ceph(分布式存储)
文章目录
- 一、ceph的组件和功能
-
- 1.简介
- 2.层次结构和功能
- 二、ceph的数据读写流程
- 三、使用ceph-deploy安装一个最少三个节点的ceph集群(推荐3个或以上的磁盘作为专用osd)
-
- 1.基础配置
-
- 配置主机名
- 给三台主机写入hosts解析
- 配置node1到所有节点root用户免密钥互信
- 配置时间同步
- 在node1上配置本地yum源
- 2.部署ceph集群
-
- 步骤一:安装ceph-deploy
- 步骤二:创建ceph集群,在/ceph-cluster目录下生成配置文件。
- 步骤三:准备日志磁盘分区
- 步骤四:创建OSD存储空间
- 步骤五:查看ceph状态,验证
- 步骤六:启用dashboard
一、ceph的组件和功能
1.简介
Ceph是一种为了优秀的性能、可靠性和可扩展性而设计的统一的、 分布式的存储系统。
“统一的” : 意味着Ceph可以一套存储系统同时提供对象存储、 块存储和文件系统存储三种功能, 以便在满足不同应用需求的前提下简化部署和运维。
“分布式” : 在Ceph系统中则意味着真正的无中心结构和没有理论上限的系统规模可扩展性。
2.层次结构和功能
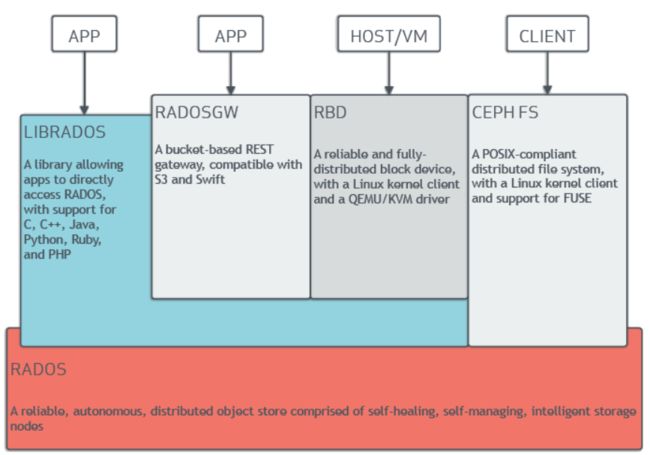
RADOS: 是一个完整的对象存储系统,所有存储在Ceph系统中的用户数据最终都是由这一层来存储的,主要由OSD、Monitor组成。
OSD:由数目可变的大规模OSD(Object Storage Devices)组成的集群,负责存储所有的Objects数据。( 默认有3个副本,但可以调整副本数)
Monitor:由少量Monitors组成的强耦合、小规模集群,负责管理Cluster Map。其中,Cluster Map是整个RADOS系统的关键数据结构,管理集群中的所有成员、关系和属性等信息以及数据的分发。
LIBRADOS:层的功能是对RADOS进行抽象和封装,并向上层提供API。
RADOSGW:功能特性基于LIBRADOS之上,提供当前流行的RESTful协议的网关,API抽象层次更高,并且兼容S3和Swift接口,作为对象存储
RBD(Rados Block Device):功能特性也是基于LIBRADOS之上,通过LIBRBD创建一个块设备,通过QEMU/KVM附加到VM上,作为传统的块设备来用。目前OpenStack、CloudStack等都是采用这种方式来为VM提供块设备,同时也支持快照、COW(Copy On Write)等功能。
Ceph FS(Ceph File System):功能特性是基于RADOS来实现分布式的文件系统,引入了MDS(Metadata Server),主要为兼容POSIX文件系统提供元数据。一般都是当做文件系统来挂载。(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )
MGR (ceph-mgr) :该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统
二、ceph的数据读写流程
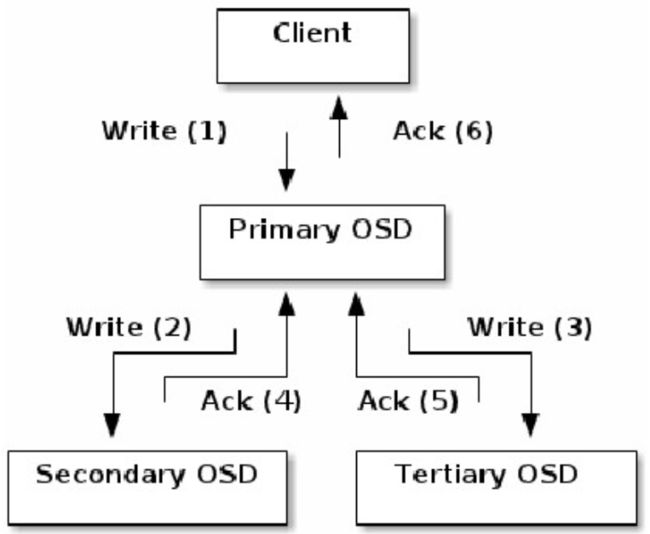
当某个client需要向Ceph集群写入一个file时, 首先需要在本地完成寻址流程, 将file变为一个object, 然后找出存储该object的一组三个OSD。
找出三个OSDS, client将直接和Primary OSD通信,
发起写入操作(步驟1 ) ;
Primary OSD收到请求后, 分别向Secondary OSD和
Tertiary OSD发起写入操作(步驟2 、 3) ;
当Secondary OSD和Tertiary OSD各自完成写入操作后, 将分别向Primary OSD发送确认信息(步骤4、 5) ;
当Primary OSD确信其他两个OSD的写入完成后, 则自己也完成数据写入, 并向client确认object写入操作完成( 步骤6) ;
三、使用ceph-deploy安装一个最少三个节点的ceph集群(推荐3个或以上的磁盘作为专用osd)
1.基础配置
| IP地址 | 主机名 | 附加磁盘 | 系统 |
|---|---|---|---|
| 192.168.43.111 | node1 | sdb,sdc,sdd | CentOS 7 X64 |
| 192.168.43.112 | node2 | sdb,sdc,sdd | CentOS 7 X64 |
| 192.168.43.113 | node3 | sdb,sdc,sdd | CentOS 7 X64 |
| 192.168.43.114 | client | sdb,sdc,sdd | CentOS 7 X64 |
sdb划分为两个区各5G,作为journal跟cache的缓存盘;sdc,sdd为数据共享盘
关闭防火墙和selinux
配置主机名
[root@localhost ~]# hostnamectl set-hostname node1
[root@localhost ~]# hostnamectl set-hostname node2
[root@localhost ~]# hostnamectl set-hostname node3
[root@localhost ~]# hostnamectl set-hostname client
给三台主机写入hosts解析

配置node1到所有节点root用户免密钥互信
只在node1上配置,生成密钥对
[root@node1 ~]# ssh-keygen -f ~/.ssh/id_rsa -N ‘’ -q
公钥分发到所有节点
[root@node1 ~]# for i in node1 node2 node3 client; do ssh-copy-id $i; done
验证免密钥互信
[root@node1 ~]# for i in node1 node2 node3 client; do ssh $i hostname; done
node1
node2
node3
client

配置时间同步
配置node1为时间服务器,其他节点作为客户端向node1同步时间
四台需同时操作
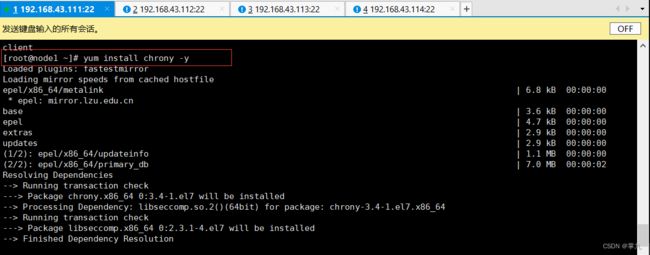
修改配置文件
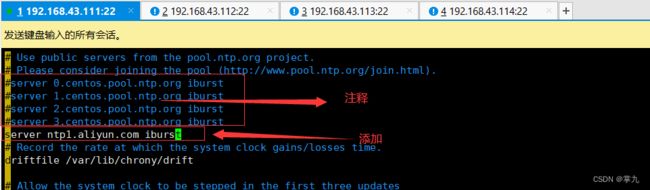
重启,并设置开机自启

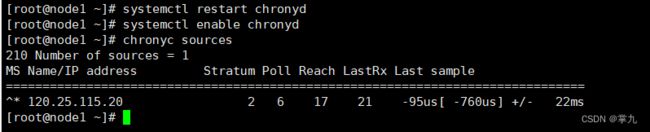
检查时间同步



在node1上配置本地yum源
[root@node1 ~]# cat getcephrpm.sh
#!/bin/sh
url=$1
version=$2
curl $1 |awk -F '"' '{print $4}' |grep $2 > /home/$2-list
mkdir -p /ceph/ceph-$2-rpm
for i in `cat /home/$2-list`
do
echo "===================== Now get file: $i ======================="
wget -r -p -np -k -P /ceph/ceph-$2-rpm $url$i
done
rm -f /home/$2-list
执行脚本:
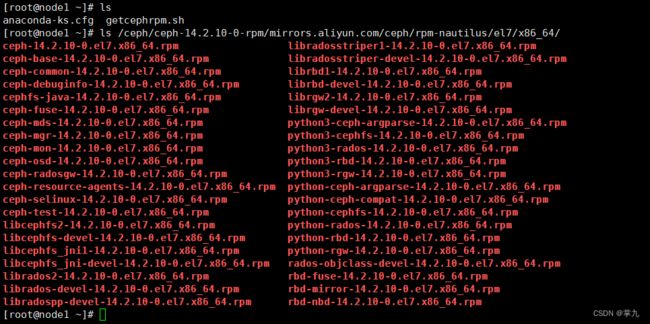
[root@node1 ~]# sh getcephrpm.sh http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/ 14.2.10-0
查看下载的指定包
[root@node1 ~]# ls /ceph/ceph-14.2.10-0-rpm/mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
同样,下载http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/ 下面的rpm包
[root@node1 ~]# sh getcephrpm.sh http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/ 14.2.10-0
ceph下创建目录x86_64和noarch,将下载好的x86_64和noarch下面内容分别拷贝到创建的对应目录
[root@node1 ~]# mkdir /ceph/{x86_64,noarch}
[root@node1 ~]# mv /ceph/ceph-14.2.10-0-rpm/mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/* /ceph/x86_64/
[root@node1 ~]# mv /ceph/ceph-14.2.10-0-rpm/mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/* /ceph/noarch/
单独下载ceph部署工具ceph-deploy至/ceph/ceph-noarch/
[root@node1 ~]# wget http://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-nautilus/el7/noarch/ceph-deploy-2.0.1-0.noarch.rpm -P /ceph/noarch/
使用createrepo创建仓库档案
[root@node1 ~]# yum install createrepo -y
[root@node1 ~]# createrepo -v /ceph/x86_64/
[root@node1 ~]# createrepo -v /ceph/noarch/
说明:
filelists.xml.gz:软件报的安装清单
primary.xml.gz:软件报的基本/主要信息
other.xml.gz:软件包的其他信息
repomd.xml:提高.xml.gz下载和校验信息
目录文件制作ISO文件
[root@node1 ~]# yum install mkisofs -y
[root@node1 ~]# mkisofs -r -o /opt/ceph.iso /ceph/
node1配置为yum仓库服务器,其他节点使用ftp方式使用ceph仓库
# 上传ceph.iso到node1
[root@node1 ~]# ll ceph.iso
-rw-r--r-- 1 root root 2408808448 Mar 18 09:15 ceph.iso
# 安装httpd并设置为开机自启动
[root@node1 ~]# yum install -y vsfpd
[root@node1 ~]# systemctl enable vsftpd --now
# 挂载ceph.iso到/var/ftp
[root@node1 ~]# mkdir /var/ftp/ceph
[root@node1 ~]# echo "/opt/ceph.iso /var/ftp/ceph iso9660 defaults 0 0" >> /etc/fstab
[root@node1 ~]# mount -a
# yum文件ceph.repo由后面的ceph-deploy工具安装时自动生成。


2.部署ceph集群
步骤一:安装ceph-deploy
注意:直接设置环境变量即可,否则集群部署过程将使用官方yum源;只在第一个节点操作
1、在node1上安装部署工具,学习工具的语法格式。
Ceph官方推出了一个用python写的工具 cpeh-deploy,可以很大的简化ceph集群的配置过程
[root@node1 ceph-cluster]# yum install /var/ftp/ceph/noarch/ceph-deploy-2.0.1-0.noarch.rpm
注意:安装高版本的ceph-deploy,否则后面配置会报错
[root@node1 ~]# ceph-deploy --help
[root@node1 ~]# ceph-deploy mon --help
2、node1上创建工作目录
[root@node1 ~]# mkdir /ceph-cluster
[root@node1 ~]# cd /ceph-cluster
步骤二:创建ceph集群,在/ceph-cluster目录下生成配置文件。
1、创建ceph集群
创建一个新集群,并设置mon节点。
node1-node3添加epel源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
解决方法——pip install distribute
[root@node1 ceph-cluster]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
[root@node1 ceph-cluster]# yum install python2-pip -y
[root@node1 ceph-cluster]# pip install distribute -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
再次执行:ceph-deploy new node1 node2 node3


2、给node1节点安装ceph相关软件包。
[root@node1 ceph-cluster]# ceph-deploy install node1 node2 node3

3、添加监控节点
初始化所有节点的mon服务,也就是启动mon服务。
[root@node1 ceph-cluster]# ceph-deploy mon create-initial
作用是将ceph.conf配置文件拷贝到所有mon节点,并将ceph-mon服务启动并设置开机自启
[root@node3 ~]# ls /etc/ceph/
ceph.conf rbdmap tmpn1zEAD
[root@node3 ~]# systemctl is-active [email protected]
active
4、创建ceph管理节点(mgr)
注意:每个运行了mon的节点上都需要安装mgr节点
[root@node1 ceph-cluster]# ceph-deploy mgr create node1 node2 node3

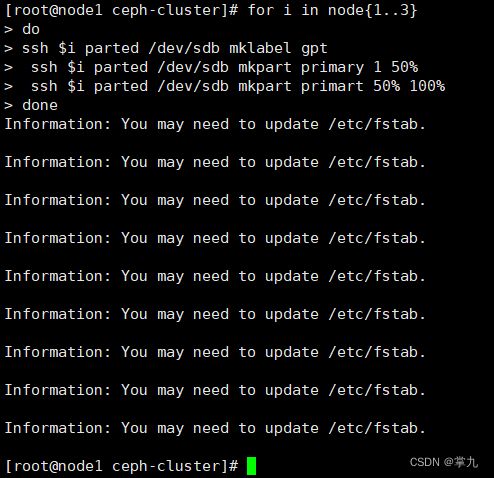
步骤三:准备日志磁盘分区
注意:sdb1和sdb2两个分区用来做存储服务器的journal缓存盘。生产中固态用于缓存,sas用户共享。
1、格式化sdb
[root@node1 ceph-cluster]# for i in node{1…3}
do
ssh $i parted /dev/sdb mklabel gpt
ssh $i parted /dev/sdb mkpart primary 1 50%
ssh $i parted /dev/sdb mkpart primart 50% 100%
done
2、磁盘分区后的默认权限无法让ceph对其进行读写操作,需要修改权限。
[root@node1 ceph-cluster]# for i in node{1…3}
do
ssh $i chown ceph.ceph /dev/sdb1 /dev/sdb2
done
以上操作服务器重启后再次重值导致授权失效,所以需要把规则写到配置文件实现永久有效。
规则1:如果设备名为/dev/sdb1,则设备文件的拥有者和拥有组为ceph
规则2:如果设备名为/dev/sdb2,则设备文件的拥有者和拥有组为ceph
[root@node1 ceph-cluster]# vim /etc/udev/rules.d/70-sdb.rules
ENV{DEVNAME}==“/dev/sdb1”,OWNER=“ceph”,GROUP=“ceph”
ENV{DEVNAME}==“/dev/sdb2”,OWNER=“ceph”,GROUP=“ceph”
复制到其他osd节点
[root@node1 ceph-cluster]# for i in node{2…3}
do
scp /etc/udev/rules.d/70-sdb.rules $i:/etc/udev/rules.d/
done

步骤四:创建OSD存储空间
1、初始化清空磁盘数据(仅在node1操作)
注意ceph-deploy v2.0.0开始不再使用ceph-disk命令来初始化osd磁盘,如果还使用旧的命令初始磁盘报错
[root@node1 ceph-cluster]# for i in node{1…3}
do
ssh $i parted /dev/sdc mklabel gpt
ssh $i parted /dev/sdd mklabel gpt
done
清理磁盘
[root@node1 ceph-cluster]# for i in node{1…3}
do
ssh $i ceph-volume lvm zap /dev/sdc
ssh $i ceph-volume lvm zap /dev/sdd
done
2、创建OSD存储空间
[root@node1 ceph-cluster]# ceph-deploy osd create --data /dev/sdc --journal /dev/sdb1 --data /dev/sdd --journal /dev/sdb2 node1
// 创建osd存储设备,sdc提供存储空间,sdb1提供缓存
[root@node1 ceph-cluster]# ceph-deploy osd create --data /dev/sdc --journal /dev/sdb1 --data /dev/sdd --journal /dev/sdb2 node2
[root@node1 ceph-cluster]# ceph-deploy osd create --data /dev/sdc --journal /dev/sdb1 --data /dev/sdd --journal /dev/sdb2 node3
步骤五:查看ceph状态,验证
在主节点生成的ceph.client.admin.keyring文件拷贝至所有节点的/etc/ceph下
[root@node1 ceph-cluster]# ceph-deploy admin node1 node2 node3
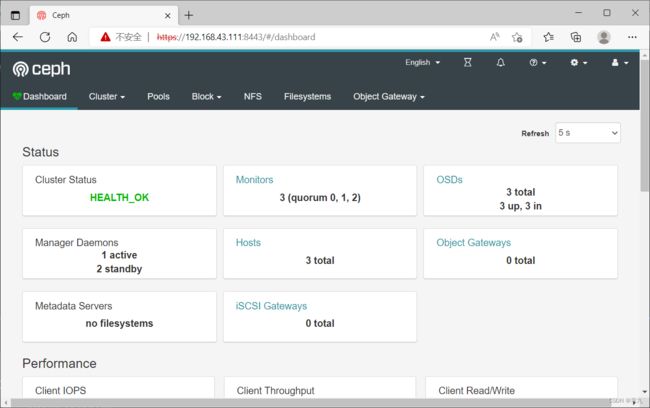
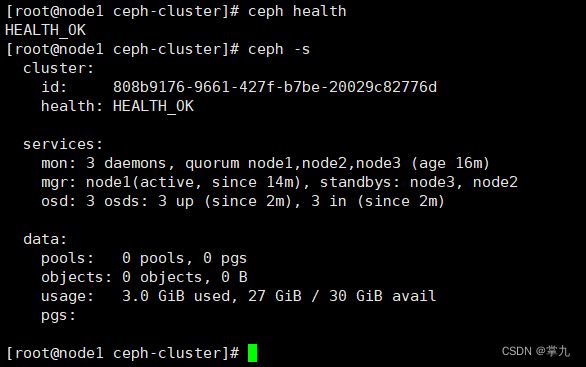
检查集群状态:使用命令 ceph health 或者 ceph -s
[root@node1 ceph-cluster]# ceph health

步骤六:启用dashboard
自 nautilus开始,dashboard作为一个单独的模块独立出来了,使用时需要在所有的mgr节点上单独安装
在所有的mgr节点上单独安装
[root@node1 ceph-cluster]# for i in node{1…3}
do
ssh $i yum install -y ceph-mgr-dashboard
done
启用dashboard
[root@node1 ceph-cluster]# ceph mgr module enable dashboard --force
默认启用SSL/TLS,所以需要创建自签名根证书
[root@node1 ceph-cluster]# ceph dashboard create-self-signed-cert

创建具有管理员角色的用户
[root@node1 ceph-cluster]# ceph dashboard ac-user-create admin admin administrator
{“username”: “admin”, “lastUpdate”: 1616031372, “name”: null, “roles”: [“administrator”], “password”: “$2b$12$4wa4pCKkDf.pvDO9LFldZuwn1GRt.W6zDXvV9QHxnjovrmpA3inWS”, “email”: null}

查看ceph-mgr服务
[root@node1 ceph-cluster]# ceph mgr services
{
“dashboard”: “https://node1:8443/”
}