安装Hadoop HA集群
1、Hadoop基本安装配置
该项的所有操作步骤使用专门用于集群的用户admin进行
此项只在一台主机操作,然后在下一步骤进行同步安装与配置
首先,Hadoop软件包“hadoop-2.7.3.tar.gz”,上节课传到用户家目录的“setups”目录下,然后进行解压和环境变量设置。
$mkdir ~/hadoop #创建用于存放Hadoop相关文件的目录
$cd ~/hadoop #进入该目录

$tar -xzf ~/setups/hadoop-2.7.3.tar.gz #将软件包解压

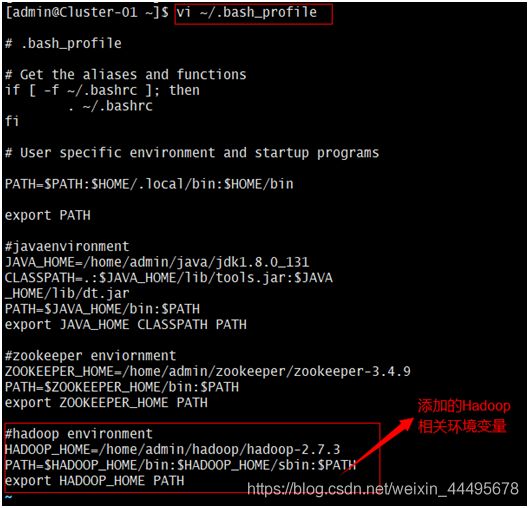
$ vi ~/.bash_profile #配置Hadoop相关的环境变量
对配置文件进行修改,在文件末尾添加以下内容:
#hadoop environment
HADOOP_HOME=/hpme/admin/hadoop-2.7.3 #该路径以Hadoop软件包实际解压解包的路径为准
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH #确保此项输入正确,否则可能导致所有命令无法使用
Export HADOOP_HOME PATH #必须按照前面的定义顺序书写
$source ~/.bash_profile #使新配置的环境变量立即生效
![]()
$echo $HADOOP_HOME #查看新添加和修改的环境变量是否设置
$echo $PATh 成功,以及环境变量的值是否正确
$hadoop version #验证Hadoop的安装配置是否成功

2、Hadoop高可用完全分布模式配置
该项的所有操作步骤使用专门用于集群的用户admin进行
$cd ~/hadoop #进入Hadoop相关文件的目录
$mkdir tmp nama data journal #分别创建Hadoop的临时文件目录“tmp”、HDFS的元数据文件目录“name”、
HDFS的数据文件目录“data”、Journal的逻辑状态数据目录“journal”

$cd ~/hadoop/hadoop-2.7.3/etc/hadoop #进入Hadoop的配置文件所在目录
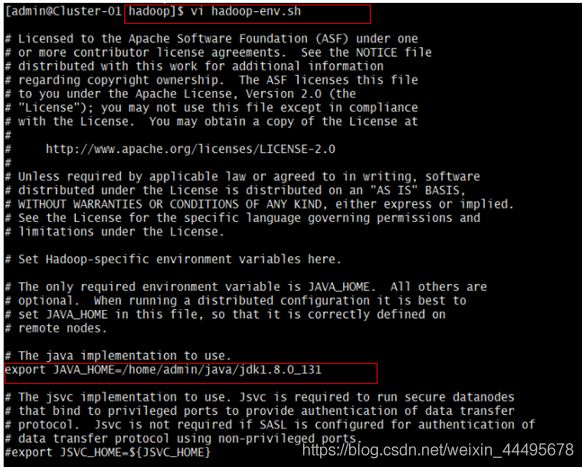
$vi hadoop_env.sh #对配置文件进行修改
找到配置项“JAVA_HOME”所在行,将其改为以下内容:(去掉注释#)
Export JAVA_HOME=/home/admin/java/jdk1.8.0_131 #该路径以JDK软件包实际解压解包的路径为准
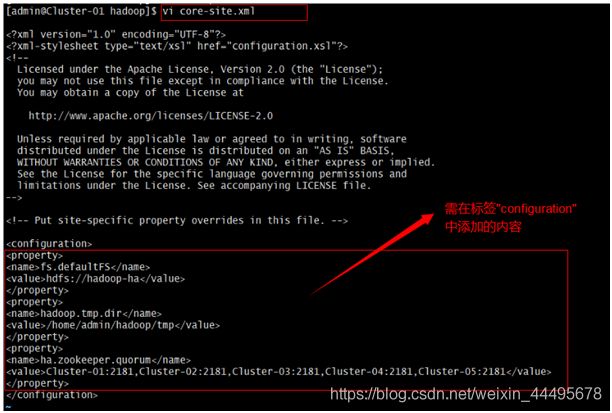
$vi core-site.xml #对配置文件进行修改
找到标签“”所在的位置,在其中添加如下内容:
fs.defaultFS 空间的逻辑名称之一 - ->
hdfs://hadoop-ha
hadoop.tmp.dir <!- -指定Hadoop的临时文件的本地存放路径- ->
/home/admin/hadoop/tmp
ha.zookeeper.quorum
Cluster-01:2181,Cluster-02:2181,Cluster-
03:2181,Cluster-04:2181,Cluster-05:2181
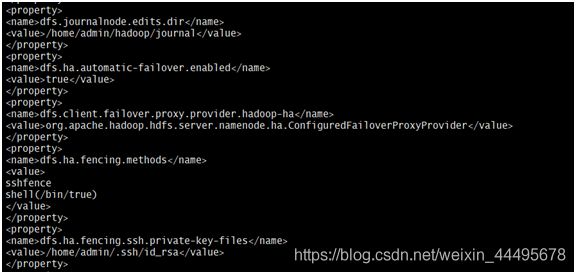
$vi hdfs-site.xml #对配置文件进行修改
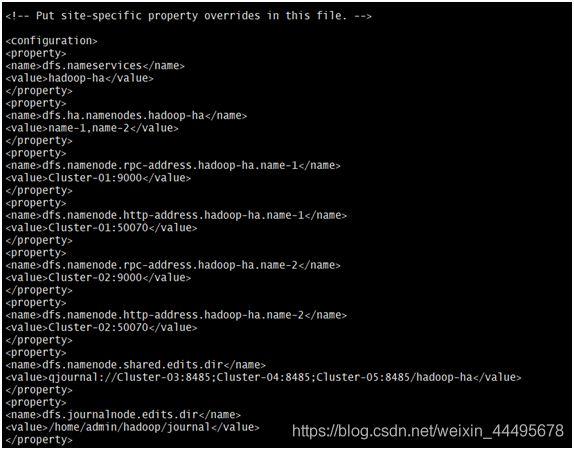
找到标签“”所在的位置,在其中添加如下红色部分的内容:
dfs.nameservices
hadoop-ha
dfs.ha.namenodes.hadoop-ha
name-1,name-2
dfs.namenode.rpc-address.hadoop-ha.name-1
Cluster-01:9000
dfs.namenode.http-address.hadoop-ha.name-1
Cluster-01:50070
dfs.namenode.rpc-address.hadoop-ha.name-2
Cluster-02:9000
dfs.namenode.http-address.hadoop-ha.name-2
Cluster-02:50070
dfs.namenode.shared.edits.dir
qjournal://Cluster-03:8485;Cluster-04:
8485;Cluster-05:8485/hadoop-ha
dfs.journalnode.edits.dir
/home/admin/hadoop/journal
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.hadoop-ha
org.apache.hadoop.hdfs.server.namenode.
ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/admin/.ssh/id_rsa
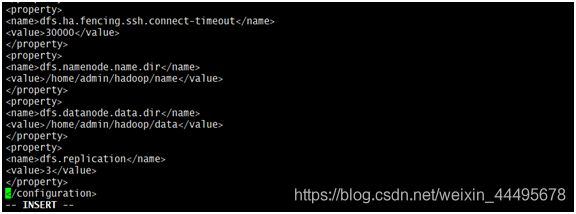
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.namenode.name.dir
/home/admin/hadoop/name
dfs.datanode.data.dir
/home/admin/hadoop/data
dfs.replication
3
$cp mapred-site.xml.template mapred-site.xml #由模板文件拷贝生成配置文件“mapred-site.xml”
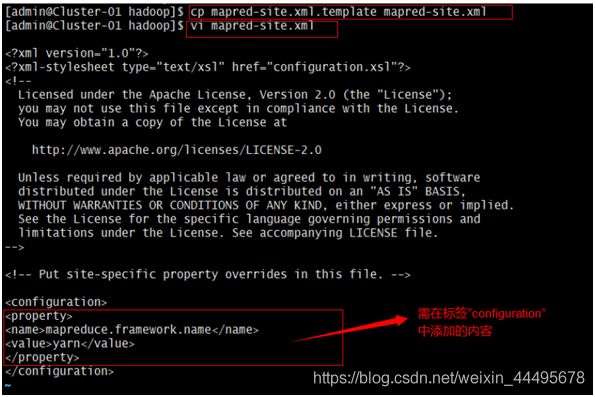
$vi mapred-site.xml #对配置文件进行修改
找到标签“”所在的位置,在其中添加如下红色部分的内容:
mapreduce.framework.name
yarn
$vi yarn-env.sh #对配置文件进行修改
找到配置项“JAVA_HOME”所在行,将其改为以下内容:(注意取消注释#,顶格)
Export JAVA_HOME=/home/admin/java/jdk1.8.0-131#该路径以JDK软件包实际解压解包的路径为准

$vi yarn-site.xml #对配置文件进行修改
![]()
找到标签“”所在的位置,在其中添加如下内容:
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yarn-ha
yarn.resourcemanager.ha.rm-ids
resource-1,resource-2
yarn.resourcemanager.hostname.resource-1
Cluster-01
yarn.resourcemanager.hostname.resource-2
Cluster-02
yarn.resourcemanager.zk-address
Cluster-01:2181,Cluster-02:2181,Cluster
-03:2181,Cluster-04:2181,Cluster-05:2181
yarn.nodemanager.aux-services
mapreduce_shuffle

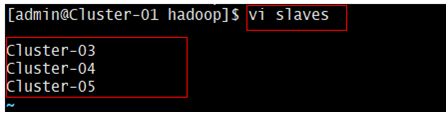
$vi slaves #对配置文件进行修改
删除文件中原有的所有内容,然后添加集群中所有数据节点的主机名,每行一个主机的主机名,配置格式如下:
Cluster-03
Cluster-04
Cluster-05
3、同步安装和配置
该项的所有操作步骤使用专门用于集群的用户admin进行
将“hadoop”目录和“.bash_profile”文件发给集群中所有主机,发送目标用户为集群专用用户admin,发送目标路径为“/home/admin”,即集群专用用户admin的家目录。
$scp -r ~/hadoop ~/.bash_profile admin@Cluster-02:/home/admin
$scp -r ~/hadoop ~/.bash_profile admin@Cluster-03:/home/admin
$scp -r ~/hadoop ~/.bash_profile admin@Cluster-04:/home/admin
$scp -r ~/hadoop ~/.bash_profile admin@Cluster-05:/home/admin
$source ~/.bash_profile #使新配置的环境变量立即生效
![]()
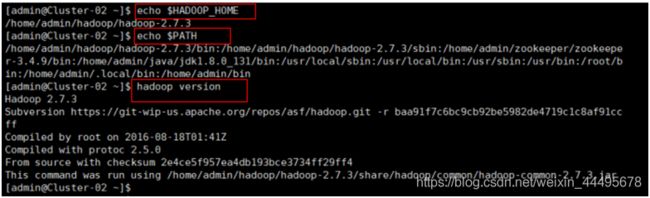
$echo $HADOOP_HOME #查看新添加和修改的环境变量是否设置
$echo $PATh 成功,以及环境变量的值是否正确
$hadoop version #验证Hadoop的安装配置是否成功
4、Hadoop高可用完全分布模式格式化和启动(注意本节格式化内容不可多次执行、注意格式化步骤)
该项的所有操作步骤使用专门用于集群的用户admin进行
$hadoop-daemon.sh start journalnode #在所有同步通信节点的主机执行,启动同步通信服务,然后使用命令“jps”查看java进程信息,若有名为“JournalNode” 的进程,则表示通步通信节点启动成功。
注:本操作只在第一次安装时执行。安装完成后,以及关机重启服务器后不需要再次执行。(Cluster-03、04、05)

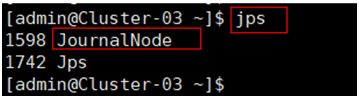
$jps
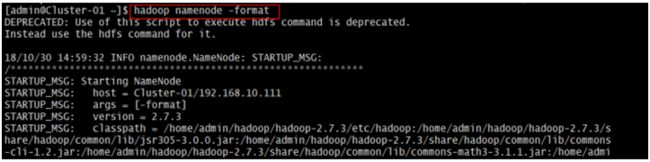
$hadoop namenode-format #在主节点使用此命令,对HDFS进行格式化,若格式化过程中没有报错则表示格式化成功。
注:本操作只在第一次安装时执行。安装完成后,以及关机重启服务器后不需要再次执行。千万不要多次格式化。
格式化完成后“hadoop”目录下“name”目录发给集群中所有备用主节点的主机,发送目标用户为集群专用用户admin,即当前与登录用户同名的用户,发送目标路径为“/home/admin/hadoop”,即集群专用用户admin家目录下的Hadoop相关文件的目录。
$scp -r ~/hadoop/name admin@Cluster-02:/home/admin/hadoop

$zkServer.sh status #在集群中所有主机使用此命令,查看该节点Zookeeper服务当前的状态,若集群中只有一个“leader”节点,其余的均为“follower" 节点,则集群的工作状态正常。如在主机Cluster-01上:

$zkServer.sh start #如果Zookeeper未启动,则在集群中所有主机上使用命令 “zkServer.sh start”启动Zookeeper服务的脚本。如在主机Cluster-01上:

启动后再查看所有主机节点Zookeeper服务当前的状态:Cluster-03为“leader”节点,其余的均为“follower" 节点

$hdfs zkfc -formatZK #在主节点使用命令,对Hadoop集群在Zookeeper中的主节点切换控制信息进行格式化,若格式化过程中没有报错则表示格式化成功。格式化之前确保集群中各主机Zookeeper开启。
注:本操作只在第一次安装时执行。安装完成后,以及关机重启服务器后不需要再次执行。千万不要多次格式化。

$在所有同步通信节点的主机,使用此命令,关闭同步通信服务。
注:本操作只在第一次安装时执行。安装完成后,以及关机重启服务器后不需要再次执行。

注:以下两步操作,启动命令,每次重启后,在Hadoop启动成功的前提下,只需执行两步即可。
$start-all.sh #在主节点使用命令,启动Hadoop集群。

$yarn-daemon.sh start resourcemanager #在所有备用主机节点的主机,使用此命令,启动YARN主节点服务。

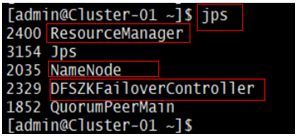
在主节点使用命令“jps”查看java进程信息,若有名为“NameNode”、“RecourseManger”、“DFSZKFailoverController”的三个进程,则表示Hadoop集群的主节点启动成功。
在所有备用主节点主机,使用命令“jps”查看java进程信息,若有名为“NameNode”、“RecourseManger”、“DFSZKFailoverController”的三个进程,则表示Hadoop集群的备用主节点启动成功。
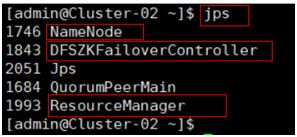
在所有数据节点主机,使用命令“jps”查看java进程信息,若有名为“DataNode”、“NodeManger”、“JournalNode”的三个进程,则表示Hadoop集群的数据节点启动成功。
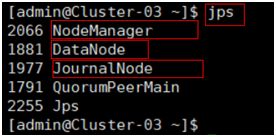
5、Hadoop高可用完全分布模式验证
该项的所有操作步骤使用专门用于集群的用户admin进行
$hadoop fs -mkdir -p /uers/admin #在Hadoop中创建当前登录用户自己的目录
![]()
$hadoop fs -ls -R / #查看HDFS中的所有文件和目录的结构

$cd ~/hadoop/hadoop-2.7.3/share/hadoop/mapreduce #进入Hadoop的示例程序包hadoop-macpreduce-examples-2.7.3.jar所在目录
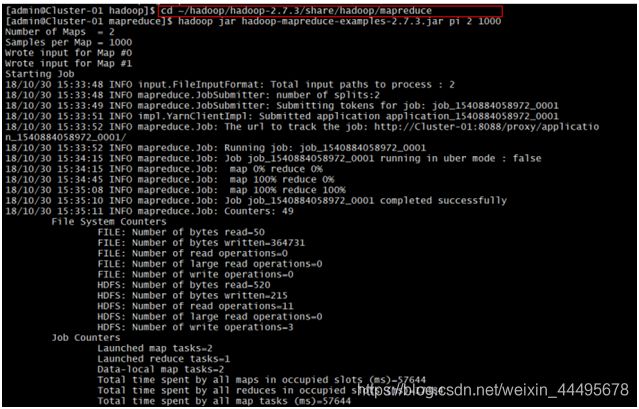
$cd jar hadoop-macpreduce-examples-2.7.3.jar pi 2 1000#运行使用蒙地卡罗法计算PI的示例程序

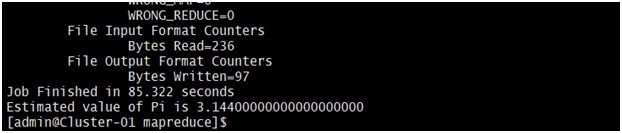
如有想法,欢迎评论!