hadoop HA集群搭建
第一步:由于Hdoop HA集群中没有SecondaryNameNode 因此要先删除hadoop目录下的masters文件
在所有机器上输入rm -rf /usr/local/hadoop/masters
![]()
第二步:删除之前的非高可用hadoop集群产生的数据文件
第三步:在master上修改hadoop目录下的配置文件hdfs-site.xml



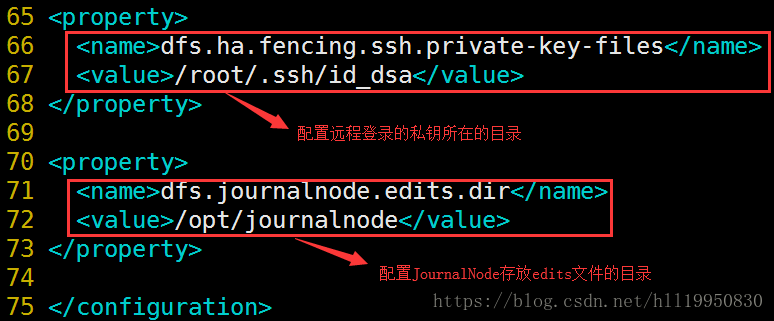
完整的配置文件如下:
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
34
35
36
37
38
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
第四步:在master上修改hadoop目录下的配置文件core-site.xml

第五步:启用active NameNode的自动切换
在master上修改hadoop目录下的配置文件hdfs-site.xml 加入以下内容:

修改hadoop目录下的配置文件core-site.xml 加入以下内容:

第六步:将master上hadoop的配置文件拷贝到slave1 slave2 slave3上

第六步:在slave1 slave2 slave3分别上启动JournalNode集群(slave1 slave2 slave3):hadoop-daemon.sh start journalnode



第七步:查看hadoop的日志文件 确保JournalNode正常启动
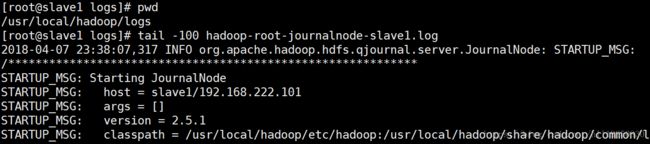
第八步:在两台NameNode(master slave3)中随便选择一台进行hdfs格式化(注意:一定要先启动JournalNode再对hdfs进行格式化 否则会抛出异常)

此时就会在master上生成fsimage文件
第九步:手动把master上的fsimage文件拷贝到slave3上:scp -r ./hadoop-2.5.1 root@slave3:/opt

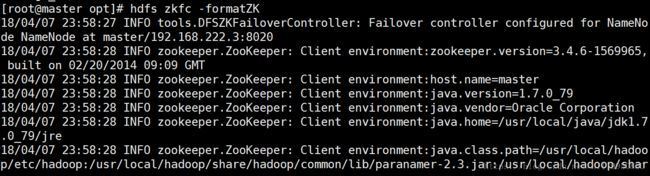
第十步:在两台NameNode(master slave3)中随便选择一台进行zookeeper格式化: hdfs zkfc -formatZK
第十一步:在master上启动zookeeper集群(原则上可以在master slave1 slave2中任意一台上启动zookeeper集群 但是由于在master上配置了免密登录 因此更方便):start-dfs.sh(在启动之前最好先关闭dfs:stop-dfs.sh)
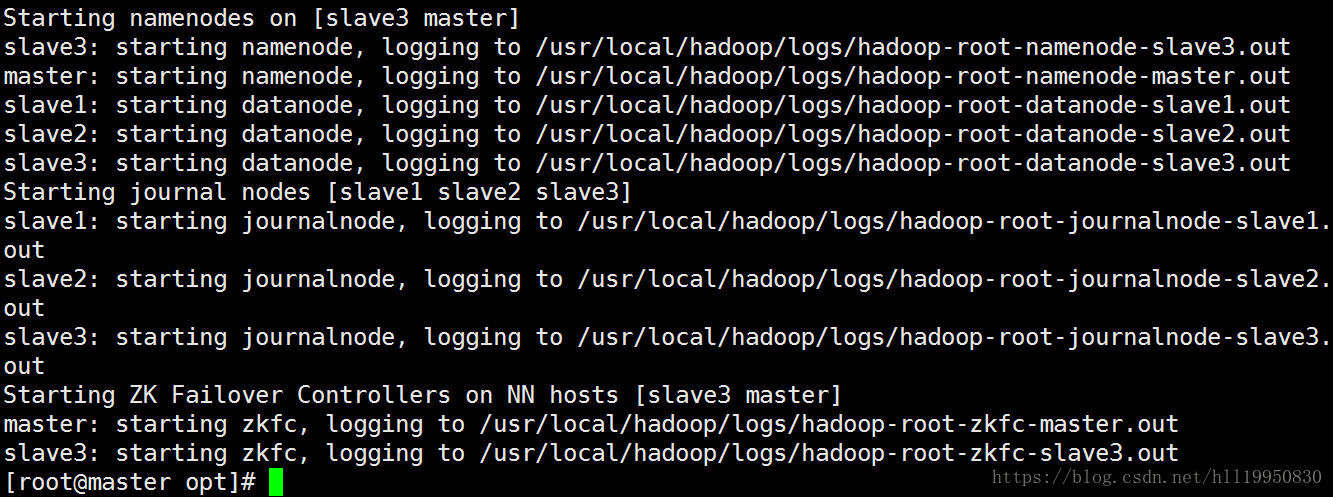
第十二步:查看进程状态
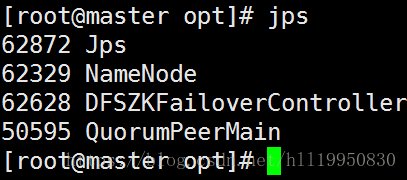
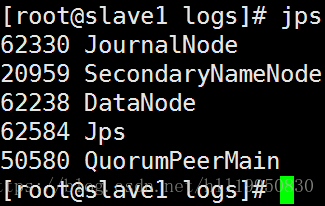
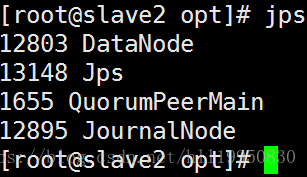
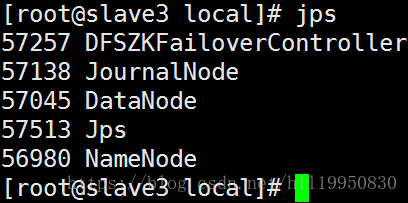
第十三步:通过浏览器查看集群状态


第十四步:强制使NameNode master挂掉 测试NameNode slave3是否会自动接管
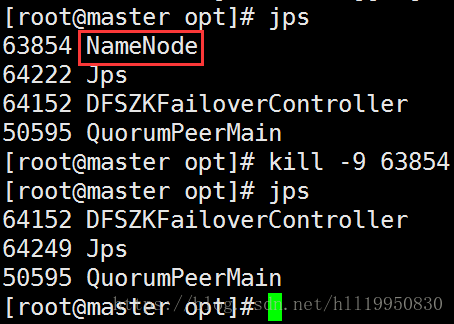
此时无法通过浏览器查看master信息
发现slave3还是standy 说明slave3并未成功接管

查看slave3中FailOverController的日志:tail -100 /usr/local/hadoop/logs/hadoop-root-zkfc-slave3.log
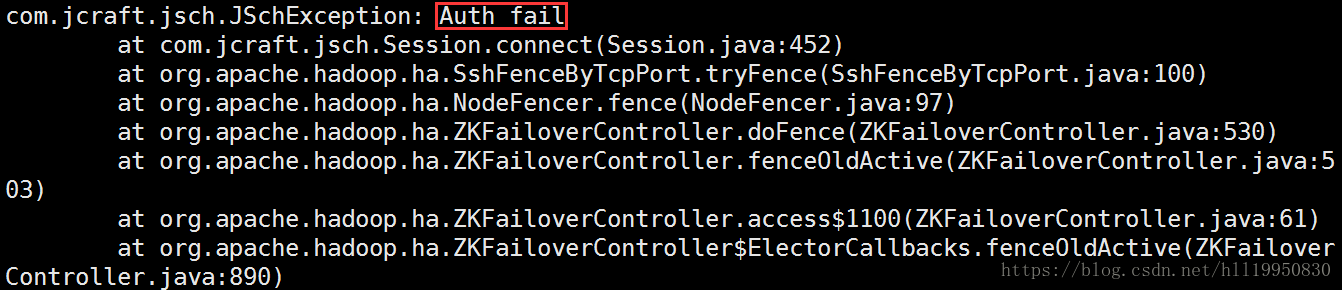
原因是没有在master上设置对slave3免密登录。先删除~/.ssh目录下的所有文件

关闭整个集群stop-dfs.sh
首先设置slave3自己免密登录
在slave3上生成公钥和私钥:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
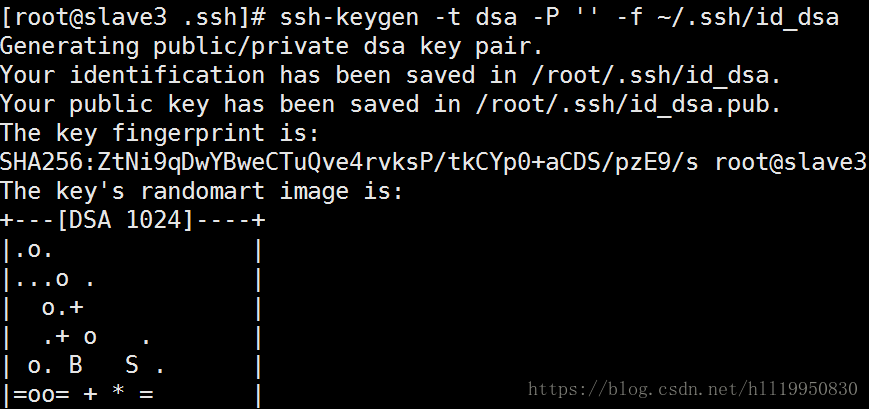
将slave3自己的公钥追加到认证文件中 并测试自己是否可以免密登录:ssh slave3
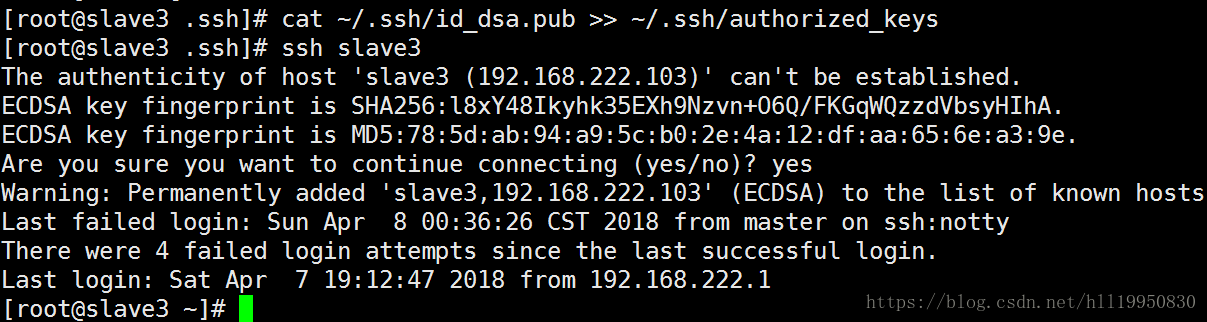
将slave3的公钥拷贝到master的/opt目录下:scp ~/.ssh/id_dsa.pub root@master:/opt

在master上将slave3的公钥加入到认证文件中:cat /opt/id_dsa.pub >> ~/.ssh/authorized_keys

测试slave3是否可以免密登录master:ssh master

将master的公钥拷贝到slave3上:scp ~/.ssh/id_dsa.pub root@slave3:/opt

将master的公钥添加到slave3的认证文件中:cat /opt/id_dsa.pub >> ~/.ssh/authorized_keys

测试master是否可以免密登录slave3:ssh slave3
在master slave1 slave2上启动zookeeper
在master上关闭hdfs集群再重启
然后强制杀死master上的NameNode进程:
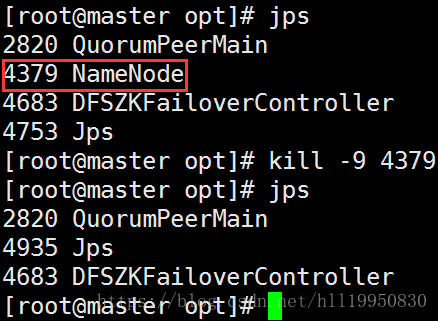
通过浏览器查看slave3状态信息发现还是standby
再次查看slave3中FailOverController的日志信息 发现异常信息如下:

由上面的警告可知:fuser: command not found,在做主备切换时执行fuser命令失败了。查看hdfs-site.xml配置文件,
hdfs-site.xml通过参数dfs.ha.fencing.methods来实现,在出现故障时通过哪种方式登录到另一个namenode上进行接管工作。
系统在任何时候只有一个namenode节点处于active状态。在主备切换的时候,standby namenode会变成active状态,原来的active namenode就不能再处于active状态了,否则两个namenode同时处于active状态会有问题。所以在failover的时候要设置防止2个namenode都处于active状态的方法,可以是Java类或者脚本。fencing的方法目前有两种,sshfence和shell 。sshfence方法是指通过ssh登陆到active namenode节点杀掉namenode进程,所以需要设置ssh无密码登陆,还要保证有杀掉namenode进程的权限。
在网上查找到的解决方法如下:在两个NameNode(master slave3)节点上安装fuser(datanode节点不用安装)
[root@master~]# yum -y install psmisc
![]()
[root@slave3 ~]# yum -y install psmisc
![]()
重新测试 发现当master(NameNode active )挂掉以后 slave3(NameNode standby) slave3会自动接管 并将自己的状态由standby改为active
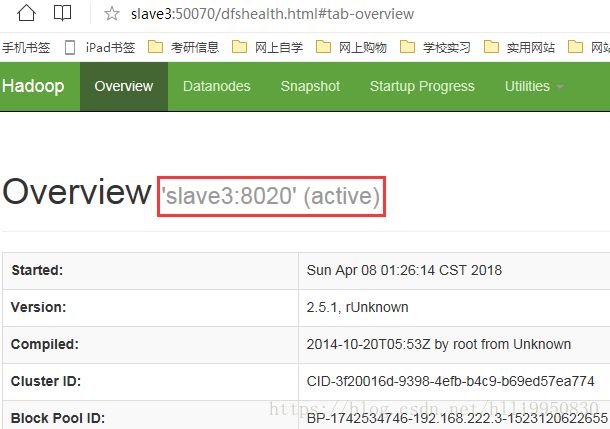
需要注意的是:当master重新启动后 master的状态为standy slave3的状态仍然为active 也就是说master并不会抢夺active状态 这是因为它与keepalived不同 两个NameNode没有主备之分 处于同级关系 但是可以通过Hadoop HA管理命令手动将master的状态改为active 将slave3的状态改为standby(hdfs haadmin -transitionToActive master 此处master是之前设置的NameNode ID 而不是nameservice id)
Hadoop HA 管理命令
hdfs haadmin:
-transitionToActive:将NameNode状态手动改为active
-transitionToStandby:将NameNode状态手动改为Standby

至此 Hadoop HA集群搭建成功。