强化学习-时序差分、SARSA与Q-Learning(第2章)
来源书籍:
TENSORFLOW REINFORCEMENT LEARNING QUICK START GUIDE
《TensorFlow强化学习快速入门指南-使用Python动手搭建自学习的智能体》
著者:[美]考希克·巴拉克里希南(Kaushik Balakrishnan)
译者:赵卫东
出版社:Packt 机械工业出版社
1.时序差分、SARSA与Q-Learning
1.1理解TD学习
TD学习是强化学习中非常基础的概念。在TD学习中,agent的学习是通过经验实现的。在环境下进行多次尝试,积累奖励用于更新价值函数。具体而言,agent将在遇到新的状态或动作时保持状态-动作价值函数的更新。贝尔曼方程用于更新状态-动作价值函数,目标是最小化TD误差。这实质上意味着agent正在降低其在给定状态下哪种动作是最佳动作时的不确定性,其通过降低TD误差来获取在给定状态下的最佳动作的置信度。
价值函数与状态之间的关系
价值函数是agent对给定状态好坏程度地估计。例如,如果机器人靠近悬崖边缘,并且可能坠崖,那么该状态是糟糕的,并且必须赋予较低的值。而如果机器人或agent接近其最终目标,那么该状态是一个良好的状态,因为它们很快将获得很高的奖励,因此该状态对应更高的值。
价值函数 在到达
在到达 状态,并从环境接收
状态,并从环境接收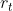 奖励后更新。最简单的TD学习算法是
奖励后更新。最简单的TD学习算法是![]() ,并且使用下面的等式进行更新:
,并且使用下面的等式进行更新:

其中, 是学习率, 且 0≤≤1 。请注意, 在一些参考文献中, 上式使用而不是 , 这只是习惯的差异而不是错误, 表示从 状态收到并转移到
, 这只是习惯的差异而不是错误, 表示从 状态收到并转移到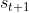 状态的奖励。
状态的奖励。
还有另一种名为 () 的 TD 学习变体使用了资格迹 (Eligibility Traces) ![]() ,这是访问一个状态的记录。以如下方式执行 () 的更新:
,这是访问一个状态的记录。以如下方式执行 () 的更新:

资格迹由以下公式给出:

其中, =0 时, ()=0 。在 agent 所经过的每一步, 对于所有状态,资格迹减少 λ; 对于在当前时间步中访问的状态, 资格迹增加 1 。这里, 0≤≤1 并且是决定将奖励中的多少额度分配给远端状态的参数。下面介绍后续两种强化学习算法背后的理论, 即 SARSA 和 Q-Learning, 这两种算法在强化学社区非常流行。
1.2理解 SARSA 与 Q-Learning
SARSA是一种使用状态-动作Q值进行更新的算法, 这些概念源自计算机科学领域的动态规划。Q-Learning是一种异步策略算法, 最初由 Christopher Watkins于1989年提出, 是一种广泛使用的强化学习算法。
1.2.1学习 SARSA
SARSA 是一种非常流行的同步策略算法, 特别是在 20 世纪 90 年代。它是我们之前提到的TD学习的扩展, 是一种同步策略算法。SARSA 保持对状态 - 动作价值函数的更新, 并且当遇到新的经验时, 使用动态规划的贝尔曼方程更新该状态 - 动作价值函数。将前面的TD算法扩展到状态-动作价值函数 ![]() , 这种方法称为 SARSA:
, 这种方法称为 SARSA:
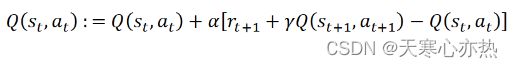
从给定的状态 , 采取动作 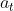 , 获得奖励 , 转换到新状态 , 然后进行动作
, 获得奖励 , 转换到新状态 , 然后进行动作  并继续。这个五元组 (,,,,) 为该算法提供了名字: SARSA。 SARSA 是一种同步策略的算法, 因为相同的策略被更新, 并用于估计值。对于探索,可以使用 -greedy算法。
并继续。这个五元组 (,,,,) 为该算法提供了名字: SARSA。 SARSA 是一种同步策略的算法, 因为相同的策略被更新, 并用于估计值。对于探索,可以使用 -greedy算法。
1.2.2 理解 Q-Learning
Q-Learning 与 SARSA 类似, 对于每个状态-动作对, 保持对状态-动作价值函数的更新, 并且在收集到新经验时使用动态规划的贝尔曼方程递归地进行更新。请注意, 它是一个异步策略算法, 因为它使用在动作中评估的状态 - 动作价值函数, 这将最大化价值。Q-Learning 用于动作是离散的问题。举个例子, 如果定义动作为向北移动、向南移动、向东移动和向西移动, 并将决定在给定状态下的最佳动作,这种设定下Q-Learning是适用的。 在经典的 Q-Learning 算法中, 更新操作如下所示:
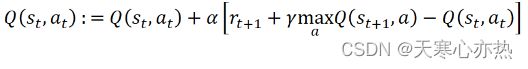
其中, max 是对动作执行的, 即在状态, 对应Q最大值执行的动作。α是 学习率, 是用户可以指定的超参数。
总结
本章介绍了 TD 的概念, 还学习了两种强化学习算法: Q-Learning 和 SARSA, 以及如何用 Python 编写这两种算法, 并使用它们来解决悬崖徒步和网格世界问题。 这两种算法使我们对强化学习的基础知识以及如何从理论到代码的转换有了很好的理解。Q-Learning 和 SARSA 仍然在今天的强化学习社区中得到应用。
下一章将研究在强化学习中使用深度神经网络, 从而引出深度强化学习。深度 Q 网络 (Deep Q-Networks, DQN) 使用神经网络, 是 Q-Learning 变体, 不是本章中介绍的表格式的状态-动作价值函数。请注意, Q-Learning 和 SARSA 只适用于具有较少数量的状态和动作的问题。当有大量的状态或动作时, 就会遇到所谓的维度灾难, 其中表格式方法由于使用过多的内存而变得不可行; 在这类问题中, DQN 更加适合, 这将是下一章的关键内容。
源码请见书籍配套的链接:https://github.com/packtpublishing/tensorflow-reinforcement-learning-quick-start-guide