机器学习算法基础(回归算法、逻辑回归、k-means聚类算法)
目录
- 第一部分 回归算法
-
- (一)线性回归
-
- 线性模型
- 线性回归
- 损失函数(误差大小)
- 减小误差的方法
-
- 正规方程
- 梯度下降
- 正规方程、梯度下降API
- 回归性能评估
-
- 回归评估API
- 两种方法的总结
- (二)欠拟合与过拟合
-
- 定义
- 产生原因及解决方法
- (三)岭回归——带正则项的线性回归
-
- 正则化
- 岭回归API
- 代码实例——预测波士顿的房价
- 模型的保存与加载
-
- 代码示例
- 第二部分 分类算法——逻辑回归
-
- 逻辑回归
- 对数似然损失函数
- 逻辑回归API
- 逻辑回归案例——乳腺肿瘤的良恶性预测
- 第三部分 聚类——k-means方法
-
- k-means步骤
- k-means的API
- k-means性能评估系数
- k-means性能评估API
- k-means总结
第一部分 回归算法
(一)线性回归
线性模型

线性回归

损失函数(误差大小)

减小误差的方法
正规方程

梯度下降

正规方程、梯度下降API


回归性能评估

回归评估API
![]()

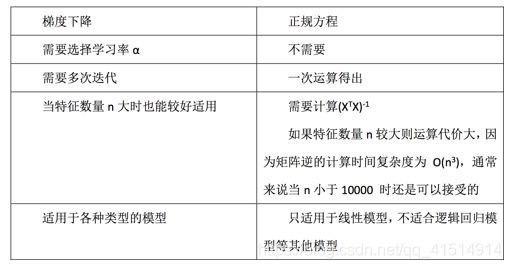
两种方法的总结
(二)欠拟合与过拟合
定义

产生原因及解决方法


(三)岭回归——带正则项的线性回归
正则化

岭回归API
![]()


代码实例——预测波士顿的房价
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor,Ridge
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
import numpy as np
def myliner():
'''
线性回归直接预测房子价格
'''
#获取数据
lb=load_boston()
#分割数据集到训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(lb.data,lb.target,test_size=0.25)
#进行标准化处理,特征值和标准值都必须进行标准化处理
std_x=StandardScaler()
x_train=std_x.fit_transform(x_train)
x_test=std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1)) #0.19版的sklearn要求传入的数组必须是二维数组
y_test = std_y.transform(y_test.reshape(-1,1))
#estimator预测
#正规方程求解方式预测结果
lr=LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_)
#预测测试集的房子价格
y_lr_predict=std_y.inverse_transform(lr.predict(x_test))
print("正规方程测试集里面每一个房子的预测价格:",y_lr_predict)
print("正规方程的均方误差:",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
#梯度下降求解方式预测结果
sgd=SGDRegressor()
sgd.fit(x_train,y_train)
print(sgd.coef_)
#预测测试集的房子价格
y_sgd_predict=std_y.inverse_transform(sgd.predict(x_test))
print("梯度下降测试集里面每一个房子的预测价格:",y_sgd_predict)
print("梯度下降的均方误差:", mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
# 岭回归去进行房价预测
rd = Ridge(alpha=1.0)
rd.fit(x_train, y_train)
print(rd.coef_)
# 预测测试集的房子价格
y_rd_predict = std_y.inverse_transform(rd.predict(x_test))
print("梯度下降测试集里面每个房子的预测价格:", y_rd_predict)
print("梯度下降的均方误差:", mean_squared_error(std_y.inverse_transform(y_test), y_rd_predict))
return None
if __name__=="__main__":
myliner()模型的保存与加载
![]()

代码示例
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, classification_report
from sklearn.externals import joblib
import pandas as pd
import numpy as np
def mylinear():
"""
线性回归直接预测房子价格
:return: None
"""
# 获取数据
lb = load_boston()
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train, y_test)
# 进行标准化处理(?) 目标值处理?
# 特征值和目标值是都必须进行标准化处理, 实例化两个标准化API
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# estimator预测
# 正规方程求解方式预测结果
lr = LinearRegression()
lr.fit(x_train, y_train)
print(lr.coef_)
# 保存训练好的模型
joblib.dump(lr, "./tmp/test.pkl")
# 预测房价结果
model = joblib.load("./tmp/test.pkl")
y_predict = std_y.inverse_transform(model.predict(x_test))
print("保存的模型预测的结果:", y_predict)
return None
if __name__=="__main__":
myliner()
第二部分 分类算法——逻辑回归
逻辑回归
逻辑回归是以线性回归的式子作为输入,实现二分类的一种分类算法。


逻辑回归公式

对数似然损失函数

逻辑回归API
![]()

逻辑回归案例——乳腺肿瘤的良恶性预测

from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, classification_report
from sklearn.externals import joblib
import pandas as pd
import numpy as np
def logistic():
"""
逻辑回归做二分类进行癌症预测(根据细胞的属性特征)
:return: NOne
"""
# 构造列标签名字
column = ['Sample code number','Clump Thickness', 'Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class']
# 读取数据
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data", names=column)
print(data)
# 缺失值进行处理
data = data.replace(to_replace='?', value=np.nan)
data = data.dropna()
# 进行数据的分割
x_train, x_test, y_train, y_test = train_test_split(data[column[1:10]], data[column[10]], test_size=0.25)
# 进行标准化处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 逻辑回归预测
lg = LogisticRegression(C=1.0)
lg.fit(x_train, y_train)
print(lg.coef_)
y_predict = lg.predict(x_test)
print("准确率:", lg.score(x_test, y_test))
print("召回率:", classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"]))
return None
if __name__ == "__main__":
logistic()第三部分 聚类——k-means方法
k-means步骤

k-means的API
![]()

k-means性能评估系数


k-means性能评估API
![]()

k-means总结
