Python网络爬虫实战
爬取豆瓣电影top250
1、准备工作
2、构造网页链接
3、正式爬取网页
4、信息筛选
5、综合输出方法
6、保存爬取内容
1、准备工作
(1)安装python和jupyter环境:window+r输入cmd回车:
(2)使用pip install jupyter命令安装jupyter编辑环境,如下:
2、构造网页链接
(1)新建一个文件夹,在文件夹上方法输入cmd回车:

![]()
结果:
(2)输入jupyter notebook回车:
结果:
(3)点击New,然后选择python3:
(4)在谷歌浏览器中搜索豆瓣电影top250,分别复制前面的几个页面的链接,分析链接中存在的规律。
第一页https://movie.douban.com/top250或https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
第四页:https://movie.douban.com/top250?start=75&filter=
直接跳到第十页:https://movie.douban.com/top250?start=225&filter=
然后再返回去看第一页:https://movie.douban.com/top250?start=0&filter=
#由1-4页的链接不难看出每个页面链接的start这个变量的值相差25因此我们直接跳到第十页,然后再返回第一页观察发现任然符合之前发现的规律。
利用发现的规律一次性构造10个链接:采用for循环,代码如下:
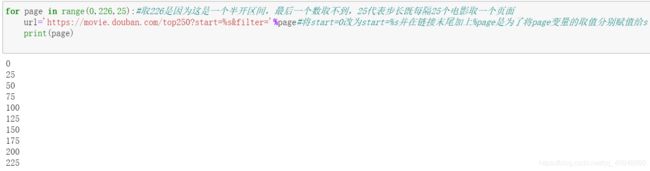

3、正式爬取网页
(1)请求网页源代码
安装request库:使用命令pip install request:

以请求第一页为例,请求网页代码如下:
 (2)到豆瓣top250上进行代码审查:
(2)到豆瓣top250上进行代码审查:
右键单击,选择检结果如下:
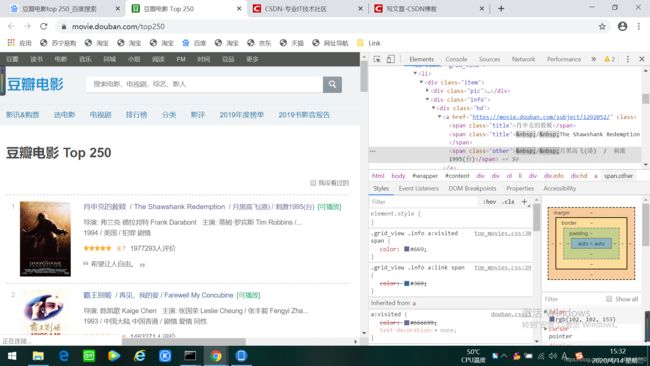
点击notework然后再点击headers结果如下:
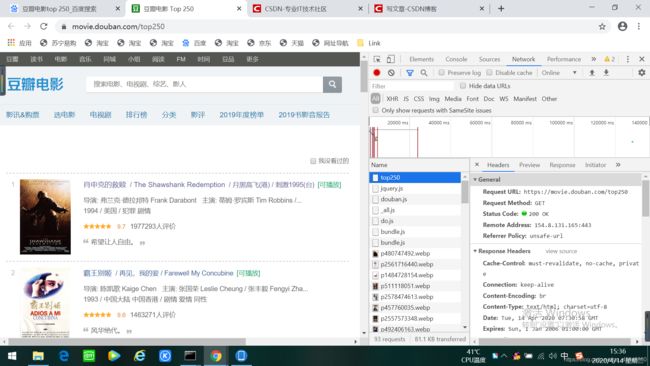
在上图中我们就可以看到网页的获取方法。
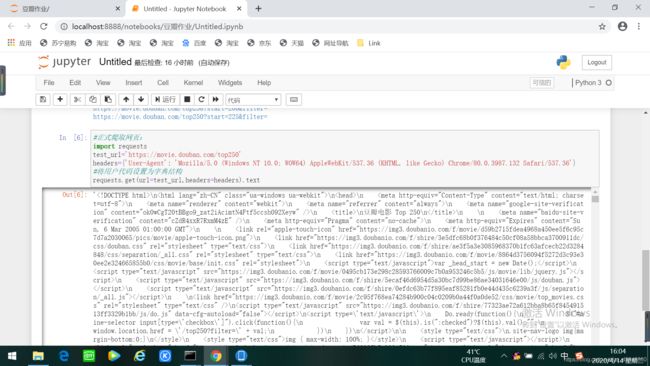
(3)开始请求网页:
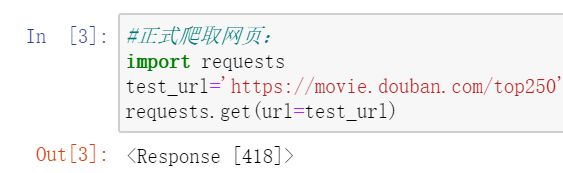
返回结果为418是因为浏览器识别出这个语句是爬虫语句,所以拒绝返回值。所以就需要伪装程序才能得到我们想要的内容:
(4)伪装程序
将程序伪装为正常的用户访问,躲过浏览器的识别,就可以成功获取数据,首先将代码审查中的用户代理代码复制过来,并将其构造成一个字典。用户代码如下: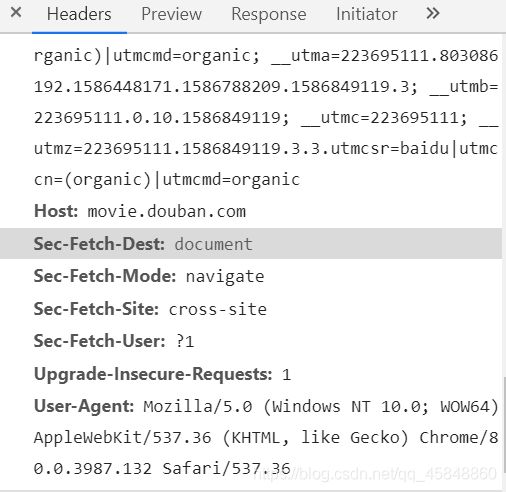
下图就是用户代码将它复制

将代码构造成字典结构,如下:
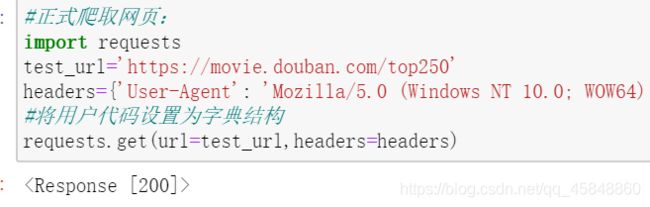
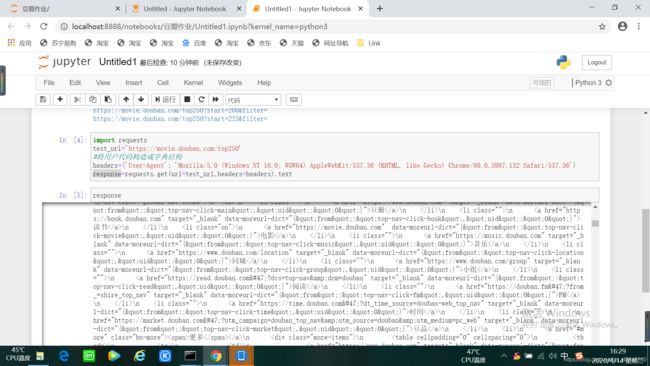
最后在代码后加.text就得到文本形式的返回值:
将获取的结果赋值给response,这样可以隐藏返回结果:
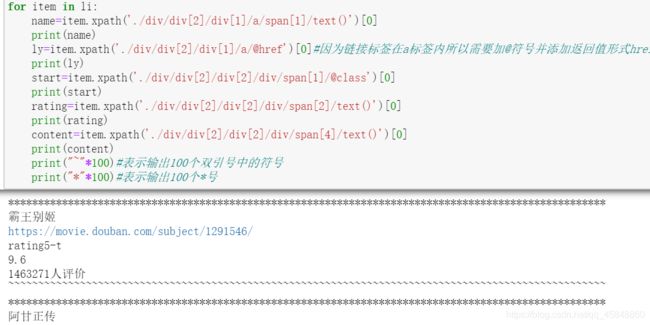
4、信息筛选
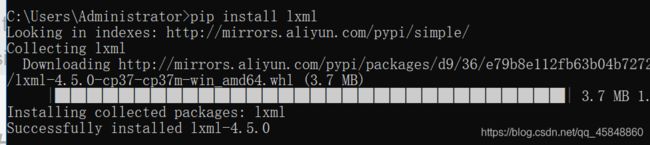
(1)安装lxml库:使用pip install lxml命令安装:
(2)过滤

(3)正式在网页中提取需要的信息:
在浏览器中右键单击选择检查,然后选中需要提取信息处右键选择copy在选择copy xpath,最后回到编辑环境中粘贴,在地址后面添加/text()这样可以让返回值以文本方式返回。

xpath的使用方法:
①:过滤名.xpath(‘要提取信息的xpath路径’)
②:如果要以出文字显示吗、内容则为:
过滤名.xpath(‘要提取信息的xpath路径/text()’)
③:如果要单独提取文字则为:
过滤名.xpath(‘要提取信息的xpath路径/text()’)[0]
(4)复制整个网页的xpath路径:
打开网页,右击检查元素找到每个电影模块对应的序列代码,如下图:
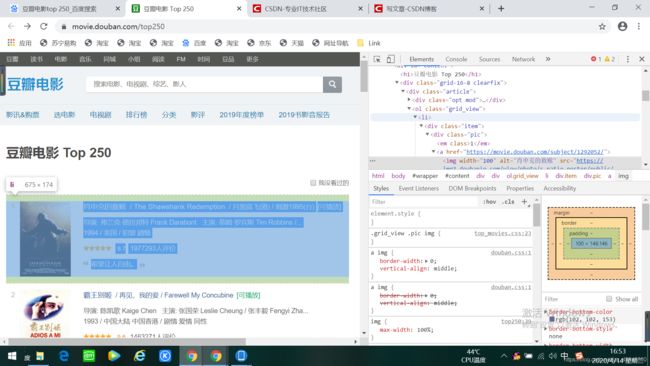
将图中右侧鼠标选中的位置的xpath路径复制下来,其他的电影的xpath路径也用同样的方法复制,结果如下图:
由上图可以发现每个电影的xpath路径是有规律的,及最后一个标签li[]中的数字从1开始逐一增加。接下来用一条语句来表示它们的xpath路径,如下:

共有25个返回值,可以用len()函数查看返回值的长度,如下图: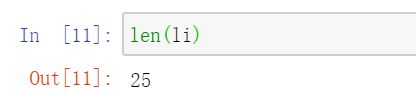
(5)获取每个电影的名字
①:从上面的分析结果可以知道,25个路径中,一个路径中有10电影名称,共250个。进入浏览器,右击电影名称出点击检查,在弹出的代码框中对应的电影名称处右击copy all xpath,结果如下:

由于上面的li标签处的值已经被模糊了,所以获取名称是只需要取li标签后面的部分就可以,这样就取了第一个页面内的所有电影名称的共同特征的部分。代码及运行结果如下:
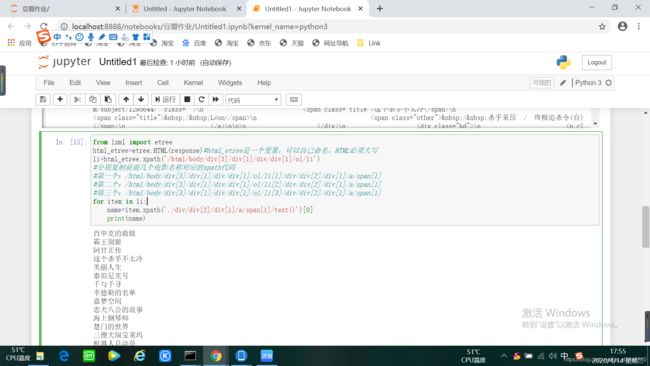
(5)获取电影链接(与获取电影名称方法一致)代码如下图: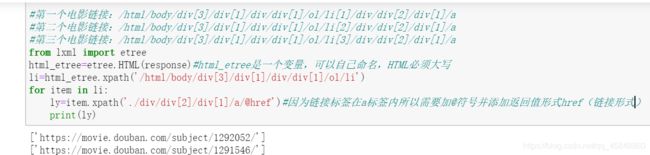
@href为输出链接时必须加上的后缀。
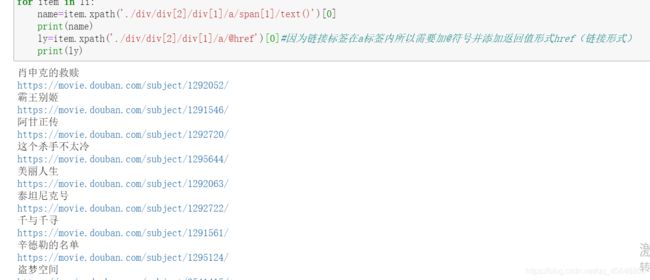
(6)获取电影星级,结果如下图:
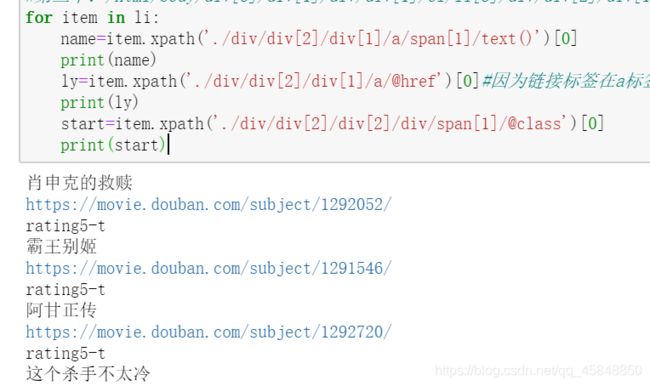
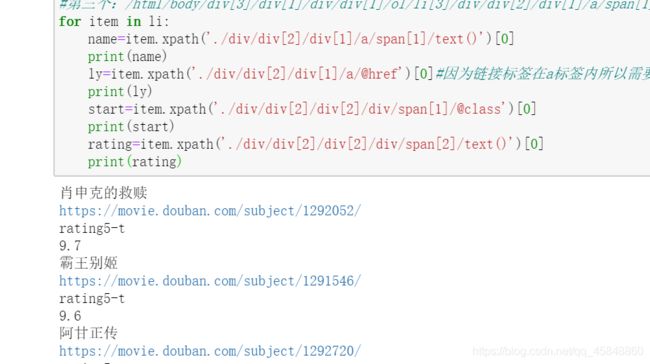
(7)获取电影评分,结果如下:
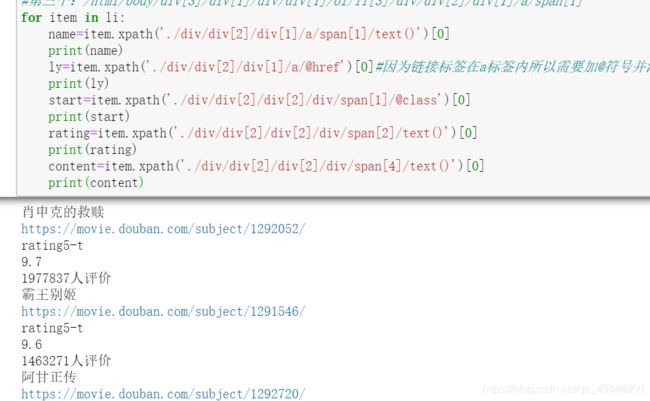
(8)获取电影评价人数,结果如下:
5、综合输出方法