转载:https://blog.csdn.net/qq_34190023/article/details/82999702
html转换为pdf的关键技术是如何处理网页中复杂的css样式、以及中文乱码处理。
各实现对比表
于Windows平台进行测试:
| 基于IText |
基于FlyingSaucer |
基于WKHtmlToPdf |
基于pd4ml |
||
| 跨平台性 |
跨平台 |
跨平台 |
跨平台 |
跨平台 |
|
| 是否安装软件 |
否 |
否 |
需安装WKHtmlToPdf |
否 |
|
| 是否收费 |
免费 |
免费 |
免费 |
收费 |
|
| 转换Html |
效率 |
速度快 |
未测 |
速度慢。相比URL来说,效率较慢。能忽略一些html语法或资源是否存在问题。 |
速度快。部分CSS样式不支持。 |
| 效果 |
存在样式失真问题。 对html语法有一定要求 |
存在样式失真问题。对html语法有较高要求。 |
失真情况较小 大部分网页能按Chome浏览器显示的页面转 |
部分CSS样式有问题。 |
|
| 转换URL |
效率 |
未测 |
未测 |
效率不是特别高 |
未测 |
| 效果 |
未测 |
未测 |
部分网页由于其限制,或将出现html网页不完整。 |
未测 |
|
| 优点 |
不需安装软件、转换速度快 |
不需安装软件、转换速度快 |
生成PDF质量高 |
不需要安装软件、转换速度快 |
|
| 缺点 |
对html标签严格,少一个结束标签就会报错; 服务器需要安装字体 |
对html标签严格,少一个结束标签就会报错; 服务器需要安装字体 |
需要安装软件、时间效率不高 |
对部分CSS样式不支持。 |
|
| 评价 |
|||||
综合:使用WKHtmlToPdf效果(样式)最好。但速度较慢(对于文件来说)。其余均有大大小小的失真问题。
| 分页 |
图片 |
表格 |
链接 |
中文 |
特殊字符 |
整体样式 |
速度 |
|
| IText |
支持 |
支持 |
支持 |
支持 |
支持 |
支持 |
失真问题 |
快 |
| FlyingSaucer |
未知 |
未知 |
未知 |
未知 |
未知 |
未知 |
未知 |
快 |
| WKHtmlToPdf |
支持 |
支持 |
支持 |
支持 |
支持 |
支持 |
很好 |
慢 |
| pd4ml |
支持 |
支持 |
支持 |
支持 |
支持 |
支持 |
失真问题 |
快 |
html网页完整转换为pdf,所有的方案均有不足。
itext有时并不能满足需求,不能兼容html的样式,且从html页面导出的图片到pdf中也并不好处理。
Flying Sauser实现html2pdf,纠错能力差,支持多种中文字体(部分样式不能识别),且对html的格式也是十分的严格,如果用一种模版的话用Flying Sauser技术倒是不错的选择,但对于不规则的html导出pdf就并不是那么的适用。
PD4ML实现html2pdf,速度快,纠错能力强可以过滤不规则的html标记,支持多种中文字体,支持css。
WKHtmlToPdf效果最好,但转换速度慢。
1. wkhtmltopdf(速度慢、需要安装软件)
wkhtmltopdf是一个用webkit网页渲染引擎开发的用来将html转成 pdf的工具,可跟多种脚本语言进行集成来转换文档,有windows、linux等平台版本。官网地址 http://wkhtmltopdf.org/
技术特点:
Wkhtmltopdf可直接把浏览器中浏览的网页转换成一个pdf,他是一个把html页面转换成pdf的软件(需要安装在服务器上)。使用时可通过java代码调用cmd指令完成网页转换为pdf的功能。
功能测试:
直接在cmd里输入测试指令,可查看处理进度。
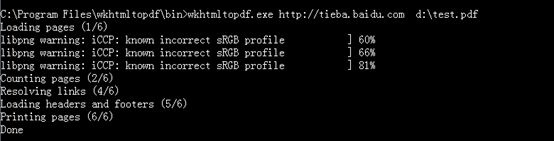
原理:
使用wkhtmltopdf工具对url或html进行转换
使用命令:
Wkhtmltopdf https:baidu.com /usr/local/temp/baidu.pdf
安装
下载地址:https://wkhtmltopdf.org/downloads.html
wkhtmltopdf安装方法
1.解压wkhtmltox.tar到某个文件夹$DIR
2.设置环境变量
vim /etc/profile
在最后一行加 export PATH=$DIR/wkhtmltox/bin:$PATH 保存退出、

source /etc/profile
3.运行 wkhtmltopdf 报wkhtmltopdf: error while loading shared libraries: libXrender.so.1: cannot open shared object file: No such file or directory这个错,请运行 apt-get/yum install libXrender*
运行 wkhtmltopdf 报wkhtmltopdf: error while loading shared libraries: libfontconfig.so.1: cannot open shared object file: No such file or directory这个错,请运行apt-get/yum install libfontconfig*
运行 wkhtmltopdf 报wkhtmltopdf: error while loading shared libraries: libXext.so.6: cannot open shared object file: No such file or directory这个错,请运行 apt-get/yum install libXext*
运行 wkhtmltopdf
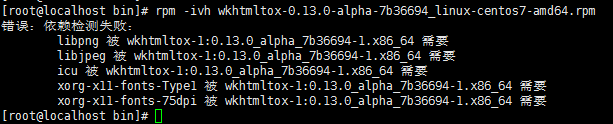
yum install xorg-x11-fonts-75dpi.noarch
yum install xorg-x11-fonts-Type1.noarch
yum install icu.x86_64
yum install libjpeg
yum install libpng
优点:
支持中文、图片、CSS等
缺点:
有时对于html文件的转化可能比较慢,对于url的转化速度较快。存在失真情况
具体实现:
Java调用命令。
1 public class HtmlToPdf {
2
3 // wkhtmltopdf在系统中的路径
4 private static String toPdfTool = Consts.WEB.CONVERSION_PLUGSTOOL_PATH_WINDOW;
5
6 /**
7 * html转pdf
8 *
9 * @param srcPath
10 * html路径,可以是硬盘上的路径,也可以是网络路径
11 * @param destPath
12 * pdf保存路径
13 * @return 转换成功返回true
14 */
15 public static boolean convert(String srcPath, String destPath) {
16 File file = new File(destPath);
17 File parent = file.getParentFile();
18 // 如果pdf保存路径不存在,则创建路径
19 if (!parent.exists()) {
20 parent.mkdirs();
21 }
22 StringBuilder cmd = new StringBuilder();
23 if (System.getProperty("os.name").indexOf("Windows") == -1) {
24 // 非windows 系统
25 toPdfTool = Consts.WEB.CONVERSION_PLUGSTOOL_PATH_LINUX;
26 }
27 cmd.append(toPdfTool);
28 cmd.append(" ");
29 cmd.append(" \"");
30 cmd.append(srcPath);
31 cmd.append("\" ");
32 cmd.append(" ");
33 cmd.append(destPath);
34
35 System.out.println(cmd.toString());
36 boolean result = true;
37 try {
38 Process proc = Runtime.getRuntime().exec(cmd.toString());
39 HtmlToPdfInterceptor error = new HtmlToPdfInterceptor(proc.getErrorStream());
40 HtmlToPdfInterceptor output = new HtmlToPdfInterceptor(proc.getInputStream());
41 error.start();
42 output.start();
43 proc.waitFor();
44 } catch (Exception e) {
45 result = false;
46 e.printStackTrace();
47 }
48
49 return result;
50 }
51
52 public static void main(String[] args) {
53 // HtmlToPdf.convert("http://www.baidu.com", "F:/pdf/baidu.pdf");
54 String filename = "JAVA将图片转换成pdf文件-CSDN博客";
55 HtmlToPdf.convert("F:/pdf/"+filename+".html", "F:/pdf/"+filename+".pdf");
56 // HtmlToPdf.convert("http://api.gyingyuan.com/", "F:/pdf/"+ UUID.randomUUID().toString()+".pdf");
57 // HtmlToPdf.convert("https://www.aliyun.com/jiaocheng/285649.html", "F:/pdf/baidu.pdf");
58 }
59 }
1 public class HtmlToPdfInterceptor extends Thread {
2 private InputStream is;
3
4 public HtmlToPdfInterceptor(InputStream is){
5 this.is = is;
6 }
7
8 @Override
9 public void run(){
10 try{
11 InputStreamReader isr = new InputStreamReader(is, "utf-8");
12 BufferedReader br = new BufferedReader(isr);
13 String line = null;
14 while ((line = br.readLine()) != null) {
15 System.out.println(line.toString()); //输出内容
16 }
17 }catch (IOException e){
18 e.printStackTrace();
19 }
20 }
21 }
效果:
URL转换


对于url转会遇到一些网站限制的问题。
https://blog.csdn.net/m0_38138387/article/details/79314260
如果转为html则效率较慢,但能很大程度比较完美地转换
文件转换:速度较慢,失真情况比较小
68.225s
2. PhantomJS(样式有问题,需要安装软件)
PhantomJS是一个基于webkit内核的无头浏览器,即没有UI界面,即它是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现。它提供javaScript API接口,即通过编写JS程序可以直接与webkit内核交互,在此之上可以结合java语言等,通过java调用js等相关操作,从而解决了以前c/c++才能比较好的基于webkit开发优质采集器的限制。它同时提供windows、linux、mac等不同os的安装使用包,也就是说可以在不同平台上二次开发采集项目或是自动项目测试等工作。官网地址http://phantomjs.org/
PhantomJS可做网页分析,功能很多,本次仅调用网页的截图功能。在cmd中的测试如下:


URL转

测试效果并没有wkhtmltopdf好。
html2pdf.js
1 var page = require('webpage').create();
2 var system = require('system');
3
4 读取命令行参数,也就是js文件路径。
5 if (system.args.length === 1) {
6 console.log('Usage: loadspeed.js ');
7 //这行代码很重要。凡是结束必须调用。否则phantomjs不会停止
8 phantom.exit();
9 }
10 page.settings.loadImages = true; //加载图片
11 page.settings.resourceTimeout = 30000;//超过10秒放弃加载
12 //截图设置,
13 //page.viewportSize = {
14 // width: 1000,
15 // height: 3000
16 //};
17 var address = system.args[1];
18 page.open(address, function(status) {
19
20 function checkReadyState() {//等待加载完成将页面生成pdf
21 setTimeout(function () {
22 var readyState = page.evaluate(function () {
23 return document.readyState;
24 });
25
26 if ("complete" === readyState) {
27
28 page.paperSize = { width:'297mm',height:'500mm',orientation: 'portrait',border: '1cm' };
29 var timestamp = Date.parse(new Date());
30 var pdfname = 'HT_'+timestamp + Math.floor(Math.random()*1000000);
31 var outpathstr = "E:/POMFiles/HTPDF/"+pdfname+".pdf";
32 page.render(outpathstr);
33 //page.render("c://test.png");
34 //console.log就是传输回去的内容。
35 console.log("生成成功");
36 console.log("$"+outpathstr+"$");
37 phantom.exit();
38
39 } else {
40 checkReadyState();
41 }
42 },1000);
43 }
44 checkReadyState();
45 });
PhantomJS对bootstap的样式支持较好。对css3的新特性如圆形图片样式支持行不好。部分页面样式会失效。对于echart图表展示,也可直接导出
3. IText(技术老旧,对样式不支持)
iText是一个第三方报表java插件,可以在后端利用java随意生成、转化pdf文件,提供了很多api,比较灵活
IText实现html2pdf,速度快,纠错能力差,支持中文(要求HTML使用unicode编码),但中支持一种中文字体,开源。
原理:
使用IText将HTML文件转化为PDF文件
优点:
速度快,支持中文(要求HTML使用unicode编码)、开源
缺点:
纠错能力差,
对CSS样式支持不是很好。
失真情况可能比较大
具体实现:
org.eclipse.birt.runtime.3_7_1
com.lowagie.text
2.1.7
org.xhtmlrenderer
flying-saucer-pdf
9.0.8
com.itextpdf
itextpdf
5.4.2
Java代码
1 ITextRenderer renderer = new ITextRenderer();
2 ITextFontResolver fontResolver = renderer.getFontResolver();
3 fontResolver.addFont("/Users/hehe/share/Fonts/simsun.ttc", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
4 OutputStream os = new FileOutputStream("/Users/hehe/Desktop/iTextPDF.pdf");
5 String htmlstr = HttpHandler.sendGet("http://localhost:10086/test/iTextPDF.html");//HttpHandler.sendGet只是单纯获得指定网页的html字符串内容
6 renderer.setDocumentFromString(htmlstr);
7 renderer.layout();
8 renderer.createPDF(os);
以上只是简单利用html字符串来生成pdf,需要注意的是:
1、如果页面中有中文,服务器端需要下载字体库simsun.ttc,在后台进行引用,同时在页面的样式中加入对应字体的定义,如:body{font-family: SimSun;},否则中文无法渲染(中文处渲染出来的效果是空白);
2、页面中如果有图片,如果图片引用是绝对路径或者base64则不用考虑,如果是相对路径,需要在后台用renderer.getSharedContext().setBaseURL("图片绝对路径目录");来指定图片路径,否则图片无法渲染。
3、要转化的页面必须是标准的XHTML页面,有一处不符合规范就会报错,小编再试的时候就经常报诸如org.xml.sax.SAXParseException;lineNumber: 24; columnNumber: 6;元素类型 "span" 必须由匹配的结束标记 " 终止"之类的错误,所以如果要用iText来大量爬取网络中的页面的话,还是放弃吧,毕竟网上很多页面都是不标准的~
1 public class HtmlToPdfUtils {
2 /*** 默认中文字体 */
3 private static final String FONT = "C:\\Windows\\Fonts\\simhei.ttf";
4 public static void htmlToPdf(String sourcePath,String tagetPath) throws IOException {
5 htmlToPdf(sourcePath,tagetPath,FONT);
6 }
7 public static void htmlToPdf(String sourcePath,String tagetPath,String fontPath) throws IOException {
8 htmlToPdf(sourcePath,tagetPath,fontPath,PageSize.TABLOID);
9 }
10 public static void htmlToPdf(String sourcePath,String tagetPath,String fontPath,PageSize pageSize) throws IOException {
11 // 默认source路径下装载有css、image、以及html等文件的文件夹
12 htmlToPdf(sourcePath,tagetPath,fontPath,pageSize,FileUtils.GetFilePath(sourcePath));
13 }
14 public static void htmlToPdf(String sourcePath,String tagetPath,String fontPath,PageSize pageSize,String baseuri) throws IOException {
15 PdfWriter writer = new PdfWriter(tagetPath);
16 PdfDocument pdf = new PdfDocument(writer);
17
18 pdf.setTagged();
19 // 设置pdf页面大小
20 pdf.setDefaultPageSize(pageSize);
21 ConverterProperties properties = new ConverterProperties();
22 FontProvider fontProvider = new DefaultFontProvider();
23 // 字体
24 FontProgram fontProgram = FontProgramFactory.createFont(fontPath);
25 fontProvider.addFont(fontProgram);
26 properties.setFontProvider(fontProvider);
27 //properties.setBaseUri(html);
28 properties.setBaseUri(baseuri);
29 MediaDeviceDescription mediaDeviceDescription = new MediaDeviceDescription(MediaType.SCREEN);
30 mediaDeviceDescription.setWidth(pageSize.getWidth());
31 properties.setMediaDeviceDescription(mediaDeviceDescription);
32 // 转化
33 convertToPdf(sourcePath,pdf, properties);
34 }
35
36 private static void convertToPdf(String sourcePath,PdfDocument pdf,ConverterProperties properties ) throws IOException {
37 InputStream inputStream = new FileInputStream(sourcePath);
38 // 转化
39 // HtmlConverter.convertToPdf(new FileInputStream(sourcePath), pdf, properties);
40 HtmlConverter.convertToPdf(inputStream, pdf, properties);
41 inputStream.close();
42 }
43 public static void main(String[] args) throws IOException {
44 htmlToPdf("F:\\pdf\\1.html","F:\\pdf\\est-04.pdf");
45 }
46 }
效果:
Converting HTML to PDF _ iText Developers.html
消耗时间:3660
CSS样式丢失:
JAVA 将图片转换成pdf文件 - CSDN博客.html
消耗时间:7609


样式同样丢失问题
itext html转pdf布局问题_百度搜索.html
消耗时间:5485
4. Flying Sauser(技术老旧,对样式不支持)
Flying Sauser实现html2pdf,纠错能力差,支持中文、支持简单的页面和样式,开源
对html代码要求很严格。极易出现中文乱码问题
优点:
支持多种中文字体(部分样式不能识别),开源
缺点:
纠错能力差,对CSS支持不是很好。当页面内容较长时,处理时间慢
具体实现:
1 public class Html2Pdf {
2 /**
3 * HTML代码转PDF文档
4 *
5 * @param content 待转换的HTML代码
6 * @param storagePath 保存为PDF文件的路径
7 */
8 public static void parsePdf(String content, String storagePath) {
9 FileOutputStream os = null;
10 try {
11 File file = new File(storagePath);
12 if(!file.exists()) {
13 file.createNewFile();
14 }
15 os = new FileOutputStream(file);
16
17 ITextRenderer renderer = new ITextRenderer();
18 //解决中文支持问题
19 // ITextFontResolver resolver = renderer.getFontResolver();
20 // resolver.addFont("simhei.ttf", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
21 // resolver.addFont("simhei.ttf", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
22 renderer.setDocumentFromString(content);
23 // 解决图片的相对路径问题,图片路径必须以file开头
24 // renderer.getSharedContext().setBaseURL("file:/");
25 renderer.layout();
26 renderer.createPDF(os);
27
28 } catch (DocumentException e) {
29 e.printStackTrace();
30 } catch (IOException e) {
31 e.printStackTrace();
32 }finally {
33 if(null != os) {
34 try {
35 os.close();
36 } catch (IOException e) {
37 e.printStackTrace();
38 }
39 }
40 }
41 }
42
43 /**
44 * 对Html要求特别严格
45 * @param args
46 * @throws IOException
47 */
48 public static void main(String[] args) throws IOException {
49 String htmlFilePath = "";
50 htmlFilePath = "F:/pdf/IText实现对PDF文档属性的基本设置 - 半亩池光 - 博客园.html";
51 StringBuilder content = new StringBuilder();
52 BufferedInputStream in;
53 byte[] bys = new byte[1024];
54 int len;
55 in = new BufferedInputStream(new FileInputStream(htmlFilePath));
56 while ((len = in.read(bys)) != -1) {
57 content.append(new String(bys, 0, len));
58 }
59 String html = closeHTML(content.toString());
60 html = html.replace(" "," ");
61
62 parsePdf(html,"F:/pdf/wahaha.pdf");
63
64 }
65
66 public static String closeHTML(String str){
67 List arrTags = new ArrayList();
68 arrTags.add("br");
69 arrTags.add("hr");
70 arrTags.add("link");
71 arrTags.add("meta");
72 arrTags.add("img");
73 arrTags.add("input");
74 for(int i=0;i=0){
78 int tagEnd = str.indexOf(">",tagStart);
79 j = tagEnd;
80 String preCloseTag = str.substring(tagEnd-1,tagEnd);
81 if(!"/".equals(preCloseTag)){
82 String preStr = str.substring(0,tagEnd);
83 String afterStr = str.substring(tagEnd);
84 str = preStr + "/" + afterStr;
85 }
86 }else{
87 break;
88 }
89 }
90 }
91 return str;
92 }
93
94 }
5. PD4ML(样式有问题)
PD4ML是纯Java的类库,使用HTML、CSS作为页面布局和内容定义格式来生成PDF文档的强大工具,可以简化最终用户生成PDF的工作。参考网站:http://www.pd4ml.com
优点:
支持中文、对html代码不严格、速度较快
支持的HTML标签、CSS属性较全,转换失真比较小,可以使用HTML+CSS实现精确的布局控制。
对网页文件标签、CSS语法错误的容错性比较好。
对不用额外的控制,就支持图片的转化输出。
缺点:
存在样式失真问题,CSS支持较不好。
不开源,最新的demo版本,下载测试以后,发现不支持中文转换。必须购买商业版本才可以。(这里很坑,测试乱码问题通不过,后面发现是本来就不支持)。
破解后的一些旧版本可以解决乱码问题,但是支持的css样式没有新版本的全。
具体实现:
1 public class HtmlToPDFUtil {
2 public static void main(String[] args) throws Exception {
3 //HtmlToPDFUtil htmlToPDFUtil = new HtmlToPDFUtil();
4 HtmlToPDFUtil.generatePDF_2(new File("F:\\pdf/demo_ch_pd4ml.pdf"),
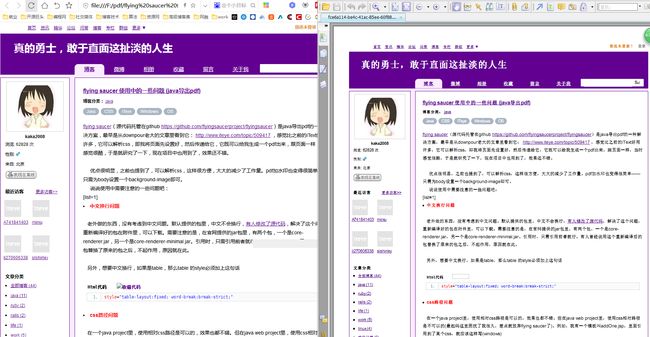
5 "F:\\pdf/flying saucer 使用中的一些问题 (java导出pdf) - 真的勇士,敢于直面这扯淡的人生 - ITeye博客.htm");
6
7 //File pdfFile = new File("D:/Test/test3.pdf");
8 // String pdfPath = "D:/Test1/mmt";
9 //
10 // File file = new File(pdfPath);
11 // if (!file.exists()) {
12 // file.mkdirs();
13 // }
14 // String pdfName = "aa.pdf";
15 // File pdfFile = new File(pdfPath+File.separator+pdfName);
16 // StringBuffer html = new StringBuffer();
17 // html.append("")
18 // .append("")
19 // .append("")
20 // .append("").append("")
21 // //.append("")
22 // .append("")
23 // .append("显示中文aaaaaaaaaa")
24 // .append("").append("");
25 // StringReader strReader = new StringReader(html.toString());
26 // HtmlToPDFUtil.generatePDF_1(pdfFile, strReader);
27
28 }
29
30 // 手动构造HTML代码
31 public static void generatePDF_1(File outputPDFFile, StringReader strReader)
32 throws Exception {
33 FileOutputStream fos = new FileOutputStream(outputPDFFile);
34 PD4ML pd4ml = new PD4ML();
35 pd4ml.setPageInsets(new Insets(20, 10, 10, 10));
36 pd4ml.setHtmlWidth(950);
37 pd4ml.setPageSize(pd4ml.changePageOrientation(PD4Constants.A4));
38 pd4ml.useTTF("java:fonts", true);
39 //pd4ml.setDefaultTTFs("KaiTi_GB2312", "KaiTi_GB2312", "KaiTi_GB2312");
40 pd4ml.setDefaultTTFs("KaiTi", "KaiTi", "KaiTi");
41 pd4ml.enableDebugInfo();
42 pd4ml.render(strReader, fos);
43 }
44
45 // HTML代码来自于HTML文件
46 public static void generatePDF_2(File outputPDFFile, String inputHTMLFileName)
47 throws Exception {
48 FileOutputStream fos = new FileOutputStream(outputPDFFile);
49 PD4ML pd4ml = new PD4ML();
50 pd4ml.setPageInsets(new Insets(20, 10, 10, 10));
51 pd4ml.setHtmlWidth(950);
52 pd4ml.setPageSize(pd4ml.changePageOrientation(PD4Constants.A4));
53
54 pd4ml.useTTF("java:fonts", true);
55 pd4ml.setDefaultTTFs("KaiTi", "KaiTi", "KaiTi");
56 pd4ml.enableDebugInfo();
57 pd4ml.render("file:" + inputHTMLFileName, fos);
58 }
59
60 }

pd4browser和pd4fonts是生成的
-
乱码解决方案:
-
https://blog.csdn.net/u014769730/article/details/54375836
测试结果:


对CSS有一定的要求
部分Html能支持:

6. Sferyx:(样式有问题)
官网:https://www.sferyx.com/pdfgenerator/html-to-pdf-java.htm

支持URL、支持文件。支持中文,对html文件几乎无要求。样式不佳,中文字体支持不佳。
具体实现
引入Java包:PDFGenerator.jar
代码:
1 PDFGenerator pdfGenerator=new PDFGenerator();
2 pdfGenerator.setMarginsForStandardPageFormat (10,10,10,10);
3 // pdfGenerator.setCharset ("utf-8");
4 pdfGenerator.setCharset("ISO-10646-UCS-2");
5 // pdfGenerator.generatePDFFromURL ("https://blog.csdn.net/gisboygogogo/article/details/77601308",
6 pdfGenerator.generatePDFFromURL ("F:\\pdf\\1.html",
7 "F:\\pdf/pdfgenerator-test1.pdf",
8 "A4", "Portrait");
样式问题:

7. jPDFWriter(样式有问题、对html文件支持不好)
具体实现:
1 // URL url = new URL("https://www.baidu.com/");
2 // PageFormat pf = new PageFormat();
3 // PDFDocument pdfDoc = PDFDocument.loadHTML (url, pf, true);
4 // pdfDoc.saveDocument ("F:\\pdf\\output.pdf");
5 File f1 = new File ("F:\\pdf\\1.html");
6 PDFDocument pdfDoc = PDFDocument.loadHTML(f1.toURI().toURL(), new PageFormat (), false);
7 pdfDoc.saveDocument ("F:\\pdf\\output.pdf");
效果:
并不是很好,虽然支持中文

其他未知方案。。。。。。。。。。
在线转换方案:
仅支持URL,但能很好地转换,效果较好,速度较快。但收费,且为第三方服务,或有信息安全性问题。
如果不考虑html文件安全性的话,可以考虑。
以转CSDN及百度搜索网页为测试例。
1. restpack
官网:https://restpack.io/
能很好保持样式,且支持中文,速度快。价格相比较优惠。

使用实例:
https://www.cnblogs.com/IT-study/p/13738157.html
2. pdfshift
官网:https://pdfshift.io
能很好保持样式,且支持中文,速度快。价格相比较优惠。
测试效果:

实现方法:
1 String encoding = Base64.getEncoder().encodeToString("YOUR_API_KEY:".getBytes());
2 HttpPost httppost = new HttpPost("https://api.pdfshift.io/v2/convert/");
3 httppost.setHeader("Authorization", "Basic " + encoding);
4 httppost.setHeader("Content-type", "application/json");
5
6 HttpEntity postingString = new StringEntity("{\"source\":\"https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=PhantomJS%20html%E8%BD%ACpdf&oq=PhantomJS&rsv_pq=c942451400041f65&rsv_t=3566cYExdLkZv6pJRhDXeda3WgHs37R3GASuPvnEGrOmBl9Lur2EMGyfdF8&rqlang=cn&rsv_enter=1&rsv_sug3=15&rsv_sug1=4&rsv_sug7=100&rsv_sug2=0&inputT=6104&rsv_sug4=6105\",\"landscape\":false,\"use_print\":false}");
7 httppost.setEntity(postingString);
8
9 CloseableHttpClient client = HttpClients.createDefault();
10 try (CloseableHttpResponse response = client.execute(httppost)) {
11 HttpEntity entity = response.getEntity();
12 // Use the entity
13 }
3.其他(不考虑的方案)
1. pdfmyurl(网站反应慢)
官网:http://pdfmyurl.com/
转化效率极低,速度极其慢
2. pdflayer(不支持中文)
官网:https://pdflayer.com/
不支持中文。虽然能很好保持样式。
个人总结:
到现在未知并为找到完美的方案。各种方案都有缺点,但是在线转换的方案转化效率以及对CSS等支持程度比较好。也不知道他们这些内部是如何实现的。
参考链接:
http://blog.csdn.net/ouyhong123/article/details/26401967
http://blog.csdn.net/tengdazhang770960436/article/details/41320079
http://www.cnblogs.com/jasondan/p/4108263.html
http://blog.csdn.net/accountwcx/article/details/46785437
http://blog.csdn.net/zdtwyjp/article/details/5769353