基于Apache Doris数仓平台架构设计
1、数仓平台架构设计
1.1、数仓架构V1.0

在公司成立初期业务量不大,数据团队的规模也比较小,对数据的需求仅局限于少量的T+1定制化报表需求。
数仓架构V1.0的问题
- 随着公司业务规模、数据量的增长,MySQL的数据分析性能已经不能满足需求;
- 没有进行分层划域,烟囱式的开发模式数据复用性很差,开发成本高,需求的响应速度较慢;
- 对数据的质量和元数据的管理缺乏管控;
- T+1的数据延迟较大,期望能够达到准时的数据延迟。
1.2、数仓架构V2.0

1.2.1、为什么选择Doris
1、易用性
- 采用MySQL协议和语法,可以通过各类客户端工具来访问,能过与BI工具无缝对接;
- 支持多表join,针对不同场景join提供了多种优化方案;
- 生态扩展完善,离线数据的高效批量导入,流式数据的低延迟实时导入都有很好的支持;
- 简洁的分布式架构,只有FE、BE两个进程,运行不依赖任何第三方系统;
- 支持弹性伸缩,对于部署、运维非常友好;
2、性能
- MPP架构、高效列式存储引擎;
- 支持数据的预聚合以及预聚合结果的自动更新;
- 支持数据的实时更新;
- 支持高并发查询;
1.3、构建数仓的问题及优化方案
1.3.1、遇到的问题
1、服务稳定性
- Doris服务频繁宕机
- Doris连接超时
2、数据同步和调度
- 数据同步失败
- 调度依赖异常
3、查询速度
- Doris查询缓慢
- 甚至无法返回查询结果
1.3.2、优化方案
1、服务稳定性优化
优化前对Doris服务的理解和部署方式
FE负责元数据的管理、用户请求接入、查询的解析规划,资源占用较少;与其它大数据组件混合部署FE*3;
BE负责数据存储、查询计划的执行,资源占用较大;独立部署且分配较多的资源BE(16C 128G 4T*1) * 7;
存在的问题
-
FE混合部署存在资源竞争问题
每当机器资源使用率打满,都会导致FE节点无法连接,长时间获取不到心跳被FE集群判定为离线;
-
BE单磁盘性能问题
Doris限制了每个磁盘上能够同时进行的Compaction任务数量、节点整体的任务数量;
Compaction由以下三个配置控制:
compaction_task_num_per_disk:每个磁盘上compaction的任务数,默认为2;
max_compaction_threads:compaction线程的总数,默认为10;
total_permits_for_compaction_score:compaction任务配额,默认10000
每个BE节点分配了一块4T的磁盘,compaction线程数只有2;compaction很慢,这是导致BE compaction score不健康的原因之一;
Doris优化后的部署方式
-
FE独立部署
避免了FE混合部署资源竞争的问题。
-
BE多磁盘部署
4T * 1—>1T * 5,BE compaction线程数提升5倍,compaction速度增快,磁盘I/O带宽也得到了提升。
-
其它服务稳定性优化
使用ProxySQL对FE连接进行负载均衡,解决FE连接单点问题;
使用Supervisor对FE、BE服务进程状态进行监控,当FE、BE进程发生意外宕机可以快速恢复;
2、查询稳定性优化
遇到的问题
随着时间和数据量的增长,Doris集群进入了几乎不可用的状态,主要体现在以下几个方面
- DDL操作非常缓慢甚至超时失败;
- 简单的查询也需要非常久的时间才能返回结果甚至超时失败;
- FE频繁出现OOM宕机;
经过排查发现很多表的数量并不大,但是Tablet数量却很大;
进一步确认Doris集群5T数据量Tablet数量达到了150w;
优化前的情况
对Doris数据量大小、分区粒度、Bucket数量、Tablet数量的关系以及Tablet数量对集群的影响没有概念;为了追求查询效率,大部分动态分区表的分区Bucket设置了32,而且分区粒度较小(按天、周分区)。
Tablet数量过大会引发以下问题:
- 所有与元数据相关的操作都会耗时很长,甚至超时失败;
- FE负责管理元数据,所有的元数据存放在FE的内存中,导致FE GC压力很大,容易发生OOM;
优化方案
明确Tablet数量、分区数量、Bucket数量、副本数的关系;
Tablet数量 = 分区数量 * Bucket数量 * 副本数
结合实际应用情况,可以从分区粒度和Bucket数量进行优化;
鉴于集群目前数据量大小为5T,结合对Bucket的更进一步理解以及当前集群实际情况
| 数据大小 | Bucket数量 |
|---|---|
| 0MB~10MB | 1 |
| 10MB~50MB | 2 |
| 50MB~2GB | 4 |
| 2GB~5GB | 8 |
| 5GB~25GB | 32 |
| 大于50GB | 64 |
优化目标和长期控制目标
Tablet数量:150w —>15w
Tablet增长量:30000/TB(三副本)
优化后的情况
在仅对ODS层的分区粒度和Bucket数量进行调整的情况下,集群Tablet数量从150w—>15w;
FE执行checkpoint时,元数据在内存中复制一份在FE JVM Heap Stat监控上形成一个波峰;
优化后FE在堆内存占用明显下降、波峰也变得平缓,FE在稳定性得到了提升;
BE compaction score反映当前Tablet版本堆积情况:
BE compaction score在100以内属于正常范围,如果持续接近100,说明集群可能存在风险;
集群在优化前compaction score周期性的达到了500;
经过磁盘调整和Tablet优化后,BE compaction score稳定在50以内,查询的性能和稳定性得到了提升。
3、数据同步优化
Doris数据同步
MySQL数据同步使用Flink CDC—>Kafka—>flink_doris_connector—>Doris的方式全量+增量进入Doris。但由于历史遗留问题,MySQL部分表单表数量比较大(大约几亿数据),并且没有设置任何索引和分区,这种执行简单的cout查询都需要花费10分钟以上的时间,使用Flink CDC虽然可以进行增量数据的同步,但是全量数据同步不能实现。
针对这种情况:
- 全量同步使用mysqldump—>csv—>Doris StreamLoad—>Doris
- 增量同步使用Flink CDC—>Kafka—>flink_doris_connector—>Doris
4、调度优化
Doris数据调度
使用DolphinScheduler进行Doris SQL的任务调度,同一node下配置多条SQL时会出现node执行状态异常,导致工作流DAG的node依赖失效,前一个节点未执行,后一个节点就开始执行,结果会出现缺数据甚至没有数据的情况。
这个问题是因为DolphinScheduler2.x在同一个node下不支持按顺序执行MySQL的多段SQL。而Doris在DolphinScheduler中使用MySQL数据源创建连接,所以会发生以上问题,这个问题在DolphinScheduler3.x版本被修复,配置中可以设置多段SQL的分隔符,解决了DAG依赖关系失效的问题。
1.4、元数据管理和数据血缘实现方案
1.4.1、元数据管理和数据血缘解决的问题
1、元数据
- 表、字段、指标、报表在哪儿;
- 表的分区情况、清理策略、资源占用、Replica Count、Row Count…;
- 表的分层划域、指标口径、负责人、使用场景说明;
- 表结构变更通知、表结构变更记录维护;
- 数据何时发生变更、谁做的变更、发生了什么变更;
- 表对应的调度任务详情、执行记录、变更记录;
2、数据血缘
- 理解数据从哪儿来,到哪儿去;
- 对数仓治理提供依据(跨层引用率、引用热度、调度依赖预测…);
- 影响分析(某表、某字段的变更对指标、报表的影响,减少盲目变更导致重要报表、重要数据的异常);
- 理解某张报表依赖于哪些表、哪些字段,进一步明确报表是否能够进行复用;
1.4.2、元数据管理和数据血缘实现方案
元数据管理和数据血缘主要针对Doris,对DolphinScheduler的元数据信息进行整合。
将元数据分为了物理元数据和业务元数据两大类:
- 物理元数据维护的是表的属性信息、调度信息;
- 业务元数据维护的是表在使用过程中约定的口径和规范信息;
数据血缘实现了表级血缘和字段级血缘
| 物理元数据 | 业务元数据 | 数据血缘 |
|---|---|---|
| Schema信息 | 分层 | 表血缘 |
| 数据量 | 主题域 | 字段血缘 |
| 存储空间占用大小 | 负责人 | 数仓影响分析 |
| Tablet数量 | 指标信息 | 报表影响分析 |
| 分区信息 | 表的使用规则 | 跨层引用分析 |
| 生命周期 | 引用热度分析 | |
| DDL变更 | ||
| 读写记录 | ||
| 产出信息 | ||
| 产出脚本 |
1.4.3、元数据管理和数据血缘实现方案
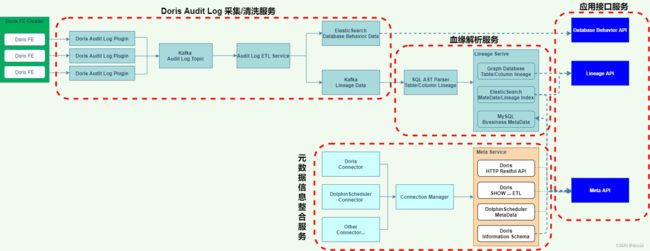
1、元数据管理和数据血缘使用的技术栈
- 数据采集:Doris Audit Plugin
- Doris stmt存储:Kafka
- 血缘分析:Druid
- 血缘关系存储:Nebula Graph
- 业务元数据:MySQL
- 搜索数据:ElasticSearch
2、Doris审计日志的采集和清洗服务
Doris Audit Log Plugin
- 收集Doris审计日志
- 数据格式化
- Sink Kafka dmp_audit_log Topic
Audit Log ETL Service
- 乱序数据排序
- 数据清洗
- Database Behavior Data Sink ES(数据读写记录、DDL变更记录)
- Lineage Data Sink Kafka dmp_lineage Topic(产生血缘的SQL执行记录)
SQL AST Parser
- 表血缘解析
- 字段血缘解析
- 血缘关系数据Sink Graph Database
- 血缘关系数据index Sink ES
- 物理元数据index Sink ES
- 业务元数据 Sink MySQL
元数据整合服务
元数据整合服务参考了Metacat的架构实现方式。
Connector Manager
- 创建Doris元数据连接
- 创建DolphinScheduler元数据连接
Meta Service
- Doris Information Schema获得的元数据信息
- Doris Http Restful API获得的元数据信息
- Doris SHOW …查询结果ETL后的元数据信息
- DolphinScheduler工作流元数据信息和调度记录信息
应用接口服务
Lineage API
- 提供表血缘和字段血缘的查询服务
Meta API
- 提供表、字段的搜索服务
- 提供表的物理元数据查询服务
- 提供某张表的业务元数据查询服务
- 提供表的调度数据查询服务
Database Behavior API
- 提供表的读写记录、DDL变更记录查询服务
是的地方
Doris Http Restful API获得的元数据信息
- Doris SHOW …查询结果ETL后的元数据信息
- DolphinScheduler工作流元数据信息和调度记录信息
应用接口服务
Lineage API
- 提供表血缘和字段血缘的查询服务
Meta API
- 提供表、字段的搜索服务
- 提供表的物理元数据查询服务
- 提供某张表的业务元数据查询服务
- 提供表的调度数据查询服务
Database Behavior API
- 提供表的读写记录、DDL变更记录查询服务