【计算机架构】python并发编程:多线程和线程池
一、python多线程
1. 为什么要引入并发编程
场景1:一个网络爬虫,按顺序爬取花了1小时,采用并发下载减少到20分钟
场景2:一个APP应用,优化前每次打开页面需要3秒,采用异步并发提升到打开每次200毫秒
其实引入并发就是为了提升程序的运行速度。
2. python中对并发编程的支持
- 多线程:threading模块,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴的等待IO完成
- 多进程:multiprocessing模块,利用多核CPU的能力,真正的并行执行任务
- 异步IO:asyncio模块,在单线程利用CPU和IO同时执行的原理,实现函数异步执行
同时python又提供了一些模块来辅助或者简化并发的运行。
- 使用Lock对资源进行加锁,防止冲突访问
- 使用Queue实现不同线程、进程之间的数据通信,实现生产者-消费者模型
- 使用线程池、进程池Pool,简化线程、进程的任务提交,等待结束,获取结果
3. 如何选择
- CPU密集型:CPU密集型也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率特别高。典型的示例:压缩、解压缩,加密解密,正则表达式搜索等
- IO密集型:IO密集型指的是系统运作大部分的状况是CPU在等待I/O,例如一些磁盘、内存、网络的读写,这种状况,CPU占用率不高,系统IO特别高。 典型的示例:文件处理程序,网络爬虫,读写数据库等
4. python中多进程、多线程、多协程的对比
-
多线程:
- 优点:相比进程,更加轻量级,占用资源少
- 缺点:相比协程,启动数目有限,占用内存资源,有线程切换开销
- 适用于:IO密集型计算,同时运行的任务数目要求不多
-
多进程
- 优点:可以利用多核CPU并行运算
- 缺点:占用资源最多,可启动数目比线程少
- 适用于:CPU密集型计算场景
-
多协程
- 优点:内存开销最少,启动协程数可以非常多
- 缺点:支持的库有限,例如不能使用requests模块,代码实现复杂
- 适用于:IO密集型计算、需要超多任务运行,有现成库支持的场景
5. python全局解释器锁GIL
(1)python速度慢的两个原因?
相比其他语言,例如:C/C++/java/golang,python确实很慢,在一些特殊场景下,python要比C++慢100~200倍
那么python慢的原因到底是什么?
- 动态类型语言,边解释边执行
- GIL无法利用多核CPU并发执行
(2)那么GIL是什么?
GIL:全局解释器锁,是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行,即便在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。
出现GIL的原因?
python设计初期,为了规避并发问题,解决多线程之间数据完整性和状态同步问题,因此引入了GIL。
由于python中对象的管理,是使用引用计数器进行的,引用数为0则释放对象。
比如:有两个线程A和B都想引用对象obj,并对该对象做撤销处理,线程A先执行了撤销,将对象obj做了减一处理,此时发生了多线程的调度切换,线程B也做了obj的撤销处理,obj此时又减一,这个时候又发生了多线程调度切换,此时对象obj的计数已经为0,此时Python会释放此对象,这个时候可能会破坏内存。
而多线程在执行期间,线程会释放GIL,实现CPU和IO的并行执行,因此多线程对于IO密集型的运行效率会有很大的提升。
6. 创建多线程的方法
创建多线程的流程
- 先准备一个执行函数,例如:
def my_func(a, b):
do_something(a, b)
- 创建一个线程
import threading
t = threading.Thread(target=my_func, args=(100, 200,))
- 启动线程
t.start()
- 等待结束
t.join()
7. 爬虫示例
测试示例来源于爬取的北京新发地菜价信息,地址如下:http://www.xinfadi.com.cn/priceDetail.html
浏览器f12抓包分析,可以看到,价格信息是通过http://www.xinfadi.com.cn/getPriceData.html这个请求拿到的,请求方法为POST,我们试着拿第一页的数据信息,代码如下:
import requests
url = 'http://www.xinfadi.com.cn/getPriceData.html'
def get_resource(url, page=1):
data = {
"limit": 20,
"current": page
}
resp = requests.post(url, data=data)
resp.encoding = 'utf-8'
price_list = resp.json()['list']
res_data = [
(info['prodName'], info['place'], info['avgPrice']) for info in price_list
]
print(res_data)
return res_data
if __name__ == '__main__':
res = get_resource(url)
print(res)
执行结果:
[('大白菜', '冀陕辽', '1.15'), ('娃娃菜', '冀', '1.25'), ('小白菜', '', '2.75'), ('圆白菜', '冀', '2.5'), ('圆白菜', '鲁', '1.9'), ('紫甘蓝', '冀', '0.75'), ('芹菜', '鲁', '2.65'), ('西芹', '辽', '2.9'), ('菠菜', '蒙', '6.5'), ('莴笋', '冀', '2.25'), ('团生菜', '冀', '4.5'), ('散叶生菜', '京辽', '4.75'), ('罗马生菜', '冀', '3.25'), ('油菜', '冀', '2.9'), ('香菜', '冀', '6.0'), ('茴香', '冀', '6.5'), ('韭菜', '粤冀', '2.85'), ('苦菊', '辽', '4.5'), ('油麦菜', '辽', '6.0'), ('黄心菜', '皖', '1.55')]
下面看下单线程爬取五十页的菜价信息时的用时情况吧:
为了测试方便,这里写一个统计程序运行时间的装饰器,最终单线程运行时的代码为:
import time
import xinfadi_spider
import threading
from functools import wraps
def count_time(func):
@wraps(func)
def _wraper(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
end = time.time()
print(f"运行时间: {end - start}")
return res
return _wraper
@count_time
def single_thread():
for page in range(1, 51):
xinfadi_spider.get_resource(xinfadi_spider.url, page)
if __name__ == '__main__':
single_thread()
运行时间最终为:
运行时间: 13.166715621948242
下面再看下多线程时的运行代码:
@count_time
def single_thread():
for page in range(1, 51):
xinfadi_spider.get_resource(xinfadi_spider.url, page)
return
@count_time
def multi_thread():
t = []
for page in range(1, 51):
t.append(
threading.Thread(target=xinfadi_spider.get_resource, args=(xinfadi_spider.url, page,))
)
for thread in t:
thread.start()
for thread in t:
thread.join()
if __name__ == '__main__':
multi_thread()
最终运行速度提升了10倍左右,结果为:
运行时间: 1.8293204307556152
二、线程池
1. 介绍
首先了解一下线程的生命周期,如下图所示:
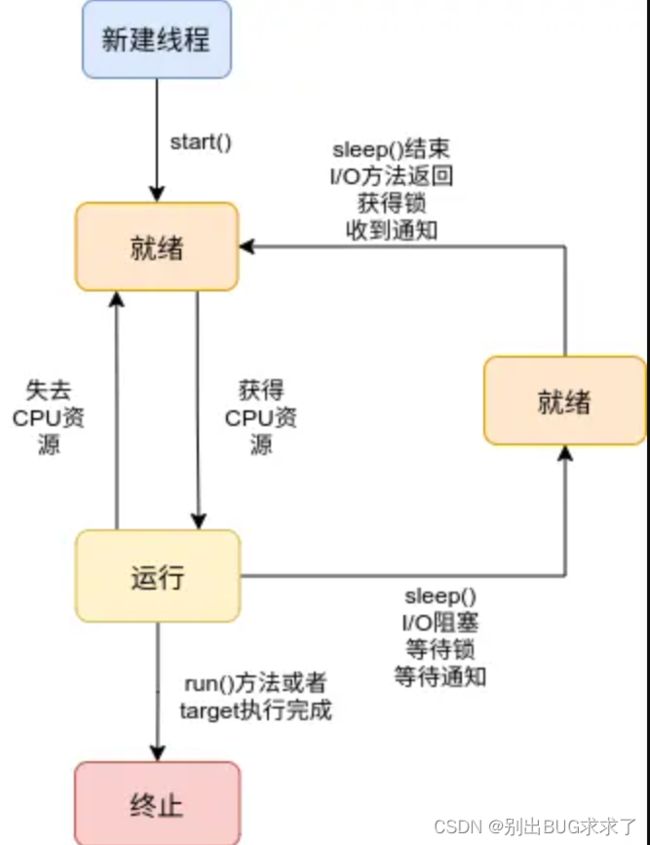
从上图可以看到新建线程时,系统需要分配资源,终止线程系统需要回收资源,因此这就会产生一定新建和终止的开销,如果可以重用线程,那么就可以减少系统开销,所以就有了线程池,那么使用线程池有哪些优势呢?
- 提升性能,减少了大量的新建、终止线程的开销,重用线程资源
- 适用于处理突发性大量请求或需要大量线程来完成任务,但实际任务处理时间较短的场景
- 能有效避免系统因为创建线程过多,导致系统负荷较高而变慢的问题
- 使用线程池,比单独使用线程要更加简洁
2. 使用方法
(1)map函数方式
map的结果和入参顺序是固定的
from concurrent.futures import ThreadPoolExecutor, as_completed
with ThreadPoolExecutor() as pool:
# func 是目标函数
# args_list 是一个参数列表
results = pool.map(func, args_list)
# 获取执行的返回结果
for result in results:
print(result)
(2)future模式
as_completed顺序是不固定的
from concurrent.futures import ThreadPoolExecutor, as_completed
with ThreadPoolExecutor() as pool:
# arg 是指一个参数
futures = [pool.submit(func, arg) for arg in args_list]
for future in futures:
print(future.result())
for future in as_completed(futures):
print(future.result())
下面结合上面的爬虫案例进行改造,首先是通过submit方式来看下
import xinfadi_spider
from concurrent.futures import ThreadPoolExecutor
# 新建一个线程来获取所有url资源
with ThreadPoolExecutor() as p1:
futures = {
page: p1.submit(xinfadi_spider.get_resource, xinfadi_spider.url, page)
for page in range(1, 51)
}
for k, v in futures.items():
print(k, v.result())
with ThreadPoolExecutor() as p2:
futures_parse = {}
for resource in futures.values():
res = p2.submit(xinfadi_spider.parse_resource, resource.result())
futures_parse[res] = resource
for k, v in futures_parse.items():
print(res.result())
注意:当使用submit时,返回的是一个future对象,可以通过result()获取返回结果,
而使用map提交任务时,相当于启动了len(iterlables)个线程来并发的去执行func函数
with ThreadPoolExecutor() as p3:
res = p3.map(xinfadi_spider.get_resource, [xinfadi_spider.url] * 50, [i for i in range(1, 51)])
with ThreadPoolExecutor() as p4:
p4.map(xinfadi_spider.parse_resource, [r for r in res])
需要注意的是,使用map时,传入多个参数时,需要保证传入的变量是一个可迭代的对象,例如数组、元祖等,并且需要保证参数的个数是一致的。
三、多进程
多线程和协程本质上还是在单核上进行,而多进程是真正意义上的并行,利用了多进程在多核CPU上并行执行。
由于多进程和多线程写法几乎一样,所以这里不在做过多的讲解,只列出一些创建方法和使用方法。
1. 导入模块
# 多进程
from multiprocessing import Process
# 多线程
from threading import Thread
2. 新建、启动、等待结束
# 多进程
p = Process(target=func, args=(1,))
p.start()
p.join()
# 多线程
t = Thread(target=func, args=(1,))
t.start()
t.join()
3. 数据通信
# 多进程
from multiprocessing import Queue
q = Queue()
q.put([1,2,3])
item = q.get()
# 多线程
import queue
q = Queue()
q.put([1,2,3])
item = q.get()
4. 线程安全加锁
# 多进程
from multiprocessing import Lock
lock = Lock()
with lock:
do_something()
# 多线程
from threading import Lock
lock = Lock()
with lock:
do_something()
5. 池
# 多进程
from concurrent.futures import ProcessPoolExecutor
with ProcessPoolExecutor() as pool:
# 方法一
res = pool.map(func, *iterables)
# 方法二
res = pool.submit(func, arg)
result = res.result()
# 多线程
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor() as pool:
# 方法一
res = pool.map(func, *iterables)
# 方法二
res = pool.submit(func, arg)
result = res.result()
四、协程
关于协程这部分,需要很多的内容去描述。后续再阐述