How Do Seq2Seq Models Perform on End-to-End Data-to-Text Generation?
一、论文来源及选读原因
1论文来源
- 发表会议:ACL2022
- 作者:Xunjian Yin,万小军
北京大学王选计算机研究所
北京大学计算语言学教育部重点实验室
2 选读原因
前段时间我打算看一下ACL2022中关于摘要生成方向的文章,选了几篇进行了下载。其中这篇的主要原因是论文名字十分有趣,从题目能够看出论文主要工作是对于seq2seq模型在端到端生成任务上进行了一个表现分析,并且采取了疑问句作为题目。
二、论文内容
不是对论文全部内容的翻译,主要记录我认为的重要内容!
摘要
在seq2seq在端到端的数据到文本生成已经十分普遍的情况下,虽然BLEU分数一直增加,但是model生成质量和人工编写的还是有明显差距的(很好理解的一个现象,计算机毕竟不能像人类一样思考,可能多少年后就可以了?)
本文采用多维质量度量(MQM)(两大类共八小类错误)评估几个代表性model。
对模型的输出分析统计是否出现三个级别错误(通过人工注释统计模型输出的生成文本错误情况,计算模型得分)
发现:
- 复制机制有助于改善遗漏和不准确的外部错误,但它会增加其他类型的错误,例如加法;
- 预训练技术高效,预训练策略和模型大小非常重要;
- 数据集的结构对模型的性能也有很大影响;
- 某些特定类型的错误通常对 seq2seq 模型具有挑战性。
1.介绍
数据到文本的生成是一项从非语言输入自动生成文本的任务(Gatt 和 Krahmer,2018 年)。输入可以是各种形式,例如记录数据库、电子表格、知识库、物理系统模拟。
基于精度的BLEU不能很好地评估模型。它过于粗粒度,无法反映模型性能的不同维度,并且并不总是与人类判断一致。而且,现有的人工评估通常受到样本大小,数据集、模型大小,评估维度的限制。
本文目标是基于多个数据集和评估维度对基于seq2seq的model进行彻底和可靠的手动评估。从股票个维度主要是在准确性和流畅性方面使用8个指标来计算错误。因此与现有的人工评估报告相比,它更具信息性和客观性。(安东尼是人工的评估方式本身就有很多缺点吧,耗时耗力,需要定义统一标准,注视者情况等)
本文对TRM,TRM with Pointer Generator,T5-small,T5-base,BART-base五个模型在E2E,WebNLG,WikiBio,ToTTo四个数据集进行评估

2.相关工作
里面有个注释写的因为计算资源有限,没有对T5-large和BART-large模型进行评估。比较好奇北京大学也没有这样的资源,在中国有多少学校具有这样的能力呢?
据我们所知,在全面评估 Seq2Seq 模型在数据到文本生成方面的性能方面几乎没有做任何工作。许多工作基于自动指标,例如 ROUGE 或 BLEU,这可能不同于人类评估,正如一些工作(Novikova 等人,2017a;Reiter,2018;Sulem 等人,2018)所示。因此,在数据到文本的任务中手动评估具有代表性的 Seq2Seq 模型是有意义的。
3.models datasets
我们在实验中使用了数据到文本任务中常用的数据集,包括 E2E、WebNLG、WikiBio 和 ToTTo。它们具有不同的形式和特点,可以对模型进行全面比较。这些数据到文本数据集的摘要如表 1 所示。
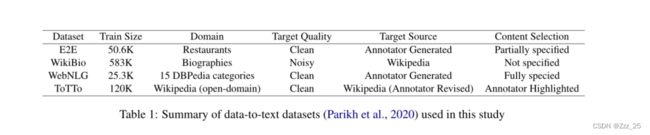
E2E
E2E 数据集 (Novikova et al., 2017b) 的输入是关于餐厅的信息,输出是它的自然语言描述。它由超过 50K 的组合组成,输出文本的平均长度为 8.1 个单词。
WikiBio
WikiBio (Lebret et al., 2016) 是一个包含超过 70K 示例的个人传记数据集。输入是来自维基百科的信息框,输出是传记的第一句话。输出文本的平均长度为 26.1 个单词。
WebNLG
WebNLG 挑战(Gardent 等人,2017 年)包括将 RDF 三元组映射到文本。最新的 WebNLG 数据集包含超过 40K 的数据-文本对。输出文本的平均长度为 22.3 个单词。
ToTTo
ToTTo (Parikh et al., 2020) 是一个开放域英语表格到文本数据集,具有超过 120,000 个训练示例,它提出了一个受控生成任务:给定一个 Wikipedia 表格和一组突出显示的表格单元格,生成一个单句描述。
4.评估方式
BLEU 是一种基于精度的度量标准,用于评估生成文本的质量,它被广泛用于数据到文本生成的工作。
多维质量指标 (MQM)(Mariana,2014 年)是一个用于描述和定义自定义翻译质量指标的框架。它定义了灵活的问题类型和生成质量分数的方法。基于 MQM,Huang 等人。 (2020)介绍了一种面向错误的细粒度人工评估方法PolyTope。它定义了五种关于准确性的问题类型、三种关于流畅性的问题类型、句法标签和三种错误严重性规则。请注意,我们不使用 PolyTope 中的句法标签,因为它们不是我们在本研究中评估的重点。我们评估维度的定义与 Huang 等人的非常相似。 (2020),但为了论文的完整性,更具体地说,为了 Data2Text 的任务,我们仍然在下面解释它们。
4.1 Issue Type
根据MQM原理,我们从准确性和流程性两个方面俩定义错误类型。
准确性(生成的文本不忠实于原始数据,或者没有完全反映原始数据中的关键信息)
- Addition 加法
生成的文本包含来自源数据的不必要和不相关的片段。 - Omission 疏忽
输出中不存在关键点。 - Inaccuracy Intrinsic 内在错误
原始数据中出现的内在术语或概念在输出中被扭曲。 - Inaccuracy Extrinsic 外在错误
生成的文本显示源数据中不存在的内容。 - Positive-Negative Aspect 正反面
生成的文本是正面的,而源数据代表负面的陈述,反之亦然。
流畅性(评估生成文本的语言质量,这是自然语言的主要要求)
- Duplication 重复
不必要地重复一个单词或文本的较长部分。 - Word Form 词形
与词形有关的问题,包括连贯性、词性、时态等。 - Word Order 词序
关于输出中单词顺序的问题。
4.2 Severity
- Minor
不影响内容可用性或可理解性的错误。例如,我们将虚词的重复视为一个错误,但这个错误不会影响对文本的理解,所以我们认为这个错误是Minor。 - Major
影响内容可用性或可理解性但不会使内容无法使用的错误。例如,我们认为额外的属性不会使内容不适合目的,尽管它可能会导致读者做出额外的努力来理解预期的含义。 - Critical
使内容完全不适合使用的错误。每种错误类型在太严重时都会使文本完全无法使用。例如,当句子中的关键元素缺失或错误过多而误导人们的理解时,我们认为这个错误是关键。
4.3 Calculation
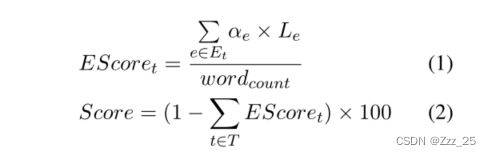 其中 T 是错误类型的集合,Et 是类型 t 的所有错误段的集合。 αe 是按 1:3:7 设置的三个严重级别的扣除比率:Minor、Major 和 Critical。 Le是error3的字长。 wordcount 是样本中的单词总数。我们可以看到,如果句子没有错误,系统性能得分最高可以达到 100,并且越高越好。通过这种方法,我们可以得到Score,每个模型的整体评价,以及错误分数EScoret,表示每种错误类型对整体分数的惩罚。
其中 T 是错误类型的集合,Et 是类型 t 的所有错误段的集合。 αe 是按 1:3:7 设置的三个严重级别的扣除比率:Minor、Major 和 Critical。 Le是error3的字长。 wordcount 是样本中的单词总数。我们可以看到,如果句子没有错误,系统性能得分最高可以达到 100,并且越高越好。通过这种方法,我们可以得到Score,每个模型的整体评价,以及错误分数EScoret,表示每种错误类型对整体分数的惩罚。
4.4 Human Annotation
对注释者进行怎样的培训
5.结果分析
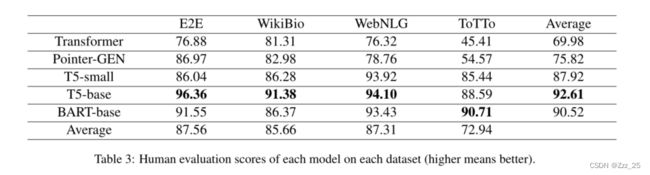
Copy Mecahnism 和 预训练 具有里程碑意义
复制机制 可以用复制概率修改词汇级别概率,减少对先前输出的依赖。但是自回归解码器倾向于从源中复制较长的序列,并且很难中断复制操作,Addition 错误略有增加
6.BLEU or Human Evaluation?
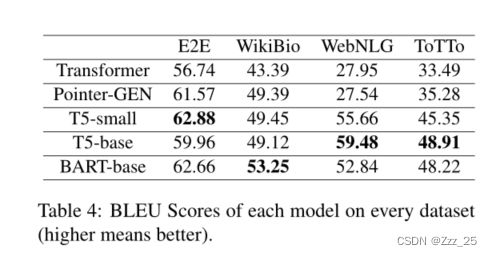
BLEU 和 人工评价整体趋势是一致的,基本可以反映模型的整体表现。
尽管我们的主要目标不是推广人工评估指标,但我们的带有人工注释的数据集为我们提供了一个测试平台来分析自动指标和人工指标之间的相关性和差异。
指出很多人对BLEU指标的不可靠性进行了讨论。
BLEU既不能反映语法,也不能反应the menaning of preservation
7.总结
我们使用基于 MQM 的一组细粒度的人工评估指标,在数据到文本任务中经验性地比较了五个具有代表性的 Seq2Seq 模型。我们的目标是对数据到文本任务的端到端 Seq2Seq 模型进行系统和全面的评估和分析。我们分析了里程碑技术(如复制和预训练)的影响、数据集和模型大小的影响以及模型在不同类型错误方面的性能。我们的评估表明,预训练模型可以生成非常好的文本。但这项任务仍有很大的改进空间。此外,对遗漏误差和不准确固有误差等具体误差的改进也值得未来探索。
三、Think
本文提出一种全面的人工评价方式对五个模型在四个数据集上进行了实验对比。虽然人工评注的方式并没有机器评估省时省力,但是这种评估方式能够指出模型生成的文本潜在语义层次的错误。
介绍和相关工作内容挺多重复的。。。
重点是文中对生成的样本错误进行了分类,这个很不错!几类错误明确分析了现在模型生成的问题所在
