LAMP架构之mysql(5):MHA高可用
LAMP架构之mysql(5):MHA高可用
- 一、认识MHA
-
- 1.MHA简介
- 2.MHA服务
- 3.MHA 提供的服务
- 4.MHA工作原理
- 二、实现过程
-
- 一、环境配置
- 二、MHA 手动切换
- 三、MHA自动切换
- 四、设置vip漂移
一、认识MHA
1.MHA简介
在前面的学习中,我们学习了如何去配置mysql的主从复制,但是如果master主机down掉后,只能手动去CHANGE MASTER,这在企业运维中是十分不理想的解决方案。
MHA(Master HA)是一款开源的 MySQL 的高可用程序,它为 MySQL 主从复制架构提供了 automating master failover 功能。MHA 在监控到 master 节点故障时,会提升其中拥有最新数据的 slave 节点成为新的master 节点,在此期间,MHA 会通过于其它从节点获取额外信息来避免一致性方面的问题。MHA 还提供了 master 节点的在线切换功能,即按需切换 master/slave 节点。
2.MHA服务
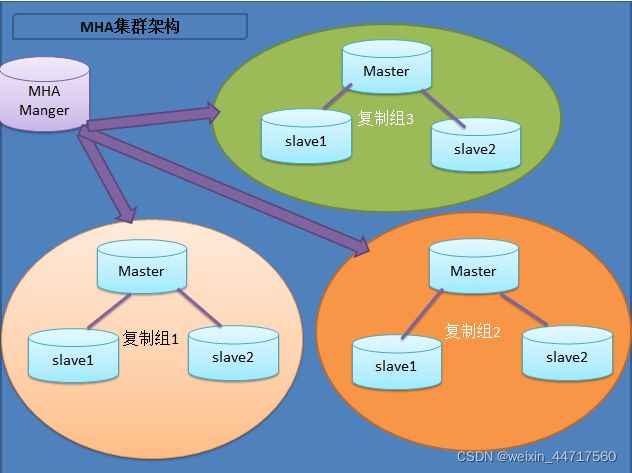
MHA服务角色: MHA 服务有两种角色, MHA Manager(管理节点)和 MHA Node(数据节点):
1、MHA Manager:
通常单独部署在一台独立机器上管理多个 master/slave 集群(组),每个 master/slave 集群称作一个 application,用来管理统筹整个集群。
2、MHA node:
运行在每台 MySQL 服务器上(master/slave/manager),它通过监控具备解析和清理 logs 功能的脚本来加快故障转移。
主要是接收管理节点所发出指令的代理,代理需要运行在每一个 mysql 节点上。简单讲 node 就是用来收集从节点服务器上所生成的 bin-log 。对比打算提升为新的主节点之上的从节点的是否拥有并完成操作,如果没有发给新主节点在本地应用后提升为主节点。
由上图我们可以看出,每个复制组内部和 Manager 之间都需要ssh实现无密码互连,只有这样,在 Master 出故障时, Manager 才能顺利的连接进去,实现主从切换功能。
3.MHA 提供的服务
在Manager工具包主要包括以下几个工具:
在Manager工具包主要包括以下几个工具:
masterha_check_ssh //检查MHA的SSH配置状况
masterha_check_repl //检查MySQL复制状况
masterha_manger //启动MHA
masterha_check_status //检测当前MHA运行状态
masterha_master_monitor //检测master是否宕机
masterha_master_switch //控制故障转移(自动或者手动)
masterha_conf_host //添加或删除配置的server信息
Node工具包(由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs //保存和复制master的二进制日志
apply_diff_relay_logs //识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog //去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs //清除中继日志(不会阻塞SQL线程)
4.MHA工作原理
MHA工作原理总结为以下几条:
(1) 从宕机崩溃的 master 保存二进制日志事件(binlog events);
(2) 识别含有最新更新的 slave ;
(3) 应用差异的中继日志(relay log) 到其他 slave ;
(4) 应用从 master 保存的二进制日志事件(binlog events);
(5) 提升一个 slave 为新 master ;
(6) 使用其他的 slave 连接新的 master 进行复制。
二、实现过程
一、环境配置
实验前准备:
1、得先把之前配置的mysql集群转成一组两从的架构。
2、MHA工具包配置无误
1、修改配置文件
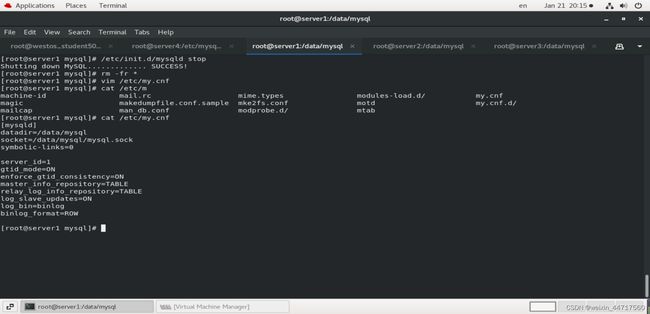
my.cnf文件中的内容如下:
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
symbolic-links=0
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
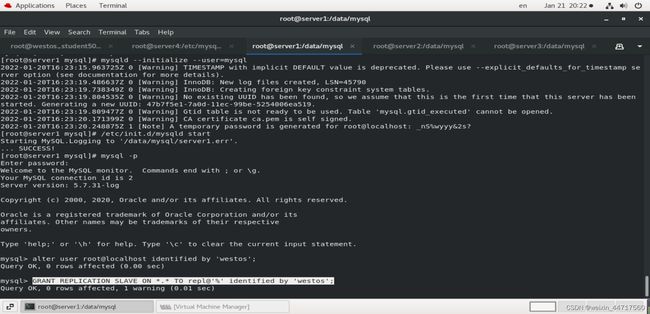
2、进入数据库 做初始化操作:
alter user root@localhost identified by ‘westos’;
GRANT REPLICATION SLAVE ON . TO repl@’%’ identified by ‘westos’;
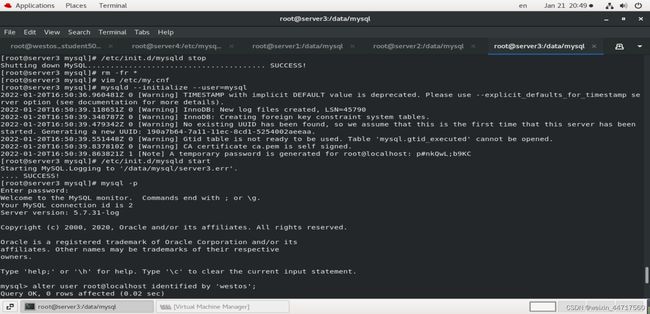
server2 server3 也是如此:
3、然后 在管理端安装软件:
yum install mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
yum install *.rpm -y (解决依赖性)
在server2 3上安装: yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm
4、在server4端的etc下 mkdir mha
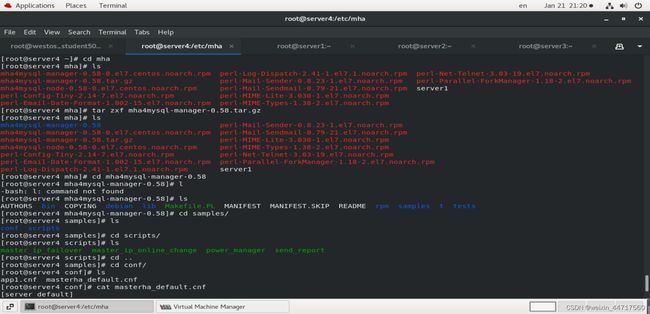
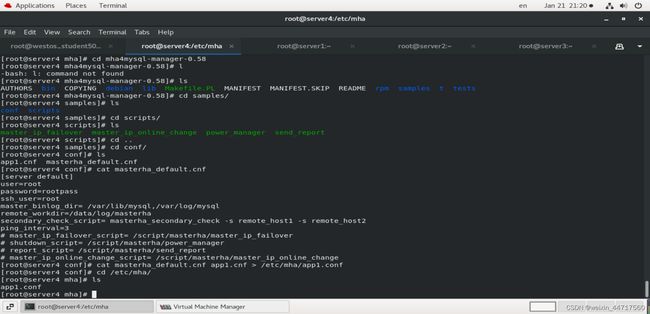
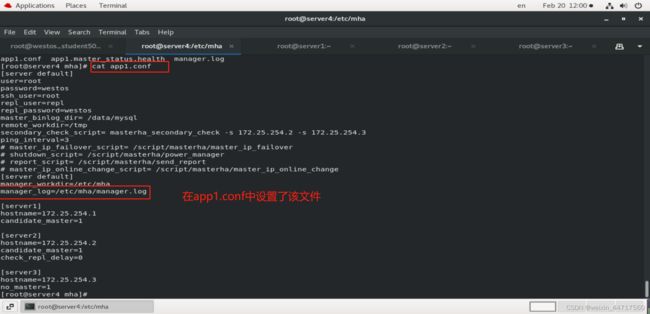
vim app1.conf
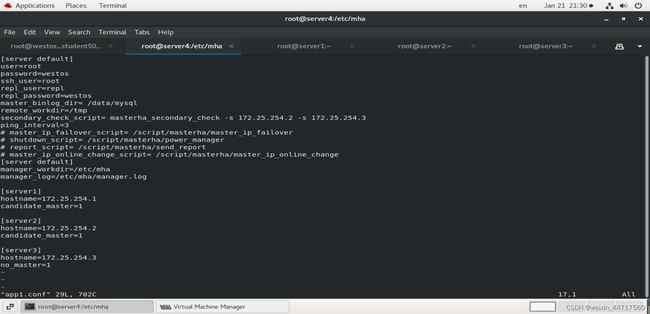
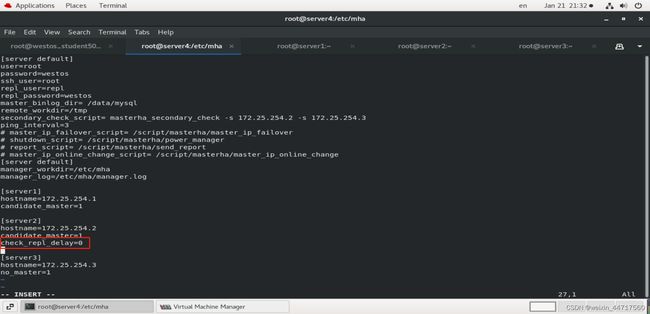
5、最后测试,看看环境到底有没有准备好
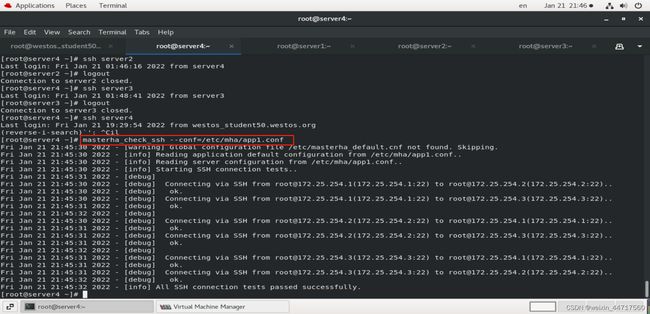
masterha_check_ssh --conf=/etc/mha/app1.conf
由下图可以看出,集群节点间要求能够相互免密互访,而且manager也要求能够免密访问其他节点
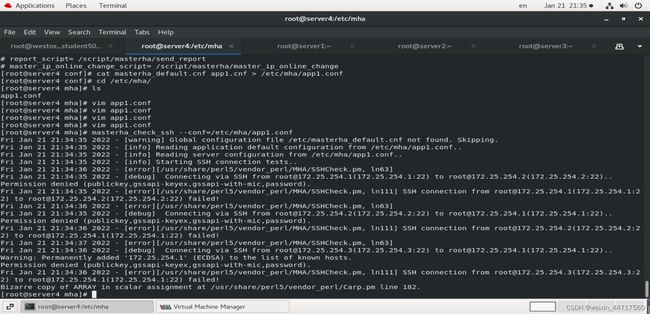
解决一下免密登录问题:
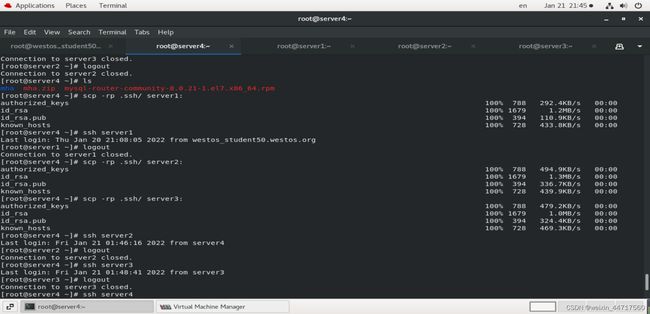
再次检测 显示无误。
masterha_check_repl --conf=/etc/mha/app1.conf 这个是用来检测 数据库主从集群的配置有没有到位
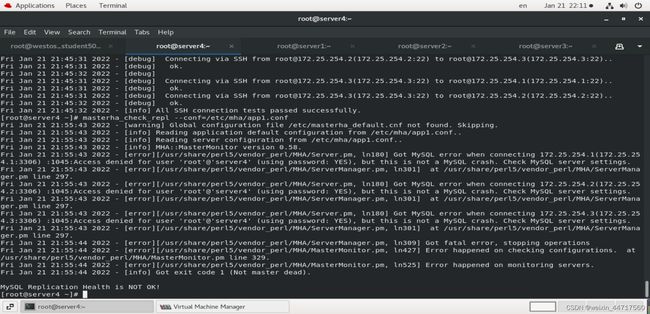
解决办法:
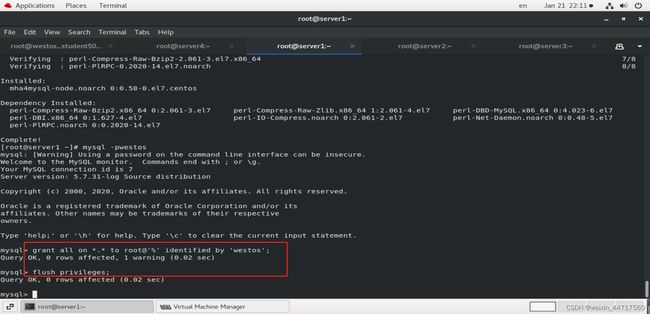
这样就解决好了:
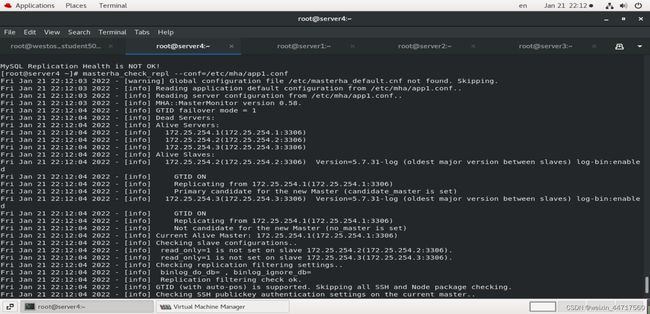
以上,mysql一主两从的状态无误(show master status; show slave status\G中的双yes),MHA的ssh配置情况以及mysql复制情况都无误,可以进行下一步。
二、MHA 手动切换
为啥要手动切换? 因为用着放心,心里有数。呜呜呜
1、手动切换一:(master还没有down掉,状态为alive)
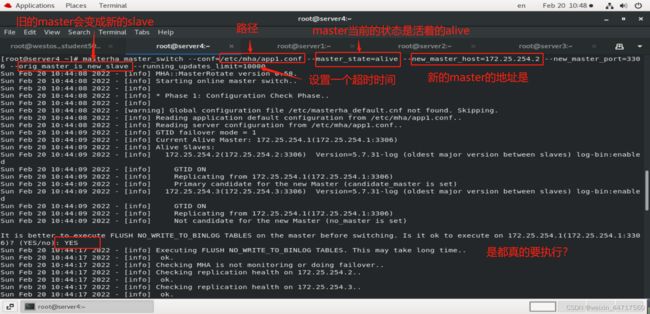
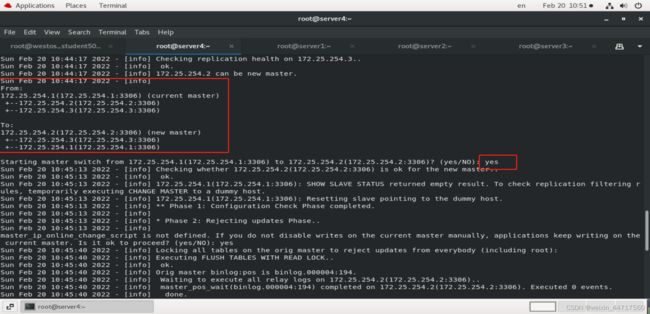
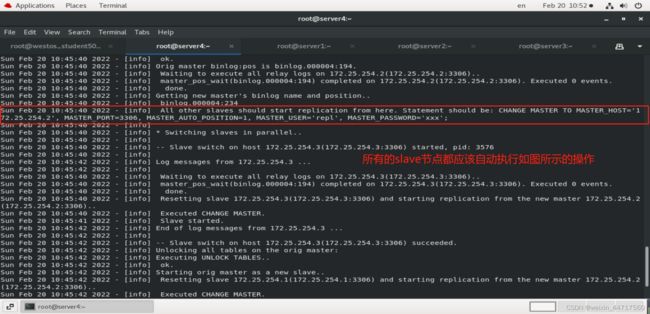
测试:
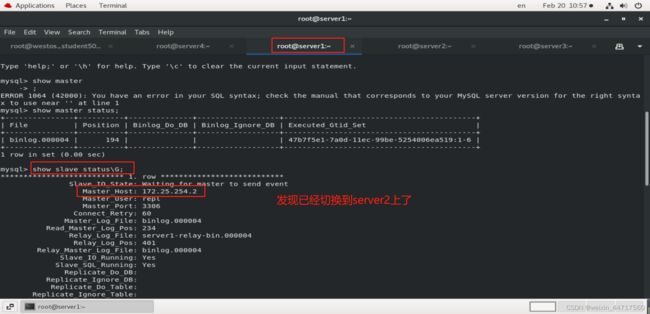
2、手动切换2:master已经down掉,状态为dead
此时停掉master(server2):[root@server2 ~]# /etc/init.d/mysqld stop
那么会出现如下图所示的情况
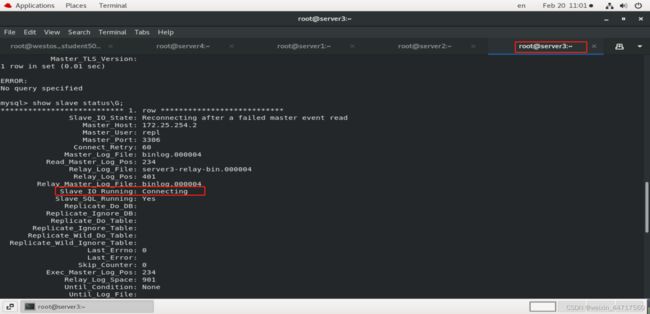
那此时的切换方式就变为:
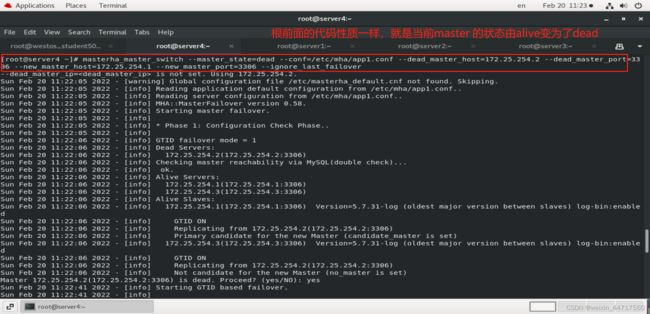
上图中:–ignore_last_failover代表忽略最后一次的故障切换
每次通过MHA 进行自动的主从切换(故障切换),就会在你的数据目录中生成一个log文件,这个文件是为了避免我们的主从集群频繁的切换,因为切换就代表不可用,频繁切换就意味着你的服务抖动,不稳定,那你就不要再做切换了,因为作为生产环境来说你太不靠谱了。这里会有一个锁定文件,好像是8个小时,(8个小时以内不让你切换)。
而此时这个的意思就是 忽略它的锁定文件,强制忽略,当然也可以把那个文件删掉。
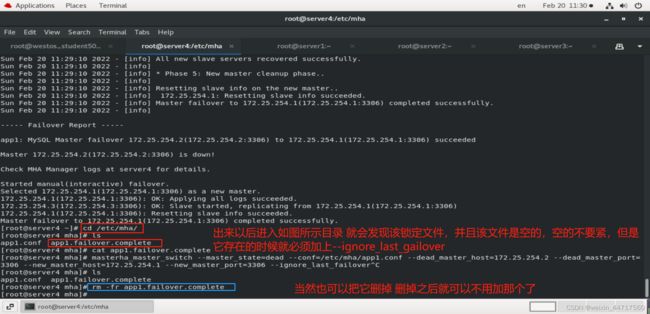
此时要注意,server2由于已经dead,不能自动切换到slave 所以你得手动执行。操作如下:
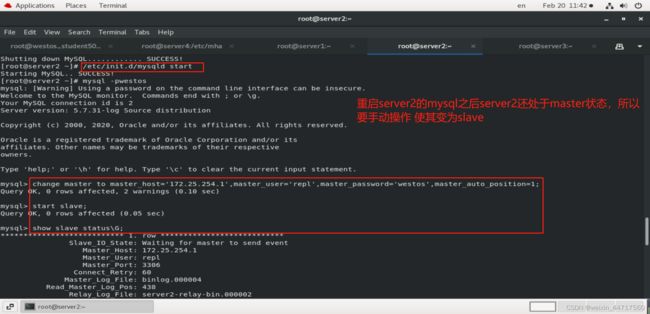
有人说宕掉之后重新配置就好了呀
一方面 你手工配置肯定比自动的慢很多,效率低下,再者 宕掉之后,其他节点的数据是否一致?主从之间肯定是有延迟的,此时如果直接kill掉节点,那每个节点间的数据可能都不太一样,这个时候就能体会到MHA 的好处了,它会自动帮你去应用不一样的日志,自动解决数据同步的问题。它在这个地方的逻辑就是,先把你的数据一致性搞定,然后再进行切换,如果数据都不一致,那不能切换,一般情况下,诸如一些大厂都是做二次开发。
三、MHA自动切换
自动切换很简单,只要把它打到后台去就可以,
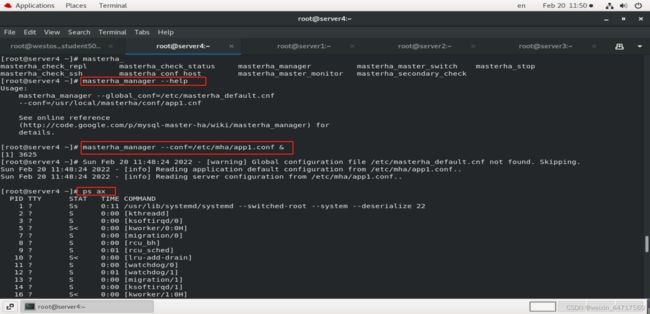
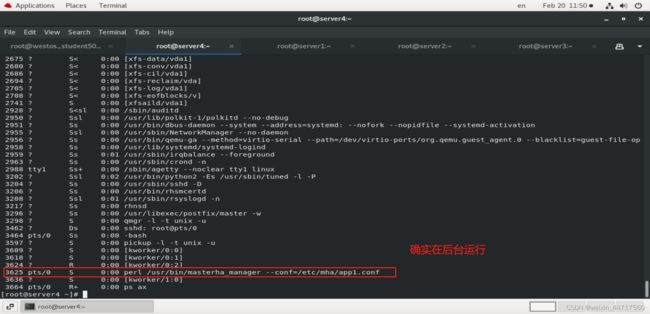
此时MHA 就在监控我们的集群呢,
如下图,可以找到它的监控日志:
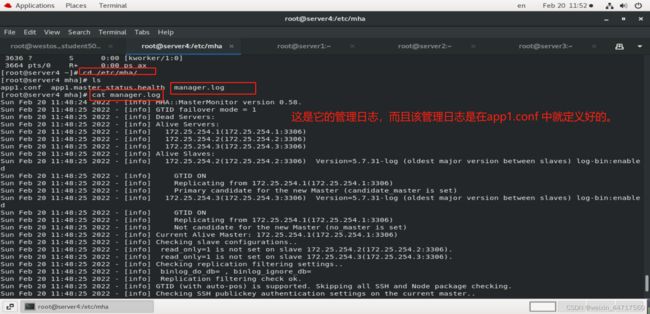
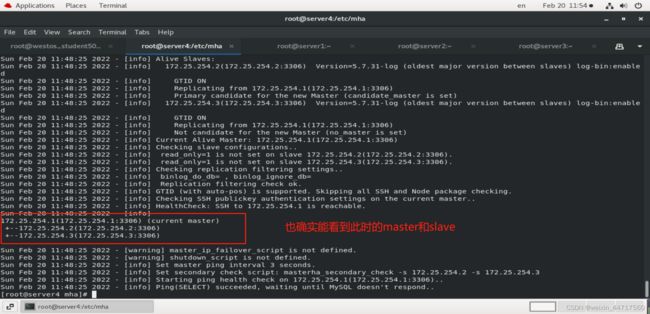
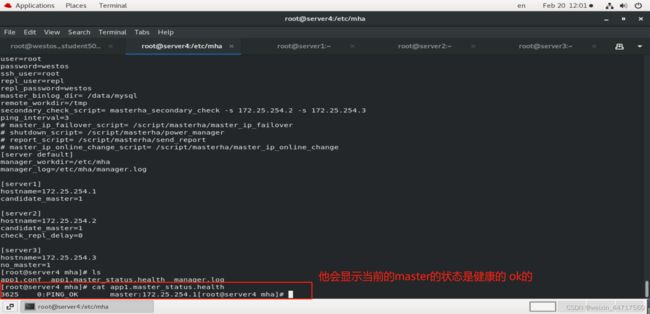
ok,上述设置及检测都没有问题,那我们接下来进行测试。
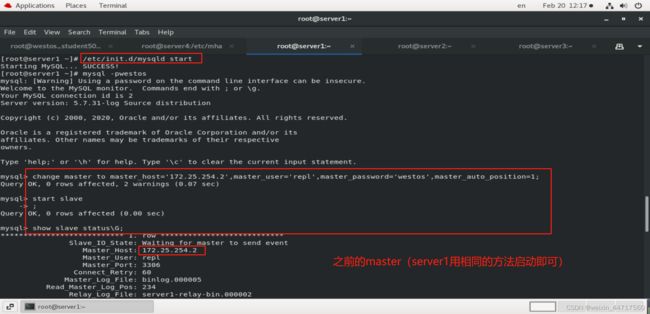
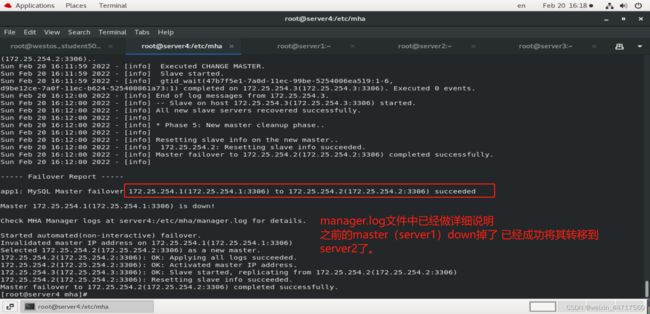
我们像之前一样停掉master(server1)的mysql
[root@server1 ~]# /etc/init.d/mysqld stop
Shutting down MySQL… SUCCESS!
然后可以在MHA的manager端看到如下图所示的样子:
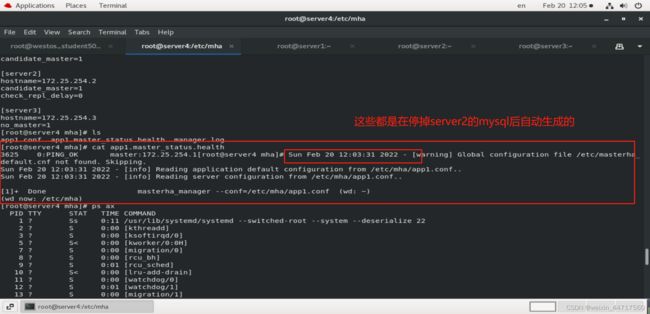
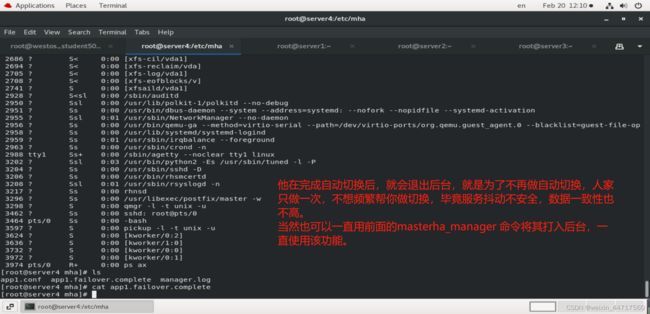
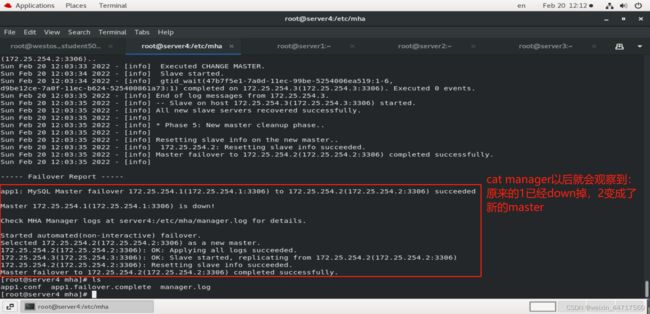
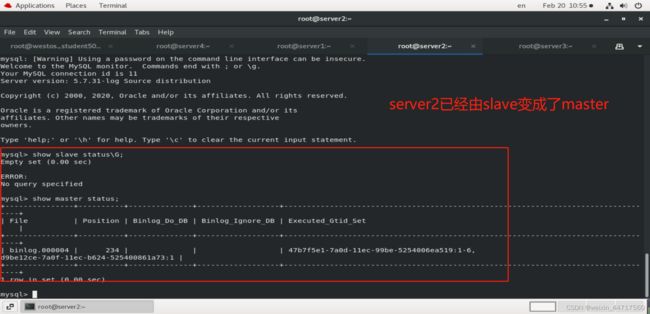
我们在server2中进行 测试:
发现server2已经成为新的master,server3也指向了254.2
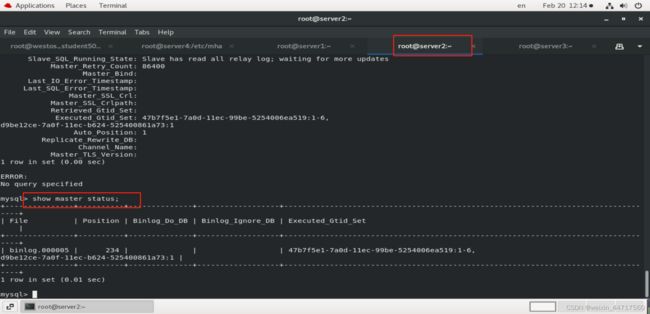
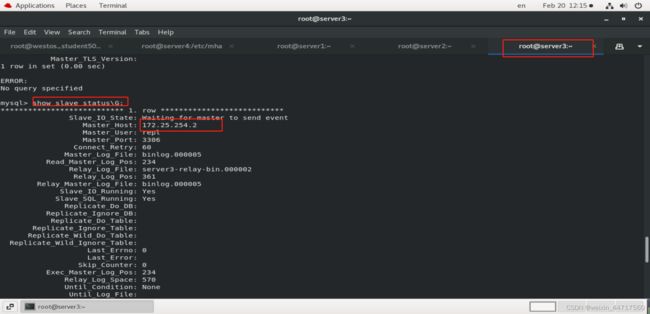
至于谁是下一个master也是在app1.conf中定义好的,
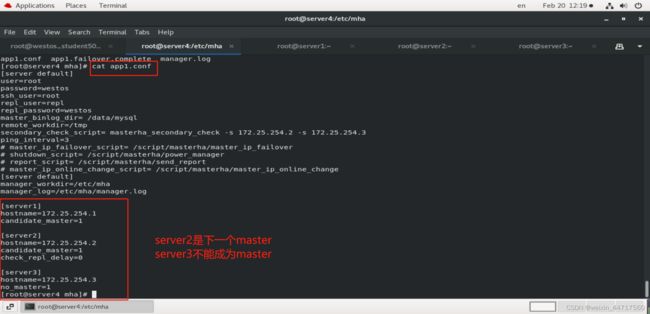
以上,手动切换与自动切换都实现!
四、设置vip漂移
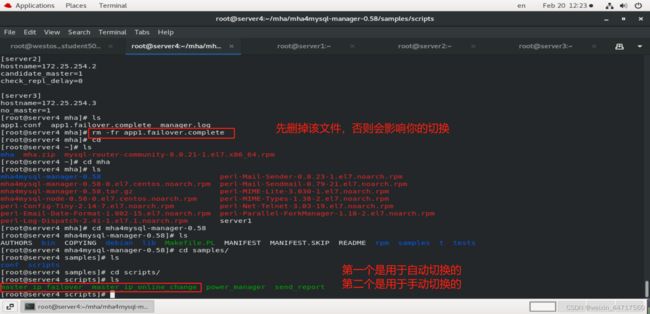
上图中最后一行的四个绿色文件都是脚本,但是都没有写全,但是他们还是模板,得依靠他们来进行完善。
power manager是用来控制电源管理的,实现服务器断电的,比如有的时候他停不掉,可以用它来解决。
send report 是用来发送报警,就是节点发现故障以后,他进行切换,切换完以后把切换的信息以邮件的方式发给你,提醒你我已经做过数据库切换了,你来看看。
操作如下:
step1:打开下图两个注释,并修改路径等相关内容
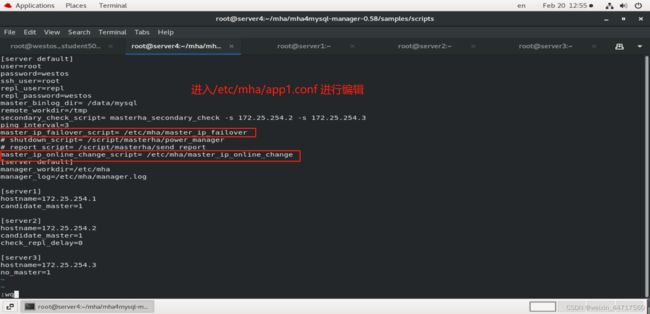
step2:向该文件添加可执行权限
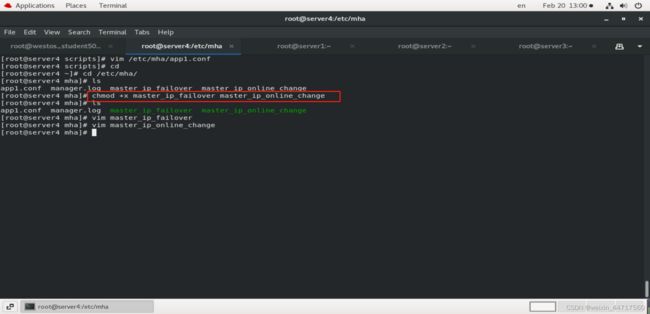
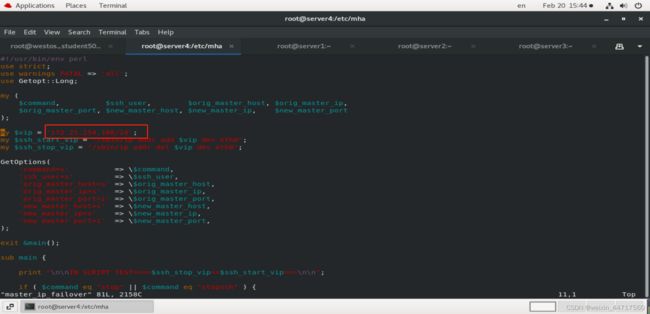
step3:观察这个两个文件中的vip为254.100
测试一:手动切换脚本
step1:手动添加vip
此时server2是master ,1和3都是slave ,所以可以向server2中手动添加vip(虚拟ip)
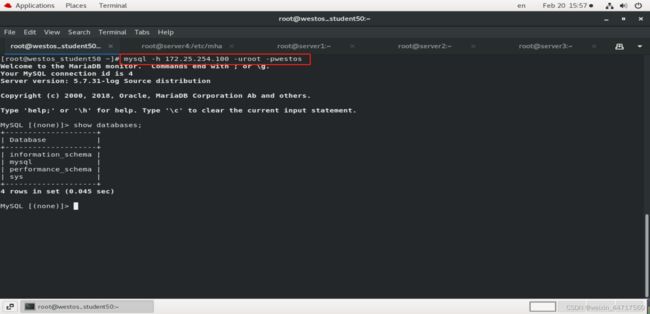
step2:在客户端中测试
客户端通过vip访问mysql数据库
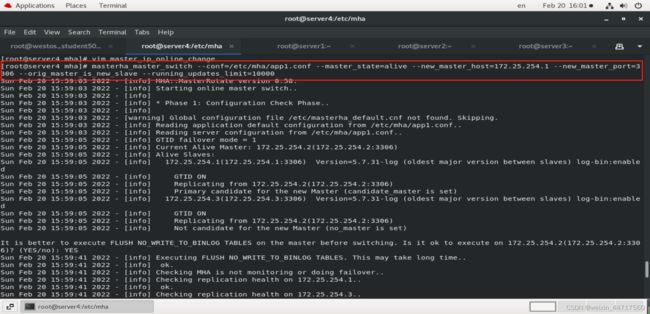
step3:手动切换master到server1
step4:客户端查看
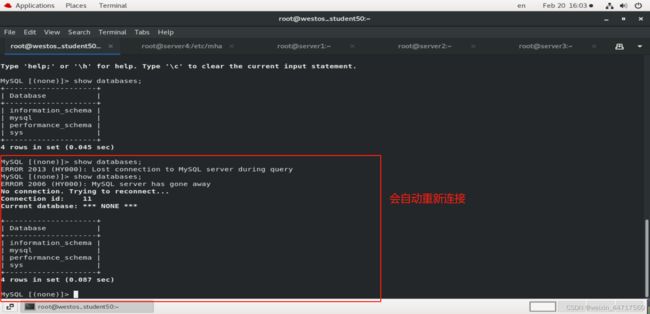
这是因为vip已经从server2变到了server1中,
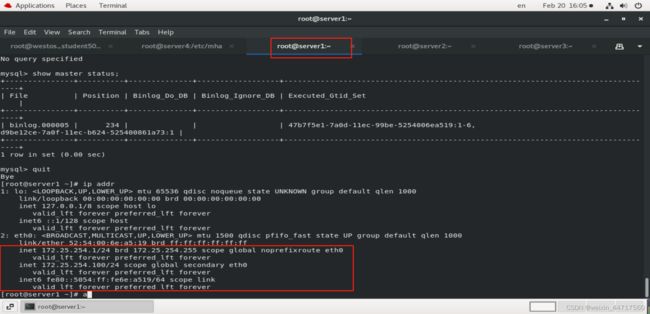
测试二:自动切换脚本
step1: 确认vip在server2或1中
step2:执行自动切换的命令并打入后台,命令如下:
masterha_manager --conf=/etc/mha/app1.conf &
step3:手动停掉master(server1)上的mysql服务
[root@server1 ~]# /etc/init.d/mysqld stop
Shutting down MySQL… SUCCESS!
step4:在服务端检查
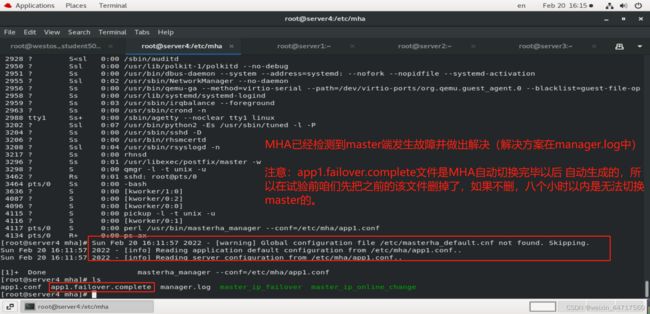
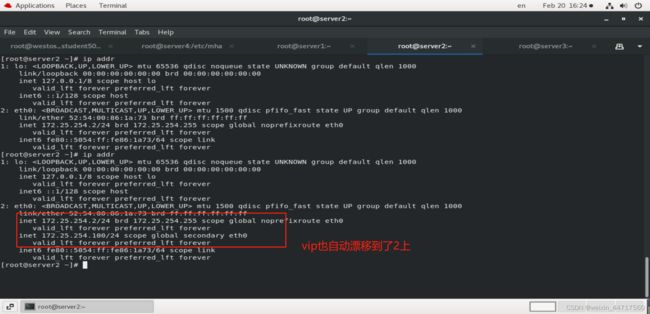

此时还是要注意一下:在进行切换时,一定要注意–ignore_last_failover选项,刚刚我们在做实验前是把app1.failover.complete文件删掉了,如果我们不加该选项,那么自动切换是没办法进行的(时间不够8小时)。