Elasticsearch详解
公司最近需要用到Elasticsearch,于是抱着学习的态度写一篇文章:
首先我们了解下基础知识
ElasticSearch是什么
ElasticSearch是智能搜索,分布式的搜索引擎。是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana
(1)E:EalsticSearch 搜索和分析的功能
(2)L:Logstach 搜集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统
(3)K:Kibana 数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台
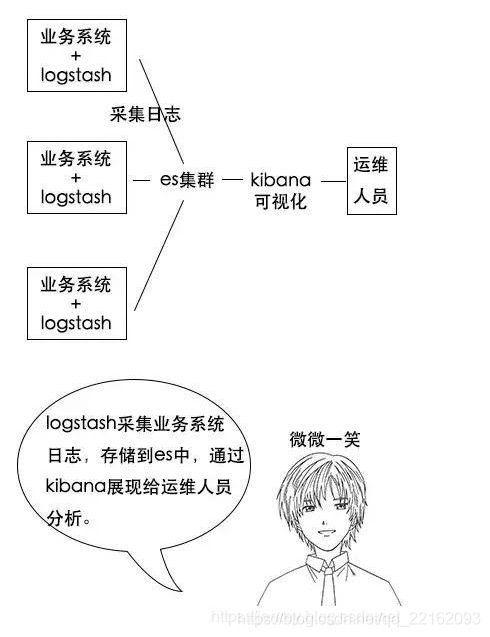
分析日志的用处:假如一个分布式系统有 1000 台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,是不是非常麻烦?
但是如果日志接入了 ELK 系统就不一样。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入 ELK 系统中,我们直接在 Kibana 就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。
这都依赖ES强大的反向索引功能,这样我们根据关键字就能查询到关键的错误日志了。
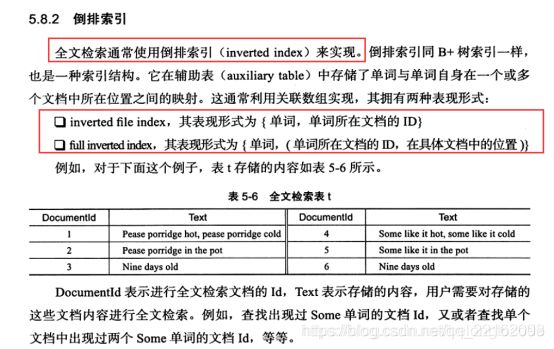
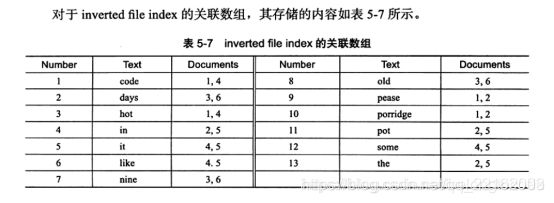
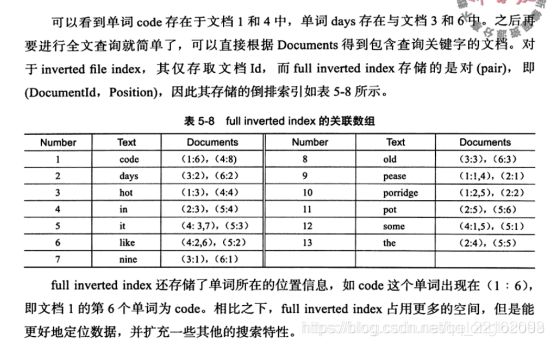
全文索引和倒排索引:
ElasticSearch的架构
节点类型
1. 候选主节点(Master-eligible node)
一个节点启动后,就会使用Zen Discovery机制去寻找集群中的其他节点,并与之建立连接。集群中会从候选主节点中选举出一个主节点,主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。Elasticsearch中的主节点的工作量相对较轻,用户的请求可以发往任何一个节点,由该节点负责分发和返回结果,而不需要经过主节点转发。
正常情况下,集群中的所有节点,应该对主节点的选择是一致的,即一个集群中只有一个选举出来的主节点。然而,在某些情况下,比如网络通信出现问题、主节点因为负载过大停止响应等等,就会导致重新选举主节点,此时可能会出现集群中有多个主节点的现象,即节点对集群状态的认知不一致,称之为脑裂现象。为了尽量避免此种情况的出现,可以通过discovery.zen.minimum_master_nodes来设置最少可工作的候选主节点个数,建议设置为(候选主节点数 / 2) + 1, 比如,当有三个候选主节点时,该配置项的值为(3/2)+1=2,也就是保证集群中有半数以上的候选主节点。
候选主节点的设置方法是设置node.mater为true,默认情况下,node.mater和node.data的值都为true,即该节点既可以做候选主节点也可以做数据节点。由于数据节点承载了数据的操作,负载通常都很高,所以随着集群的扩大,建议将二者分离,设置专用的候选主节点。当我们设置node.data为false,就将节点设置为专用的候选主节点了。
node.master = true
node.data = false
2. 数据节点(Data node)
数据节点负责数据的存储和相关具体操作,比如CRUD、搜索、聚合。所以,数据节点对机器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统CPU、Memory和IO的性能消耗都很大。通常随着集群的扩大,需要增加更多的数据节点来提高可用性。
前面提到默认情况下节点既可以做候选主节点也可以做数据节点,但是数据节点的负载较重,所以需要考虑将二者分离开,设置专用的数据节点,避免因数据节点负载重导致主节点不响应。
node.master = false
node.data = true
3. 客户端节点(Client node)
按照官方的介绍,客户端节点就是既不做候选主节点也不做数据节点的节点,只负责请求的分发、汇总等等,也就是下面要说到的协调节点的角色。这样的工作,其实任何一个节点都可以完成,单独增加这样的节点更多是为了负载均衡。
node.master = false
node.data = false
4. 协调节点(Coordinating node)
协调节点,是一种角色,而不是真实的Elasticsearch的节点,你没有办法通过配置项来配置哪个节点为协调节点。集群中的任何节点,都可以充当协调节点的角色。当一个节点A收到用户的查询请求后,会把查询子句分发到其它的节点,然后合并各个节点返回的查询结果,最后返回一个完整的数据集给用户。在这个过程中,节点A扮演的就是协调节点的角色。毫无疑问,协调节点会对CPU、Memory要求比较高。
分片与集群状态
分片(Shard),是Elasticsearch中的最小存储单元。一个索引(Index)中的数据通常会分散存储在多个分片中,而这些分片可能在同一台机器,也可能分散在多台机器中。这样做的优势是有利于水平扩展,解决单台机器磁盘空间和性能有限的问题,试想一下如果有几十TB的数据都存储同一台机器,那么存储空间和访问时的性能消耗都是问题。
1:当新建一个索引库时,可以预先设置其会被分为N个分片(主分片),同时可以为每个主分片产生N个备份分片(副分片)。
2:N个主分片随机分布在集群的多个节点中;N个副分片也是随机的分布在集群的多个节点中,但是副分片和其主分片不会在一个节点上。
ES索引中主副分片的作用:
1:当在该索引库中新增一个文档时,会通过计算该文档ID的哈希值来决定将该文档存储到哪个主分片上;随后会将该操作同步到该主分片的所有副本分片上,做到主副数据的一致。(主从复制的过程由ES自身完成)
2:当在该索引库中修改或者删除一个文档时,根据文档ID找到文档所在的主分片,并进行操作;随后会将该操作同步到该主分片的所有副本分片上,做到主副数据的一致。(主从复制的过程由ES自身完成)
3:当搜索索引中的文档时,每次都会从主分片和副分片中选择一套完整的分片来组合成一个索引,以供搜索,而且每次搜索请求主副的组合可能不一样;这样当并发搜索很多时,就可以把压力分散在多个节点上,做到负载均衡。(提高了搜索性能/并发吞吐量)(读写请求的分发也是由ES自身完成的)
4:当集群中某个节点宕机,该节点上所有分片中的数据全部丢失(既有主分片,又有副分片);丢失的副分片对数据的完整性没有影响,丢失的主分片在其他节点上的副分片就会自动变成主分片;所以整个索引的数据完整性没有被破坏。(提高了容错性/容灾性)
Elasticsearch计算分片位置的公式:
shard = hash(routing) % number_of_primary_shards
解释:routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
所以说主分片的数量不会改变,,因为如果改变了,文档就找不到了。
默认情况下,Elasticsearch会为每个索引分配5个分片,但是这并不代表你必须使用5个分片,同时也不说分片越多性能就越好。一切都取决对你的数据量的评估和权衡。虽然跨分片查询是并行的,但是请求分发、结果合并都是需要消耗性能和时间的,所以在数据量较小的情况下,将数据分散到多个分片中反而会降低效率。
关于多分片与多索引的问题。一个索引可以有多个分片来完成存储,但是主分片的数量是在索引创建时就指定好的,且无法修改,所以尽量不要只为数据存储建立一个索引,否则后面数据膨胀时就无法调整了。笔者的建议是对于同一类型的数据,根据时间来分拆索引,比如一周建一个索引,具体取决于数据增长速度。
上面说的是主分片(Primary Shard),为了提高服务可靠性和容灾能力,通常还会分配复制分片(Replica Shard)来增加数据冗余性。比如设置复制分片的数量为1时,就会对每个主分片做一个备份。
通过API( http://localhost:9200/_cluster/health?pretty )可以查看集群的状态,通常集群的状态分为三种:
Red,表示有主分片没有分配,某些数据不可用。
Yellow,表示主分片都已分配,数据都可用,但是有复制分片没有分配。
Green,表示主分片和复制分片都已分配,一切正常。
事实可以发送请求到集群中的任一节点。 每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。
新建、索引和删除 请求都是 写 操作, 必须在主分片上面完成之后才能被复制到相关的副本分片。
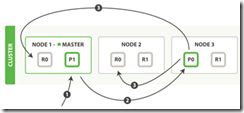
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
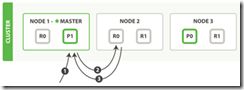
局部更新文档update API 结合了先前说明的读取和写入模式 。
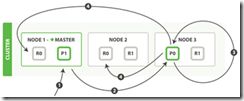
查询阶段
查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的 _优先队列_。
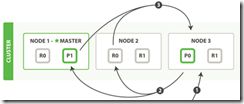
客户端发送一个 search 请求到 Node 3 , Node 3 会创建一个大小为 from + size 的空优先队列。
Node 3 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from + size 的本地有序优先队列中。
每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是 Node 3 ,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
分片返回一个轻量级的结果列表到协调节点,它仅包含文档 ID 集合以及任何排序需要用到的值,例如 _score 。
取回阶段
取回阶段,查询阶段标识哪些文档满足 搜索请求,但是我们仍然需要取回这些文档。
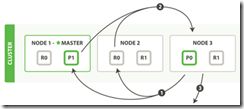
1、协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。
2、每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。
3、一旦所有的文档都被取回了,协调节点返回结果给客户端。