redis的数据结构
redis是一个提供kv服务的组件,其中存储的数据都是以key-value形式来组织的。所以需要快速根据key找到对应的value。那就需要对数据进行构建索引加速。常见的索引有很多,比如hash表、B+树、字典树、倒排索引、跳跃表等等。memcached和redis都采用的是hash表作为其内存索引、rocksdb采用的是跳跃表作为其内存中的key-value索引、而mysql采用的是B+树、很多newsql(比如Tidb)采用的是LSM tree等等。数据存储结构B+树 vs LSM Tree
对于redis和memcached来说,其kv数据都是保存在内存中的,内存具有高效的随机访问特性,这于hash表的O(1)复杂度高效数据访问也正好匹配。
键值数据基本都是保存在内存中的,而内存的高性能随机访问特性可以很好地与哈希表 O(1) 的操作复杂度相匹配
对于redis来说,其value支持了很多中类型,比如String、List、Map、Set、SortedSet、HyperLogLog等,而这些类型其底层又是一个比较复杂的数据结构来支撑。所以对于redis来说,全局的这个hash表的value不是存的具体的值,而是这个值的指针。
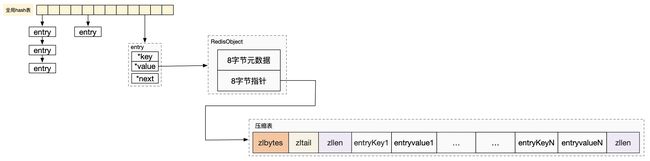
redis的整体数据结构:
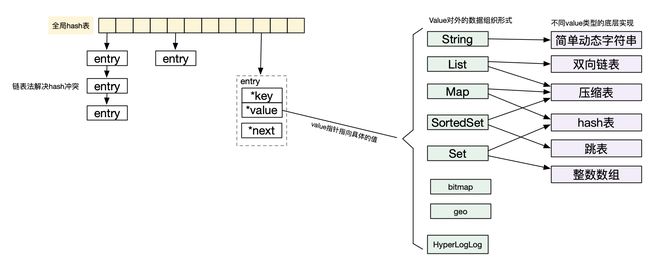
全局是一个hash表。hash桶里存放的entry不是数据本身,而是指向数据的指针。
采用链表法解决hash冲突。
如果某个hash值冲突比较大,那么在这个hash桶里的元素查找就是O(n)的顺序遍历,效率就遍地了。jdk中的HashMap采用的方式就是当同一个hash桶里的元素超过8个,就会变成红黑树,红黑树中的查找是个O(logn)的,随着元素删除、或者rehash,同一个桶里的元素小于6个的时候,又会退化成链表。
redis对hash冲突的并没有链表转红黑树的操作,而是依靠扩容hash桶、rehash将原本冲突的放在一个hash桶里的元素分散出去。
扩容rehash。因为数组的扩容是要重新申请一个新数组,然后copy数据的,这个过程是相对耗时的,会影响效率的。比如jdk的HashMap就有可能遇到rehash造成性能波动。
redis要支持大流量高并发,这种rehash过程stop the world是不能忍受的。所以redis其本上就是一个online rehash。
它采用了两个全局hash桶,平常只会使用一个。当需要rehash的时候,另一个进行二倍扩容,然后切换到新hash桶上去使用、但是并不是一次性将旧的桶里的数据一次性重新计算hash值然后copy到新桶里,而是当有请求访问到某个桶的数据的时候,一方面返回数据,另一方面将这个桶里链表上的所有数据重新计算hash,copy到新桶里。这样就将数据的copy进行了分散,避免一次性copy所有数据。
其实会发现,如果value是String类型,那么数据的访问就是一个O(1)的,但是如果value是其他类型,那么O(1)定位到value后,还需要进一步操作,所以整个操作就不一定是O(1)的了。这就需要结合访问操作类型以及value的类型来看不同操作的访问效率了。
string类型
基本原理结构
在redis的value类型中,其实会发现是没有变成语言中的一些基本类型的:比如数字类型(int、long、float、double等)、字节/字节位(byte、bit)等。其实这些都是用String来承担的,包括incre()/decre()这种自增/自减的操作,其实虽然value是String类型,但要求存入的value一定是数字,否则就会报错。
在redis中,value是string类型的时候,采用了简单动态字符串Simple Dynamic String,SDS)来实现,它包含如下三个部分:
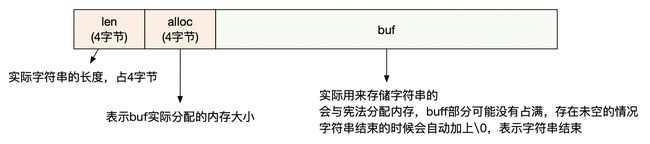
会发现,不管实际放在value的字符是多长,那么固定开销都会有8个字节+1个字节的\0。如果说value就一个字符,那么这些元数据的占用空间,比数据本身都还大了。
在实际的实现中,全局hash表的桶位上存储的是entry结构,包含三部分:
key指针
value指针:指向的value值。它实际桑是指向了一个RedisObject的结构,真实的value数据就是存放在RedisObject中的。redisObject包含两部分:
8字节的元素据:比如当前key最近访问时间等
8字节的指针,指向真实的数据。比如value是map结构的时候,那value就执行的是一个hashmap等。
next指针:链表法解决hash冲突,指向冲突的下一个元素
当value类型是String的时候,以为前面也说了redis的string类型承担的不仅仅是字符串的角色,其实value的数字类型也是通过string来实现的。所以redis在实现string的时候,又系分了三种情况
如果value是个数字,那么就不会初始化SDS结构来存储了。而是直接将数字存放在RedisObject的8字节指针处,正好是一个long型数据。
RedisObject的这种布局,又称为int编码方式
如果value包含字符,但是字符数小于44个,即短小的字符串时。
如果RedisObject和SDS也是各自申请分配内存,那么会发现RedisObject占16字节、SDS最多也就占53字节(9字节的固定开销+44个字符)。也就是说会向操作系统申请很多这种小块内存。那么随着key的过期删除,这些小块内存回收后,就成了内存碎片了。为了减少内存碎片的产生,所以redis在value字符串小于44改个的时候,是将RedisObject和SDS放在一个连续内存的,即两个合并在一起申请内存。
RedisObject的这种布局,又称为embstr编码方式
如果value包含字符,但是字符数大于44个。
这个时候当然字符串数据肯定是放在SDS中的,RedisObject中的指针也就是指向了SDS。只是RedisObject和SDS是分开申请内存的,他们两就不一定是放在一块连续的内存了。
RedisObject的这种布局,又称为raw编码方式
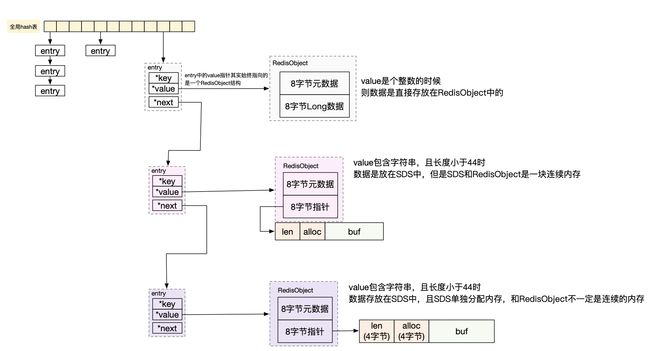
所以会发现,哪怕用户使用redis的时候,value是个string类型,其实内部的在内存中的 布局实现是有可能不一样的。
当包含字符的时候,一个value所占用的内存包含:
entry中 的value指针8字节
next指正不一定有可能是空的,这里算value的内存开销,暂时忽略key的内存开销
RedisObject的固定16字节
SDS的固定9字节
字符串本身占用的内存
所以一个非数字的string类型的value,固定占用41字节。所以当value的内容都是比较短的内容的时候,其实使用String类型效率是非常低的。这里还没有算key的开销,再算上key的开销,那效率就更低了。
所以当value是比较小的字符串的时候,使用string类型的value,效率其实是比较低的,其本质就是string的内部实现决定的。
jedis客户端使用示例
// jedis客户端使用示例
private void stringTest() {
jedis.set("key", "strvale");
SetParams setParams = new SetParams();
setParams.ex(10);// 10s后过期。单位:秒。等同于jedis.setex()
setParams.exAt(12312);// 在指定unix时间点过期,单位:秒
setParams.px(10L);// 10ms后过期,单位:毫秒
setParams.pxAt(1000L);//在指定unix时间点过期,单位:ms
setParams.nx();// 当key不存在的时候,才插入;已经存在不会覆盖。默认是不存在就插入、存在就覆盖。等同于jedis.setnx()
setParams.xx();// 如果不存在就报错、存在就覆盖。
//setParams.keepttl();
jedis.set("strkeyparam", "strvalueparam", setParams);
// 批量读取
jedis.mget("strkey1", "strkey2");
// 如下几个取value子串的方法,因为要在value上计算,不是一个O(1)的性能。
jedis.substr("key", 0, 1);
jedis.getrange("strkey", 0, 10);
jedis.setrange("strkey", 0, "value");
}private void numerictest() {
// 这个其内部实现其实是将string转换成了int/float,然后开始增加和减少的。
// 所以使用这个方法的时候,value一定要是数字。否则就会报错
jedis.incr("numkey");
jedis.decr("numkey");
jedis.incrByFloat("floatkey", 1.0D);
}private void bitTest() {
// 查询指定偏移量的bit是0还是1
jedis.getbit("key", 1);
// 设置指定偏移量的bit为0或者1
jedis.setbit("key", 2, true);
jedis.bitcount("key");
jedis.bitfield("key", "arg1");
jedis.bitfieldReadonly("key", "arg1");
BitPosParams bitPosParams = new BitPosParams();
jedis.bitpos("key", true, bitPosParams);
// 按位与、或、抑或、非运算。按位运算其实也就是bit类型集合的集合运算(并、交、补、差)
jedis.bitop(BitOP.AND, "dstkey", "srcke1", "srck2");
}// jedis连接redis服务器
JedisPool pool = new JedisPool("localhost", 6379);
Jedis jedis = pool.getResource();// 也支持从配置文件读取配置初始化集合类型
集合类型底层依赖的结构
压缩表(ziplist)
压缩表的结构:

其实压缩表就是相对于SDS的,SDS是每个value数据都待了RedisObject以及SDS的头,而压缩表是n个数据。这n个数据是连续内存来存放的
双向链表(quicklist)
ziplist的设计结构,因为保个,存了元素个数、尾部偏移量,所以对头尾的增删改都是O(1)的操作。而且相对于SDS接口,又节约了空间。但是也正因为ziplist的entry是存放在连续内存中的,那么当原本的空间已经被entry沾满,那么对新增entry、或者原有entry中字符串边长,就只能去申请新的内存,然后进行元数据的copy并修改。而当ziplist元素个数过多的时候,就会导致性能下降。
其实会发现ziplist结构其实和数组是类似的,都是使用连续内存来存放数据。所以要解决因为连续内存存放带来的问题,那么就是用链表来实现。
在redis3.2之后引入quickList,其本质就是双向链表和ziplist的结合。

这样通过控制ziplist 的大小,解决了超大ziplist 的拷贝情况下对性能的影响。每次改动只需要针对具体的小段ziplist 进行操作。
ps:这种将两个数据结构结合来取长补短,平衡各自的优缺点,是一个不错的思路。lucene中对map也重新进行实现,使用了两次hash、嵌套的hash桶,就可以很好的避免rehash带来的影响。
list类型
基本原理结构
在redis的value是List的时候,当list中元素比较少的时候,其背后就是一个ziplist:

当元素变多了后,背后支撑value这个列表的就是quickList(本质是链表和ziplist的结合)

这就是为什么说实现list类型的背后是压缩表和双向链表的原因啦。
jedis客户端使用示例
// redis的列表底层是基于链表的实现。在对外api上,除了List接口外,还支持了队列、栈操作接口。
private void listTest() {
// 将指定元素添加到链表头部:如果指定key对应的列表不存在,就会创建一个。
jedis.lpush("key", "value1", "value2");
// 也是将指定元素添加到链表头部:但如果指定列表不存在,则什么也不做。
jedis.lpushx("key", "value1", "value2");
//将指定元素添加到链表尾部
jedis.rpush("key", "value1", "value2");
jedis.rpushx("key", "value1", "value2");
// 从链表头部弹出一个元素:即删除并返回头部元素。如果key不存在,则什么也不做,返回空
jedis.lpop("key");
// 从链表尾部弹出一个元素:即删除并返回头部元素
jedis.rpop("key");
// 替换指定下标位置的值。注意:不是插入,是替换。如果指定下标不存在,即index>jedis.llen("key"),则会报错
jedis.lset("lstkey", 0, "lstvalue");
//在key指定的列表中,从头到尾遍历,当遇到第一个pivot指定元素之前/之后插入一个value值。
jedis.linsert("key", ListPosition.BEFORE, "a", "b");
// 返回对应你key的列表的长度
jedis.llen("lstkey");
// 从rsckey指定的列表头/尾(to=left是头、to=riht是尾)弹出一个元素,然后将这个元素添加到dstkey指定的列表的头/尾(to=left是头、to=riht是尾)
jedis.lmove("rsckey", "dstkey", ListDirection.LEFT, ListDirection.RIGHT);
//在指定key中的列表中,如果指定的value出现了count次,则删除。
// 如果count=0,则就是删除列表中所有值=value参数指定指值的元素
// 如果count>0,就是从头开始遍历,将前count次出现的value值都删除
// 如果count<0,就是从尾开始遍历,将前count次出现的value值都删除
// 比如:a,b,c,a,,d
// jedis.lrem("lstkey", 0, "a"),那么会删除列表中所有的1。即最后列表是:b,c,d
// jedis.lrem("lstkey", 1, "a"),那么就会从头开始遍历,删除一个a,那么最终结果就是b,c,a,d。如果count>=2,那么就是将a都删除了,因为一共就有两个a
// jedis.lrem("lstkey", -1, "a"),那么就是从尾开始遍历,删除一个a,那么最终结果是a,b,c,d
jedis.lrem("lstkey", 0, "lstvalue");
// 获取指定key对应列表,指定下标位置的元素。注意:如果index超过限制,不是报错,是返回null
jedis.lindex("lstkye", 0);
// 裁剪指定key对应的列表。会删除[start,stop]之外的元素,只保留指定范围内的元素。即相当于[star,stop]和原来[0,len]取了个交集。
// 比如原有数组[1,2,3]
// 1. ltrim("lstkey",0,1),那么就会删除3,剩下[1,2]
// 2. ltrim("lstkey",0,100),最后还是[1,2,3],相当于啥也没干
// 3. ltrim("lstkey",100,200),就是清空了整个列表。两个范围取交后不剩下元素了
jedis.ltrim("lstkey", 0, 1);
// 获取[start,stop]范围内的元素。但是不改变原数组。其逻辑和trim其实是一样的,只是不修改原数组。返回的是[start,stop]和[0,len-1]这两个区间的交集
jedis.lrange("lstkey", 0, 1);
// 返回指定指定key对应列表中,指定元素的下标位置。
jedis.lpos("lstkey", "eletemen");
// 求两个指定key对应的列表的最大公共序列
LCSParams lcsParams = new LCSParams();
jedis.lcs("lstkey1", "lstkey2", lcsParams);
// 对于普通的poo()是不阻塞的,没有数据返回null。这种其实在缓存使用场景是符合预期的,没有啥问题。
// 但实际上redis本身是支持消息队列的,其消息队列就是依靠list来实现的。
// 它的消费模型是pull方式:消费者不断去调用pop()方法,来拉取队列的元素。如果说队列是空的,那么消费者以要一直调用pop(),否则当队列有元素了感知不到
// 这就会造成消费者很多空轮询。所以redis提供了阻塞式的pop()方法来避免空轮询。
jedis.blpop(1, "key");
jedis.blmpop(1, ListDirection.LEFT, "key1", "key2");
jedis.blmove("rsckey", "dstkey", ListDirection.LEFT, ListDirection.RIGHT, 1);
jedis.brpop(1, "key");
jedis.brpoplpush("sourcekey", "dstkey", 1);
}Hashmap类型
基本原理结构
Redis对外提供的整体的key-vaule服务,其数据索引组织形式就是hash表,所以在基本原理和逻辑上,value的HashMap类型是一样的。在实现上,都有很多是复用的。
不过需要注意一点就是,当元素个数比较少的时候,底层的实现不是hash表,而是ZipList。这个时候ziplist的entry个数是成对出现,存储key-value。
所以put操作的时候,就直接是添加了两个entry元素;hget 操作时也不需要进行 hashCode 的计算,直接遍历ziplist,比对key的值来获取value。
当使用hash表来实现的时候,其实就跟全局hash桶的实现是类似的了。
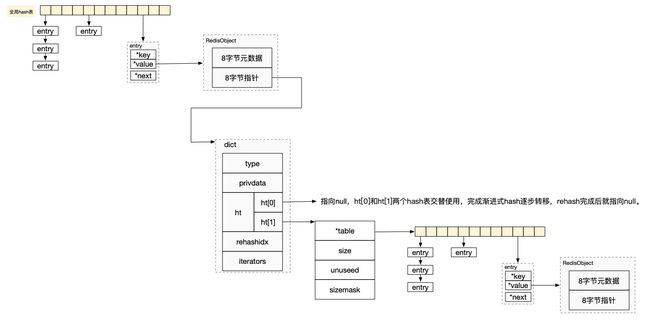
这个时候RedisObject的8字指针指向的是一个dict结构,这个结构就是hash表的实现,其实全局hash桶也是使用这个结构来实现的。只是在画图时,为了表达原理不搞那么复杂,全局hash表简化了。
jedis客户端使用示例
// 虽然value是map结构,但是map中的键值对都只能是string类型了。即redis的复杂类型不支持复杂类型的嵌套使用
// 即redis的复杂类型只是支持:
// List,不在支持嵌套了,比如List>,List>等都不支持了。map、set、sortedset同理
private void mapTest() {
// 向key指定的map结构中增加一个键值对。如果map中field指定的key不存在就插入、存在就覆盖
jedis.hset("mpkey", "mpfile", "mpvalue");
// 和hset()一样,只是说如果field指定键值不存在才插入、已经存在则啥也不做。即不覆盖更新
jedis.hsetnx("mpkey", "mpfield", "mpvalue");
// 批量插入一个map
jedis.hmset("mpkey", new HashMap());
// 返回指定key这个map的所有值。
jedis.hgetAll("mpkey");
// key指定map中指定field的一个值
jedis.hget("mpkey", "mpfield");
// key指定map中指定field的一组值
jedis.hmget("mpkey", "mpfield", "mpfield2");
// field指定的键值对在key指定的map中否存在
jedis.hexists("mpkey", "mpfield");
// key指定map中的所有key、hvals()返回的是指定map中的所有value
jedis.hkeys("mpkey");
jedis.hvals("mpkey");
// 指定map的元素个数
jedis.hlen("mpkey");
// field指定键值对,value的长度
jedis.hstrlen("mpkey", "mapfield");
// 渐进式遍历,每次只返回有限数量的数据
jedis.hscan("mpkey", "cursor");
// 从指定map中,随机获取一个键值队的key。
jedis.hrandfield("mpkey");
jedis.hrandfieldWithValues("mpkey", 1);
// 如果键值对中的value是数字类型,可以将对应field指定的value进行加上指定的数值
jedis.hincrBy("mpkey", "mpfiled", 1L);
jedis.hincrByFloat("mpkey", "mapfile", 1D);
} Set类型
IntSet
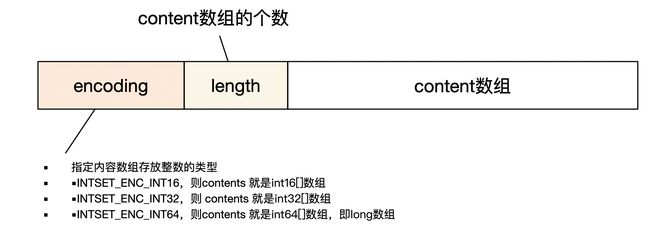
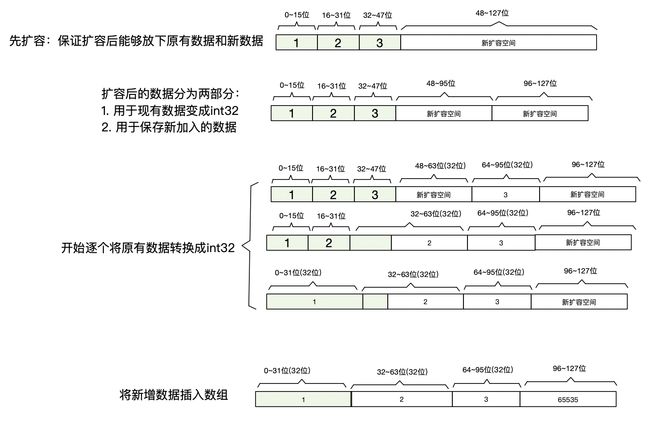
如果原来在content中存放的都是一个4字节的整数,这个时候,突然插入一个超过2字节能够表示的范围的整数,比如插入2^20这个数,两个字节肯定是表示不下的,那其实需要换4字节的整数来表示。但是原本里面已经存在的数据该怎么办呢?
最简单的想法就是申新的int32[]数组,然后 将原有数据给copy过来,毕竟4字节肯定是可以表示2字节能够表示的数的,无非就是有空间浪费。
所以redis并没有这么做,而是自己实现了这个数组,它并不会重新分配新类型的数组,而是在原数组上扩展,然后将原来的数据转换
ps:会发现redis在支撑value的各种结构中,基本上都不是使用的通用的结构,而是自己针对内存操作专门优化实现了一些结构来支持value的各种类型。其实这也是redis高效的原因之一,因为它底层使用的数据结构都是针对性的优化过的高效数据结构,而不是通用的数据结构。
比如,当前数组中有1、2、3三个数
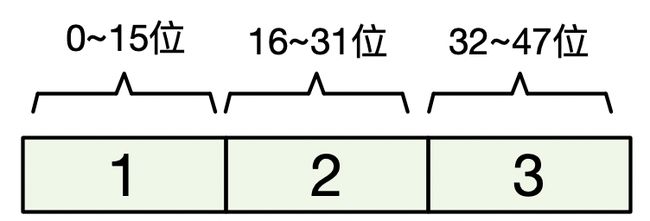
这个时候要插入65535这个数,这个数2字节表示不小,需要用4字节来表示。但是这个数组中又是一个int16数组。
set类型的实现
当一个 Set 对象只包含整数值元素,并且元素数量不大时,就会使用IntSet来存储数据。

如果Set元素不仅仅包含整数,那么底层就是使用HahsMap实现,无非就是HashMap中的value都是空的,RedisObject中的8字节指针就是指向的一个Map
jedis客户端使用示例
private void setTest() {
jedis.sadd("key", "e1", "e2");
// 删除set中指定的元素
jedis.srem("key", "e1");
// 指定元素在set中是否存在
jedis.sismember("key", "e");
// 返回set中元素的个数
jedis.scard("key");
// 返回set中所有元素
jedis.smembers("key");
// 随机返回set中的一个元素
jedis.srandmember("key");
jedis.sscan("key", "cursor");
// 这些集合运算,复杂度都是比较高的。所以一般这种集合运算会放到副本节点上
// 集合取并集
jedis.sunion("key1", "key2");
jedis.sunionstore("key1", "key2");
//集合取差集
jedis.sdiff("key1", "key2");
jedis.sdiffstore("key1", "key2");
//集合取交集
jedis.sinter("key1", "key2");
jedis.sintercard("key1", "key2");
jedis.sinterstore("key1", "key2");
}SortedSet类型
基本原理结构
SortedSet提供的是一个按照score排序的有序set类型。但在redis的实现中,其实是存储了一个二元组:
member,其实就是数据元素
score:用于排序
sorted set有两种实现方式:
ziplist实现
zset(hash表+skiplist)实现
当元素个数比较少的时候,使用的是ziplist来实现。和使用ziplist实现hash表时一样,entry也是成对出现的:前面是数据元素紧跟着的就是改元素的score。整个entry列表按照score进行排序的。

在查询时,比如判断元素是否在SortedSet中,都是遍历entry来实现。对于写入的时候,就需要按照score排序找到对应的位置然后插入,保持整体的按score有序。
当元素个数比较多时候,底层就会变成HashMap+跳跃表的实现
HashMap:Set集合也是通过HashMap实现的时候,value是空的。而sortedSet中的HashMap中的value是score。
跳跃表:提供按照score排序。即跳跃表中是按照score进行排序的。跳跃表简介:常见数据结构之跳跃表简介
当数据修改/插入的时候,需要同时维护HashMap和跳跃表。而查询的时候,如果只是Set的功能,比如存在性判断、查询下元素的score等直接HashMap就支持了;但是当操作依赖score顺序的时候,就会用到跳跃表了.
等搞一篇跳表的介绍后,再来补充这张图
jedis客户端使用示例
//sortedSet是按照score排序的一个有序set
private void sortedSetTest() {
// 添加元素:需要指定元素以及对应的score
jedis.zadd("key", 1, "member");
ZAddParams zAddParams = new ZAddParams();
// 将指定元素的score增加指定值
// 1. 如果key指定的sortedSet都不存在,则会初始化一个,并将指定的member加入到初始化的sortedSet中,这个member的score就是指定的score
// 2. 如果key指定的sortedSet存在
// 2.1 但是指定的member在sortedset中不存在,则将指定的member加入到初始化的sortedSet中,这个member的score就是指定的score
// 2.2 指定的member在sortedset中存在,则将原有的member的socre = score+参数指定的score值。
jedis.zaddIncr("key", 1D, "member", zAddParams);
// 看描述和zaddIncr()区别在于当key指定的set空时候,将报错。其他的和zaddIncr()一样。不过
jedis.zincrby("key", 1, "member");
// 返回sortedSet中元素个数
jedis.zcard("key");
//返回sortedSet中指定score范围内的[min,max]元素个数
jedis.zcount("key", 1D, 2D);
jedis.zlexcount("key", "min", "max");
// 弹出score最小的元素,如果sortedSet为空返回null
jedis.zpopmin("key");
// 弹出score最大的元素,如果sortedSet为空返回null
jedis.zpopmax("key");
jedis.zmpop(SortedSetOption.MAX, "");
//弹出score最小的元素,如果sortedSet为空,则阻塞当前线程
jedis.bzpopmin(1, "key");
jedis.bzpopmax(1, "key");
// 随机返回sortedSet中的一个元素
jedis.zrandmember("key");
jedis.zrandmember("key", 1L);
jedis.zrandmemberWithScores("key", 1L);
// 查询指定范围内的元素
ZRangeParams zRangeParams = new ZRangeParams(1, 2);
jedis.zrange("key", zRangeParams);
jedis.zrangeByLex("key", "min", "max", 1, 2);
jedis.zrangeByScore("key", 1D, 2D);
jedis.zrangeByScoreWithScores("key", 1D, 2D);
jedis.zrangeWithScores("key", 1L, 2L);
// 从sortedSet中删除元素,如果远不不存在将会报错
jedis.zrem("key", "m");
// 删除指定范围内的元素
jedis.zremrangeByRank("key", 1, 2);
jedis.zremrangeByLex("key", "min", "max");
jedis.zremrangeByScore("key", "min", "max");
// 按照score升序,元素的下表
jedis.zrank("key", "e");
// 按照score降序,元素的下表
jedis.zrevrank("", "");
// 扫描遍历
jedis.zscan("key", "cursor");
// 取交集
ZParams zParams = new ZParams();
jedis.zinter(zParams, "key1", "key2");
jedis.zintercard(1, "key");
jedis.zinterstore("dstkey", zParams, "key1", "key2");
jedis.zinterWithScores(zParams, "key");
// 取差集
jedis.zdiff("key1", "key2");
jedis.zdiffStore("dstkey", "keye", "key2");
jedis.zdiffWithScores("key1");
// 取并集
jedis.zunion(zParams, "key1", "key2");
jedis.zunionstore("dstkey", "key1", "key2");
jedis.zunionWithScores(zParams, "key1", "key2");
}HyperLogLog类型
基本原理结构
参考:https://www.bbsmax.com/A/Vx5MNpy3dN/
这个地方的基本原理更多的是一些数学原理,以及redis怎么用极少的空间,来存储居多数据的去重统计的,这里就不展开了。
结论:HyperLogLog可以用12K的内存来记录2^64个数据的近似基数统计(去重个数统计)。因为HyperLogLog 的统计是基于概率统计,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。所以如果要精确统计的话,HyperLogLog还是不合适的。
jedis客户端使用
private void hyperLogLogTest() {
// 向byperloglog中增加元素,如果指定导致计数值加增加,则返回1;如果指定元素是重复元素/或者因为近似估算认为是重复元素,计数器不变,则返回0
jedis.pfadd("key", "e1");
// 返回hyperloglog中不重复元素的个数(估算值)。如果传入的是多个key,那就是返回多个hyperloglog并集中不重复元素的个数。
jedis.pfcount("key");
// 将n个sourcekey指定的hyperloglog进行取并集合并,放到destkey指定的hyperloglog中
jedis.pfmerge("destkey", "sourcekey", "sourcekey2");
}
集合类型的统计
集合类型上常见的4中统计方式:
聚合统计:指统计多个集合元素的聚合结果。包括取交集、并集、差集。redis在set和sortedSet这两种类型上支持了集合的交、并、差集的运算。
排序统计:redis中list和sortedSet是有序的。
list是按照插入序排序
sortedsSet是按照指定score进行排序
二值状态统计:即存在性统计。redis的String底层其实是用字节数组来存储的,并且对外提供了位运算的接口。所以String类型的value还可以当成BitMap使用,可以利用它进行二值状态统计。
基数统计:即统计集合中不重复的元素个数。redis的set、hashmap类型其实都是天然去重的集合类型,但是他两毕竟不是面向统计的,用它来做去重统计,是可以实现的,不过会占用比较多的内存。redis为这种统计不重复元素提供了一个数据结构:HyperLogLog。
ps:HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。所以如果要精确统计的话,HyperLogLog还是不合适的。
Stream数据类型
专门为消息队列设计的数据类型,它提供了丰富的消息队列操作命令。虽然在实际生产中,使用消息队列的时候,我们不会优先选择redis来作为消息队列,而是使用kafka、rocketMq等这类专门的消息系统。但是redis内部很多机制其实依赖了自己的消息队列能力的
jedis客户端,value为stream类型的主要api
private void streamTest() {
// 插入消息。会自动生成全局唯一的id,并保证有序。
StreamEntryID streamEntryID = new StreamEntryID();
jedis.xadd("key", streamEntryID, new HashMap());
// 读取消息,可以按照id进行读取
XReadParams xReadParams = new XReadParams();
jedis.xread(xReadParams, new HashMap());
// 按照消费者组的方式读取
XReadGroupParams xReadGroupParams = new XReadGroupParams();
jedis.xreadGroup("group", "cousumer", xReadGroupParams, new HashMap());
jedis.xrange("key", "start", "end");
jedis.xlen("key");
// 查询每个消费组内所有消费者已读取但尚未确认的消息
jedis.xpending("key","group");
// 向消息队列确认消息处理已完成
StreamEntryID streamEntryID1 = new StreamEntryID();
jedis.xack("key","group",streamEntryID1);
} 扩展类型
Bitmap 类型
本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型
String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态。你可以把 Bitmap 看作是一个 bit 数组
GEO类型
GEO 类型的底层数据结构就是用 Sorted Set 来实现的,但是SortedSet是一个一维度结构,而地理位置是需要经纬度的,是二维结构,该怎么来进行存储、以及排序呢?
所以就需要对数据进行降维运算后存储。而对地理位置二维数据的降维被广泛使用的就是:geoHash,redis也不例外。geohsah后面有时间会详细介绍多维数据降维后排序的思路以及geohash编码的详细规则
经纬度经过geohash后,其实是存储在SortedSet中的。
jedis客户端使用
private void GeoTest() {
// 添加一个经纬度。redis里其实是存量一个三元素(经纬度,member),这个memer其实就是个这个经纬度了一个唯一表示
jedis.geoadd("key", 1D, 2D, "");
// 两个经纬度之间的举例。注意:地球是球面的,这里计算的是球面举例,不是两点之间的直线举例。
jedis.geodist("key", "e1", "e2", GeoUnit.KM);
// 获取指定经纬度的geohash编码
jedis.geohash("key", "e1", "e2");
// 查询指定member编码的经纬度值。
jedis.geopos("key", "e1", "e2");
GeoRadiusParam param = new GeoRadiusParam();
GeoRadiusStoreParam storeParam = new GeoRadiusStoreParam();
// 以指定经纬度为圆心,查找在指定半径的其他位置点。如下就是查找(1,2)这个点3km内的其他点的集合
jedis.georadius("key", 1D, 2D, 3D, GeoUnit.KM);
jedis.georadiusReadonly("key", 1D, 2D, 3D, GeoUnit.FT);
jedis.georadiusByMember("key", "member", 1D, GeoUnit.FT);
jedis.georadiusStore("key", 1D, 2D, 3D, GeoUnit.FT, param, storeParam);
jedis.georadiusByMemberStore("key", "", 1D, GeoUnit.FT, param, storeParam);
jedis.georadiusByMemberReadonly("key", "", 1D, GeoUnit.FT);
jedis.geosearch("key", "member", 1D, GeoUnit.FT);
jedis.geosearchStore("key", "", "", 1D, GeoUnit.FT);
GeoSearchParam geoSearchParam = new GeoSearchParam();
jedis.geosearchStoreStoreDist("destkey", "srckey", geoSearchParam);
}自定义value的类型
前面说过,redis的全局hash表的桶位存储是个Entry结构,Entry里的value指针指向的是一个RedisObject结构,这个RedisObject才是真正承载value数据的结构。前面简单介绍了RedisObject包含两部分元数据和指针,其8字节的元数据进一步分成了4个字段
8字节的元数据:
type:value的类型,包括了redis内置的string、list、map、set、sortedset、hyperloglog。
encodeing:底层实现value类型的编码方式:int编码、embstr编码、raw编码
lru:记录的了当前键值对的最近一次访问时间,LRU淘汰策略就是使用的这里记录的最近访问时间
refcount:对应引用计数,记录了value类型这个队形被应用的次数
8字节的指针:根据元素据encodeing的不同,可能存储的是指针、也可能存储的是long型数据

我们要自定义数据类型,其实就是扩展type的取值和encoding的取值,然后让指针执行我们新自定义的结构就好了。
redis的扩展模块
RedisTimeSeries
RedisTimeSeries是用于聚合计算的一个扩展模块。 支持的聚合计算类型很丰富,包括求均值(avg)、求最大 / 最小值(max/min),求和(sum)等