调用chatgpt的api, 必须知道的三件事
牙叔教程 简单易懂
调用api的代码
let url = "https://api.openai.com/v1/completions";
let answer = await axios // 使用axios发送post请求
.post(url, data, { headers: headers })
.then((res) => {
return res.data.choices[0].text.trim();
})
.catch((err) => {
console.log(err.response.data);
return "error";
});
很简单吧, 就是一个post请求
调用api须知
字符限制
问题+答案<4000, 单位是token; 一个英文算1个token, 一个汉字算2个token;
也就是说, 问题和答案总的字数不能超过2000汉字, 不能超过4000英文;
token价格
一般大家使用的模型是 Davinci, $0.02每个token
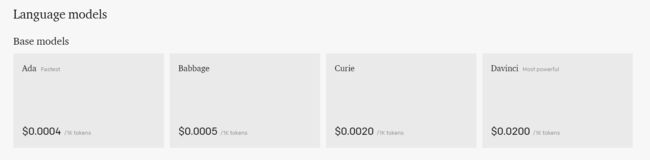
图片模型的token价格

其他产品的token价格


什么是token
你就认为一个token就是一个英文单词就可以了.
一个汉字算2个token

一次提问怎么计算价格
翻译一下就是:
一次问花费的tokens = 问题tokens + 答案tokens

破解字符限制
问题别超过1000个字符, 超过的字符就舍弃; 给答案留下1000个字符的空间, ;
根据自己的实际情况决定舍弃那些文字, 问题和答案的文字数量比例,
比如你要2000个字的答案,
那么就提问100个字的问题, AI 最多回答1900, 差不多也算2000字
if (data.prompt.length > 1000) {
data.prompt = data.prompt.slice(-1000);
}
有没有上下文
比如你问了 AI 两个问题, 然后你问AI : 我上一个问题是什么?
AI 回答: XXXX,
如果他回答正确, 那说明就有上下文, 回答错误, 就说明没有上下文;

创建上下文
post提交数据的时候, 把之前所有的对话都提交上去, 这样就有了上下文;
比如, 你把之前的对话, 存到一个数组里面, 提交数据的时候, 把数组里面的元素用
\n\n
连接起来, AI 就会识别你上传的对话内容, 就有了上下文
getPreviousConversationContent(data) {
var len = data.length;
let arr = [];
for (var i = 0; i < len; i++) {
let item = data[i];
arr.push(item.content);
}
return arr.join("\n\n");
}
使用时间
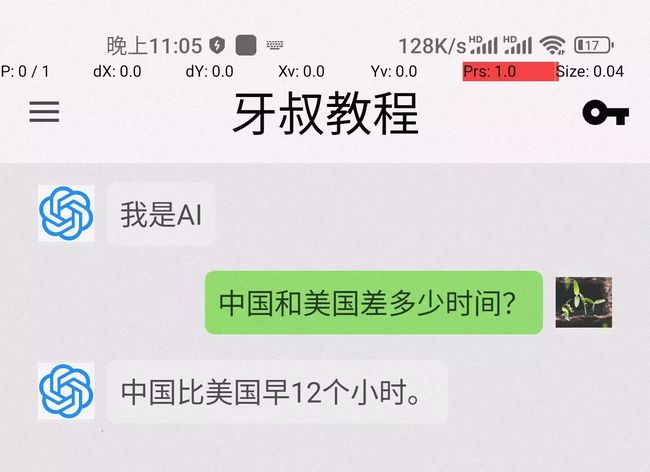
中国和美国差12到13个小时, 中国人多, 美国人也多, 人多了服务器就卡,
所以, 晚上我们使用的时候, 服务器容易报错, 白天报错就少;
封号
除了服务器错误, 另一个常见的报错就是 封号, 真的头大;
这个就只能换号了;
如果有钱, 就去订阅正版;20美金一个月;

环境
设备: 小米11pro
Android版本: 12
Autojs版本: 9.3.11
名人名言
思路是最重要的, 其他的百度, bing, stackoverflow, github, 安卓文档, autojs文档, 最后才是群里问问 --- 牙叔教程
声明
部分内容来自网络 本教程仅用于学习, 禁止用于其他用途