【爬虫】案例04:某小说网多线程小说下载
时光轮回,冬去春来,转眼时间来到了2023年4月。天空沥沥淅淅下着小雨,逐渐拉上了幕布。此刻,正值魔都的下班高峰,从地铁站出来的女孩子纷纷躲到一边,手指飞快的划过手机屏幕,似乎在等待男朋友送来的雨伞,亦或者是等待滴滴专车的到来,其中也不乏一些勇敢的女孩子,带上帽子,加快步伐,快速的消失在熙熙攘攘的人群中。此时,一名不起眼的少年,从人群中快速的走了出来,似乎没有注意到天空中的雨滴,迈着有力的步伐,直径冲向一家小饭馆,饭馆老板熟悉的上了他常吃的套餐,炒米粉,加素鸡和卤蛋,一顿狼吞虎咽之后,又快速起身,转身向出租屋的方向走去,穿过一段昏暗的小路,他抬起头仰望天空,清凉的雨滴打在脸上,使他疲惫的身心得到了一丝的清爽,不由得又加快了步伐,随后彻底消失在茫茫夜色中。因为他今天要创作博客,案例04:某小说网多线程小说下载
本案例仅供学习交流使用,请勿商用。如涉及版本侵权,请联系我删除。
目录
一、多线程爬虫
1. 多线程爬虫
2. 队列多线程爬虫的思路
3. Queue的使用方法
4. 生产者和消费者模型
5. 生产者消费者模型代码示例
二、某小说网多线程爬虫
1. 需求分析
2. 生产者类
3. 消费者类
4. 主函数
三、总结分析
一、多线程爬虫
1. 多线程爬虫
接上一篇文章,案例03:某图网图片多线程下载,不懂得先去看进程和线程。我们都知道线程是抢占式资源,那必然就会存在下面几个问题:
- 线程间竞争和协作问题:多个线程同时访问共享资源时,容易出现竞争和协作问题。例如,当多个线程同时对同一个变量进行修改时,可能会导致数据的不一致性;
- 有的线程抢的多,有的线程抢的少,不能大幅度的提高爬虫的效率的问题;
- 在进行I/O操作时,致使数据缺失;
为了解决这些问题,我们引入队列多线程爬虫。
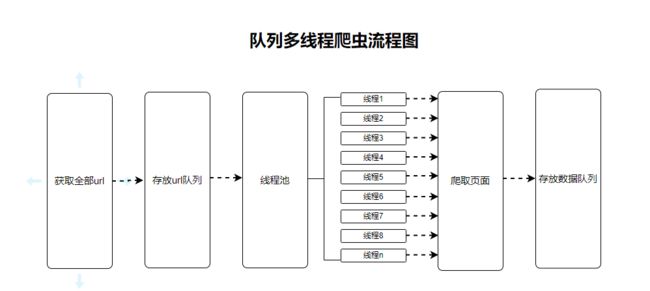
2. 队列多线程爬虫的思路
队列(queue)是计算机科学中常用的数据结构之一,它是一种先进先出(FIFO)的数据结构,类似于现实生活中的排队等待服务的过程。我们使用队列进行多线程爬虫,基本思路为创建两个队列,一个用来放url,一个用来放从url获取的结果数据,最后对结果数据进行清洗,得到我们想要的数据,下面介绍一下使用队列爬虫的创建过程和注意要点:
-
创建任务队列:首先需要创建一个任务队列,用来存储所有需要爬取的URL地址。可以使用Python内置的Queue队列,也可以使用第三方库如Redis等来实现。
-
创建线程池:创建一个包含多个线程的线程池,每个线程都会从任务队列中获取一个待爬取的URL地址进行处理。
-
编写爬取逻辑:在每个线程中编写一个爬取逻辑,用于从队列中获取一个URL地址并发起请求,获取网页内容并解析数据。具体的爬取逻辑可以根据实际需求进行编写,例如使用requests库进行网页请求,使用BeautifulSoup等库进行网页内容解析。
-
启动线程池:启动线程池,让所有线程开始处理任务队列中的URL地址。每个线程都会循环执行自己的爬取逻辑,直到任务队列为空为止。
-
添加异常处理:在爬取过程中,可能会出现各种异常情况,例如网络请求超时、网页内容解析错误等。为了保证程序的稳定性,需要添加相应的异常处理逻辑,例如重试机制、错误日志记录等。
-
控制并发度:为了防止对网站造成过大的负载压力,需要控制爬取并发度。可以通过控制线程池中的线程数、限制每个线程的请求频率等方式来实现。
-
数据存储:爬取到的数据需要进行存储,可以使用文件、数据库等方式进行存储。同时还需要考虑数据去重、数据更新等问题。
3. Queue的使用方法
| 方法 | 描述 |
|---|---|
queue.Queue([maxsize]) |
创建一个FIFO队列对象。maxsize为队列的最大长度,如果未指定或为负数,则队列长度无限制。 |
q.put(item[, block[, timeout]]) |
将元素item放入队列中。如果队列已满且block为True,则此方法将阻塞,直到有空间可用或者超时timeout。如果block为False,则此方法将引发一个Full异常。 |
q.get([block[, timeout]]) |
从队列中取出一个元素并将其返回。如果队列为空且block为True,则此方法将阻塞,直到有元素可用或者超时timeout。如果block为False,则此方法将引发一个Empty异常。 |
q.empty() |
检查队列是否为空。如果队列为空,则返回True,否则返回False。 |
q.qsize() |
返回队列中元素的数量。这种方法不可靠,因为在多线程情况下,队列长度可能会发生变化。如果要获取准确的队列长度,建议使用锁来保护队列。 |
q.queue.clear() |
清空队列中的所有元素。这种方法不是线程安全的,因此在多线程情况下需要使用锁来保护队列。 |
4. 生产者和消费者模型
生产者-消费者模型是一种并发编程模型,常用于处理大量数据的情况。在爬虫中,生产者-消费者模型被广泛应用于提高爬取效率和降低爬虫对目标网站的压力。
生产者-消费者模型通常由两部分组成:生产者和消费者。
- 生产者负责从目标网站爬取数据,并将这些数据存储到一个共享的数据结构中,如队列或缓冲区。
- 消费者从共享的数据结构中读取数据,并进行处理,例如解析数据、存储数据或者再次发送请求。
生产者-消费者模型的优势在于能够有效地处理大量数据,同时减少对目标网站的压力。通过将数据的爬取和处理分离开来,可以减少因为网络延迟或者其他原因导致的爬取效率低下的问题。此外,由于消费者和生产者可以独立运行,因此可以使用多线程或者多进程来实现并发处理,提高爬虫效率。需要注意的是,生产者-消费者模型也可能带来一些问题,例如线程同步和共享数据结构的访问冲突等。为了避免这些问题,需要在实现过程中仔细考虑线程安全和并发访问控制等问题,以确保程序的正确性和性能。简单画了一下生产者-消费者模型的流程图:
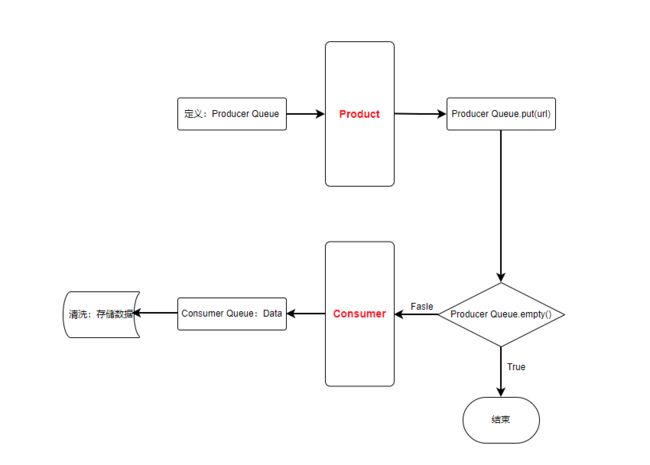
基本的思维逻辑为:
- 创建一个共享的任务队列。
- 创建若干个生产者线程,每个生产者线程负责生成任务并将其放入任务队列中。
- 创建若干个消费者线程,每个消费者线程从任务队列中取出任务并进行处理。
- 生产者线程和消费者线程之间通过共享的任务队列进行通信。
- 如果队列中没有任务了,消费者线程需要等待新的任务被生产者线程添加到队列中。
- 如果队列已满,生产者线程需要等待队列中的任务被消费者线程取出以便继续向队列中添加新的任务。
5. 生产者消费者模型代码示例
import threading
import queue
import requests
from bs4 import BeautifulSoup
# 生产者线程
class ProducerThread(threading.Thread):
def __init__(self, url_queue):
super().__init__()
self.url_queue = url_queue
def run(self):
# 从网站中爬取所有的文章链接
resp = requests.get('http://example.com/articles')
soup = BeautifulSoup(resp.text, 'html.parser')
for a in soup.find_all('a'):
link = a.get('href')
if link.startswith('/articles/'):
# 将链接添加到队列中
self.url_queue.put('http://example.com' + link)
# 消费者线程
class ConsumerThread(threading.Thread):
def __init__(self, url_queue, data_queue):
super().__init__()
self.url_queue = url_queue
self.data_queue = data_queue
def run(self):
while True:
try:
# 从队列中取出一个链接
url = self.url_queue.get(timeout=10)
# 爬取链接对应的文章内容
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'html.parser')
title = soup.find('h1').text
content = soup.find('div', {'class': 'content'}).text
# 将文章内容添加到数据队列中
self.data_queue.put((title, content))
except queue.Empty:
break
# 主函数
def main():
# 创建队列
url_queue = queue.Queue()
data_queue = queue.Queue()
# 创建生产者线程和消费者线程
producer_thread = ProducerThread(url_queue)
consumer_thread1 = ConsumerThread(url_queue, data_queue)
consumer_thread2 = ConsumerThread(url_queue, data_queue)
# 启动线程
producer_thread.start()
consumer_thread1.start()
consumer_thread2.start()
# 等待线程结束
producer_thread.join()
consumer_thread1.join()
consumer_thread2.join()
# 处理爬取到的数据
while not data_queue.empty():
title, content = data_queue.get()
# 处理文章内容
print(title, content)
if __name__ == '__main__':
main()
使用生产者-消费者模型在爬虫中可以将数据的爬取和处理分离开来,多线程的并发处理可以大大提高爬虫的效率,减少爬虫对目标网站的访问压力,从而降低被封 IP 的风险。但是还需要考虑线程同步、共享数据结构的访问冲突等问题。
二、某小说网多线程爬虫
1. 需求分析
- 我的书架:需要登录;
- 生产者函数:获取一本书的每章节url,储存在队列中;
- 消费者函数:解析url页面,获取数据,存储在队列中;
- 获取消费者队列中的数据,写入本地;

2. 生产者类
生产者类实现session登录,解析页面,将url存储到队列中。
import os
import time
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import threading
import queue
import warnings
warnings.filterwarnings("ignore")
# 生产者类
class ProducerThread(threading.Thread):
def __init__(self, url_queue):
super().__init__()
self.url_queue = url_queue
self.session = requests.Session()
self.headers = {"User-Agent": UserAgent().random}
self.login()
self.book_dict_list = self.get_book_dict_list()
def login(self):
self.session.post(
"url", #此处为登录请求的url
data={"loginName": "152****7662", "password": "******"},# 在此处替换自己的账号密码
headers=self.headers,
verify=False,
)
def get_book_dict_list(self):
res = self.session.get(
"url" #此处为书架的url
).json()
data = res.get("data")
return data
def get_chapter_urls(self, book_id):
url = f"url"#此处为书的章节列表url
page_text = requests.get(url=url).content.decode()
soup = BeautifulSoup(page_text, "lxml")
dl_li = soup.find("div", class_="Main List").find_all("dl", class_="Volume")
urls = []
for dl in dl_li:
chapter_url = ["url" + a["href"] for a in dl.dd.find_all("a")]#网站url
urls.extend(chapter_url)
return urls
def run(self):
for book_dict in self.book_dict_list:
book_id = book_dict.get("bookId")
chapter_urls = self.get_chapter_urls(book_id)
for url in chapter_urls:
self.url_queue.put(url)3. 消费者类
消费者函数,从队列中取出链接,解析页面,获取数据,将数据存储到结果队列中
# 消费者类
class ConsumerThread(threading.Thread):
def __init__(self, url_queue, data_queue):
super().__init__()
self.url_queue = url_queue
self.data_queue = data_queue
# self.session = session
self.headers = {"User-Agent": UserAgent().random}
def run(self):
while True:
try:
# 从队列中取出一个链接
url = self.url_queue.get(timeout=10)
page_text = requests.get(url=url, headers=self.headers).content.decode()
soup = BeautifulSoup(page_text, "lxml")
chapter_title = soup.find("div", class_="readAreaBox content").h1.string
content_text = soup.find("div", class_="readAreaBox content").find("div", class_="p").text
chapter_text = chapter_title + "\n" + content_text
chapter_text = chapter_text.replace(u"\xa0", "").replace(u"\u36d1", "").replace(u"\u200b", "")
print(f'{chapter_title} ,存入队列')
self.data_queue.put(({chapter_title : chapter_text}))
time.sleep(0.1)
except queue.Empty:
break
except Exception as e:
print(f"{url} 抓取错误...", e)
continue4. 主函数
主函数中,开启了200个线程,获取解析页面和数据存储
# 主函数
def main():
# 创建队列
url_queue = queue.Queue()
data_queue = queue.Queue()
# 创建生产者线程和消费者线程
producer_thread = ProducerThread(url_queue)
consumer_threads = [ConsumerThread(url_queue, data_queue) for _ in range(200)]
# 启动线程
producer_thread.start()
for consumer_thread in consumer_threads:
consumer_thread.start()
# 等待线程结束
producer_thread.join()
for consumer_thread in consumer_threads:
consumer_thread.join()
# 处理爬取到的数据
book_path = os.path.join("./结果数据/案例04:某小说网多线程小说下载")
if not os.path.exists(book_path):
os.mkdir(book_path)
while not data_queue.empty():
chapter = data_queue.get()
for title in chapter:
chapter_text = chapter[title]
chapter_path = os.path.join(book_path, f"{title}.txt")
try:
with open(chapter_path, "w", encoding='utf-8') as f:
f.write(chapter_text)
except Exception as e:
print(f"{title} 写入错误...", e)三、总结分析
本章使用消费者-生产者模型进行了多线程的数据采集,提升了爬虫效率;使用了队列,可以将生产者线程抓取的章节链接存入队列,等待消费者线程进行抓取,避免了生产者和消费者之间的阻塞和同步问题。
但是,在执行多线程的时候,线程数量数固定的,没有根据具体需求来动态调整,可能会导致效率不高或者浪费资源。没有使用线程池来管理线程的生命周期,可能会导致线程过多、创建线程时间过长等问题。在下一章中我们通过创建线程池的方式来管理线程,继续提高爬虫的效率。附全部代码:
import os
import time
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import threading
import queue
import logging
import warnings
warnings.filterwarnings("ignore")
# 生产者类
class ProducerThread(threading.Thread):
def __init__(self, url_queue):
super().__init__()
self.url_queue = url_queue
self.session = requests.Session()
self.headers = {"User-Agent": UserAgent().random}
self.login()
self.book_dict_list = self.get_book_dict_list()
def login(self):
self.session.post(
"url",#此处为登录界面的url
data={"loginName": "152****7662", "password": "******"},#在此处替换自己的账户密码
headers=self.headers,
verify=False,
)
def get_book_dict_list(self):
res = self.session.get(
"url"#此处为书架的url
).json()
data = res.get("data")
return data
def get_chapter_urls(self, book_id):
url = f"url"#此处为书本章节的url
page_text = requests.get(url=url).content.decode()
soup = BeautifulSoup(page_text, "lxml")
dl_li = soup.find("div", class_="Main List").find_all("dl", class_="Volume")
urls = []
for dl in dl_li:
chapter_url = ["url" + a["href"] for a in dl.dd.find_all("a")]#此处为网站的url进行拼接
urls.extend(chapter_url)
return urls
def run(self):
for book_dict in self.book_dict_list:
book_id = book_dict.get("bookId")
chapter_urls = self.get_chapter_urls(book_id)
for url in chapter_urls:
self.url_queue.put(url)
# 消费者类
class ConsumerThread(threading.Thread):
def __init__(self, url_queue, data_queue):
super().__init__()
self.url_queue = url_queue
self.data_queue = data_queue
# self.session = session
self.headers = {"User-Agent": UserAgent().random}
def run(self):
while True:
try:
# 从队列中取出一个链接
url = self.url_queue.get(timeout=10)
page_text = requests.get(url=url, headers=self.headers).content.decode()
soup = BeautifulSoup(page_text, "lxml")
chapter_title = soup.find("div", class_="readAreaBox content").h1.string
content_text = soup.find("div", class_="readAreaBox content").find("div", class_="p").text
chapter_text = chapter_title + "\n" + content_text
chapter_text = chapter_text.replace(u"\xa0", "").replace(u"\u36d1", "").replace(u"\u200b", "")
print(f'{chapter_title} ,存入队列')
self.data_queue.put(({chapter_title : chapter_text}))
time.sleep(0.1)
except queue.Empty:
break
except Exception as e:
print(f"{url} 抓取错误...", e)
continue
# 主函数
def main():
# 创建队列
url_queue = queue.Queue()
data_queue = queue.Queue()
# 创建生产者线程和消费者线程
producer_thread = ProducerThread(url_queue)
consumer_threads = [ConsumerThread(url_queue, data_queue) for _ in range(200)]
# 启动线程
producer_thread.start()
for consumer_thread in consumer_threads:
consumer_thread.start()
# 等待线程结束
producer_thread.join()
for consumer_thread in consumer_threads:
consumer_thread.join()
# 处理爬取到的数据
book_path = os.path.join("./结果数据/案例04:某小说网多线程小说下载")
if not os.path.exists(book_path):
os.mkdir(book_path)
while not data_queue.empty():
chapter = data_queue.get()
for title in chapter:
chapter_text = chapter[title]
chapter_path = os.path.join(book_path, f"{title}.txt")
try:
with open(chapter_path, "w", encoding='utf-8') as f:
f.write(chapter_text)
except Exception as e:
logging.error(f"Download error: {e}") # 记录下载错误的日志
print(f"{title} 写入错误...", e)
if __name__ == '__main__':
main()
由于版权原因,取消了代码中的url,源码需要的兄弟们网盘自取,提取码:sgss