Prometheus监控
用Zabbix监控底层设备,用Prometheus监控容器。
Prometheus监控官网地址
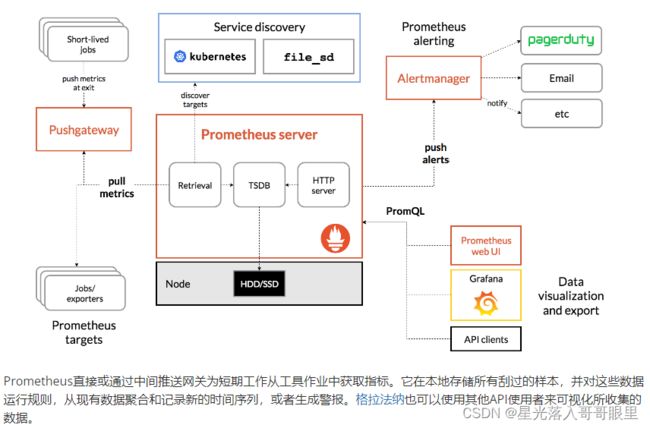
Prometheus架构图
分为客户端Agent和Server端。agent端推送数据给服务器。
一、Grafana介绍
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。
它主要有以下六大特点:
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
6、过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
二、Prometheus组件
普罗米修斯是一个开源系统监视和警报工具包,包含一整套数据的搜索\存储\处理\可视化功能。使用http接口来传输数据(通常搭配cAdvisor使用)。
1.Server 负责从exporters拉取监控数据,提供一套非常灵活的查询语言
2.exporters 负责收集目标对象的性能数据(内存、CPU、硬盘),主动提交给Server端
3.Grafana 可视化数据组件
4.Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给server。当server来pull时,直接返回实时状态的 metrics。
5.Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
6.Alertmanager: 从server端接收到警报后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。
常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
三、prometheus运行流程
prometheus根据配置定时去拉取各个节点的数据,默认使用的拉取方式是pull,也可以使用pushgateway提供的push方式获取各个监控节点的数据。将获取到的数据存入TSDB(一款时序型数据库)。此时prometheus已经获取到了监控数据,可以使用内置的PromQL进行查询。它的报警功能使用Alertmanager提供(Alertmanager是prometheus的告警管理和发送报警的一个组件)。prometheus原生的图标功能过于简单,可将prometheus数据接入grafana,由grafana进行统一管理。
从上面架构图也可以看出 Prometheus 的主要模块包含, Server, Exporters, Pushgateway, PromQL, Alertmanager, WebUI 等。
它大致使用逻辑是这样:
1.Prometheus server 定期从静态配置的 targets 或者服务发现的 targets 拉取数据。
2.当新拉取的数据大于配置内存缓存区的时候,Prometheus 会将数据持久化到磁盘(如果使用 remote storage 将持久化到云端)。
3.Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager。
4.Alertmanager 收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告。
5.可以使用 API, Prometheus Console 或者 Grafana 查询和聚合数据。
四、优点
✔ 强大的多维度数据模型:
时间序列数据通过 metric 名和键值对来区分。
所有的 metrics 都可以设置任意的多维标签。
数据模型更随意,不需要刻意设置为以点分隔的字符串。
可以对数据模型进行聚合,切割和切片操作。
支持双精度浮点类型,标签可以设为全 unicode。
只需定义一个全局指标,通过维度来增加监控的标准。
✔ 灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。
✔ 易于管理: Prometheus server是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
✔ 高效: 平均每个采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
✔ 使用 pull 模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。
✔ 可以采用 push gateway 的方式把时间序列数据推送至 Prometheus server 端。
✔ 可以通过服务发现或者静态配置去获取监控的 targets。
✔ 有多种可视化图形界面。
✔ 易于伸缩。
五、应用范围
适用于什么场景
Prometheus 适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。Prometheus 是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
不适合什么场景
Prometheus 非常重视可靠性,即使在出现故障的情况下,你也可以随时查看有关系统的可用统计信息。如果你需要百分之百的准确度,例如按请求数量计费,那么 Prometheus 不太适合你,因为它收集的数据可能不够详细完整。这种情况下,你最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 来监控系统的其余部分。
六、node_exporter
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从exporter暴露的HTTP服务地址
Exporter是Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。
从上面的描述中可以看出exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接内置在监控目标中。只要能够向Prometheus提供标准格式的监控样本数据(TS时间序列)即可。这里为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。
七、安装部署
Server1:192.168.235.10
Server2:192.168.235.20
1.基础环境
hostnamectl set-hostname server1
iptables -F
iptables-save
docker run -itd --name sys1 centos:7
docker run -itd --name web1 httpd
hostnamectl set-hostname server2
iptables -F
iptables-save
docker run -itd --name sys2 centos:7
docker run -itd --name web2 httpd
两台都做(采集硬件信息):
docker pull prom/node-exporter
docker run -d -p 9100:9100 --volume /proc/:/host/proc --volume /sys/:/host/sys --volume /:/rootfs --network host --name=exporter prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/devicemapper|rootfs/var/lib/docker/aufs)($$|/)"
WARNING: 使用主机网络模式时,发布的端口将被丢弃
[root@server1 ~]# docker ps #运行起来表示成功(不清空iptables将访问不到9100端口)
运行监控容器的监控端(都做)采集容器数据:
docker pull google/cadvisor
sudo docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--network host \
google/cadvisor
验证:http://192.168.235.10:8080/metrics
2.服务端部署普罗米修斯(配置Prometheus来监视自身)
[root@server1 ~]# docker pull prom/prometheus
[root@server1 ~]# vi prometheus.yml (地址:https://prometheus.io/docs/prometheus/latest/getting_started/)
global:
scrape_interval: 15s # 默认情况下,每15秒刮一次目标。
# 将这些标签贴在任何时间序列或警报上
# 外部系统 (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
# 这是普罗米修斯.
scrape_configs: #数据采集模块
# The job name is added as a label `job=` to any 时间序列 scraped from this config.
- job_name: 'prometheus' #对于指标需要打上的标签,对于PrometheusSQL(查询语句)的标签:比如prometheus{target='values'}
# 重写全局默认值并每5秒从该作业中抓取目标.
scrape_interval: 5s
static_configs: #对于 Prometheus 的静态配置监听端口具体数据收集的位置 默认的端口 9090
- targets: ['192.168.235.10:9090','192.168.235.10:9100','192.168.235.10:8080','192.168.235.11:9100','192.168.235.11:8080']
[root@server1 ~]# docker run -d -p 9090:9090 --volume /root/prometheus.yml:/etc/prometheus/prometheus.yml --name prometheus --network host prom/prometheus
3.安装图形化界面(在创建容器的时候设置密码)
docker pull grafana/grafana
docker run -i -d --name=grafana -p 3000:3000 -e "GF_SERVER_ROOT_URL=http://grafana.server.name" -e "GF_SECURITY_ADMIN_PASSWORD=123.com" --network host grafana/grafana
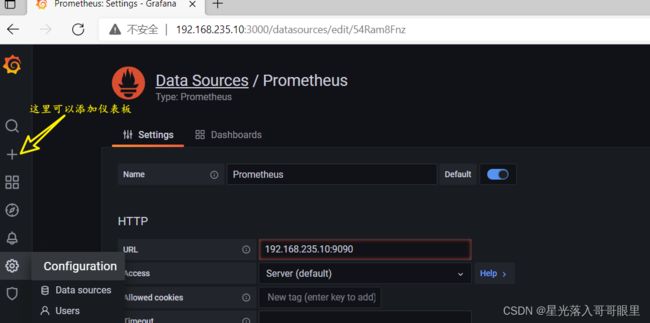
4.配置部署(使用Edge浏览器)
访问浏览器页面:192.168.235.10:3000–>默认用户为admin–>123.com–>DATA SOURCES–>Prometheus-如截图->Save && test=监测
使用QQ浏览器将访问不到界面; 具体操作可以自行探索
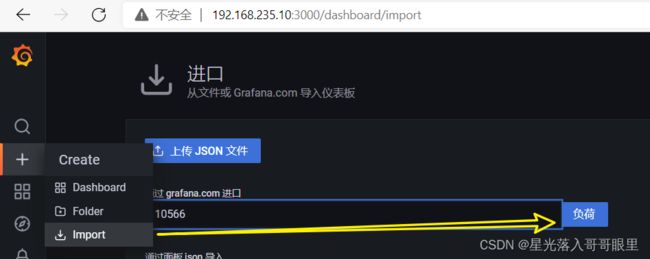
博主喜欢的仪表盘地址
不要放弃你的梦想,你终将会出人头地!积极、热爱、赤血