Java学习笔记(二十四)—— HashMap
终于到了一个比较硬核的数据结构,其实之前数据结构课讲过如何用c++实现hashmap的思路,Java也有自带的hashmap这个数据结构。
今天联系二者经验,彻底做一次梳理,并基于已有的java hashmap做一些些分析,他为什么设计思路是这样的。以及如果自己手撕一个hashmap要怎么设计。
hashmap出现原因
存连续的数据。
一开始我们用的是数组或者链表来存储数据,但明显的:数组需要开一块连续的空间存放数据,当需要插入或删除某个数据的时候,因为需要维护连续性,所以要循环将数据进行移动,操作复杂且开销大;于是出现了链表,只有相邻之间有指向关系,插入、删除节点很方便,但是想要查找某个节点的时候由于没有下标,就必须从头开始按照指向顺序对链表进行遍历,这又是一个O(n)操作,比较复杂。
于是hashmap应运而生,链表+数组,让增删改查都很方便。具体怎么方便的↓
hashmap长啥样(基于java实现的hash大家族)
概述实现过程:
保留数组的索引来找数据,保留链表的结点指向关系实现增删。
hashmap首先有一个数组:数组大小我们先设为L,每个位置我们存放的是一个链表(的首地址)。我们存入的数据是一个Node节点类,可以看做一个键值对key——value,key相当于是一个索引,用来判断存在数组哪一个位置,key到数组映射的方法通过hash函数来实现。(目前来说最简单的一种就是key转化成hashcode然后对数组长度L取余,是多少就存在那个数组对应的链表)。存放数据插入到对应数组的链表的末尾。删除就指定key,找到存放这个数的链表,然后遍历链表,哪一个key与所求的相符合,就是这个数据,停止搜索。删改查操作都是基于刚刚的找的过程+删除(将链表删除节点之前的那个节点的后继指向后一节点)/+调用修改结点value的方法。
ps:每个节点的key是唯一的,但是value可以重复。
结点Node:
属性:
K key //映射数组index,唯一
V value //这个数据实际值
Node next //后继节点方法:
构造方法(空参数;只有key、value;key、value、next 都有)
所有属性各自的set、get方法
链表linker:
属性:
Node root //根节点 没有值,head前面的结点
Node head //头结点 第一个Node(其实可设置也可不设置)
Node tail //尾节点 最后一个Node
int size //当前节点个数方法:
构造函数(初始化一个根节点)
增加节点 addNode //头插、尾插都可以
删除节点 deleteNode //从头遍历链表查找key=目标key的结点,然后删除
查找节点 getNode //从头遍历链表查找key=目标key的结点
修改结点 changeNode //从头遍历链表查找key=目标key的结点,修改value为目标valuehashmap:
属性:
ArrayList list //Linker类型数组,每个位置都存放一个链表
int size //数组大小
int defaultSize //默认数组大小
方法:
构造函数,为数组开辟空间,初始化数组存放链表 (空参数<设置数组为默认大小>,传入数组大小size)
setdata //插入数据
deletedata //删除数据
searchdata //查找数据
updatedata //修改数据
hash //hash算法得到key——数组索引index的映射
hashmap存在的问题 —— hash冲突
原本没有链表的时候,想的是,通过key可以直接算出存在数组的哪一个地方,然后直接将数数字存放在这个地方,但是很明显这种映射机制会导致虽然两个节点的key—value不相同,但是不同的key有可能映射到同一个索引index,这就叫做发生了hash冲突,已经有数据的话也不能覆盖,我们已经想到了解决办法——就是每个数组这个地方不放数字,而是放一个链表,把算出index相同的元素按顺序插入到这个链表中。
但是我们自然可以想到——尽管这是很棒的解决办法,但是不能总是这样,最后所有数字都映射到同一个链表了我还要数组干啥,我们期望的是数据尽量可以平均地映射到几乎每个数组(雨露均沾),让各个链表差不多长。链表的角度是发生了怎么办,于是乎还有另一个可以改进的思路——让他尽量不要发生——减少冲突——改进映射算法(hash算法)。
这也使得hash算法成为hashmap的核心。(总感觉在存放结构做优化是一种辅助,hash算法的改进才是解决问题的根本,但显然没有说的这么容易~)
hashmap元素 —— hash算法
hash算法有很多种
- key.hashcode取余:对key求hashcode,hashcode对数组规模取余的结果就是数组的索引。
- 将key.hashcode高16位异或低16位转成32进制然后再对数组长度取余。
- ……
hashmap边角问题
1.散列因子:也称装载因子、负载因子(load factor)。计算方法根据hash算法和解决hash冲突方式的不同而又有不一样的含义(衡量重点不同)
- 衡量hashmap填充满的程度(密集程度):散列因子 = 元素个数/数组大小
- 衡量(个人认为是平衡程度):散列因子 = 非空的链表个数/总链表个数
当散列因子达到某个阈值的时候,就会触发扩容机制,扩大多少也是不一样滴。hashmap直接扩大2倍,而hashTable是2*当前size+1
散列因子阈值设定也是一个技术活:(我们拿第二种计算方法来讲,java源码底层实现是这么算的)
当散列因子过于大的时候,就是每个数组里面的链表都至少有一个元素,这时候发生冲突的可能性增大,链表不断增长,当改为红黑树的时候,很多红黑树会导致hashmap整个很复杂,虽然空间利用率很好,但是查询元素的时候时间效率不高;当散列因子很小的时候,意味着你刚刚填了几个数据,基本还有很多的数组没用,链表是空的,就要去扩大hashmap,这样就浪费了很多空间。
因此需要找一个折中方案,同时权衡空间效率、时间效率。默认给定的的load factor就是0.75。(感觉是一个概率统计问题,大量做数据模拟或许可以求得一个最高点)
下面是API原文描述:
![]()
2.链表不能过长——当某条链表过长的时候就会不平衡,让hashmap失去了原有效率高的优势(否则还是那句话和链表没啥区别了)
当链表达到一定的长度的时候,将链表转为红黑树储存(提高查找效率)。
(这里实现机制还需要看看API文档)
3.当一个Node节点的key为null的时候没有hashcode值,应该特殊处理。
java中一些与hashmap有关的其他东西(hash-)
hashmap和hashTable的区别
简单说最大的区别就是hashmap是针对单线程,hashTable针对多线程(多个线程同时操作数据有争夺风险,加入多线程安全有关的内容)
其他还有一些机制设计的不同
——>贴大佬文: HashMap和Hashtable的区别(绝对经典)_棉花糖one.的博客-CSDN博客
hashcode
- hashcode是java中每一个对象都有的一个唯一值hashcode,是通过物理地址转换整数,然后通过映射方法得到的。不同的数据类型有不同计算hashcode的方式,但保证的是每个不同的对象hashcode不同。
- 例如String对象hashcode的计算方式:

- null没有hashcode。
- 可以通过hashcode()方法获得这个对象的hashcode。
- 和hashmap的联系:在求index的时候用到了hashcode。
hashmap —— 从更高的角度看待hashmap
以上所讲的全部内容基本都是基于java源码实现的角度来讲解hashmap的,包括介绍具体实现的框架设计、一些hash冲突的解决办法(加个链表+改进hash函数)、hash函数、优化机制等等。
但是我当初听数据结构课并不是这样讲的,是一个更高的设计的角度:我简述一下思路
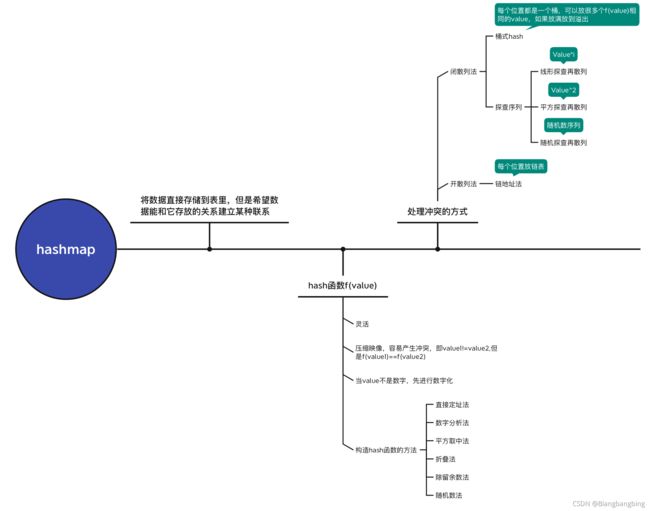
可以看出java的hashmap的设计模式就是链地址的方法处理冲突,并引入一个key值来计算数组索引index。
贴一个偶然看到的大佬的分析:
Java基础之jdk8 HashMap源码解读_we.think-CSDN博客