机器学习中的分布式通信框架
以下文章摘录自:
《机器学习观止——核心原理与实践》
京东: https://item.jd.com/13166960.html
当当:http://product.dangdang.com/29218274.html
(由于博客系统问题,部分公式、图片和格式有可能存在显示问题,请参阅原书了解详情)
1.1 分布式通信框架
1.1.1 MPI (Message Passing Interface)
MPI,即Message Passing Interface是广泛应用于并行计算的一组消息传递标准,其官方网址如下所示:
https://www.mpi-forum.org/
它的历史可以追溯到1991年,由一小组研究人员在澳大利亚创立。随后他们于1992年4月份在virginia举行了第一次workshop,并成立了一个工作组来开展标准化进程。其中的领军人物包括Jack Dongarra, Tony Hey和David W.Walker等,他们一同发布了首个MPI标准草案,即MPI1。其后在经历了多轮的研讨和修改后,MPI 1.0版本于1994年6月份正式对外发表。
目前MPI论坛大致包括80多个人,来源于大学、政府、工业界等40多个不同的组织机构。这些组织中还包含了生产并行计算硬件设备的厂商,它们可以基于MPI标准来有针对性地设计兼容的硬件产品。
目前最新的版本是mpi-3.1,建议有兴趣的读者可以自行下载阅读(https://www.mpi-forum.org/docs/mpi-3.1/mpi31-report.pdf)。对于MPI新人来说,我们需要了解下面这些信息:
l MPI不是一种语言,而是一种标准
l MPI描述了数百个函数调用接口——基于C/C++等语言编写的并行计算程序可以通过调用它们来更快速地实现功能
l MPI是一种消息传递编程模型
基于MPI标准,工业界和学术界已经推出了多个实现库,而且其中不少还是开源的。比如当前比较有名的包括但不限于:
l Open MPI
Open MPI是由科研机构和企业共同开发和维护的MPI实现库。其主要特性如下:

更多信息请参考官方主页:
https://www.open-mpi.org/
l MPICH
由Argonne国家实验室和密西西比州立大学联合开发,具有很好的可移植性
l MPI-1
l MPI-2
下面这个范例程序展示了如何基于MPI,将“hello”消息在多个进程间进行有效传递的过程,大家可以参考一下。
#include
#include
#include
#include <mpi.h> //MPI头文件
int main(int argc, char **argv)
{
char buf[256];
int my_rank, num_procs;
/* Initialize the infrastructure necessary for communication */
MPI_Init(&argc, &argv);
/* Identify this process */
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
/* Find out how many total processes are active */
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
if (my_rank == 0) {
int other_rank;
printf("We have %i processes.\n", num_procs);
/* Send messages to all other processes */
for (other_rank = 1; other_rank < num_procs; other_rank++)
{
sprintf(buf, "Hello %i!", other_rank);
MPI_Send(buf, sizeof(buf), MPI_CHAR, other_rank,
0, MPI_COMM_WORLD);
}
/* Receive messages from all other process */
for (other_rank = 1; other_rank < num_procs; other_rank++)
{
MPI_Recv(buf, sizeof(buf), MPI_CHAR, other_rank,
0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("%s\n", buf);
}
} else {
/* Receive message from process #0 */
MPI_Recv(buf, sizeof(buf), MPI_CHAR, 0,
0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
assert(memcmp(buf, "Hello ", 6) == 0),
/* Send message to process #0 */
sprintf(buf, "Process %i reporting for duty.", my_rank);
MPI_Send(buf, sizeof(buf), MPI_CHAR, 0, 0, MPI_COMM_WORLD);
}
/* Tear down the communication infrastructure */
MPI_Finalize();
return 0;
}
我们可以基于上述代码启动4个进程,正常情况下会输出如下结果:
$ mpicc example.c && mpiexec -n 4 ./a.out
We have 4 processes.
Process 1 reporting for duty.
Process 2 reporting for duty.
Process 3 reporting for duty.
不难理解,这是一个SPMD类型的分布式程序。
1.1.2 P2P和Collective Communication
MPI规范中提供了两种通信方式,即Point-to-Point Communication和Collective Communication。
l P2P Communication
顾名思义,P2P Communication指的是两个进程之间的通信机制
l Collective Communication
和P2P相对应的是Collective Communication,简单来讲它就是一组或者多组进程之间的通信机制
(1) Point-to-point Communication
P2P通信方式很好理解,相信不少开发人员以前已经接触过类似的工程实现。我们下面再以MPI提供的一个简单代码范例来讲解一下。
#include "mpi.h"
int main( int argc, char *argv[])
{
char message[20];
int myrank;
MPI_Status status;
MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &myrank );
if (myrank == 0) /* code for process zero */
{
strcpy(message,"Hello, there");
MPI_Send(message, strlen(message)+1, MPI_CHAR, 1, 99, MPI_COMM_WORLD);
}
else if (myrank == 1) /* code for process one */
{
MPI_Recv(message, 20, MPI_CHAR, 0, 99, MPI_COMM_WORLD, &status);
printf("received :%s:\n", message);
}
MPI_Finalize();
return 0;
}
P2P通信模式下的两个基础操作就是send和receive。在上面的代码范例中,我们利用MPI_Send和MPI_Recv就可以轻松地实现process zero和process one之间的消息传递。当然,如果需要的话开发人员也可以利用MPI提供的其它功能来实现更加复杂的P2P通信场景。
对于分布式机器学习框架来说,P2P通信并不是最重要的,因而我们不做过多的讲解。有兴趣的读者可以参考MPI的官方文档做深入学习。
(2) Collective Communication
相较于P2P Communication,Collective Communication显然会复杂得多。根据MPI官方文档的描述,它为这种通信模式提供了如下一些核心的功能:
l MPI_BARRIER, MPI_IBARRIER
Barrier synchronization across all members of a group
l MPI_BCAST, MPI_IBCAST
Broadcast from one member to all members of a group
l MPI_GATHER, MPI_IGATHER, MPI_GATHERV, MPI_IGATHERV
Gather data from all members of a group to one member
l MPI_SCATTER, MPI_ISCATTER, MPI_SCATTERV, MPI_ISCATTERV
Scatter data from one member to all members of a group
l MPI_ALLGATHER, MPI_IALLGATHER, MPI_ALLGATHERV, MPI_IALLGATHERV
A variation on Gather where all members of a group receive the result
l MPI_ALLTOALL, MPI_IALLTOALL, MPI_ALLTOALLV, MPI_IALLTOALLV,
MPI_ALLTOALLW, MPI_IALLTOALLW
Scatter/Gather data from all members to all members of a group
l MPI_ALLREDUCE, MPI_IALLREDUCE, MPI_REDUCE, MPI_IREDUCE
Global reduction operations such as sum, max, min, or user-defined functions, where the result is returned to all members of a group and a variation where the result is returned to only one member
l MPI_REDUCE_SCATTER_BLOCK, MPI_IREDUCE_SCATTER_BLOCK,
MPI_REDUCE_SCATTER, MPI_IREDUCE_SCATTER
A combined reduction and scatter operation
l MPI_SCAN, MPI_ISCAN, MPI_EXSCAN, MPI_IEXSCAN
Scan across all members of a group (also called prefix)
下面这些示意图应该可以帮助大家更好地理解上述这些MPI的功能:
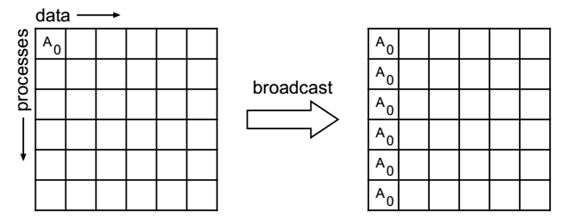
图 ‑ broadcast释义

图 ‑ scatter和gather释义
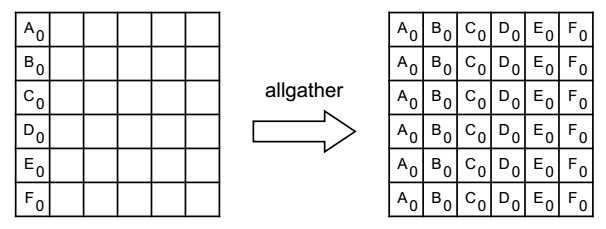
图 ‑ allgather释义
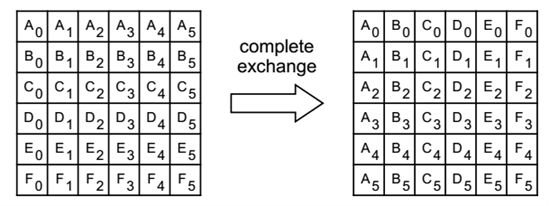
图 ‑ complete exchange释义
后续几个小节中讲解的内容,或多或少都会涉及到MPI的这些概念。希望大家可以补充必要的MPI基础知识,为进一步学习扫清障碍。
1.1.3 NCCL
NCCL是“NVidia Collective multi-GPU Communication Library”的缩写,从名称不难理解它是NVidia提供的一种多GPU之间collective communication(聚合通信)的库。
NCCL的初衷是降低多个GPU之间的通信成本,并尽可能提升GPU资源的利用率,从而保证GPU的扩展效能达到较好的水平。同时它还是NVidia的一个开源项目(至少NCCL 1.0是开源的),其github主页如下所示:
https://github.com/NVIDIA/nccl
NCCL在设计的过程中也借鉴了MPI的通信思想,因而熟悉MPI的开发人员应该可以比较快的上手NCCL编程。例如下图阐述的是NCCL中的all-reduce,可以看到和前面小节讲解的MPI中的概念是基本一致的:
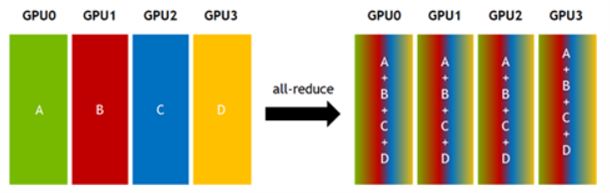
图 ‑ NCCL的all-reduce释义
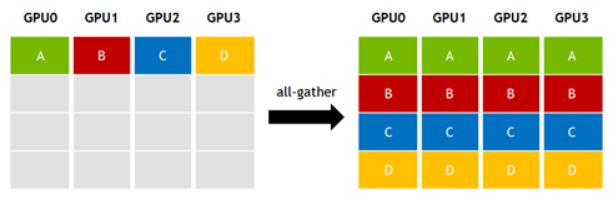
图 ‑ NCCL的all-gather释义

图 ‑ NCCL的broadcast释义
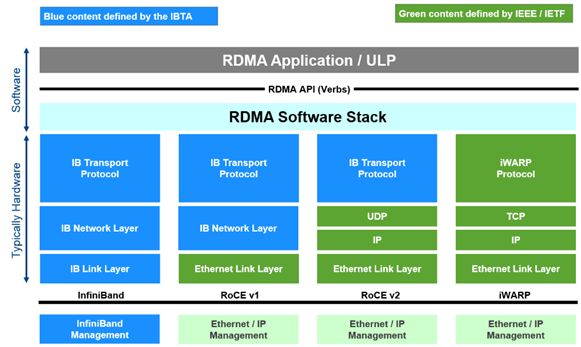
不难理解,GPU之间的Collective Communication与拓扑结构有很大关系。举个简单的例子,针对下面这样的PCIe拓扑结构:

图 ‑ 一个简单的PCIe拓扑结构
如果我们需要完成GPU0到其它节点的broadcast,那么至少有如下几种执行方案:
l 方案1
先从GPU0把消息发送到GPU2,然后GPU0和GPU2再各自把消息发送给GPU1和GPU3
l 方案2
先从GPU0把消息发送到GPU1,然后GPU0和GPU1再各自把消息发送给GPU2和GPU3
显然上述方案中比较有优势的是第1种,因为它完成broadcast任务的总路径相比于另一个方案要小。换句话说,方案1的性能更快。
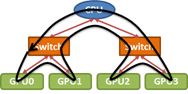
图 ‑ GPU Ring order
那么除了方案1,我们还有更好的选择吗?答案是肯定的。譬如上图所示的“Ring order of GPU”。在这种情况下,broadcast的信息会被切分为很多小块,然后在GPU环中进行“流动”。此时传输过程中的带宽利用率就有可能达到最佳水平——这种ring style collectives也是NVidia NCCL所采用的方式。
目前NCCL已经支持all-gather, all-reduce, broadcast, reduce, 和reduce-scatter等几种典型的collectives。使用NCCL也并不复杂,简单来讲就是引用nccl.h头文件以及它提供的库文件。很多机器学习框架都会考虑兼容NCCL,例如Caffe2项目中会通过USE_NCCL宏来控制是否要支持NCCL:
//include/caffe/util/Nccl.hpp
#ifndef CAFFE_UTIL_NCCL_H_
#define CAFFE_UTIL_NCCL_H_
#ifdef USE_NCCL
#include
#include "caffe/common.hpp"
#define NCCL_CHECK(condition) \
{ \
ncclResult_t result = condition; \
CHECK_EQ(result, ncclSuccess) << " " \
<< ncclGetErrorString(result); \
}
…
NCCL提供的API函数就是前面所讲的broadcast等几种collectives,例如:
//nccl.h
/* Copies count values from root to all other devices.
* Root specifies the source device in user-order
* (see ncclCommInit).
* Must be called separately for each communicator in communicator clique. */
ncclResult_t ncclBcast(void* buff, int count, ncclDataType_t datatype, int root,
ncclComm_t comm, cudaStream_t stream);
ncclResult_t pncclBcast(void* buff, int count, ncclDataType_t datatype, int root,
ncclComm_t comm, cudaStream_t stream);
在single-process机器上,我们只需要调用ncclCommInitAll进行初始化即可。而在multi-process的环境下,要求每个GPU都要调用ncclCommInitRank,后者会负责所有GPU资源之间的同步。下面这段代码是针对single-process环境的一个简单范例:
#include
typedef struct {
double* sendBuff;
double* recvBuff;
int size;
cudaStream_t stream;
} PerThreadData;
int main(int argc, char* argv[])
{
int nGPUs;
cudaGetDeviceCount(&nGPUs);
ncclComm_t* comms = (ncclComm_t*)malloc(sizeof(ncclComm_t)*nGPUs);
ncclCommInitAll(comms, nGPUs);
PerThreadData* data;
... // Allocate data and issue work to each GPU's
// perDevStream to populate the sendBuffs.
for(int i=0; i cudaSetDevice(i); ncclAllReduce(data[i].sendBuff, data[i].recvBuff, size, ncclDouble, ncclSum, comms[i], data[i].stream); } ... // Issue work into data[*].stream to consume buffers, etc. } 根据NVidia官方提供的数据显示,NCCL所带来的性能提升还是比较明显的,参考下面的图例所示: 图 ‑ NCCL性能测试数据 开发人员可以根据项目的实际情况选择是否支持NCCL,或者直接采用基于NCCL的一些机器学习框架。 1.1.4 NV-Link 我们知道,随着深度学习对计算资源诉求的日益增长,多GPU设备将成为常态。这样一来连接多个GPU的传统的PCIe总线就逐步成为了系统瓶颈,因而我们急需新型的多处理器互联技术。 NVidia自然也意识到了这个问题,并提出了NV-Link技术。 图 ‑ Tesla V100中以NVLink连接GPU 和GPU,以及GPU和 CPU 例如NVidia Tesla V100产品就采用了NVLink技术,将信号发送速率提升了20%以上。单个 NVIDIA Tesla® V100 GPU最高可支持多达六条 NVLink 链路,所以总带宽为 300 GB/秒,这个数据是PCIe 3带宽的10倍。 更为专业的8GPU服务器DGX-1V则是混合架构: 图 ‑ DGX-1V服务器采用混合立体网络拓扑,通过NVLink连接8个Tesla V100 总的来说,NVLink的出现提升了GPU和GPU、GPU和CPU之间的带宽,这在一定程度上缓解了数据传输的瓶颈。 图 ‑ NVLink的性能数据 当然,带宽得到提升的同时,也意味着硬件成本的增长,所以大家应该根据项目的实际需求来决定是否使用这些技术。 1.1.5 RDMA RDMA,即“Remote Direct Memory Access”是一种高性能的远程内存直接存取机制,主要用于满足某些网络通信场景(例如HPC、分布式深度学习等)中对于低延迟的诉求。学习过计算机原理的读者应该对DMA不会陌生——它指的是一种完全由特殊硬件(而不需要CPU全程参与,从而大幅降低CPU的负担,提升整体性能)来执行IO交换的数据访问机制。RDMA也是一种内存直接存取机制,不同之处在于它是在网络区域内跨不同机器实现的。 图 ‑ 传统网络通信需要经由CPU处理,这是性能无法提升的重要原因之一 业界根据RDMA不同的应用场景提出了多种具体的网络实现方案,包括Infiniband、RoCE、iWARP等等。 图 ‑ RDMA处理方式示意图 其中Infiniband可以从硬件级别来保证RDMA,所以性能是最好的;而后两者则是基于Ethernet实现的RDMA技术,虽然性能相对没有那么高,但成本上有较大优势。另外,RoCE的v1版本是基于以太网链路层实现的RDMA,而v2版本则基于UDP层实现。 图 ‑ 3种RDMA软件栈 引用自Mellanox公司的分享 从上图中不难发现——无论何种类型的RDMA,它们都可能向上层应用提供RDMA API Verbs接口,从而有效保证兼容性。