【Hbase】知识总结
Hbase的简介
Hbase的来源
1、数据量越来越大,传统的关系型数据库,不能满足存储和查询功能的需求。而hive虽然能够满足存储的要求,但是hive的本质也是利用底层的mr,所以读写速度不快,而且hive不能满足非结构化,半结构化的存储,hive主要的作用是分析和统计,hive用于存储是毫无意义的。
2、起源于Google在2006发表的一篇论文《bigtable》,是对bigtable的开源实现的java版本
Hbase的定义
Hbase是一个在HDFS上运行的,面向列的,分布式的,hadoop数据库。他是一个非关系型()(Not Only Sql)的数据库,不是传统的非关系型数据库,对事物支持很差起源于《BigTable》
Hbase的特征
1、适合存储超大规模的数据集,可以提供数据的实施读写。
2、线性扩展好,高的可靠性。
3、Hbase的表模型与关系型数据库的表模型不同:
a)Hbase表中没有固定的字段定义
b)Hbase表中每行存储的都是些key-value对
c)Hbase表中有列簇的划分,用户可以指定将哪些kv插入哪个列簇
d)Hbase的表在物理存储上,是按照列簇来切分的,不同列簇的数据一定存储在不同的文件中
e)Hbase表中的每一行都有固定的行键作为唯一标识,每行的行键在表中是不能重复的
4、Hbase中的数据,包含行键、key、value都是byte[]类型,Hbase不负责为用户维护数据类型。
5、Hbase对事物的支持很差。
Hbase的表模型
Hbase是一个面向列的,非关系型数据库,区别于面向行存储的非关系型数据库。
1、Hbase表的基本存储单位是一个单元格(cell),也可以成为列(column)
2、单元格内存储的是一对key-value键值对
3、每一对键值对都有N个时间戳作为版本号(版本数量可以控制)
4、为了管理不同的key-value,Hbase引入了列簇的概念
a)一个表可以有多个列簇(不同列簇的数据一定存储在不同文件中,一个列簇对应一个文件)
b)一个列簇下可以有成千上百万个不同的key-value,即列
5、为了标识某一个key-value是某一个事物的,引入了rowKey的概念,rowKey作为唯一标识符,不能重复。
6、一张表由于数据量过大,会被横向切分成若干个region(用rowKey范围标识),不同region的数据也存储在不同的文件之中
7、Hbase会对插入的数据按顺序存储:(内存)
a)首先会按照行键排序
b)行键相同,会按照列簇排序,再按key排序,若key也相同,则根据版本号来排序(时间戳)
Hbase存储结构中的概念
单元格
1、关系型数据库中的表模型是由行和列构成,交叉点我们称之为Cell(单元格),用于存储字段(Column)的数据。
2、 Hbase的表模型与关系型数据库的表模型不同。在单元格上是以 key-value 形式来存储某一个字段(Column)数据的。每一个单元格都有自己对应的版本号。
rowKey(行键)
对于每个单元格(列名与值)来说,他属于哪一行记录,尤为重要,因此引入rowkey这个概念,用于区分单元格属于那一行记录,行键是唯一存在的,不能重复。
** 列族(Column family)**
1、列簇是多个列的集合,用于统一管理相似的数据。
2、Hbase会尽量把同一个列簇的列放在同一个服务器上,这样可以提高存取得效率,可以批量管理有关得一堆列。
3、一个列簇对应一个目录,不同得列簇一定存储在不同得文件中。
4、Hbase在建表时,指定的是列簇,而非列,列簇的个数有限制,默认是10个。
5、列簇是由多个列组成,列簇的成员可以有上百万个。
6、列簇成员的标识方式: ColFamiName:colName
Hbase的架构
Hbase的架构如下图
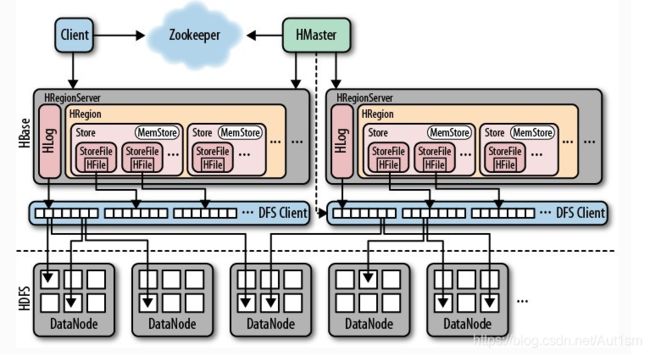
文字描述
1、client hbase的客户端
包含访问hbase的接口,除此之外,他还会维护缓存,来加速访问hbase的速度,如region位置信息
2、Zookeeper
a)监控Hmaster的状态,保证有且仅有一个Hmaster处于活跃状态
b)它可以存储所有region的寻址入口,如:root表放在拿一台服务器上
c)可以实时监控HregionServer的状态,维护HregionServer的动态上下线
d)存储hbase的部分元数据
3、Hmaster
a)为HregionServer分配region(新建表)
b)负责HregionServer的负载均衡,
c)负责region的重新分配:HregionServer宕机之后或者HregionServer切分之后
d)Hdfs上的垃圾回收
e)处理schema的更新(增删改)
4、HregionServer
a)管理Hmaster分配的region(管理本机的region)
b)处理客户端的读写请求,并和Hdfs进行交互,(Hlog写入,Hfile读写)
c)切分region的操作者,实际是由Hmaster管理切分的,所以Hmaster不能够长时间的宕机
5、Hlog
a)对Hbase的操作进行记录,使用WAL写数据,优先写入Hlog
操作时,先写入Hlog,再写入memstore,这样可以防止数据丢失,即使数据丢失,也可以回滚
6、Hregion
Hbase中分布式存储和负载均衡的最小单元,他是表,或者表的一部分。
7、Store
相当于列簇
8、memstore
内存缓冲区,用于将数据刷写到hdfs中,默认大小为128M
9、HStoreFile(HFile)
和HFile概念一样,不过是一个逻辑概念(存储的是HFile的元数据信息)。HBase中的数据是以HFile存储在Hdfs上。可以理解为hbase中的hstorefile是以hfile的形式存在在hdfs上的。
Hbase各组件之间的比例关系
hmaster:hregionserver=1:*
hregionserver:hregion=1:*
hregionserver:hlog=1:1
hregion:hstore=1:*
store:memstore=1:1
store:storefile=1:*
storefile:hfile=1:1
Hbase的存储机制
Hbase中的所有文件数据都存储在hadoop hdfs上,主要包括两种文件类型
- HFile(HStoreFile)
HFile是HBase的数据存储的实际载体,Hbase不直接与磁盘进行交互,而是通过调用HDFS的client接口,由HDFS进行存储的。 - Hlog
HBase中采用WAL(Write Ahead Log)的存储格式,物理上是Hadoop的SequenceFile。在写数据时会先往Hlog写一份,然后往内存写,以避免内存丢失数据,可以从日志文件中恢复Hlog记录数据的所有变更。
每个HregionServer上维护一个Hlog,而不是每个Hregion上一个,这样,不同的Hregion的日志信息会混在一起,这样做的目的是:将日志不断追加到一个文件,相对于同时写多个文件而言,可以减少磁盘的寻址次数,因此可以提高table的写性能。但是,如果一台HregionServer下线,为了恢复其上的region,需要将HregionServer上的log进行拆分,然后发送到其他的HregionServer上进行恢复。
Hregion存储
HregionServer内部管理了一系列的Hregion对象,每个Hregion对应了一个Table,或者 多个Hregion对应一个Table,在Hregion中,有多个HStore,每个HStore对应Table中的一个列簇的存储,ColumnFamily(列簇)其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个ColumnFamily中,这样性能最好。
HStore存储是Hbase存储的核心,包含一个或者0个memStore,MemStore是Sorted Memory Buffer,用户写入的数据首先会放到MenStore中,这里可以对数据进行整理和排序,当MemStore满了之后(或是达到了相应的条件,真个Hregion的阈值),会flush成一个StoreFile,(底层实现是Hfile),用户可以手动flush,将内存中的数据直接溢写到磁盘上,进行手动干预。
Flush与Compact、Split
- Flush
客户端的数据写入内存,一直到MemStore满了或者达到阈值之后,会将MemStore中的数据flush成一个StoreFile- Compact
当StoreFile的数量越来越多时,增长到数量阈值,会触发Compact操作,合并多个StoreFile,同时进行【版本的合并和标记删除数据的删除】。- Split
由于合并操作,当合并后的StoreFile的大小超过一定阈值之后,会触发Region的spilt操作,实际是新生成两个region来管理维护旧的Region中的数据,旧的Region会下线,新的两个Region会被Hmaster分配到相应的HregionServer上,这样使得原来一个region的压力分流到两个region上。
增删改查的本质
- 新增单元格数据时,在HDFS上新增一条记录
- 修改一个单元格时,也是新增一条记录,只是版本号比之前大了。
- 删除时,还是新增一条记录,只不过没有value值,类型为DELETE。
为了提高性能,Hbase每间隔一段时间或者文件大小达到阀值后,都会进行一次合并,
合并的对象就是HFile文件。当合并成一个HFile时,会忽略掉DELETE类型的记录,
从而达到了删除的目的,并对剩下的数据做排序和版本合并。形成一个大的HFile,
当Hfile的大小达到需要切分的阀值时,会等分为两个HFile...
Hbase的寻址操作
Hbase早期寻址操作
三层寻址
1、Client --> -root-表 --> .meta.表 --> region
Region:
就是你要查找的数据所在的Region
.meta.:
是一张元数据表,存储了所有Region的简要信息。.meta.表中的一行记录就是一个region信息,记录了该region的startkey,endkey,及其地址信息
-root-:
是一张存储.meta.表的表。.meta.可以有很多张,而root就是存储了.meta.表在什么region上。通过这样的扩展,可以支持大约171亿个region。
寻址步骤:
1、用户通过查找zk的/hbase/root-region-server节点来知道-root-表在哪个RegionServer上。
2、访问-root-表,来看你需要的数据在哪个.meta.表上,并获取这个.meta.在哪regisonserver上
3、访问.meta.表,来查看你要查询的行间在什么Region里
4、连接具体的数据所在的Regionserver,这回就可以开始获取数据了。
说明:
(1) root region永远不会被split,保证了最多需要三次跳转,就能定位到任意region 。
(2).META.表每行保存一个region的位置信息,
(3) 为了加快访问,.META.表的全部region都保存在内存中。
(4) client会将查询过的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行最多6次网络来回,才能定位到正确的region(其中三次用来发现缓存失效,另外三次用来获取位置信息)。
现在的寻址操作
去掉了root表及其zookeeper中的/hbase/root-region-server.直接将meta表所在的regionsServer信息存储在zk中的/hbase/meta-region-server中,在后来引用了namespace,meta表改成了hbase:meta.
寻址操作
1. 用户可以通过查找zk的/hbase/meta-region-server节点来查询哪个regionserver上存储hbase:meta,
2. 访问含有hbase:meta表所在的RegionServer,然后通过hbase:meta表来查询你要查询的行间在什么region里,以及这个region所在regionserver
3. 连接具体的数据所在的regionserver,并找到region开始获取数据
4. 客户端会把meta信息缓存起来,下次操作就不需要进行加载hbase:meta的步骤了。
Hbase的读写流程
Hbase的读流程
1. Client访问Zookeeper,查找-ROOT-表,获取.META.表信息。
2. 从.META.表查找,获取存放目标数据的Region信息,从而找到对应的RegionServer。
3. 通过RegionServer获取需要查找的数据。
4. Region的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。如果你开启了BlockCache,读请求先到BlockCache中查数据,查不到就到Memstore中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
Hbase的写流程
1、和读流程一样,先通过zk找到要写入的region信息。
2、陷阱数据写入到MemStore中,直到MemStore达到预设阈值。
3、(Flush) MemStore中的数据被Flush成一个StoreFile。
4、(Compact) 随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除。
5、StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile。
6、(Split)单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个新的Region。父Region会下线,新Split出的2个子Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上。