Gavin老师Transformer直播课感悟 - Rasa对话机器人项目实战之教育领域Education Bot项目NLU Pipeline、Dialogue Policies、及多意图识别(七十)
本文继续围绕工业级业务对话平台和框架Rasa,对Rasa对话机器人项目实战之教育领域Education Bot项目NLU Pipeline的各个组件、Dialogue Policies使用的组件,以及多意图识别及对话管理等方面进行详细分析。

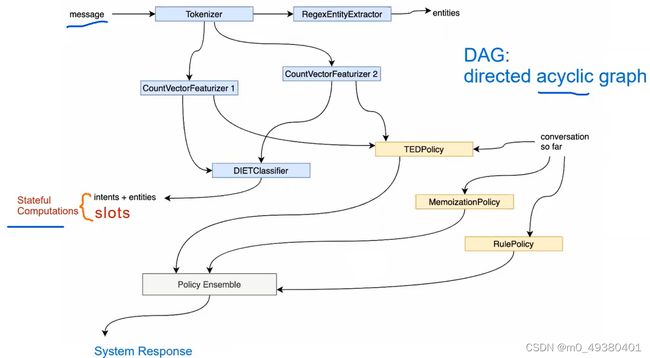
一、Rasa对话机器人项目实战之教育领域Education Bot项目NLU Pipeline、Dialogue Policies、及多意图识别及对话管理解密
- Rasa Architecture视角下Agent与NLU Pipeline、Dialogue Policies交互关系解析
一个对话系统主要就是围绕用户意图(intent),对话状态(state),微服务(action)三者之间的交互来展开的。Intent需要通过NLU Pipeline定义的一系列组件来进行识别,之后转交Dialogue Policies组件来预测对话机器人接下来的行为是什么,而在进行对话业务处理时我们通常需要借助于微服务action。在对话过程中会基于用户输入得到的intent和entities来影响对话状态,譬如调用微服务后可以通过触发事件来更新tracker中的状态。
2. Education Bot项目NLU Pipeline逐个组件解析
这是定义在config中的pipeline,其中包含了各个NLU组件,通常它们之间存在一定的依赖关系:

从Rasa DAG架构图中可以看到,这些组件可以有依赖关系,也可以并行运行,policies依赖于状态或者上下文来进行action的预测,而状态会受到NLU组件如DIETClassifier所产出的intents和entities的影响。
WhitespaceTokenizer:
用于从以空格分割的字符串中提取token。通常用于英文,token_pattern指定了匹配token所使用的正则表达式。
RegexFeaturizer:
当使用RegexFeaturizer时,并不是把正则表达式作为rule来对意图进行分类,它只提供一个特征给意图分类器(譬如DIETClassifier)用于学习意图分类的方式(patterns)。目前所有的意图分类器都利用可用的正则表达式特征进行意图分类。一个正则表达式的名称是易读的,从而帮助人们记忆它的用途,这个名称不需要匹配任何意图或者实体名称。
lookup tables可以和RegexFeaturizer结合在一起使用,需要提供足够的你想要匹配的intent或者entity的训练数据以便模型能够学习使用正则表达式作为一个特征。
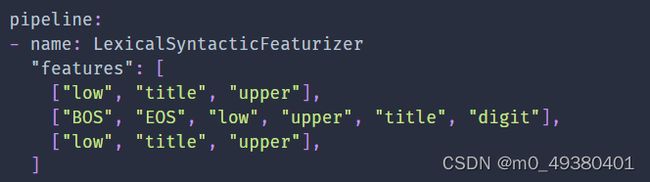
LexicalSyntacticFeaturizer:
根据用户输入创建语言层面的feature来支持实体提取,输出是sparse features。由于存在默认配置,所以不需要额外指定配置,也可以根据需要指定配置,样例如下:
CountVectorsFeaturizer:
用来根据词汇计数的方式为意图分类和response选择创建features,即创建用户输入消息,intent,response所对应的bag-of-words的表示。在pipeline中配置了基于token级别和基于characater级别的两个CountVectorsFeaturizer,其中token级别的CountVectorsFeaturizer配置了OOV_token参数,用于指定“不可见”词汇(在vocabulary之外的词汇)对应的关键字,如果训练数据中包含有“不可见”词汇,那么在预测时:
-如果OOV_token的值不为None,则这些词汇就会被OOV_token所指定的值所替换
-如果OOV_token=None,则这些词汇会被忽略掉
而基于character级别的CountVectorsFeaturizer有两个n-grams相关的参数,即n-grams的上下边界。另外一个参数analyzer可以设置为char或者char_wb。
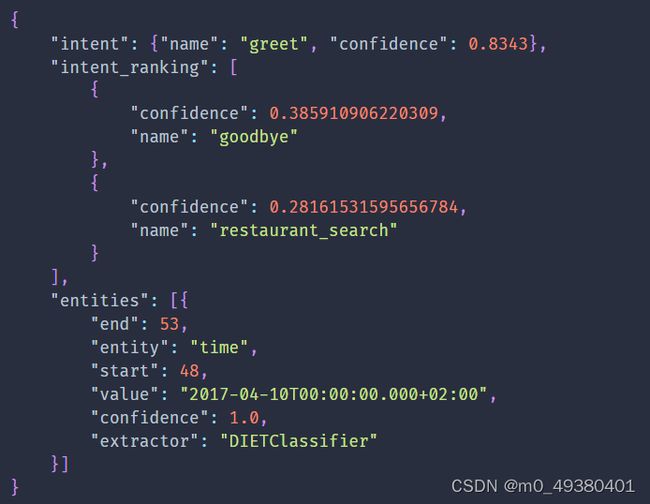
DIETClassifier:
用于意图分类和实体提取,这里的参数ranking_length用于设定在intent_ranking列表中需要展示排名最靠前的多少个intents。以下是示例:
EntitySynonymMapper:
EntitySynonymMapper会根据训练数据把提取的entities映射为定义好的synonyms。以下是样例:

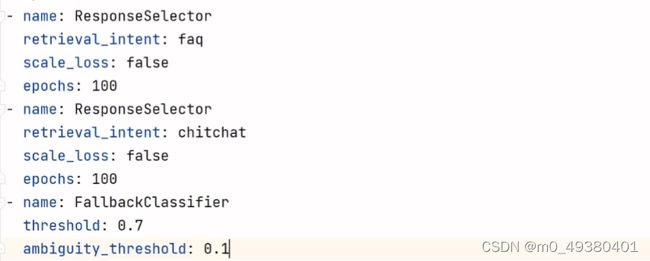
ResponseSelector:
用于常见问答或者闲聊的场景,根据retrieval intent来识别对应的response selector,而每个selector具有两个属性:response和ranking,最后会根据ranking中的confidence来选择最高的confidence所对应的response。下面是示例:

FallbackClassifier:
FallbackClassifier通常在以下两种情况下使用:
-intent预测的confidence低于设定的threshold值
-排名前2位的confidence的差值低于设定的ambiguity_threshold
下面的例子显示FallbackClassifier根据用户输入识别到intent为nlu_fallback:
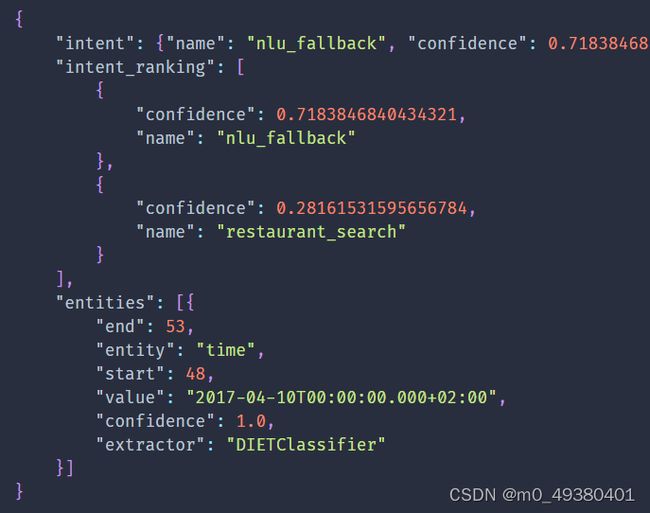
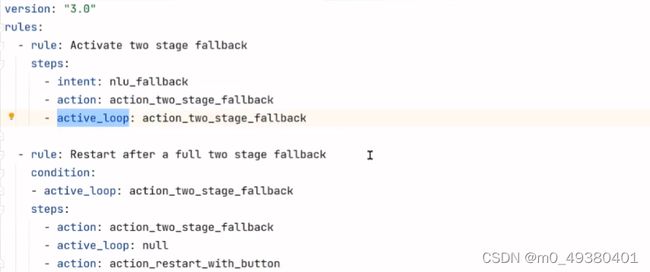
你可以使用FallbackClassifier来触发一个fallback action,譬如在这个项目中配置了相关的rules:
3. Education Bot项目Dialogue Policies逐个组件解析
这是policies的配置:

RulePolicy:
当预测低于fallback设定的threshold时,就会触发对应的fallback action。
AugmentedMemoizationPolicy:
这种policy具有“遗忘机制”,会根据对话turn的内容与stories中的数据在忽略一些内容的前提下进行匹配,如果匹配成功则直接返回预测的action,confidence为1.0;如果没有找到匹配结果,则预测结果为None,confidence为0.0。这里的参数max_history指定在预测时需要参考stories训练数据中的多少个对话turns。
TEDPolicy:
这是基于机器学习的policy,使用了TED模型来进行预测。这里的参数max_history指定了需要使用stories训练数据中的多少个对话turns来进行训练,可以考虑在max_history的基础上如何拆分为更短的turns组合来进行训练,以及正负样本的选择等。
4. Rasa中Multi-Intent多意图Classifier分类器工作原理和流程解析
当用户输入的内容涉及到多个业务场景时或者具有前后内容有关联关系时,可以考虑使用多意图,大致分为两类:
-多个意图之间是平级的,譬如:check_balances+transfer_money,
-多个意图之间构成等级结构,譬如:feedback+positive或者feedback+negative
下面的NLU样例定义了:
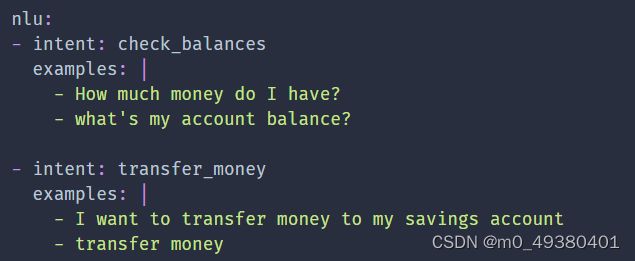
而用户输入信息为:How much money do I have? I want to transfer some to savings.
针对多意图的情况,需要在训练数据中加入明确的由多个意图组合的例子,否则模型很难进行意图组合的预测。为了防止出现过多的不可控制的意图组合情况,需要根据用户实际对话来在训练数据中只包括必需的多意图组合。
无论使用哪一个tokenizer,需要定义以下属性:
intent_tokenization_flag
intent_split_symbol
以下是配置示例:

5. Rasa中Multi-Intent多意图Dialogue Management处理机制及实例剖析
在对话管理中有两种方式来使用多意图:
-为多意图添加rules或者stories,例如为每一个intent添加一个rule:

然后再添加一个rule用于意图组合,并指定多个actions执行序列来对应这个组合:

-允许机器学习的policy可以基于单意图的stories训练数据通过训练具有处理多意图场景的泛化能力,在这种情况下,使用multi-hot encoding来提取intent的特征,这就意味着使用check_balances+transfer_money提取特征而不是针对每个intent提取特征。虽然TEDPolicy在stories中没有明确存在多意图组合训练数据的情况下也可以基于多意图来进行预测,但是最好的做法是明确指定story或者rule来处理多意图的情况。