Oracle正则表达式匹配
Oracle从10g开始支持正则表达式
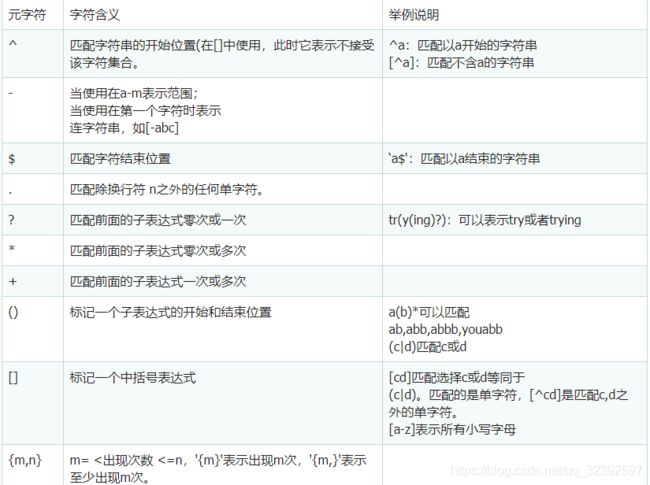
元字符(metacharacters)
POSIX 正则表达式由标准的元字符(metacharacters)所构成:
'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹
配 '\n' 或 '\r'。
'.' 匹配除换行符之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的
字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少
出现m次。
\num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
各种操作符的运算优先级
\转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
ORACLE中的支持正则表达式的函数如下:
REGEXP_LIKE:用POSIX 正则表达式替代百分号(%)和通配符(_)字符进行模糊匹配;REGEXP_INSTR(instr:返回一个字符串在另一字符串中的位置):返回正则表达式匹配的字符串在另一字符串中的位置;REGEXP_SUBSTRinstr:根据指定位置截取字符串):使用正则来指定返回字符串的起点和终点;REGEXP_REPLACE:替换字符串中的某个值,是REPLACE的增强版,支持正则表达式,扩展了一些功能;REGEXP_COUNT:返回在源串中出现的模式的次数,作为对REGEXP_INSTR函数
的补充。
1 . REGEXP_LIKE
regexp_like( source_string, pattern [match_parameter] )
- source_string:源字符串
- pattern :正则表达式
- match_parameter:匹配模式
i:不区分大小写;c:区分大小写;n:允许使用可以匹配任意字符串的操作符;m:将x作为一个包含多行的字符串。默认为’c’
例: 判断字符串是否以“201”或者“202”开头
SELECT 1 FROM DUAL WHERE REGEXP_LIKE('201','^201|202'); -- 结果为1
SELECT 1 FROM DUAL WHERE REGEXP_LIKE('200','^201|202'); -- 无结果
-- 也可以这么写
SELECT 1 FROM DUAL WHERE REGEXP_LIKE('202','^20[12]'); -- 结果为1
2. REGEXP_INSTR
3. REGEXP_SUBSTR
REGEXP_SUBSTR 函数使用正则表达式来指定返回串的起点和终点。
语法:
regexp_substr(source_string,pattern[,position[,occurrence[,match_parameter]]])
source_string:源串,可以是常量,也可以是某个值类型为串的列。
position:从源串开始搜索的位置。默认为1。
occurrence:指定源串中的第几次出现。默认值1.
match_parameter:文本量,进一步订制搜索,取值如下:
'i' 用于不区分大小写的匹配。
'c' 用于区分大小写的匹配。
'n' 允许将句点“.”作为通配符来匹配换行符。如果省略改参数,句点将不匹配换行符。
'm' 将源串视为多行。即将“^”和“$”分别看做源串中任意位置任意行的开始和结束,
而不是看作整个源串的开始或结束。如果省略该参数,源串将被看作一行来处理。
如果取值不属于上述中的某个,将会报错。如果指定了多个互相矛盾的值,将使用最后一个值。如'ic'会被当做'c'处理。
省略该参数时:默认区分大小写、句点不匹配换行符、源串被看作一行。
例: 将表中PROVINCE字段中以市,省,自治区开头的部分截取出来。
SELECT REGEXP_SUBSTR(PROVINCE,'.*?[市|省|自治区]+') FROM TABLE_NAME;
-- 结果为
湖南省
上海市
宁夏自治区
四川省自
----------有问题 四川省这里把“自"也匹配进来了
----------修改如下,把字符串用括号包起来保证不被作为单个字符,而是字符串匹配
SELECT REGEXP_SUBSTR(PROVINCE,'.*?([市]+|[省]+|[自治区]+)') FROM TABLE_NAME;
4. REGEXP_REPLACE
REPLACE 函数用于替换串中的某个值。
语法:
replace(char,search_string[,replace_string]) 如果不指定replace_string,会将搜索到的值删除。
REGEXP_REPLACE 是 REPLACE 的增强版,支持正则表达式,扩展了一些功能。
语法:
regexp_replace(source_string,pattern[,replace_string[,position[,occurrence[,match_parameter]]]])
例: 将表中NAME字段中间第二个字进行脱敏,改为 ”*“
SELECT REGEXP_REPLACE('王女士大幅回升','(.)','*',2,1) AS NAME
FROM DUAL ;
-- 表示从第2个字符开始,取任意1个字符,替换为*;;
-- 结果为
王*士大幅回升
参考:
Oracle正则表达式使用介绍
Oracle中的正则表达式(及函数)详解