python并发爬虫——多线程、线程池实现
python并发爬虫——多线程、线程池实现
目录
- python并发爬虫——多线程、线程池实现
-
- 一、常规网络爬虫
-
- 1. 执行顺序
- 2. 缺点
- 二、并发爬虫
-
- 1. 原理
- 2. 优点
- 3. 应用
-
- 3.1 多线程
-
- 1)常规调用
- 2)自定义线程
- 3)PCS模式
- 3.2 线程池
-
- 1)一次性提交
- 2)分步提交
- 3)分步提交加强版
- 四、结语
一个网络爬虫通常由发送请求、获取响应、解析页面、本地保存等这几部分组成。其中最难,细节最多的当然是页面解析环节,对于不同的页面,其解析难度必然又所差异,甚至有些安全性较高的网站还设有各种反扒机制,想要获取需要的信息需要视具体情况而言。当然这些内容不在本篇的介绍范围内。本文主要内容是针对如何使用多线程、线程池进行并发操作,提高爬虫的爬取效率。
一、常规网络爬虫
1. 执行顺序
通常,我们在使用爬虫对网页进行爬取的时候,往往采用requests库发送get请求,获取响应text文本,再使用beautifulsoup库、正则表达式、xpath对网页文本进行解析以得到我们所需数据,之后再对数据进行其他处理。
resp = requests.get(url).text
html = etree.HTML(resp)
result = html.xpath(//div[class="col-md-1/text()"])
print(result)
2. 缺点
1)耗时多。整个爬取过程中,只要前一个环节尚未完成时,后一环节就一直处于等待状态,尤其是解析页面环节往往需要耗费大量时间。
2)效率低。采用这种单线程处理方式会增加整个爬虫的运行时间,降低爬取效率。
3)易崩溃。一旦某一模块出现异常,整个爬虫程序也会崩溃。
二、并发爬虫
1. 原理
将整个爬虫程序分为CPU操作和IO操作两部分。CPU首先开始执行task,在遇到IO操作时,CPU会切换到另一个Task开始执行,IO操作结束后,再通知CPU进行处理。由于IO操作读取内存、磁盘网络等不需要CPU的参与,两者可以同时进行,CPU可以释放出来执行其他Task实现加速。采用多线程并发操作执行程序可以大大降低运行时间,提高效率。

2. 优点
1)速度快。相比于单线程爬虫,采用多线程并发处理减少了不必要的等待时间,使得整个程序运行速度大大加快。
2)效率高。多线程能够同时进行CPU操作和IO操作,降低整个程序运行的时间。
3)安全性高。多线程可以采用Lock机制来控制全局共享变量,确保数据的正确性。
值得注意的是,由于python多线程的GIL(Global Interpreter Lock)全局解释器锁的存在,使得整个CPU操作过程中永远只能使用一个CPU,每个线程在执行时候都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。因此python的多线程并不是真正意义上的同时执行,使用多线程提高运行效率也仅仅是通过同时执行CPU操作和IO操作完成的,并不是通过使用多个CPU同时执行Task实现的。
3. 应用
在介绍多线程之前,先介绍一种需要使用到生产者-消费者的爬虫模式(Producer-Consumer-Spider PCS模式)。这种模式将爬虫集成为生产者、消费者模块。生产者负责处理输入数据,生成中间变量传递给消费者。消费者负责解析内容,生成输出数据。
在爬虫程序中,生产者往往是对url进行处理,发送请求获取响应。消费者往往是对响应页面进行解析,获取输出数据。

3.1 多线程
python实现多线程有多种不同的方式,这里介绍几种常用的方法。
1)常规调用
开启多线程需要引入threading包,通过函数threading.Thread(target=fun, args=())即可创建线程。target参数为需要执行函数的函数名(不是调用不带括号),args参数为所调函数需要的参数元组。
import threading
import requests
from lxml import etree
urls = [
f'https://www.cnblogs.com/sitehome/p/{page}'
for page in range(1, 20)
]
def craw(u):
res = requests.get(u)
print(u, len(res.text))
return res.text
def parse(h):
html = etree.HTML(h)
links = html.xpath('//a[@class="post-item-title"]')
results = [(link.attrib['href'], link.text) for link in links]
print(results)
return results
def multi_thread(u):
results = parse(craw(u))
for r in results:
print(r)
if __name__ == "__main__":
for u in urls:
t = threading.Thread(target=multi_thread, args=(u,))
t.start()
2)自定义线程
通过继承threading.Thread来定义线程类,其本质是重构Thread类中的run()方法,构建实例启动线程即可,不需要传入被执行函数和参数。通过对run方法的重写,可以实现更加强大的功能。
import threading
import requests
from lxml import etree
urls = [
f'https://www.cnblogs.com/sitehome/p/{page}'
for page in range(1, 20)
]
# 自定义线程
class MyThread(threading.Thread):
def __init__(self, url):
super(MyThread, self).__init__() # 重构run函数必须写
self.url = url
def run(self):
results = parse(craw(self.url))
for r in results:
print(r)
def craw(u):
res = requests.get(u)
print(u, len(res.text))
return res.text
def parse(h):
html = etree.HTML(h)
links = html.xpath('//a[@class="post-item-title"]')
results = [(link.attrib['href'], link.text) for link in links]
print(results)
return results
if __name__ == "__main__":
for u in urls:
t = MyThread(u)
t.start()
3)PCS模式
在常规爬虫的基础上采用生产者-消费者模式进行改进,引入队列(Queue)对数据进行更加复杂的操作,实现更加强大的功能。创建线程传入url_queue队列执行生产者方法得到html_queue队列,消费者方法依次从html_queue队列中获取数据执行解析方法,得到输出数据。直到两个队列为空时,结束线程。
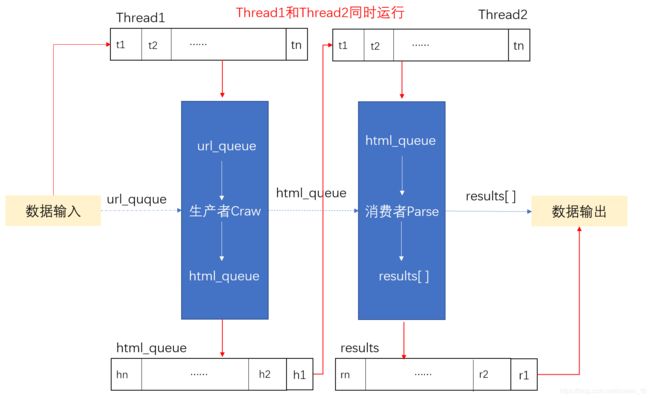
import queue
import random
import threading
import time
# 生产者
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
u = url_queue.get()
html_queue.put(blog_spider.craw(u))
print(threading.current_thread().name, f"craw {u}",
'url_queue.qsize=', url_queue.qsize())
time.sleep(random.randint(1, 2))
#消费者
def do_parse(html_queue: queue.Queue, fout):
while True:
h = html_queue.get()
results = blog_spider.parse(h)
for result in results:
fout.write(str(result) + '\n')
print(threading.current_thread().name, f"results.size", len(results),
'html_queue.qsize=', html_queue.qsize())
time.sleep(random.randint(1, 2))
if __name__ == "__main__":
url_queue = queue.Queue()
html_queue = queue.Queue()
for u in blog_spider.urls:
url_queue.put(u)
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f'craw{idx}')
t.start()
fout = open(r'results.txt', 'w+', encoding='utf-8')
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f'parse{idx}')
t.start()
3.2 线程池
尽管在使用多线程进行爬虫时可以提高程序运行效率,但是线程的创建和销毁都会消耗资源,过多的创建线程会导致线程浪费,增加运行成本。引入线程池对线程进行管理,当我们需要调用线程时从线程池中获取,用完之后再归还入池中,实现线程的循环使用,大大降低运行成本。创建一个线程池需要使用到concurrent.futures包中的ThreadPoolExecutor()方法。
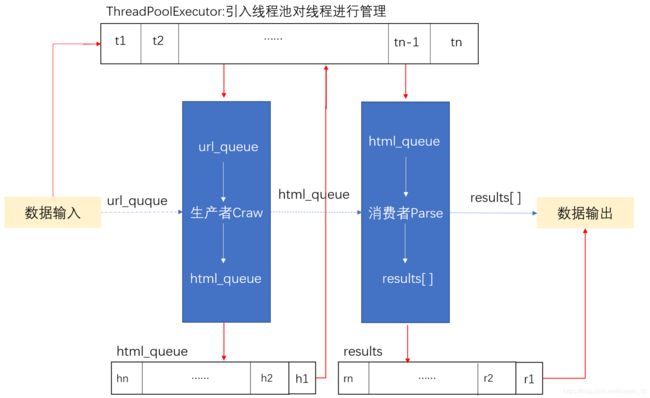
可以用with ThreadPoolExecutor()创建线程池,之后方法执行时会自动从池中获取线程并发执行。可以在ThreadPoolExecutor()中传入参数设置线程池信息。例如max_workers参数可以设置池中最大线程数。线程池的使用共有三种方法:
1)一次性提交
使用pool.map()方法一次性提交任务队列里的任务并得到所有结果。注意map()方法中有两个参数,一个是被执行的方法名,另一个是其所需参数集,必须是可迭代对象(*iterables)。
from concurrent.futures import ThreadPoolExecutor,as_completed
# craw
with ThreadPoolExecutor() as pool:
htmls = pool.map(blog_spider.craw, blog_spider.urls)
htmls = list(zip(blog_spider.urls, htmls))
for url, html in htmls:
print(url, len(html))
2)分步提交
使用pool.submit()方法可以依次从任务队列取出Task执行,并将其结果依次封装到future对象中,调用result()方法可以取得返回的结果。
# parse
with ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(blog_spider.parse, html)
futures[future] = url
for future, url in futures.items():
print(url, future.result())
3)分步提交加强版
使用as_completed()可以优先返回已经执行完的结果。在整个代码运行过程中,先执行完毕的线程先将其返回值封装到future对象中。对比第二种方法,减少了运行时间,提高了执行效率。
with ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(blog_spider.parse, html)
futures[future] = url
for future in as_completed(futures):
print(futures[future], future.result())
四、结语
多线程的使用场景非常广泛,熟悉并掌握并发操作会大大提高你程序的运行效率。相比与单线程爬虫,多线程爬虫的效率平均能提高5-10倍。合理的利用多线程会让你的程序更加高效。当然,多线程涉及到的内容十分广泛,其中本文未提到的Lock锁机制是也其重要内容之一。将本文可以作为使用多线程进行并发操作的入门参考,想要详细了解多线程的更多知识还需要继续努力。