C10K问题与IO多路复用
epoll基本介绍
操作系统早期的IO都是阻塞式的,所以为了一个应用能够支持并发的IO操作,所以基本的做法就是每来一个IO请求,就创建一个线程来专门处理。当IO并发不大的情况,这中方式工作的很好
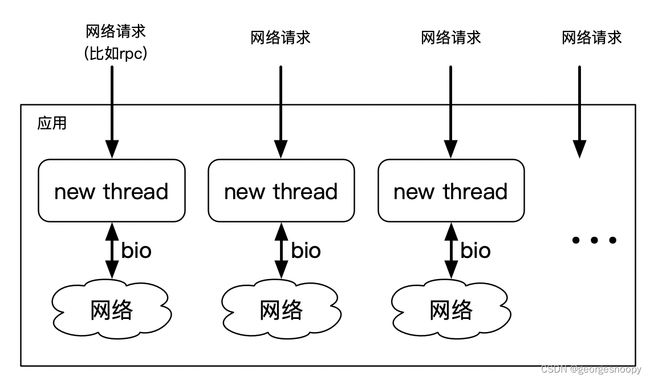
但随着IO并发越来越大,到了每秒需要支持1000的并发量的时候,那么就需要创建1000个线程来支持。随着线程越来越多,极大的超出了cpu的核心数,那么随之而来的就cpu调度成本增加、大量的上下文切换、以及线程的内存消耗等,这些都将成为并发量继续增加的瓶颈。
所以并发量很大的情况下,就不再适合用这种模型来处理。那么自然的想法就是:用一个线程去支持多个IO请求,所以后面的思路就是考虑如何用一个线程来同时处理多个IO请求的问题了:
- 肯定不能用原来的阻塞IO了。如果是使用阻塞IO,一旦调用IO,线程就挂起了,不可能再支持其他IO请求了。所以底层的IO方式需要变化,需要操作系统支持非阻塞式的IO。
- 一个线程如何去支持多个IO请求呢?线程发起IO请求后,因为是非阻塞式的IO,所以会立马返回,这个时候这个线程没有被阻塞,倒是可以去做别的事情,比如还可以继续响应其他IO请求,这就已经达到了一个线程可以处理多个IO请求的目的了。但是有个问题:当已经发起的IO请求就绪了,线程怎么感知到呢?
- 轮询:线程自己记录下已经发起的IO的fd,然后不断的去轮询(即继续调用如read()、write()这种io请求方法,如果IO就绪了read就绪(读缓冲区不为空),会返回具体读取到的内容、如果io没有就绪、那么返回的就是-1)。这其实就是多路复用的方式,所谓的多路是指多个IO、复用是指复用一个线程。
- 操作系统内核支持事件触发。线程发起IO请求后,实际上是注册了一个监听事件到操作系统内核、当IO就绪时,内核直接通过事件的方式来告诉线程。这个其实就是AIO方式
只要是有了操作系统非阻塞式IO的支持,应用系统使用轮询的方式,就完全可以实现一个线程支持多个IO请求的目的了。

这种多路复用的实现方式,其实整个的IO的fd是在用户空间来维护的,轮询也是依赖操作系统提供的非阻塞的read系统调用来实现:
- 轮询是使用操作系统提供的非阻塞IO的系统调用来实现,所以一次轮询都会有系统调用,而系统调用就会涉及到用户态到内核态、再从内核态到用户态的转换,这个过程是有成本的。
- 整个fd的集合是存储在用户空间的。而按照操作系统的设计,内核态是不会去访问用户态的内存空间的。所以每次系统调用都会将fd的数据copy到内核态。
要破这个局,那就只能操作系统提供能力来支持,而现在互联网的发展,大并发的IO已经是家常便饭了,所以这个IO多路复用也成了一个大众诉求了。所以linux在系统层面提供了IO多路复用的方案,那就是大家经常说的select/poll/epoll。
select和poll的实现思路和上图大致一样,无非就是从操作系统的角度提供了一个通用的IO复用能力,不用所有的上层应用都需要去实现一遍。select/poll维护fd都是使用的线性数据结果,只是说select使用的数组、poll使用的链表,所以poll相对来说就没有了fd数量的限制。但是他们都是没有就绪队列的,所以每次调用select()/poll()都是要扫一遍fd的列表,不管fd有没有就绪了。所以整体的扫描效率并不高。但总归是有了一个通用的IO复用能力,上层应用能够直接拿来使用的,而这种方式也基本上是解决了C10K的问题。
但随着互联网的崛起,用户量、数据量都暴增,对应的C100K、C1000K也逐步走进了现实中,在大并发免签,上面的这种IO多路复用方案,还是会限制并发量的。epoll隆重登场,从操作系统内核层面提供了IO多路复用机制,提高IO效率。
epoll的改进:
- 使用红黑树代替了数组/链表来存储注册进来的fd。从数据结构层面提升了fd的增删改查效率。
- 注册进来的fd是存储在内核空间的。轮询的时候不需要应用层将fd的数据copy传入。
- 增加了一个就绪队列。在轮询的时候,不是轮询所有注册上来的fd,而只是会去遍历就绪的fd。其实极大减少了无效访问,提搞了轮询效率。
- 因为有了就绪队列。其实从某种意义上,和上面的方案已经有了本质区别:上述的方案其实应用层不知道啥时候会有fd就绪,所以只要注册的fd不为空,就只能定时周期性的来轮序,但是很有可能一次轮询,一个就绪的fd都没有。但是有了就绪对了,其实应用层是不需要周期来轮询的。应用层就只需要调用epoll_wait()就好了,如果没有就绪的fd,那么epoll_wait()会让线程阻塞的;当有fd就绪了,epoll负责唤醒阻塞的线程。可以发现,这种方式基本上是消除了无用轮询的。只要poll_wait()方法返回,那势必是有fd就绪了。
epoll的惊群问题
回过头来看,上面讲的epoll,没有特意强调,其实是以单个线程支持多个IO的角度来看多路复用的,比如一个线程使用epoll多路复用能够支持100的并发量,那么用10个线程,是不是就能支持近1k的IO并发呢?
所以就要看下,多线程IO的场景下如何使用epoll多路复用。
一种方式是:多个线程复用一个epoll,每个线程去支持多路IO请求:
这里就会发现,就会有多个线程都会去调用epoll_wait(),那么当就绪队列为空的时候,所有调用epoll_wait()的线程都会被阻塞在就绪队列上。这个时候,当某一个fd就绪,被放到就绪对了中时,那么epoll就会去唤醒所有阻塞在就绪队列上的所有线程,但实际上,只有就绪fd对应的那个线程能够从epoll_wait()方法中获取就绪fd,然后从读缓冲区读取到数据(如上图的线程1),其他线程其实唤醒后,还是继续又阻塞在就绪队列上。这就是epoll的惊群问题。
明确一下惊群问题发生的场景:在并发编程中,当有多个线程/进程争抢同一资源,因资源不足而被阻塞的时,当阻塞事件解除后,如果唤醒了所有阻塞在该事件上的所有线程/进程,那就触发了惊群效应。
所以,要解决惊群问题,其实也就从这几个方面入手就好了:
- epoll里出现惊群,统一资源是指epoll的就绪队列。所以可以不共享epoll,就能避免问题。
- 阻塞事件解除,对应到epoll中,就是有ft就绪了,放到了就绪队列中,然后唤醒了所有的线程。如果这个地方不唤醒所有的线程,就不会有惊群问题了。
如下就是一个线程单独使用一个epoll,这样就不会有惊群问题了。
但是这里也需要注意一个问题:如果多个线程将一个相同的fd注册到多个epoll中,然后当fd上的IO就绪后,每一个epoll都会将这个fd加入到自己的就绪队列中,然后唤醒阻塞在就绪队列上的线程,但是其实还是只会有一个线程从这个fd上获取到IO数据,其他线程还是又会被继续阻塞。这种情况多线程公用的就不是epoll,而是一个fd,从而导致惊群问题。对于这种情况在注册的时候控制,别把一个fd注册到多个epoll中去,这其实就是一个使用上的问题。
但是对于多个线程公用一个epoll来实现IO复用的时候,惊群问题,就只能从第二个方面入手来解决了:在唤醒的地方入手。
如前面描述的,当epoll的就绪对了为空,那么所有调用epoll_wait()的线程都会阻塞在就绪队列上;当fd就绪,epoll就会将就绪的fd放到就绪队列中,并唤醒阻塞在就绪队列上的所有进程。然后线程调用的epoll_wait()就会返回,获得一个就绪的fd。当线程获取到fd后,就是去读缓冲区(读IO请求时)读取数据:这个时候就有两种可能:这个线程处理成功了,皆大欢喜;但是如果失败了,怎么办?epoll到底是将这个就绪的fd从就绪队列删除?还是会重试?
这个就是所谓的触发方式:
- LT 水平触发模式
只要仍然有未处理的事件,epoll就会通知你,调用epoll_wait就会立即返回。 - ET 边沿触发模式
只有事件列表发生变化了,epoll才会通知你。也就是,epoll_wait返回通知你去处理事件,如果没处理完,epoll不会再通知你了,调用epoll_wait会睡眠等待,直到下一个事件到来或者超时。
所以即使是多个线程公用一个epoll,但是如果是边沿触发模式,因为只会通知一次(epoll会遍历阻塞队列,只是唤醒一个线程),所以不会有惊群问题的。
所以对于多个线程线程公用一个epoll的惊群问题,只是在水平触发的时候才会出现。这水平触发方式下,惊群问题在epoll本身是没办法解决的。直到linux引入了EPOLLEXCLUSIVE标志。
在使用epoll_ctl(add)注册一个fd到epoll的时候,可以选择带上EPOLLEXCLUSIVE标志。这样当就绪队列为空 的时候,因调用epoll_wait()而阻塞在就绪队列上的那些线程,在放到阻塞队列中时就会带上EPOLLEXCLUSIVE(epoll的阻塞队列中元素的数据结构就是epollEntry,这个结构中是有地方保存EPOLLEXCLUSIVE的)。这样当有fd就绪的时候,在遍历唤醒阻塞队列中的线程时,对于没有EPOLLEXCLUSIVE标识的都会唤醒、但是遍历遇到第一个待EPOLLEXCLUSIVE标识的线程,唤醒后,就停止遍历了。从而解决惊群问题。
这跟accept使用WQ_FLAG_EXCLUSIVE解决惊群道理是一模一样的。
总结一下,惊群产生的条件:在并发编程中,当有多个线程/进程争抢同一资源,因资源不足而被阻塞的时,当阻塞事件解除后,如果唤醒了所有阻塞在该事件上的所有线程/进程,那就触发了惊群效应。
所以,要解决惊群问题,其实也就从这几个方面入手就好了:
- 不要共享,别让多个线程阻塞到相同资源上。
- 阻塞事件解除,不要唤醒所有线程。
所以说来说去,不管是linux提供的机制、还是应用层提供的机制,比如ngix等,都是在破坏这两个条件之一。
包括有些地方在说加锁,其实锁是解决不了惊群的,只是将惊群转嫁到了锁上,因为锁机制本身就有惊群问题:多个线程竞争同一个锁而阻塞在锁的阻塞队列上,锁被释放了,同样是唤醒所有想成开始去竞争锁,除非给每个线程搞一个条件变量。
惊群下的负载均衡
在epoll的惊群问题处理上,一中方式就是在唤醒阻塞在就绪队列上的线程的时候,只是唤醒一个,从而避免惊群问题。但是有个问题:比如总共有10个线程因为调用epol_wait()阻塞在就绪队列上,但突然刻有3个fd的IO就绪,那这个时候只是唤醒一个线程,那这个被唤醒线程就只能是依次处理这三个就绪fd了,但实际上,还有9个线程空闲这呢,这其实就是负载不均衡了。理想的情况下,应该是唤醒三个线程,让三个线程来处理就绪的这三个fd,就漂亮了。
但对于多个线程监听到一个fd上(epoll fd),则当IO就绪,要么唤醒阻塞在就绪队列上的所有线程、要么只是唤醒一个线程,没有机制可以根据就绪的fd数量来决定唤醒多少线程的方式。
在Socket编程中,要和客户端通信,那就是调用accept()阻塞等待客户端连接,只有客户端连接上来后才能进行下一步通信。所以第一个个需要使用到多路复用的就是accept()操作。当有连接建立完成,操作系统就会将连接放到完全队列中,并唤醒阻塞在完全队列上的线程。如果说多个线程不是通过一个ServerSocket来调用accept()而是多个,那有多个连接就绪的时候,就可以通过阻塞在多个ServerSocket上的线程,来达到唤醒多个线程处理多个连接的目的。
但是服务端上的应用都是通过特定端口来和网络通信的,一个ServerSocket就是绑定到一个ip+port上来实现和客户端通信的。要实现上述的效果,就需要多个ServerSocket绑定到相同的ip+port上。好在linux3.9以后支持SO_REUSEPORT,允许多个进程或线程 bind 相同的 ip 和端口,这样就可以实现同一个IP、PORT的请求在多个listen socket间负载均衡
所以可以通过 SO_REUSEPORT 来创建多个监听相同 IP、PORT 的 listen socket,每个进程监听不同的 listen socket。这样,在只有 1 个新请求到达监听的端口的时候,内核只会唤醒一个进程去 accept,而在同时并发多个请求来到的时候,内核会唤醒多个进程去 accept,并且在一定程度上保证唤醒的均衡性。
但是,由于 SO_REUSEPORT 根据数据包的<源ip:源port,目标ip:目标port>四元组和当前服务器上绑定同一个 IP、PORT 的 listen socket 数量,根据固定的 hash 算法来路由数据包的,其存在如下问题:
- isten Socket数量发生变化的时候,会造成握手数据包的前一个数据包路由到A listen socket,而后一个握手数据包路由到B listen socket,这样会造成client的连接请求失败
- 短时间内各个listen socket间的负载不均衡
参考:深度剖析Linux惊群:现象、原因和解决方案 - 知乎