爬取淘宝商家货物简单销售数据(销量,价格,销售地,货物名称)
爬取淘宝商家货物简单销售数据(销量,价格,销售地,货物名称)
爬取淘宝店家数据信息
- 爬取淘宝商家货物简单销售数据(销量,价格,销售地,货物名称)
-
- 一、登录淘宝,获取Cookies
- 二、输入关键字,翻动页码,查看源码以及回应内容的变化。并请求数据
- 三、分析数据网页源码,获取数据
- 四、存储数据,并将数据按照销量降序排列
前天接一个爬取淘宝商家(自行车)信息的请求,要求数据按照其销售量排行。
完成该请求后,爬取数据(李宁卫衣)如下:

接下来看如何实现的?
首先打开淘宝网:https://www.taobao.com/,在搜索栏输入自行车,结果发现页面转跳到https://login.taobao.com/member/login.jhtml 淘宝登录页面,要求登录才能进行关键字搜索获取数据。(需要登录的时候应当想到cookies)
cookies 及其用处:
当我们登录某网站时,服务器会生成一个cookies,包含有用户登录等信息,与当前账号绑定,浏览器将此cookies存储到。下一次,浏览器带着cookies访问网站,就不需要在输入账号密码。注意cookies是有时效性的。
所以,目标明确,第一步,获取用户登录的cookies
一、登录淘宝,获取Cookies
需要登录淘宝页面获取cookies,才能执行后续操作。而模拟登录有两种方法:
- 搞清淘宝登录机制,修改参数登录。(借鉴裸睡的猪 猪哥的文章)
- 使用selenium调用webdriver模块,模拟人真实的操作浏览器。
方法一:直接看源码+备注,具体原因看猪哥的解释(当然代码是自己写的啊,思想借用)
import requests
import re
import json
import time
import random
check_url = 'https://login.taobao.com/newlogin/account/check.do?appName=taobao&fromSite=0'
headers = {
'origin':'https://login.taobao.com',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
# 标记了请求从什么设备,什么浏览器上发出
}
session = requests.session()
login_url = 'https://login.taobao.com/newlogin/login.do'
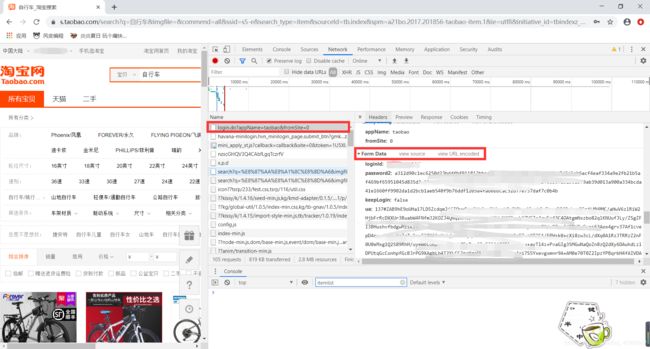
#自己手动登录一次,在参数页面把所有参数复制过来替换掉,看下图
Login_Data = {
'loginId': '****',
'password2': '*****',
'keepLogin': 'true',
'ua': '***',
'umidGetStatusVal': '255',
'screenPixel': '1536x864',
'navlanguage': 'zh-CN',
'navUserAgent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'navPlatform': 'Win32',
'appName': 'taobao',
'appEntrance': 'taobao_pc',
'_csrf_token': '*****',
'umidToken': '****',
'hsiz': '****',
'bizParams':'',
'style': 'default',
'appkey': '00000000',
'from': 'tbTop',
'isMobile': 'false',
'lang': 'zh_CN',
'returnUrl': 'https://www.taobao.com/',
'fromSite': '0',
}
login_res = session.post(login_url,headers=headers,data=Login_Data) #带着这些参数再登录一次爬取数据
#获取st码申请地址
token_json = login_res.json()
st_url = token_json['content']['data']['asyncUrls'][0] #st码的申请地址
print('验证用户名和密码成功')
#通过st码申请地址获取st码
st_res = requests.get(st_url,headers=headers)
st_code_text = st_res.text
st_code = st_code_text[579:-270] #获取st码,自己发现的规律,可以这么提取,也可以使用正则表达式
print('获取st码成功,st码:{}'.format(st_code))
#获取登录跳转链接
res_st = session.get('https://login.taobao.com/member/vst.htm?st={}'.format(st_code) , headers=headers)
my_taobao = re.search(r'top.location.href = "(.*?)"', res_st.text)
print('登录淘宝成功,跳转链接:{}'.format(my_taobao.group(1)))
my_taobao_url = my_taobao.group(1)
#登录
res_login = session.get(my_taobao_url, headers=headers)
nick_name = re.search(r'', res_login.text)
print('登录淘宝成功,你的用户名是:{}'.format(nick_name.group(1)))
username = nick_name.group(1)
# 获取cookies,将cookies转成字典,再将字典转成字符串,保存到文件夹中
cookies_ditc = requests.utils.dict_from_cookiejar(session.cookies)
cookies_str = json.dumps(cookies_ditc)
f = open(r'C:\Users\13426\Desktop\cookies.txt','w',encoding='utf-8')
f.write(cookies_str)
print(cookies_str) #cookies,具有时效性。
print('cookie已经完成序列化')
f.close()
在自行登录以后,把参数都复制到Data里替换掉代码中的data就可以。
方法二:使用selenium调用webdriver模块(自己写的,所以解释详细点)
前提是安装了Chorm driver插件,Chorm插件下载地址。
下载完成后,解压到python根目录下即可。
driver可以模拟人在目标栏目输入,也可以模拟人对按钮进行点击。
对登录页面以及源码进行分析:发现:
帐号输入框对应:
<input name="fm-login-id" type="text" class="fm-text" id="fm-login-id" tabindex="1" aria-label="会员名/邮箱/手机号" placeholder="会员名/邮箱/手机号" autocapitalize="off">
密码输入框对应:
<input name="fm-login-password" type="password" class="fm-text" id="fm-login-password" tabindex="2" aria-label="请输入登录密码" placeholder="请输入登录密码" maxlength="40" autocapitalize="off">
登录按钮栏目对应:
<button type="submit" tabindex="3" class="fm-button fm-submit password-login">登录button>
所以,代码如下:在账号密码框里输入内容,点击登录进行登录.
from selenium import webdriver#调用webdriver模块
driver = webdriver.Chrome()#设置引擎为Chrome,模拟真实地打开一个浏览器
driver.get('https://login.taobao.com/member/login.jhtml') #打开这个链接
time.sleep(1) #等待一秒钟,模拟真人操作
## 运行代码之前输入自己的账号和密码
user = driver.find_element_by_name('fm-login-id')
user.send_keys('这里输入自己的账号') #在fm-login-id对应框中输入账号
time.sleep(1)
assistant = driver.find_element_by_name('fm-login-password')
assistant.send_keys('这里输入自己的密码')
time.sleep(1)
submit = driver.find_element_by_class_name('fm-btn') #点击登录按钮
submit.click()#登录
time.sleep(5)
cookie_list = driver.get_cookies() #登录以后获取cookie
cookies = {}
print(len(cookie_list))
for cookie in cookie_list:
cookies[cookie['name']] = cookie['value'] #将cookies字典化
print("已经成功的获取到用户登录的cookies")
print(cookies)
driver.close()
注意,有时候登录时需要滑动滑块,手动滑动登录即可。
到此用户操作所用cookies的已经获取,这时候就可以搜索关键字了
二、输入关键字,翻动页码,查看源码以及回应内容的变化。并请求数据
进入搜索页:https://s.taobao.com/search? 输入关键字,观察url变化

我们发现q参数对应着搜索内容。然后翻动页面,来到第二页,观察url变化,发现变化的有s参数

研究多个页面发现,url需要修改的参数只有q与s。
在翻页的过程中,发现我们所需要的内容在Response的第0个回应中,即存在于Element中,所以只要获取到该网页的源码,就可以获取到数据。
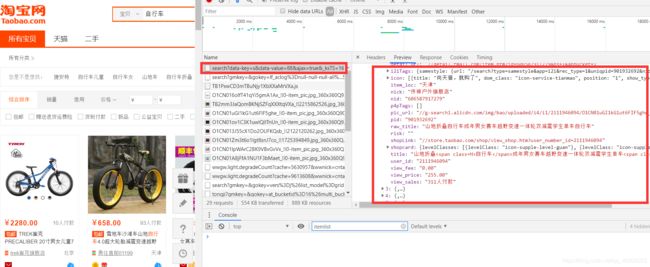
所以使用https://s.taobao.com/search?q=自行车&s=88 这个格式(q表示搜索的关键字,s*44代表页数)的链接就可以访问带有数据的源码。
所以代码如下:
headers = {'Host':'s.taobao.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding':'gzip, deflate, br',
'Connection':'keep-alive'
}
list_url = 'http://s.taobao.com/search?q=%(key)s&ie=utf8&s=%(pnum)d'
for i in range(Page):
pnum = i*44
url = list_url%{'key':key,'pnum':pnum}
print(url)
res = requests.get(url,headers=headers,cookies=cookies) #带有前面获取的cookies
三、分析数据网页源码,获取数据
这是我爬取的一个李宁卫衣的网页源码,发现重要信息保存在一个大字典:g_page_config中


所以我们可以通过正则表达式获取这个大字典,然后逐一提取各数据。或者直接正则各数据提取,我们采用第二种方法。
#创建正则表达式
titles = '"raw_title":"(.*?)"' #标题
locations = '"item_loc":"(.*?)"' #销售地
sales = '"view_sales":"(.*?)人付款"' #销售量
comments = '"comment_count":"(.*?)"'#评论数
prices = '"view_price":"(.*?)"' #销售价格
nids = '"nid":"(.*?)"' #这里需要nid,是因为商品的链接是需要这个参数的
#res.text表示网页源码,在其中匹配正则
title = re.findall(titles,res.text)
location = re.findall(locations,res.text)
sale = re.findall(sales,res.text)
comment = re.findall(comments,res.text)
price = re.findall(prices,res.text)
nid = re.findall(nids,res.text)
到这里已经把所有有效数据存储到title,location等变量中。它们均为字符串列表
四、存储数据,并将数据按照销量降序排列
使用csv保存数据
csv_file = open(r'文件保存路径','w',newline='',encoding='utf-8-sig')
writer = csv.writer(csv_file)
writer.writerow(['商品名称','销售地','销售量','评论数','销售价格','商品链接'])
#后续写入即可
因为要求数据要根据销量降序排列,而销量数据格式为字符串。分析源码,发现源码中销量的表示一般有’8000+’、‘1.6万+’、‘784’这几种表示。即如果销量小于10000,则按照 ‘具体数字’ 或 ‘具体数字+’ 这样表示,如’845’、‘3500+’,如果数据大于一万,则会在后续加个万字, 如’1.6万+’,‘5.8万’,强转为float时需要做判断:
所以,通过条件判断语句和if else判断:
sale[j] = sale[j] if sale[j][-1] !='+' else sale[j][:-1] #判断最后一位是不是+,如果是,就删掉
if sale[j][-1] == '万':
data.append([ title[j],location[j],float(sale[j][:-1])*10000,comment[j],price[j],goods_url ]) #如果最后一位是万,去掉最后一位,乘以10000即可
else:
data.append([ title[j],location[j],float(sale[j]),comment[j],price[j],goods_url ])
data.sort(key=itemgetter(2)) #按照第3个元素,即销量进行排序
data.reverse()#按照销量进行排序
还有一个发现就是,商品的链接与nid是有关系的,具体关系如下:
goods_url = 'https://item.taobao.com/item.htm?id='+nid[j]+'&ns=1&abbucket=19#detail'
到此代码已经分析完毕,源码如下,登录时修改自己的账号密码,以及文件的保存路径即可:
import time
import requests
import json
import re
from selenium import webdriver#调用webdriver模块
import csv
from operator import itemgetter
## 在这里设置下爬取结果文件保存的路径
csv_file = open(r'C:\Users\13426\Desktop\demo.csv','w',newline='',encoding='utf-8-sig')
writer = csv.writer(csv_file)
driver = webdriver.Chrome()#设置引擎为Chrome,模拟真实地打开一个浏览器
driver.get('https://login.taobao.com/member/login.jhtml')
time.sleep(1)
## 运行代码之前输入自己的账号和密码
user = driver.find_element_by_name('fm-login-id')
user.send_keys('输入自己的账号')
time.sleep(1)
assistant = driver.find_element_by_name('fm-login-password')
assistant.send_keys('输入自己的密码')
time.sleep(1)
submit = driver.find_element_by_class_name('fm-btn')
submit.click()#登录
time.sleep(5)
cookie_list = driver.get_cookies()
cookies = {}
print(len(cookie_list))
for cookie in cookie_list:
cookies[cookie['name']] = cookie['value']
print("已经成功的获取到用户登录的cookies")
print(cookies)
driver.close()
headers = {'Host':'s.taobao.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding':'gzip, deflate, br',
'Connection':'keep-alive'
}
list_url = 'http://s.taobao.com/search?q=%(key)s&ie=utf8&s=%(pnum)d'
titles = '"raw_title":"(.*?)"' #标题
locations = '"item_loc":"(.*?)"' #销售地
sales = '"view_sales":"(.*?)人付款"' #销售量
comments = '"comment_count":"(.*?)"'#评论数
prices = '"view_price":"(.*?)"' #销售价格
nids = '"nid":"(.*?)"' #这里需要nid,是因为商品的链接是需要这个参数的
writer.writerow(['商品名称','销售地','销售量','评论数','销售价格','商品链接'])
key = input('输入想要爬取的商品名称:')
Page = 5 # 爬取的页数 ,可以自行修改
data = []
for i in range(Page):
pnum = i*44
url = list_url%{'key':key,'pnum':pnum}
print(url)
res = requests.get(url,headers=headers,cookies=cookies)
html = res.text
title = re.findall(titles,html)
location = re.findall(locations,html)
sale = re.findall(sales,html)
comment = re.findall(comments,html)
price = re.findall(prices,html)
nid = re.findall(nids,html)
for j in range(len(title)):
goods_url = 'https://item.taobao.com/item.htm?id='+nid[j]+'&ns=1&abbucket=19#detail'
sale[j] = sale[j] if sale[j][-1] !='+' else sale[j][:-1]
if sale[j][-1] == '万':
data.append([ title[j],location[j],float(sale[j][:-1])*10000,comment[j],price[j],goods_url ]) #如果最后一位是万,去掉最后一位,乘以10000即可
else:
data.append([ title[j],location[j],float(sale[j]),comment[j],price[j],goods_url ])
print('-------Page%s 已经抓取完毕!--------\n\n'%(i+1))
time.sleep(2)
data.sort(key=itemgetter(2))
data.reverse()#按照销量进行排序
for j in range(len(data)):
writer.writerow(data[j])