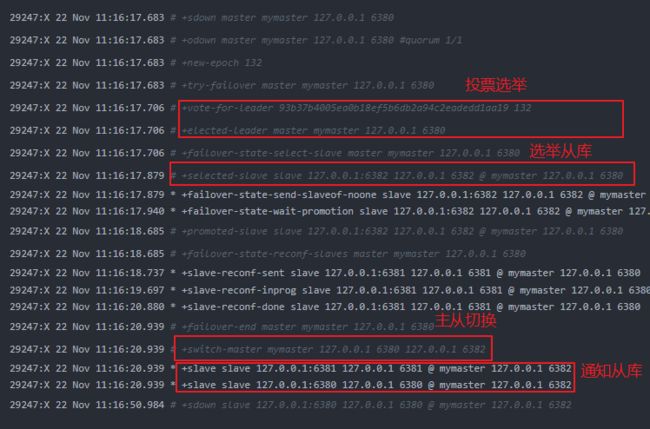
表明主服务器从
6380成功切换到了6382,sentinel.conf配置文件也修改了主从数据库配置。如果没有切换成功,日志报错-failover-abort-no-good-slave,可能是没有设置验证密码sentinel auth-pass。
哨兵模式的优缺点
- 优点
- 哨兵模式是基于主从模式,主从模式的优点,哨兵模式都有。
- 哨兵模式使用独立进程监控服务,自动切换宕机数据库,保障服务的高可用。
- 缺点
- 受限于单个服务器,很难实现单节点在线扩容。
- 每个服务器都保存相同的信息,比较浪费内存。
Cluster(官方推荐)集群
主从模式和哨兵模式数据库都存储了相同的数据,比较浪费内存。而且当数据量增加时,在单个数据库上很难实现在线扩容。Redis Cluster将数据分布存储在不同的节点上,每个节点存储不同的数据。添加节点就能解决扩容问题。
Redis Cluster翻译就是Redis集群,Redis集群提供分布式解决方案,通过分片将数据拆分到不同的节点上,并提供复制和故障转移功能。使用了水平扩展的方法,将数据分发到不同的数据库中。

每个虚线圆都表示一个节点,每个节点都有一个主数据库和多个从数据库。任意两个节点都是相同的(三个节点画图容易误以为是一个环,四个节点容易理解),节点之间都共享数据。
分片集群原理
Redis分片集群,使用了一种类似于一致性哈希的分片技术——哈希槽,每个键都有一个哈希槽的值,Redis 集群有16384个哈希嘈,对键的CRC16取模16384计算出哈希槽,以此决定放置的哈希嘈的位置。
Redis集群中每个节点都负责一部分哈希嘈,比如,集群有三个节点,其中:
- 节点 A 包含 0 到 5460 号哈希槽
- 节点 B 包含 5461 到 10922 号哈希槽
- 节点 C 包含 10923 到 16383 号哈希槽
数据根据哈希嘈分配到不同的数据库中,实现数据的分片。这里添加或者减少一个节点就比较容易了。比如,我想添加一个新的节点D,需要将节点A、B、C一部分数据移动到节点D中。而删除一个节点A,就将原来A节点的数据分发到其它节点上。
Redis集群主从模式
为了保证高可用,Redis Cluster也使用了主从模式。节点(上图虚线圆)宕机了,就无法提供继续数据服务了。当节点引入主从模式后,主服务宕机之后,从服务器升级成主服务。但是如果一个节点的所有主从服务服务都宕机了,该节点就无法提供数据服务了。
集群模式搭建
最小集群必须最少包含三个节点,这里部署使用三个主节点,三个从节点。一共有六个配置文件,端口分别是7001、7002、7003、7004、7005、7006。
复制redis.conf配置文件命名redis_7001.conf,修改以下字段:
# 端口
port 7001
# 启用集群模式
cluster-enabled yes
# 保存其他节点的名称、状态等信息,命名和端口保持一致
cluster-config-file nodes_7001.conf
logfile "redis_7001.log"
daemonize yes
protected-mode no
其他五个文件分别复制redis_7001.conf文件,文件名分别是:
redis_7002.confredis_7003.confredis_7004.confredis_7005.confredis_7006.conf
根据文件名修改修改port、cluster-config-file、logfile三个属性,比如redis_7002.conf的配置修改以下字段:
port 7001
cluster-config-file nodes_7002.conf
logfile "redis_7002.log"
其他配置文件也修改成对应文件名的字段。
启动redis节点:
bin/redis-server redis_7001.conf &
bin/redis-server redis_7002.conf &
bin/redis-server redis_7003.conf &
bin/redis-server redis_7004.conf &
bin/redis-server redis_7005.conf &
bin/redis-server redis_7006.conf
然后查看redis进程:
[root@localhost redis]# ps -ef|grep redis
root 24783 1 0 Nov15 ? 00:07:53 bin/redis-server 0.0.0.0:7001 [cluster]
root 24792 1 0 Nov15 ? 00:07:50 bin/redis-server 0.0.0.0:7002 [cluster]
root 24805 1 0 Nov15 ? 00:07:53 bin/redis-server 0.0.0.0:7003 [cluster]
root 24816 1 0 Nov15 ? 00:07:49 bin/redis-server 0.0.0.0:7004 [cluster]
root 24821 1 0 Nov15 ? 00:07:53 bin/redis-server 0.0.0.0:7005 [cluster]
root 24830 1 0 Nov15 ? 00:07:50 bin/redis-server 0.0.0.0:7006 [cluster]
--cluster-replicas 1 参数表示创建一个主节点同时也创建一个从节点。
创建redis集群:
redis-cli --cluster 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:7004 to 127.0.0.1:7001
Adding replica 127.0.0.1:7005 to 127.0.0.1:7002
Adding replica 127.0.0.1:7006 to 127.0.0.1:7003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 9f8616c497aeb89e065c9ed7e260a13a499078eb 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
M: 1064be46f6001390b47308fcb90832cb5eff3256 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
M: c862b3f74904891972debe055edee66d08563f6c 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
S: 51fa3d61cd6075d8a179ec5402c3d6771592d524 127.0.0.1:7004
replicates c862b3f74904891972debe055edee66d08563f6c
S: f2a18a3fd5f7097888f31cbbc3878f26699ecd09 127.0.0.1:7005
replicates 9f8616c497aeb89e065c9ed7e260a13a499078eb
S: 004d9acf71c448d93c8b3211f1fd132dd47cd5e9 127.0.0.1:7006
replicates 1064be46f6001390b47308fcb90832cb5eff3256
Can I set the above configuration? (type 'yes' to accept):
可以看到启动六个节点,三个主节点
Master,三个从节点Slave,以及他们之间的主从关系。六个节点,每个节点都生成一个唯一的编码。
输入yes
最后有以下输出,表示集群搭建成功:
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
测试集群
登录客户端需要带上参数-c表示集群环境,否则只能获取单个节点的数据。
先在7001添加数据
bin/redis-cli -p 7001
redis 127.0.0.1:7001> set name jeremy
OK
然后在7002获取数据:
bin/redis-cli -p 7002
redis 127.0.0.1:7002> get name
-> Redirected to slot [5798] located at 127.0.0.1:7001
OK
127.0.0.1:7001> get name
"jeremy"
在
7002获取数据,redis集群会根据key计算哈希槽的位置,算出数据在7001节点,重定向到7001节点获取数据。
- 添加新节点
添加一个新节点,一般是添加一个空节点,将其他节点数据移动该节点数据库中。实现数据库的扩容。
bin/redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7001
将新节点地址为第一个参数,集群中随机一个节点地址为第二个参数。上面的命令的表示将新节点127.0.0.1:7006添加到127.0.0.1:7001所在的集群中。
- 删除节点
bin/redis-cli --cluster del-node 127.0.0.1:7001
集群模式的优缺点
- 优点
- 具有高可用,哨兵模式的优点,他都有
- 数据分片,不重复存储数据,占内存小
- 容易实现扩容和缩容
总结
- 主从模式:
- 单机宕机或者磁盘出现故障,会导致数据丢失,主从模式将数据复制给多个从服务器上,即使一台数据库宕机了,其他数据也能正常提供数据。
- 主从模式有一台主数据库,多台从数据库的模式。客户端对主数据库进行读写,从数据库只能读操作。
- 启动主从数据库之后,从数据库发送
SYNC同步命令给主数据库,主数据库接收到命令之后,生成RDB文件。并且使用缓冲区记录所有写命令。写完毕后发送RDB文件给每个从数据库解析,以及发送缓存写命名给所以从数据库执行。 - 主数据库更新数据后,数据会同步更新到从数据库中。
- 主从模式实现了简单的可用,但是如果主数据库宕机了,手动切换主数据库比较费力,就有了哨兵模式。
- 哨兵模式:
- 根据主从模式无法自动切换问题,就有了哨兵模式。
- 哨兵是一个独立的进程,它主要有三个功能:监控数据库,发现主数据库宕机了,首先标记主观下线,当主观下线数量达到设置的数量时,就会进行投票,通过之后就执行切换主数据库,将一个从数据库升级成主数据库。并通知给其他数据库修改主数据库配置。
- 哨兵模式实现自动切换主数据库,实现了服务的高可用。
- 哨兵模式和主从模式一样,所有数据库都存放相同的数据,比较浪费内存,而且受限于单机数据库,很难实现在线扩容。
Cluster模式Redis集群有16384个哈希嘈,对键的CRC16取模16384计算出哈希槽。- 集群使用分片,使用节点方式,将哈希槽分布在每个节点上。也就讲数据分布存储上不同的节点上。
- 为了保证服务的高可用,每个节点都可以搭建主从。
- 数据库扩容需要添加节点,从新计算哈希嘈,将其他数据库的数据,转移到新节点上。也可以删除节点实现数据库的缩容,删除节点后,该节点的数据也会根据哈希嘈分配到其他节点上。
参考
-
Scaling with Redis Cluster
-
High availability with Redis Sentinel
-
你了解 Redis 的三种集群模式吗?