Class.getResource()、ClassLoader.getResource()源码解读
Class.getResource()、ClassLoader.getResource()源码解读
Java中取资源时,经常用到Class.getResource和ClassLoader.getResource,对于其参数中的路径填写,有时候往往犯糊涂,比如什么时候该加反斜杠/,什么时候不改加。本次将从源码层面带大家解读这两种方式在加载文件时的区别,以及反斜杠/的使用原理。
首先先说结论:
-
ClassLoader.getResource()
- 以反斜杠/开头时:会将参数路径视为绝对路径来读取,导致该绝对路径不以classPath为前缀,会直接返回null。因此,采用这种方式时,不能以反斜杠/开头。
- 不以反斜杠/开头时:将参数路径当作相对路径来读取,该相对路径会拼接上ClassPath根路径(…/target/classes/)得到最终的绝对路径。此种方式是从ClassPath根下获取
-
Class.getResource()
-
以反斜杠/开头时:将参数路径当作相对路径来读取,解析参数路径时会去掉/,然后当作相对路径来读取,该相对路径会拼接上ClassPath根路径(…/target/classes/)得到最终的绝对路径。此种方式与
ClassLoader.getResource方法相同。 -
不以反斜杠/开头时:该相对路径会拼接上当前类所在包的路径,再拼接上classPath路径,得到最终的绝对路径。此种方式,检索的是当前类所在包下的文件路径。
-
接下来通过源码分析来进一步一探究竟。
ClassLoader.getResource()源码剖析
这里由于涉及到Java类加载器相关的知识,可以参考
[一文读懂JVM类加载机制过程及原理万字详解]
不了解的话实际上也不妨碍我们去关注本次对于路径解析源码的分析。
首先我们编写一个测试代码:
public class getClassLoaderResources {
public static void main(String[] args) throws IOException {
URL resource = getClassLoaderResources.class.getClassLoader().getResource("config/application-test2.properties");
Properties props = new Properties();
props.load(resource.openStream());
System.out.println(props.getProperty("key"));
URL resource1 = getClassLoaderResources.class.getResource("/config/application-test2.properties");
Properties props2 = new Properties();
props2.load(resource1.openStream());
System.out.println(props2.getProperty("key"));
}
}
在Maven项目的resouces目录下创建了两个文件:

首先在Debug模式进入到getResource方法里:
public URL getResource(String name) {
URL url;
if (parent != null) {
// 双亲委派机制的递归,先去父类加载器(扩展类加载器)查找资源,最后回到系统类加载器
url = parent.getResource(name);
} else {
url = getBootstrapResource(name);
}
if (url == null) {
url = findResource(name); // 在系统类加载器中调用findResource方法
}
return url;
}
这里getResources方法首先利用了双亲委派机制,测试代码中填写的路径先去父类加载器查询资源(扩展类加载器ExtClassLoader),没有找到后,最终会回到系统类加载器(AppClassLoader)进行检索。
接下来进入到findResource方法中,找到实际的实现类URLClassLoader中的findResource方法:
public URL findResource(final String name) {
/*
* The same restriction to finding classes applies to resources
*/
URL url = AccessController.doPrivileged(
new PrivilegedAction<URL>() {
public URL run() {
// 主要执行这条语句
return ucp.findResource(name, true);
}
}, acc);
return url != null ? ucp.checkURL(url) : null;
}
再进入ucp.findResource(name, true);
public URL findResource(String var1, boolean var2) {
int[] var4 = this.getLookupCache(var1);
URLClassPath.Loader var3;
for(int var5 = 0; (var3 = this.getNextLoader(var4, var5)) != null; ++var5) {
URL var6 = var3.findResource(var1, var2);
if (var6 != null) {
return var6;
}
}
return null;
}
这里便是执行查找资源的核心逻辑。首先for循环用来遍历系统类加载器中包含的加载器(有两种JarLoader、FileLoader),这些加载器被指定在java.class.path路径里。var3.findResource表示针对每个加载器去尝试检索目标路径,如果能检索到则返回,否则,继续尝试下一个加载器来检索。
接下来进入到getNextLoader方法中,这里用Debug模式下的截图来表示
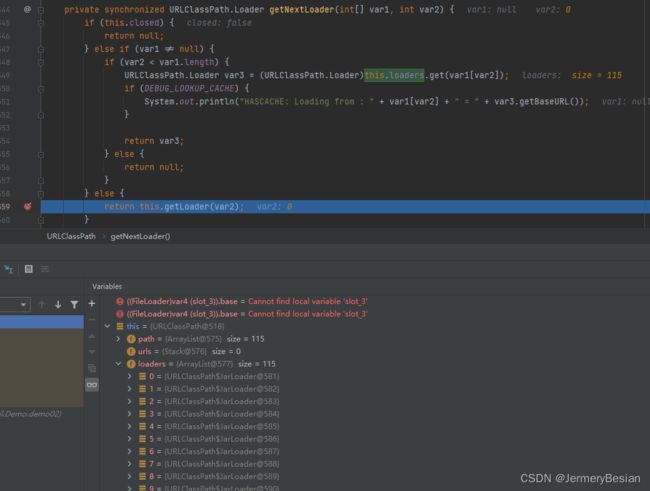
可以看到,这里this.loaders包含了115中加载器,这里我们翻阅可以找到一个FileLoader,打开发现这里的路径就是我们这个项目的classPath路径。因此实际上,本次测试我们填写的目标路径就是在这个加载器中才能找到的。
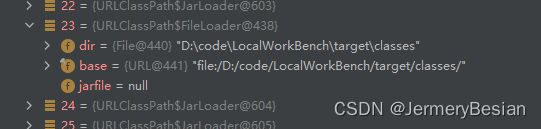
因此,当上面的var5=23时,会进入到var3.findResource中查找目标路径。由于这里的Loader类型是FileLoader,所以实际分析时需要进入到实现类FileLoader中:
URL findResource(String var1, boolean var2) {
Resource var3 = this.getResource(var1, var2);
return var3 != null ? var3.getURL() : null;
}
Resource getResource(final String var1, boolean var2) {
try {
// var4构建base路径,也就是上面图片中的项目classPath路径
URL var4 = new URL(this.getBaseURL(), ".");
// 根据传入的参数,构建参数路径
final URL var3 = new URL(this.getBaseURL(), ParseUtil.encodePath(var1, false));
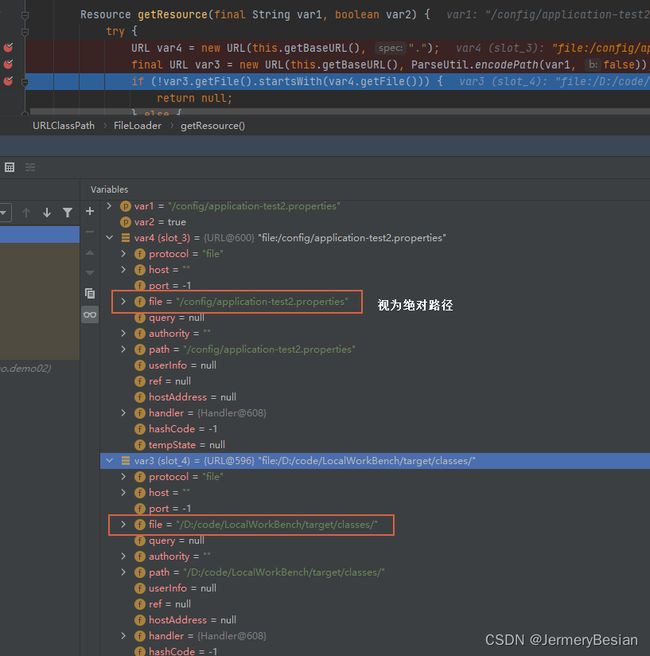
// 这里就是为什么ClassLoader.getResources()参数里是不能加反斜杠/的原因了
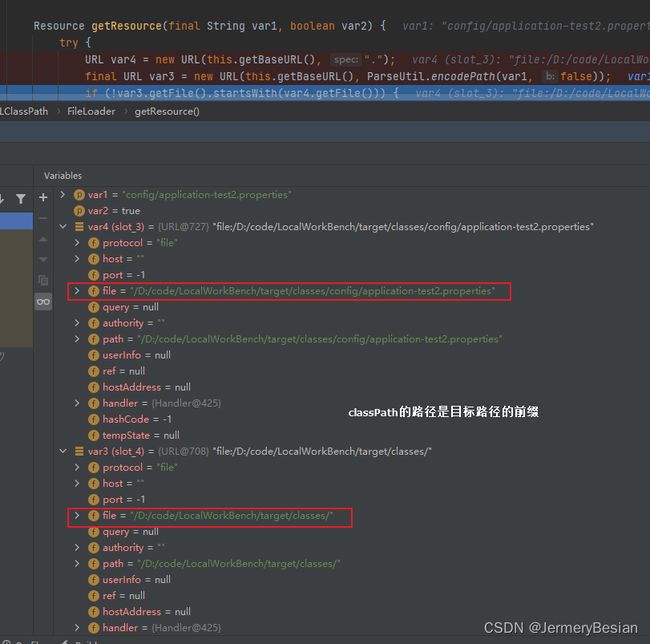
// 因为如果加了反斜杠,那么传入的参数被认为是绝对路径,var3中的file直接被赋值为传入的参数,导致var3.file的前缀与ClassPath路径不同
// 如果没加反斜杠,那么传入的参数被认为是相对路径,var3中的file是ClassPath路径拼接上传入参数,因此var3.file的前缀与ClassPath路径一定是相同的。
if (!var3.getFile().startsWith(var4.getFile())) {
return null;
} else {
if (var2) {
URLClassPath.check(var3);
}
final File var5;
if (var1.indexOf("..") != -1) {
var5 = (new File(this.dir, var1.replace('/', File.separatorChar))).getCanonicalFile();
if (!var5.getPath().startsWith(this.dir.getPath())) {
return null;
}
} else {
// 构建File文件对象
var5 = new File(this.dir, var1.replace('/', File.separatorChar));
}
// 利用File文件对象来判断目标路径的文件是否存在,如果存在,则封装成一个Resource对象,否则,返回null
return var5.exists() ? new Resource() {
public String getName() {
return var1;
}
public URL getURL() {
return var3;
}
public URL getCodeSourceURL() {
return FileLoader.this.getBaseURL();
}
public InputStream getInputStream() throws IOException {
return new FileInputStream(var5);
}
public int getContentLength() throws IOException {
return (int)var5.length();
}
} : null;
}
} catch (Exception var6) {
return null;
}
}
}
对于上面代码中的注释,下面用Debug上的截图来对可视化一下就很明了了:
不加反斜杠的情况:
添加反斜杠的情况:
目前我们发现了ClassLoader.getResouce中,为什么不能加反斜杠,以及对于目前路径文件是否存在的判断源码。但是,我们还没有发现对传入路径参数的处理原理,以及上面源码中var3.file是怎么来的。这些疑问最后进入到new URL的构造方法中,就能清晰明了了。
public URL(URL context, String spec) throws MalformedURLException {
this(context, spec, null);
}
public URL(URL context, String spec, URLStreamHandler handler)
throws MalformedURLException
{
String original = spec;
int i, limit, c;
int start = 0;
String newProtocol = null;
boolean aRef=false;
boolean isRelative = false;
// Check for permission to specify a handler
if (handler != null) {
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
checkSpecifyHandler(sm);
}
}
try {
// 其它代码省略
...
// 实际上最重要是这里,从名字也可以看出,这里是解析URL的地方
handler.parseURL(this, spec, start, limit);
} catch(MalformedURLException e) {
throw e;
} catch(Exception e) {
MalformedURLException exception = new MalformedURLException(e.getMessage());
exception.initCause(e);
throw exception;
}
}
再次进入到handler.parseURL(this, spec, start, limit);
protected void parseURL(URL u, String spec, int start, int limit) {
// These fields may receive context content if this was relative URL
String protocol = u.getProtocol();
String authority = u.getAuthority();
String userInfo = u.getUserInfo();
String host = u.getHost();
int port = u.getPort();
String path = u.getPath();
String query = u.getQuery();
// This field has already been parsed
String ref = u.getRef();
boolean isRelPath = false;
boolean queryOnly = false;
// FIX: should not assume query if opaque
// Strip off the query part
if (start < limit) {
int queryStart = spec.indexOf('?');
queryOnly = queryStart == start;
if ((queryStart != -1) && (queryStart < limit)) {
query = spec.substring(queryStart+1, limit);
if (limit > queryStart)
limit = queryStart;
spec = spec.substring(0, queryStart);
}
}
// 其它代码省略
...
// Parse the file path if any
// 核心对传入路径的解析就在这里了
if (start < limit) {
// 如果传入的参数spec以反斜杠/开头,则path直接等于spec,将当于将传入参数视为绝对路径赋给path
if (spec.charAt(start) == '/') {
path = spec.substring(start, limit);
// 如果不以反斜杠/开头
} else if (path != null && path.length() > 0) {
isRelPath = true;
// 找到最后一个反斜杠/的索引值
int ind = path.lastIndexOf('/');
String seperator = "";
if (ind == -1 && authority != null)
seperator = "/";
// path=classPath的路径+/+传入参数
// 也就是将传入参数作为相对路径拼接上classPath得到最终的绝对路径
path = path.substring(0, ind + 1) + seperator +
spec.substring(start, limit);
} else {
String seperator = (authority != null) ? "/" : "";
path = seperator + spec.substring(start, limit);
}
} else if (queryOnly && path != null) {
int ind = path.lastIndexOf('/');
if (ind < 0)
ind = 0;
path = path.substring(0, ind) + "/";
}
// 其它代码省略
...
// URL对象的属性赋值
setURL(u, protocol, host, port, authority, userInfo, path, query, ref);
}
看起来代码很长,但是本次我们的分析实际上需要关注的代码其实就是上面添加了注释的代码。URL对传入参数spec的核心解析逻辑,就是// Parse the file path if any注释下的代码。
这里的代码逻辑就对应了我们上面说的
- 如果spec加了反斜杠/,则直接视为绝对路径赋值给path
- 如果spec没加反斜杠/,则视为相对路径,会在前面拼接上classPath的路径再赋值给path
到这里,我们基本上就从源码的角度,完整分析了一遍ClassLoader.getResource方法,在解析传入的路径参数时的要求,以及这些要求背后的原理,理解了这些才能不是靠死记硬背来记得。我也觉得同样对这些问题有疑惑的同学可以跟着Debug走一遍源码来加深理解和一项。
Class.getResource
在了解清楚ClassLoader.getResource的原理后,Class.getResource的解析路径原理就更容易理解了,因此它是基于ClassLoader的方法来处理的。
首先还是进入到getResource方法中:
public java.net.URL getResource(String name) {
// 解析传入的参数
name = resolveName(name);
// 这里仍然是获取类加载器
ClassLoader cl = getClassLoader0();
if (cl==null) {
// A system class.
return ClassLoader.getSystemResource(name);
}
//
return cl.getResource(name);
}
这里的resolveName方法就是实际的对传入路径参数进行处理的方法:
private String resolveName(String name) {
if (name == null) {
return name;
}
// 如果传入的参数不以反斜杠/开头
if (!name.startsWith("/")) {
Class<?> c = this;
while (c.isArray()) {
c = c.getComponentType();
}
// 获取到当前类所在的路径,也就是包名下的路径
String baseName = c.getName();
int index = baseName.lastIndexOf('.');
if (index != -1) {
// 包名+传入参数
// 相当于将传入参数作为相对路径,与包名进行拼接后得到绝对路径。
// 只是这里拼接的是包名所在的路径,ClassLoader那里拼接的是classPath路径
name = baseName.substring(0, index).replace('.', '/')
+"/"+name;
}
} else {
// 如果以反斜杠/开头,则去除反斜杠,就返回了
name = name.substring(1);
}
return name;
}
Debug模式下,以反斜杠/开头的话, 得到的name如下图所示:
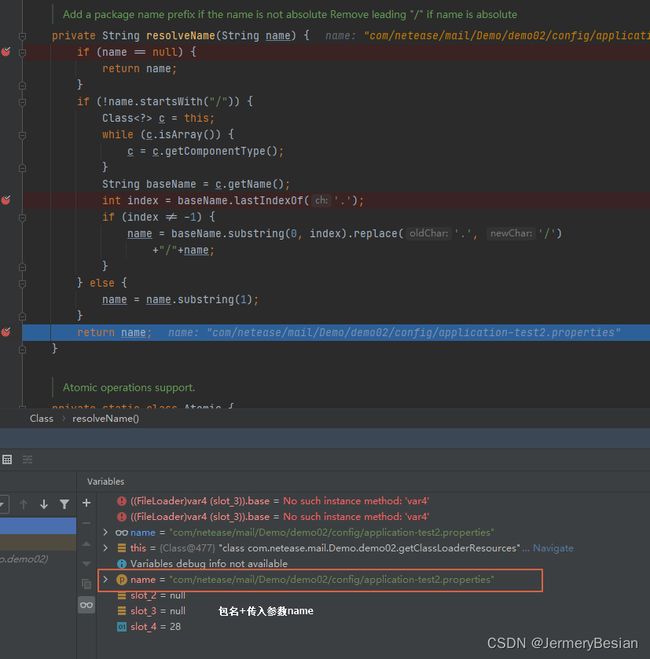
然后接下来cl.getResource(name)就又回到了我们熟悉的ClassLoader.getResource方法里的,后面的流程就跟我们上面第一部分的分析完全一致了。
同时,这里我们可以发现,Class.getResource方法里,传入的参数无论是否加了反斜杠/,在传入ClassLoader.getResource方法中时,都是不以反斜杠/开头的。因此,对于Class.getResource方法,是否以反斜杠/开头的区别在于:
- 以反斜杠/开头,则实际解析时会直接把反斜杠去掉,然后作为相对路径,传入
ClassLoader.getResource方法里,拼接上classPath的路径得到最终的绝对路径。 - 不以反斜杠/开头,则实际解析时会拼接上所在类的包路径,然后作为相对路径,传入
ClassLoader.getResource方法里,拼接上classPath的路径得到绝对路径。
案例测试
测试代码:
public class getClassLoaderResources {
public static void main(String[] args) throws IOException {
URL resource = getClassLoaderResources.class.getClassLoader().getResource("config/application-test2.properties");
Properties props = new Properties();
props.load(resource.openStream());
System.out.println("ClassLoader.getResource读取根目录下的文件: " + props.getProperty("key"));
URL resource1 = getClassLoaderResources.class.getResource("/config/application-test2.properties");
Properties props2 = new Properties();
props2.load(resource1.openStream());
System.out.println("Class.getResource读取根目录下的文件: " + props2.getProperty("key"));
URL resource2 = getClassLoaderResources.class.getResource("application-test3.properties");
Properties props3 = new Properties();
props3.load(resource2.openStream());
System.out.println("Class.getResource读取包目录下的文件: " + props3.getProperty("key"));
}
}
项目目录:
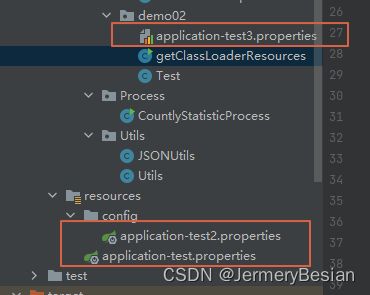
输出结果:
ClassLoader.getResource读取根目录下的文件: application-test2.properties
Class.getResource读取根目录下的文件: application-test2.properties
Class.getResource读取包目录下的文件: application-test3.properties