最强 CNI 基准测试:Cilium 网络性能分析

大家好!
随着越来越多的关键负载被迁移到 Kubernetes 上,网络性能基准测试正在成为选择 Kubernetes 网络方案的重要参考。在这篇文章中,我们将基于过去几周进行的大量基准测试的结果探讨 Cilium 的性能特点。应广大用户的要求,我们也将展示 Calico 的测试结果,以便进行直接对比。
除了展示测试的结果数据外,我们还将对容器网络基准测试这一课题进行更深入的研究,并探讨以下几个方面的问题:
吞吐量基准测试
容器网络是否会增加开销
打破常规:eBPF 主机路由(Host Routing)
测量延迟:每秒请求数
Cilium eBPF 和 Calico eBPF 的 CPU 火焰图对比
新连接处理速率
WireGuard 与 IPsec 加密开销对比
测试环境
测试结果汇总
![]()
在详细分析基准测试及其数据之前,我们先展示汇总的测试结论。如果您希望直接了解测试细节并得出自己的结论,也可以跳过这一节的内容。
eBPF 起决定性作用:Cilium 在某些方面优于 Calico 的 eBPF 数据路径(Data Path),例如在 TCP_RR 和 TCP_CRR 基准测试中观察到的延迟。此外,更重要的结论是 eBPF 明显优于 iptables。在允许使用 eBPF 绕过 iptables 的配置环境中,Cilium 和 Calico 的性能都明显优于不能绕过 iptables 的情况。
在研究具体细节后,我们发现 Cilium 和 Calico 利用 eBPF 的方式并不完全相同。虽然二者的某些概念是相似的(考虑到开源的性质,这也并不奇怪),CPU 火焰图显示 Cilium 利用了额外的上下文切换节省功能。这或许可以解释 TCP_RR 和 TCP_CRR 测试结果的差异。
总体而言,从基准测试结果来看,eBPF 无疑是解决云原生需求挑战的最佳技术。
可观测性、NetworkPolicy 和 Service:对于这个基准测试,我们把关注的焦点放在二者的共性上,也就是网络。这使得我们可以直接对比节点网络带来的性能差异。然而,在实际应用中也会需要用到可观测性、NetworkPolicy 和 Service,在这些方面 Cilium 和 Calico eBPF 数据路径差异巨大。Cilium 支持一些 Calico eBPF 数据路径不具备的功能,但即便是 Kubernetes NetworkPolicy 之类的标准功能,Cilium 和 Calico 的实现方式也不一样。如果我们投入更大的精力测试在这些更高级的用例中应用 eBPF,我们可能会发现二者在这些方面的性能有显着差异。然而,限于篇幅本文将不对此作更多的探讨,更加深入的研究将留给下一篇文章。
对比 WireGuard 和 IPsec:有些令人意外,尽管 WireGuard 在我们的测试中能够实现更高的最大吞吐量,但 IPsec 在相同的吞吐量下 CPU 使用效率更高。这很有可能得益于 AES-NI CPU 指令集。该指令集支持卸载 IPsec 的加密工作,但 WireGuard 不能从中受益。当 AES-NI 指令集不可用时,结果就明显反转了。
好消息是,从 Cilium 1.10 开始,Cilium 不仅支持 IPsec 还支持 WireGuard。您可以选择其中之一来使用。
吞吐量基准测试
![]()
免责声明:
基准测试难度很大。测试结果很大程度上依赖于运行测试的硬件环境。除非是在相同的系统上收集的结果,否则不应直接用绝对的数值进行比较。
让我们从最常见和最明显的 TCP 吞吐量基准测试开始,测量运行在不同节点上的容器之间的最大数据传输速率。
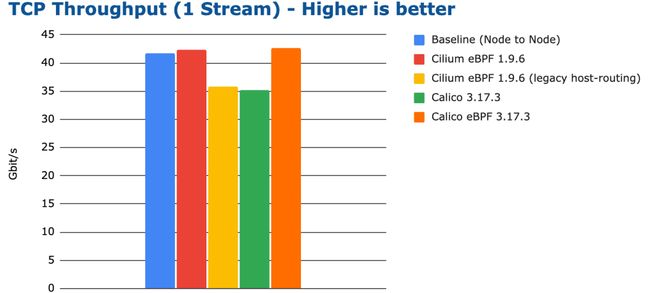
bench tcp stream 1 stream
上图显示了单个 TCP 连接可实现的最大吞吐量,最优的几个配置性能刚好超过了 40 Gbit/s。以上结果由 netperf 的 TCP_STREAM 测试得出,测试环境使用了速率为 100 Gbit/s 的网口以确保网卡不会成为瓶颈。由于运行单个 netperf 进程通过单个 TCP 连接传输数据,大部分的网络处理是由单个 CPU 核心完成的。这意味着上面的最大吞吐量受到单个核心的可用 CPU 资源限制,因此可以显示当 CPU 成为瓶颈时每个配置可以实现的吞吐量。本文后面将会进一步扩展测试,使用更多的 CPU 核心来消除 CPU 资源的限制。
使用高性能 eBPF 实现的吞吐量甚至略高于节点到节点的吞吐量。这令人非常意外。通常普遍认为,相较于节点到节点的网络,容器网络会带来额外的开销。我们暂时先把这个疑惑搁置一旁,进一步研究之后再来分析这个问题。
100 Gbit/s 传输速率所需的 CPU 资源
![]()
TCP_STREAM 基准测试的结果已经暗示了哪些配置可以最有效地实现高传输速率,但我们还是看一下运行基准测试时系统整体的 CPU 消耗。
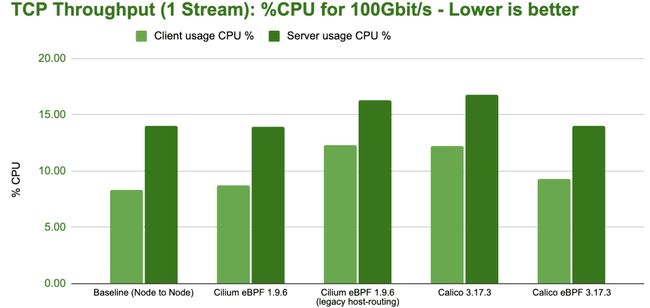
bench tcp stream 1 stream cpu
上图显示了达到 100 Gbit/s 吞吐量整个系统所需的 CPU 使用率。请注意,这不同于前一个图中吞吐量对应的 CPU 消耗。在上图中,所有的 CPU 使用率都已折算为传输速率稳定在 100 Gbit/s 时的数值以便可以直接对比。上图中的条形图越短,对应的配置在 100 Gbit/s 传输速率时的效率越高。
注意:TCP 流的性能通常受到接收端的限制,因为发送端可以同时使用 TSO 大包。这可以从上述测试中服务器侧增加的 CPU 开销中观察到。TCP 吞吐量基准测试的意义
虽然大多数用户不太可能经常遇到上述的吞吐量水平,但这样的基准测试对特定类型的应用程序有重要意义:
需要访问大量数据的 AI/ML 应用程序
数据上传/下载服务(备份服务、虚拟机镜像、容器镜像服务等)
流媒体服务,特别是 4K+ 分辨率的流媒体
在本文后面的章节,我们将继续深入讨论测量延迟:每秒请求数和新连接处理速率,以更好地展示典型微服务工作负载的性能特点。
容器网络是否会增加开销
![]()
在第一个基准测试的分析中我们提到,与节点网络相比,容器网络会带来一些额外开销。这是为什么呢?让我们从架构的角度来对比这两种网络模型。
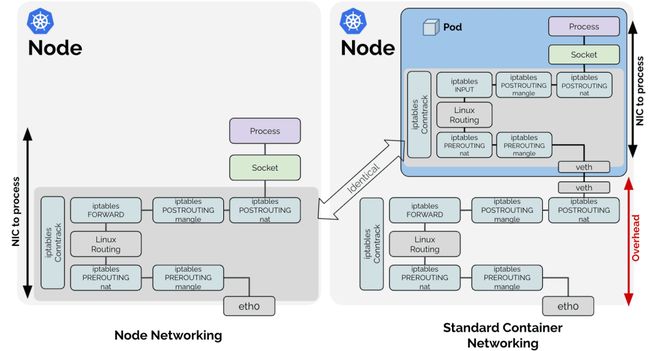
container overhead
上图表明容器网络也需要执行节点到节点网络的所有处理流程,并且这些流程都发生在容器的网络命名空间中(深蓝色部分)。
由于节点网络的处理工作也需要在容器网络命名空间内进行,在容器网络命名空间之外的任何工作本质上都是额外开销。上图显示了使用 Veth 设备时,Linux 路由的网络路径。如果您使用 Linux 网桥或 OVS,网络模型可能略有不同,但它们基本的开销点是相同的。
打破常规:eBPF 主机路由(Host-Routing)
![]()
在上面的基准测试中,您也许会疑惑 Cilium eBPF 和 Cilium eBPF 传统主机路由(Legacy Host Routing)两种配置的区别,以及为什么原生的 Cilium eBPF 数据路径会比主机路由快得多。原生的 Cilium eBPF 数据路径是一种被称为 eBPF 主机路由的优化数据路径,如下图所示:
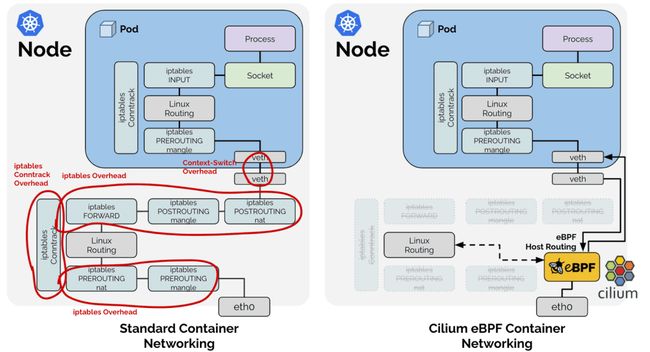
ebpf hostrouting
eBPF 主机路由允许绕过主机命名空间中所有的 iptables 和上层网络栈,以及穿过 Veth 对时的一些上下文切换,以节省资源开销。网络数据包到达网络接口设备时就被尽早捕获,并直接传送到 Kubernetes Pod 的网络命名空间中。在流量出口侧,数据包同样穿过 Veth 对,被 eBPF 捕获后,直接被传送到外部网络接口上。eBPF 直接查询路由表,因此这种优化完全透明,并与系统上运行的所有提供路由分配的服务兼容。关于如何启用该特性,请参阅调优指南中的 eBPF 主机路由[1]。
Calico eBPF 正在将一些类似的绕过方法用于 iptables,但这与 Cilium 的原理并不完全相同,文章后面会进一步介绍。不管如何,测试结果证明绕过缓慢的内核子系统(例如 iptables)可以带来极大的性能提升。
逼近 100 Gbit/s 的线速率(Line Rate)
![]()
在上文中,我们分析了只涉及一个 CPU 核心的基准测试结果。接下来我们将放开单核的限制,将 TCP 流并行化以运行多个 netperf 进程。
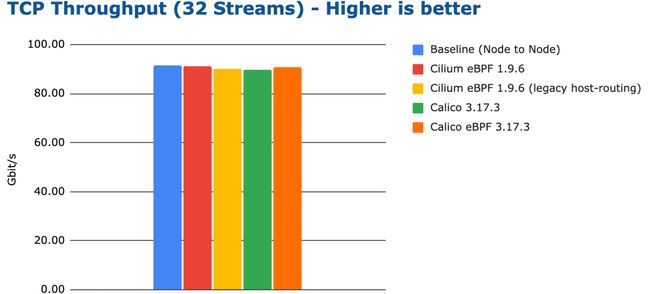
bench tcp stream 32 streams
注意:由于硬件有 32 个线程,我们特意选择了 32 个进程,以确保系统能够均匀地分配负载。
上图并没有提供十分有价值的信息,仅仅表明如果投入足够多的 CPU 资源,所有测试配置都能达到接近 100 Gbit/s 的线速率。然而,从 CPU 资源来看,我们仍然可以发现效率上的差异。
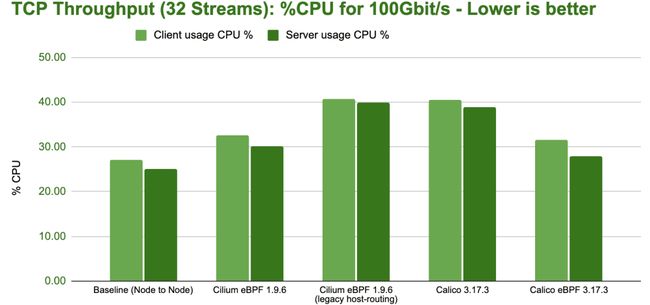
bench tcp stream 32 streams cpu
请注意,上图中的 CPU 使用率涵盖了全部的 CPU 消耗,包括正在运行的 netperf 进程的消耗,也包括工作负载执行网络 I/O 所需的 CPU 资源。然而,它并不包括应用程序通常需要执行的任何业务逻辑所带来的 CPU 消耗。
测量延迟:每秒请求数
![]()
每秒请求数与吞吐量指标几乎完全相反。它可以衡量单个 TCP 持久连接上按顺序的单字节往返的传输速率。此基准测试可以体现网络数据包的处理效率。单个网络数据包的延迟越低,每秒可处理的请求就越多。吞吐量和延迟的共同优化通常需要进行权衡。为了获得最大的吞吐量,较大的缓冲区是理想的选择,但是较大的缓冲区会导致延迟增加。这一现象被称为缓冲区膨胀。Cilium 提供了一个称为带宽管理器(Bandwidth Manager)[6]的功能,该功能可以自动配置公平队列,可实现基于最早发出时间的 Pod 速率限制,并为服务器工作负载优化 TCP 栈设置,使吞吐量和延迟之间达到最佳平衡。
这个基准测试经常被忽视,但它对用户来说通常比想象的重要得多,因为它模拟了一种十分常见的微服务使用模式:使用持久化的 HTTP 或 gRPC 连接在 Service 之间发送请求和响应。
下图显示单个 netperf 进程执行 TCP_RR 测试时,不同配置的性能表现:
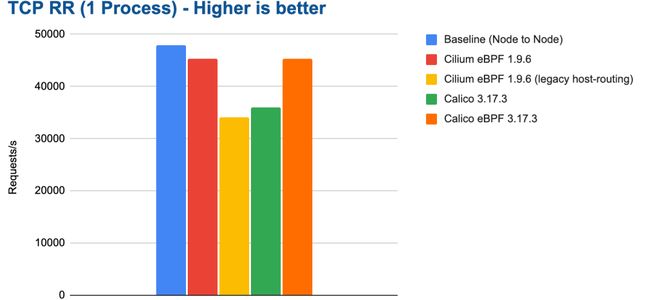
bench tcp rr 1 process
在这个测试中表现更好的配置也实现了更低的平均延迟。然而,这并不足以让我们对 P95 或 P99 延迟得出结论。我们将在未来的博客文章中探讨这些问题。
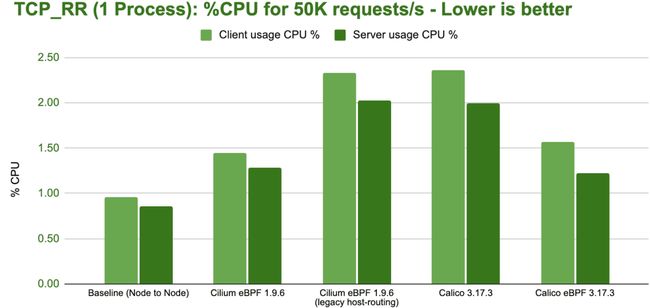
bench tcp rr 1 process cpu
我们进一步测试运行 32 个并行的 netperf 进程以利用所有可用的 CPU 核心。可以看到,所有配置的性能都有所提升。然而,与吞吐量测试不同的是,在本测试中投入更多的 CPU 资源并不能弥补效率上的欠缺,因为最大处理速率受延迟而非可用 CPU 资源限制。即便网络带宽成为瓶颈,我们也会看到相同的每秒请求数值。
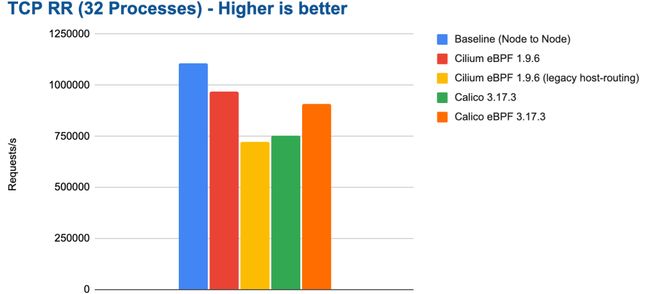
bench tcp rr 32 processes
总体而言,结果非常鼓舞人心,Cilium 可以在我们的测试系统上通过 eBPF 主机路由实现近 1,000,000 请求每秒的处理速率。

bench tcp rr 32 processes cpu
Cilium eBPF 和 Calico eBPF 的 CPU 火焰图对比
![]()
总体而言,Cilium eBPF 和 Calico eBPF 的性能基本相同。这是因为它们使用了相同的数据路径吗?并不是。并不存在预定义的 eBPF 数据路径。eBPF 是一种编程语言和运行时引擎,它允许构建数据路径特性和许多其他特性。Cilium 和 Calico eBPF 数据路径差异很大。事实上,Cilium 提供了很多 Calico eBPF 不支持的特性。但即使是在与 Linux 网络栈的交互上,两者也有显着的差异。我们可以通过二者的 CPU 火焰图来来进一步分析。
Cilium eBPF(接收路径)

cilium flamegraph zoom
Cilium 的 eBPF 主机路由提供了很好的免上下文切换的数据传送途径(从网卡到应用程序的套接字)。这就是为什么在上面的火焰图中整个接收端路径能够很好地匹配到一张火焰图中。火焰图也显示了 eBPF、TCP/IP 和套接字的处理块。
Calico eBPF(接收路径)
Calico eBPF 接收端看起来却不太一样。虽然有着相同的 eBPF 处理块执行 eBPF 程序,但 Calico eBPF 接收路径穿过了额外的 Veth,这在 Cilium eBPF 数据路径接收端并不需要。
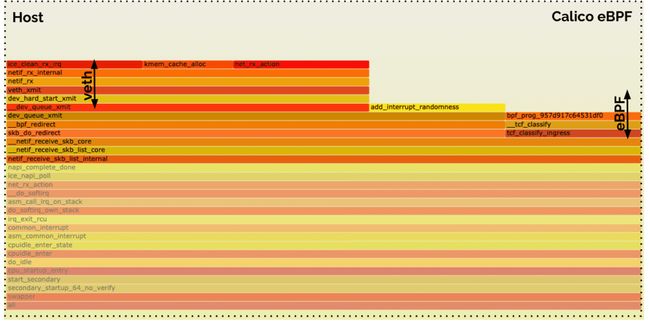
calico flamegraph zoom1
上图中的处理仍然在主机的上下文中执行。下面的这火焰图显示了 Pod 中被 process_backlog 恢复执行的工作。虽然这与 Cilium 场景下的工作一样(都是 TCP/IP+套接字数据传送),但因为穿过了 Veth 从而需要额外的上下文切换。
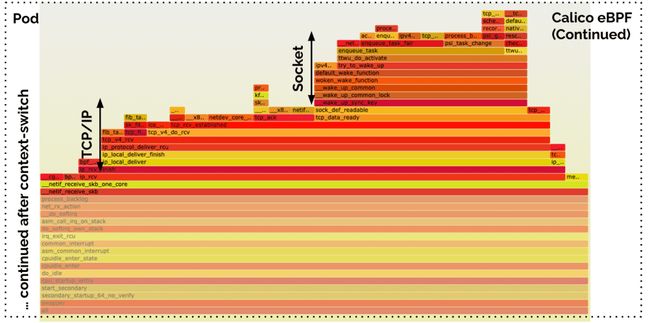
calico flamegraph zoom2
如果您希望自己进行更进一步的研究,可以点击以下链接打开交互式的火焰图 SVG 文件查看细节:
https://cilium.io/b85c71fbc3ce620c8544c9317f2bf858/cilium-ebpf-hr-rr-zh3.svg
https://cilium.io/67a828b79d79f0360468cc02810c10e0/cilium-ebpf-hr-rr-zh4.svg
https://cilium.io/3680690af3f6b5827065c0181025861e/calico-ebpf-rr-zh3.svg
https://cilium.io/cc3abd245b9bc7bf5bcab5bf04c18f29/calico-ebpf-rr-zh4.svg
新连接处理速率
![]()
连接处理速率基准测试基于每秒请求数的基准测试,但为每个请求都建立了新的连接。此基准测试的结果显示了使用持久连接和为每个请求创建新连接两种方式的性能差别。创建新 TCP 连接需要涉及系统中的多个组件,所以这个测试是目前对整个系统压力最大的测试。通过这个基准测试,我们可以看到,充分利用系统中大多数的可用资源是可能的。
这个测试展示了一个接收或发起大量 TCP 连接的工作负载。典型的应用场景是由一个公开暴露的服务处理大量客户端请求,例如 L4 代理或服务为外部端点(例如数据抓取器)创建多个连接。这个基准测试能够在卸载到硬件的工作最少的情况下尽可能地压测系统,从而显示出不同配置的最大性能差异。
首先,我们运行一个 netperf 进程来进行 TCP_CRR 测试。

bench tcp crr 1 process
在单个进程下不同配置的性能差异已经十分巨大,如果使用更多的 CPU 核心差异还将进一步扩大。同时也可以明显看出,Cilium 再次能够弥补网络命名空间额外开销造成的性能损失并达到和基线配置几乎相同的性能。
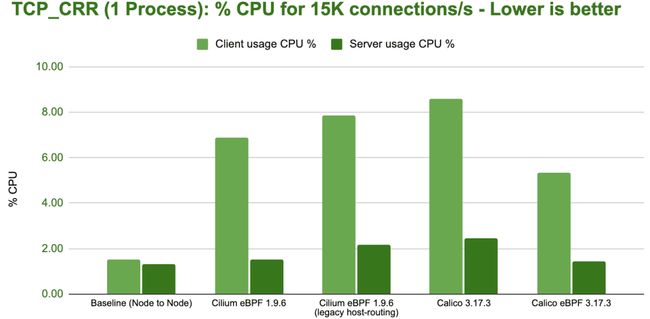
bench tcp crr 1 process cpu
后续计划:这个 CPU 资源使用率让我们很惊讶并促使我们在接下来 1.11 的开发周期做进一步研究。似乎只要涉及到网络命名空间的使用,发送端的资源开销总是必不可少的。这一开销在所有涉及网络命名空间的配置中都存在,所以很有可能是由 Cilium 和 Calico 都涉及的内核数据路径造成的。我们会及时更新这部分研究的进展。
当并行运行 32 个进行 TCP_CRR 测试的 netpert 进程以利用所有 CPU 核心时,我们观察到了一个非常有意思的现象。
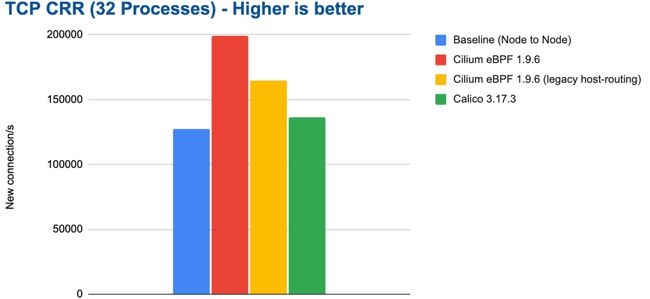
bench tcp crr 32 processes
基线配置的连接处理速率显着下降。基线配置的性能并没有随着可用 CPU 资源的增多而进一步提升,尽管连接跟踪状态表大小发生了相应变化并且我们确认并没有发生因连接跟踪表记录达到上限而导致的性能降低。我们重复进行了多次相同的测试,结果仍然相同。当我们手动通过 -j NOTRACK 规则绕过 iptables 连接跟踪表时,问题立刻解决了,基线配置性能恢复到 200,000 连接每秒。所以很明显,一旦连接数超过某个阈值,iptables 连接跟踪表就会开始出现问题。
注意:在这个测试中,Calico eBPF 数据路径的测试结果一直不是很稳定。我们目前还不清楚原因。网络数据包的传输也不是很稳定。我们没有将测试结果纳入考虑,因为测试结果不一定准确。我们邀请 Calico 团队和我们一起研究这个问题并重新进行测试。
鉴于我们使用的是未经修改的标准应用程序来处理请求和传输信息,每秒处理 200,000 连接是一个非常优秀的成绩。不过,我们还是看一下 CPU 的消耗。
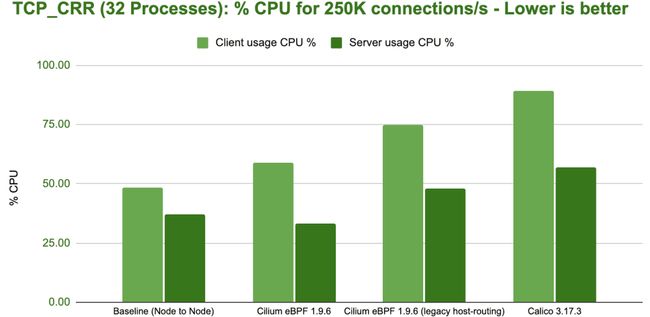
bench tcp crr 32 processes cpu
这个基准测试结果显示了不同配置的最大性能差异。为了达到每秒处理 250,000 新连接的目标,整个系统必须消耗 33% 到 90% 的可用资源。
由于发送端 CPU 资源消耗一直高于接收端,我们可以确信相同资源下每秒能接收的连接数要大于每秒能发起的连接数。
WireGuard 与 IPsec 加密开销对比
![]()
可能所有人都会认为 WireGuard 的性能会优于 IPsec,所以我们先测试 WireGuard 在不同的最大传输单元(MTU)下的性能。
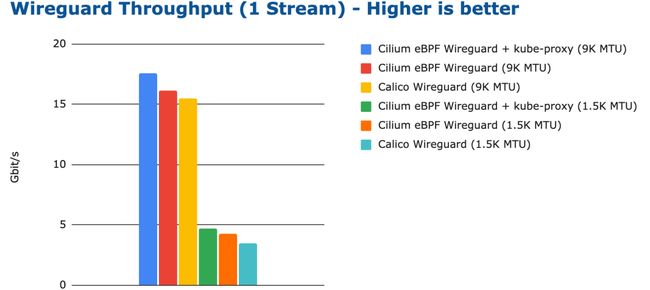
bench wireguard tcp 1 stream
不同的配置之间有一些差异。值得注意的是,Cilium 与 kube-proxy 的组合比单独 Cilium 的性能更好。然而,这个性能差异相对较小并且基本可以通过优化 MTU 弥补。
以下是 CPU 资源的消耗:
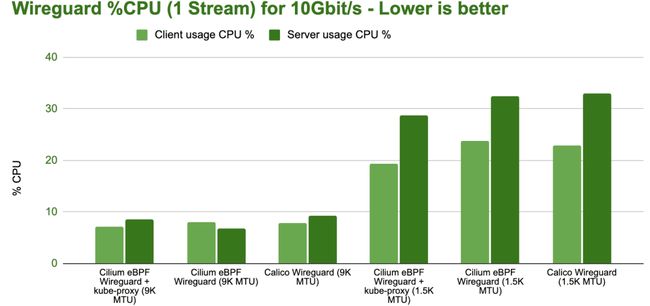
bench wireguard tcp 1 stream cpu
上述结果表明在 MTU 相同的情况下,不同配置之间的 CPU 使用率差异很小,因而可以通过优化 MTU 配置获得最佳性能。我们还对每秒请求数进行了测试,得到的结果也相同。感兴趣的读者可以参阅 Cilium 文档的 CNI 性能基准测试[2]章节。
WireGuard 与 IPsec 对比
对 Wireguard 和 IPsec 的性能进行比较更加有趣。Cilium 支持 IPsec 已经有一段时间了。从 1.10 开始,Cilium 也开始支持 WireGuard。在其他方面相同的情况下,把这两个加密方案放在一起进行对比,结果一定会非常有趣。
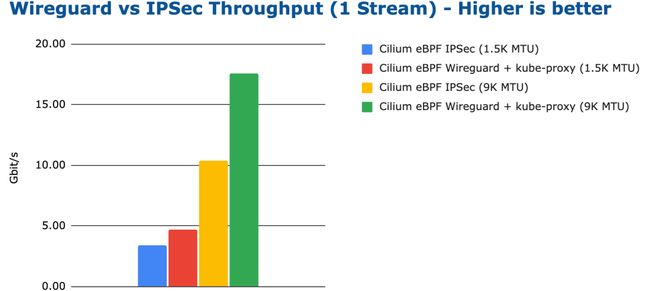
bench wireguard ipsec tcp stream 1 stream
不出所料,WireGuard 的吞吐量更高,并且在两种 MTU 配置下,WireGuard 的最大传输速率更高。
下面继续测试当吞吐量达到 10 Gbit/s 时,WireGuard 和 IPsec 在不同的 MTU 配置下的 CPU 使用率。
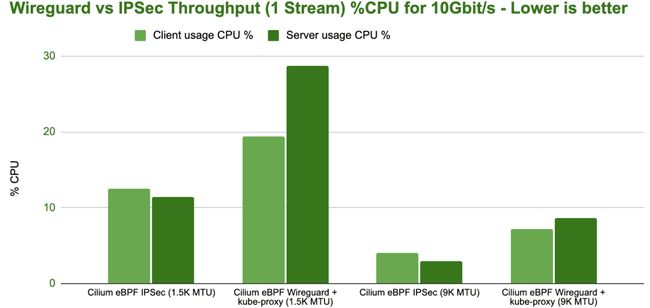
bench wireguard ipsec tcp stream 1 stream cpu
虽然 WireGuard 的最大吞吐量更高,但 IPsec 在吞吐量相同的情况下 CPU 开销更小从而更有效率,这个差异非常巨大。
注意:为了实现 IPsec 的高效率,需要使用支持 AES-NI 指令集的硬件来卸载 IPsec 的加密工作。
后续计划:目前我们还不清楚为什么 IPsec 的高效率没有带来更高的吞吐量。使用更多的 CPU 核心也没有明显提升性能。这很可能是由于 RSS 不能很好地跨 CPU 核心处理加密流量,因为通常用于哈希和跨 CPU 核心分配流量的 L4 信息是加密的,无法解析。因此,从哈希的角度来看,所有的连接都是一样的,因为在测试中只利用了两个 IP 地址。
这是否会影响延迟?让我进一步研究。延迟基准测试最能准确地描述微服务工作负载的实际状况,微服务工作负载通常都会使用持久连接来交换请求和响应。
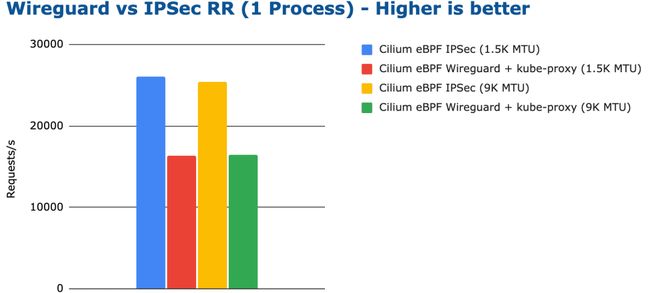
bench wireguard ipsec tcp rr 1 process
CPU 效率与观察到的每秒请求数相符。然而,每个配置总共消耗的 CPU 资源都不是很高。相比 CPU 消耗方面的差异,延迟方面的差异更为显著。
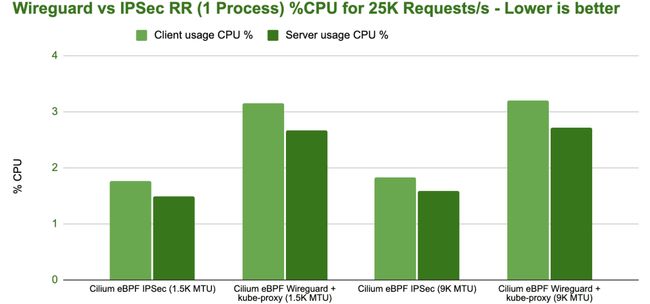
bench wireguard ipsec tcp rr 1 process cpu
测试环境
![]()
以下是我们使用的裸机配置。我们搭建了两套完全一样的互相直连的系统。
CPU:AMD Ryzen 9 3950X,AM4 平台,3.5 GHz,16 核 32 线程
主板:X570 Aorus Master,支持 PCIe 4.0 x16
内存:HyperX Fury DDR4-3200 128 GB,XMP 频率 3.2 GHz
网卡:Intel E810-CQDA2,双端口,每端口速率 100 Gbit/s,PCIe 4.0 x16
操作系统内核:Linux 5.10 LTS(配置为 CONFIG_PREEMPT_NONE)
除非特别说明,所有测试都使用了标准的 1500 字节 MTU。虽然 MTU 的值越高,测试结果的绝对数值会越好,但本文的基准测试的目的在于比较相对差异,而不是测试最高或最低性能的绝对数值。
测试配置
应广大用户的要求,我们展示了 Calico 的测试结果以便进行对比。为了尽可能清晰地进行对比,我们使用了以下配置类型进行测试:
基线配置(节点到节点):此配置不使用 Kubernetes 或容器,在基准测试过程中直接在祼机上运行 netperf。通常情况下此配置的性能最优。
Cilium eBPF:Cilium 版本为 1.9.6 并按照调优指南[3]进行了调优,开启了 eBPF 主机路由和 kube-proxy 替换。此配置需要操作系统内核版本为 5.10 或以上。此配置与 Calico eBPF 配置对比最具有参照性。我们重点进行了直接路由模式的基准测试,因为这种模式下性能通常尤为重要。后续我们也会进一步进行隧道模式的相关基准测试。
Cilium eBPF(传统主机路由):Cilium 版本为 1.9.6,以传统主机路由的模式运行,使用标准 kube-proxy,支持 4.9 及以下内核版本。此配置与 Calico 配置对比最具有参照性。
Calico eBPF:Calico 版本为 3.17.3,同时使用了开启 kube-proxy 替换、连接跟踪绕过以及 eBPF FIB 查询的 eBPF 数据路径。此配置需要操作系统内核版本为 5.3 或以上。此配置与 Cilium eBPF 配置对比最具有参照性。
Calico:Calico 版本为 3.17.3,使用标准 kube-proxy,支持较低版本的操作系统内核。此配置与 Cilium eBPF(传统主机路由)配置对比最具有参照性。
复现测试结果
测试所用的全部脚本都已经上传到 GitHub 仓库 cilium/cilium-perf-networking[4] 中,可用于复现测试结果。
下一步
![]()
我们在性能调优方面已经取得了不少结果,但我们还有许多其他的想法并将进一步优化 Cilium 各方面的性能。
可观测性基准测试:单纯的网络基准测试是必要的,但是实现可观测性所需资源的消耗才是真正区分系统高下的领域。无论是对系统安全还是对故障排除来说,可观测性都是基础设施的关键特性,并且不同系统的可视化资源消耗有很大不同。eBPF 是实现可观测性的优秀工具,并且 Cilium 的 Hubble[5] 组件也可以从中受益。在本文的基准测试中,我们禁用了 Hubble 以便测试结果可以与 Calico 对比。在后续的文章中,我们将对 Hubble 进行基准测试,以验证 Hubble 的 CPU 需求并将 Hubble 与其他类似的系统对比。
Service 和 NetworkPolicy 基准测试:当前的基准测试结果并不涉及任何 Service 和 NetworkPolicy。我们没有对二者进行测试以控制本文的内容范围。我们将进一步对使用 NetworkPolicy 的用例进行测试,除此之外还将对东西向(east-west)和南北向(north-south)的 Service 进行测试。如果您已经等不及了,Cilium 1.8 的发布博客[6]已经公布了一些基准测试结果,并且展示了 XDP 和 eBPF 对性能的显着提升。
目前,我们仍然对 NetworkPolicy 在 CIDR 规则方面的性能不太满意。我们当前的架构针对少量复杂的 CIDR 进行了优化,但并没有覆盖使用 LPM 来实现的一些特例。一些用户可能希望对单独 IP 地址的大型放行和阻止列表进行基准测试。我们会把这个用例放在优先事项中,并且提供基于哈希表的实现。
内存优化:我们将继续优化 Cilium 的内存占用。Cilium 主要的内存占用来自于 eBPF 的 Map 分配。这些是网络处理所需要的内核级数据结构。为了提高效率,eBPF Map 的大小是预先设定的,以便根据配置所需的内存量最小。我们目前对这方面并不是很满意,这将是我们后续版本的重点工作。
打破更多的规则:更多地绕过 iptables:我们认为 iptables 应该完全绕过。容器命名空间和系统其他部分仍有优化潜力。我们还会继续努力加快服务网格的数据路径应用程序。目前已经有一个利用 Envoy 的 Socket 层重定向的初步版本。请期待这个方面的进展。
想法和建议:如果您有其他想法和建议,请告诉我们。例如,您希望我们进行哪些基准测试或改进?我们非常希望能得到反馈意见。您可以在 Cilium Slack[7] 发表想法或者通过 Twitter[8] 联系我们。
更多信息
![]()
本文的所有结果数据都可以在 Cilium 文档的 CNI 性能基准测试[9]章节查阅。我们会持续更新这些数据。
调优指南[10]提供了对 Cilium 进行调优的完整教程。
有关 Cilium 的更多信息,请参阅 Cilium 官方文档[11]。
有关 eBPF 的更多信息,请访问 eBPF 官方网站[12]。
相关链接:
https://docs.cilium.io/en/latest/operations/performance/tuning/#ebpf-host-routing
https://docs.cilium.io/en/latest/operations/performance/benchmark/
https://docs.cilium.io/en/latest/operations/performance/tuning/
https://github.com/cilium/cilium-perf-networking
https://docs.cilium.io/en/latest/gettingstarted/hubble_setup/
https://cilium.io/blog/2020/06/22/cilium-18#kubeproxy-removal
https://cilium.io/slack
https://twitter.com/ciliumproject
https://docs.cilium.io/en/latest/operations/performance/benchmark/
https://docs.cilium.io/en/latest/operations/performance/tuning/
https://docs.cilium.io/en/latest/intro/
https://ebpf.io/
文章来源:KubeSphere云原生,点击查看原文。
Kubernetes线下培训
![]()
本次培训在上海开班,基于最新考纲,通过线下授课、考题解读、模拟演练等方式,帮助学员快速掌握Kubernetes的理论知识和专业技能,并针对考试做特别强化训练,让学员能从容面对CKA认证考试,使学员既能掌握Kubernetes相关知识,又能通过CKA认证考试,学员可多次参加培训,直到通过认证。点击下方图片或者阅读原文链接查看详情。
