Meta Talk: Learning To Data-Efficiently Generate Audio-Driven Lip-Synchronized Talking 论文解读
1. 相关链接
中文介绍链接:
语音语义创新Lab_News_聚焦虚拟说话人生成技术,华为云论文被人工智能语音领域顶级会议ICASSP2022接收
论文链接:
Meta Talk: Learning To Data-Efficiently Generate Audio-Driven Lip-Synchronized Talking Face With High Definition | IEEE Conference Publication | IEEE Xplore
2. 简介
语音驱动虚拟说话人模型,旨在生成与输入语音能够口型匹配的任意目标人像虚拟说话人视频。目前业界开发出了一些先进的虚拟说话人生成模型,包括语音驱动的3D虚拟人视频生成模型(AudioDVP) 和2D语音-口型生成模型(Wav2lip)。华为研究团队经过多次实验,发现AudioDVP仅有在数十小时大量训练数据下才能具有良好唇音同步效果,对应目标人物模特的训练数据录制成本太高,一旦有更换模特的需求,则需要大量的人力物力来做重新准备。另外,Wav2lip虽然在超过30小时的视频数据下构建了预训练模型,具有较好的泛化能力,但是生成的视频清晰度较低,无法满足应用需求。
基于这些观察,如下图所示,作者提出了一种新的虚拟说话人的生成方法Meta Talk,融合了AudioDVP和Wav2lip各自的优点,通过自适应裁剪模块、3D人脸模型重建和渲染等模块相互配合,突破了仅需3分钟的原始视频,即可实现生成唇形同步的4K清晰度且达到真实照片逼真程度的虚拟说话人视频的技术。
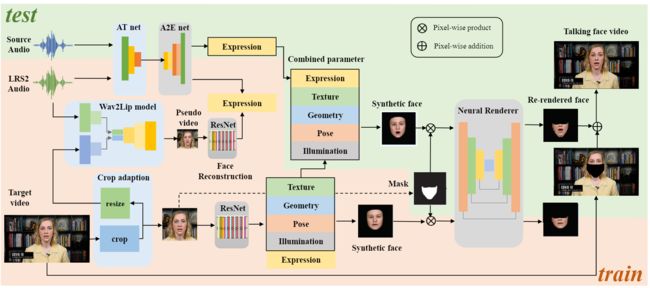
3. 模型原理
1. 训练阶段
(1) 使用AudioDVP中的3D重建模块,训练3D人脸重建模型,待训练完毕后,将其作为模块使用,可以从人脸图像中获取表情系数参数。
(2) 使用Wav2Lip与训练好的3D重建模块,制作A2E训练标签对,训练A2E模型
(3) 使用3D重建模型预测3DMM参数,对原始训练视频进行预测,并通过3D顶点渲染得到3D人脸面具,使用人脸Mask,得到3D半脸面具(脸颊下部分)
(4) 使用3D半脸面具作为输入,原始视频人脸下半脸颊部分(Mask遮罩区域)作为输出,训练Nerual Renderer模型(类似于Pixel2Pixel网络)
2. 测试阶段
(1) 输入测试Audio通过A2E模型得到3DMM expression系数
(2) 输入原始训练视频,通过3D重建模型得到纹理、形状、光照、姿态等3DMM系数
(3) 合并(1)(2)系数,经过3D顶点渲染得到3D人脸面具,并且通过Mask遮罩仅使用人脸面具的脸颊部分
(4) 使用Neural Renderer网络将3D半脸面具转化为真实的人脸下半部分,并且根据Mask形式贴合到原始训练视频
4. 个人解读
4.1 优点
1. 对训练的视频时长及要求可以进一步降低
在这里训练视频仅仅起到了训练3D重建模型及3DFace-->realFace模型的作用,Audio2Expression模型的数据是由LRS2提供的。论文中提及仅需要3分钟训练视频即可有比较好的表现效果。
2. 使用Wav2Lip优化音画同步效果
作者认为,Wav2Lip具有比较好的音画同步效果,因此使用它生成低清真实人脸,再使用3D人脸重建模块获取的Expression也与Audio具有比较好的同步效果,作者将它们作为标签对,训练A2E模型。在消融实验中,论文中也展示了wav2lip获取伪标签的方式,对音画同步的提升效果。
4.2 存在问题
1. 训练步骤繁琐
针对每一个不同人,论文都需要重新训练人脸3D重建模型,都需要使用Wav2lip获取LRS2 Audio对应的Expression标签,然后重新训练A2E模块,再训练3Dface--->realFace(pixel2pixel),训练繁琐且都需要专人专训练。
2. 3D重建模型训练与低清图像质量不匹配
Wav2Lip生成图像尺寸为96x96,而AudioDVP中的3D重建模型输入尺寸为256x256,因此使用之获取wav2lip生成图像的expression时,需对之进行上采样与插值,不可避免引入模糊,存在重建expression的问题。这里后续可以考虑使用微软官方在大规模数据上训练的3D重建模型。
5. 参考
wav2lip_train | Kaggle
语音语义创新Lab_News_聚焦虚拟说话人生成技术,华为云论文被人工智能语音领域顶级会议ICASSP2022接收
[2008.10010] A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
Photorealistic Audio-driven Video Portraits | Christian Richardt