大数据技术之Hbase
目录
目录
1.部署Hbase(伪分布式)
1.1 安装zookeeper
1.2 安装hbase(伪分布式)
2. 快速上手HBASE
2.1 Hbase介绍
2.1.1 名词解释
编辑
2.1.2 逻辑存储模型
2.1 基础命令
2.2 DDL命令
2.3 增删改查命令
2.4 Hbase的命令空间
2.5 JavaAPI的使用
3. Hbase架构原理
3.1 Region概念解释
3.2 HBase详细架构
3.3 HRegionServer详解
3.4 HRegion详解
3.5 WAL(Write-Ahead Logging) 预写日志系统
3.6 BloomFilter布隆过滤器
3.7 HFile compaction (合并)机制
3.8 Region Split (分裂)机制
3.9 Region Balance策略
4. HBase高级用法
4.1 Scan全表扫描功能
4.2 Scan + Filter案例
4.3 HBase批量导入
4.3.1 批量导入之 MapReduce
4.3.2 批量导入之 BulkLoad
5. HBase调优策略
5.1 预分区
5.2 rowkey的设计原则
5.3 列族的设计原则
5.4 批处理
5.4 Region的request计数
1.部署Hbase(伪分布式)
hbase依赖zookeeper,需要先安装zookeeper
1.1 安装zookeeper
- 1. 安装前准备
1)安装JDK
2)下载zookeeper
- 2. 解压zookeeper安装包到/opt/module/目录下
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/- 3. 修改配置
将/opt/module/zookeeper-3.4.10/conf这个路径下的zoo_sample.cfg修改为zoo.cfg
vim zoo.cfg 修改dataDir路径
dataDir=/opt/module/zookeeper-3.4.10/zkDatamkdir zkData
- 4. 将zookeeper添加到环境变量
vim /etc/profile
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin刷新配置
source /etc/profile
- 5. 启动、查看状态、关闭zookeeper
bin/zkServer.sh start
bin/zkServer.sh status
bin/zkServer.sh stop
bin/zkCli.sh # 启动zookeeper客户端
quit # 退出zookeeper客户端
1.2 安装hbase(伪分布式)
- 1. hbase版本选择
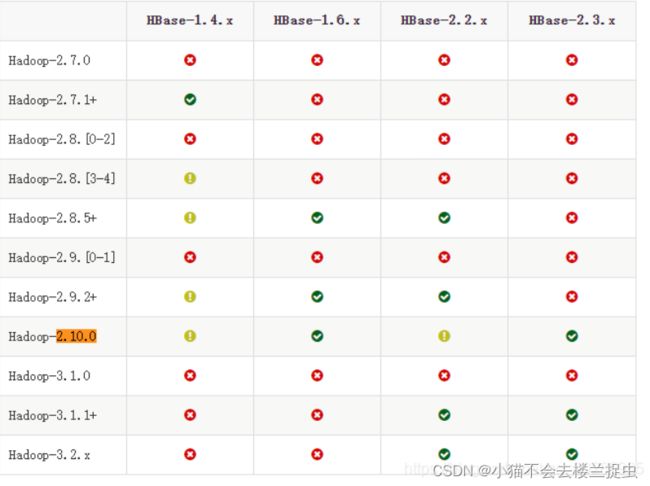
由于安装的hadoop版本是2.7.2 ,因此hbase版本选择1.4.10
- 2. 下载地址
Index of /dist/hbase/1.4.10
- 3. 解压hbase安装包到/opt/module/目录下
tar -zxvf hbase-1.4.10-bin.tar.gz -C /opt/module/- 4. 修改配置文件hbase-env.sh
添加配置
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HBASE_MANAGES_ZK=false
export HADOOP_HOME=/opt/module/hadoop-2.7.2
- 5. 修改配置文件hbase-site.xml
添加配置
hbase.rootdir
hdfs://linux01:9000/hbase
指定hbase在HDFS上存储的路径, 如果Hadoop为高可用版本请把域名改为自己配置的cluster name。比如hdfs://cluster/hbase
hbase.cluster.distributed
true
此项用于配置HBase的部署模式,false表示单机或者伪分布式模式,true表完全分布式模式
hbase.master.port
16000
端口默认60000
hbase.zookeeper.property.dataDir
/opt/module/zookeeper-3.4.10/zkData
此项用于设置存储ZooKeeper的元数据路径
hbase.zookeeper.quorum
linux01:2181
此项用于配置ZooKeeper集群所在的主机地址
hbase.tmp.dir
/opt/module/hbase-1.4.10/tmp
本地缓存目录
- 6. 修改配置regionservers
vim regionservers
linux01- 7. 将hbase添加到环境变量
- 8. 启动、关闭hbase
start-hbase.sh # 启动hbase
stop-hbase.sh # 关闭hbase
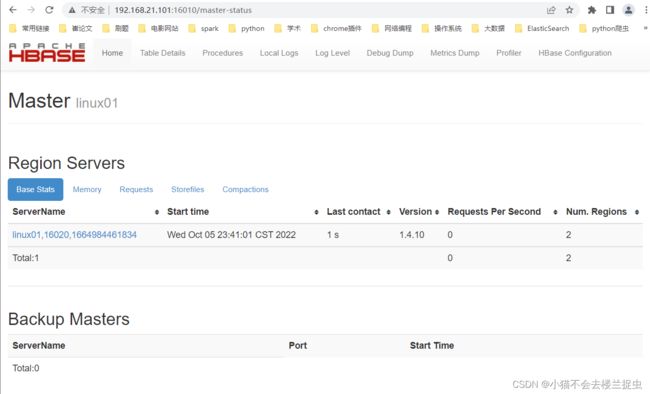
- 9. web 页面
http://192.168.21.101:16010/master-status
2. 快速上手HBASE
2.1 Hbase介绍
2.1.1 名词解释

- 命名空间:相当于MySQL中的数据库
- 行键(rowkey): 相当于MySQL表的主键
- 列族:一系列列的集合,创建表的时候至少要定义一个列族,列不需要定义。
- 数据类型:不管是什么数据类型 在HBASE中存储的时候统一转化为字节数组。
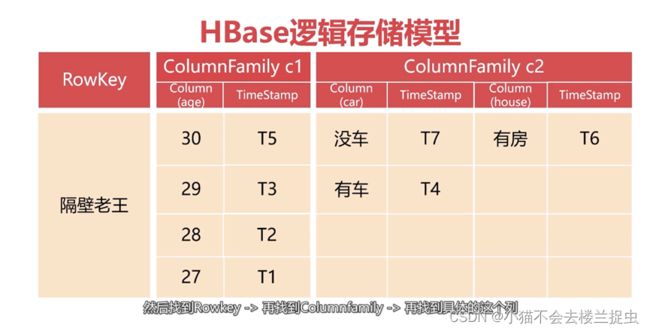
2.1.2 逻辑存储模型

2.1 基础命令
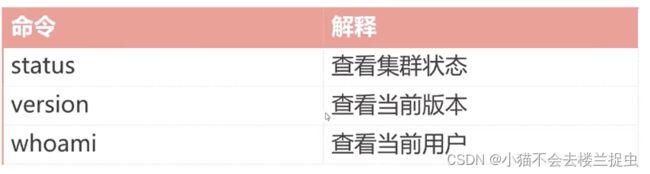
hbase(main):001:0> status
1 active master, 0 backup masters, 1 servers, 0 dead, 2.0000 average load
hbase(main):002:0> version
1.4.10, r76ab087819fe82ccf6f531096e18ad1bed079651, Wed Jun 5 16:48:11 PDT 2019
hbase(main):003:0> whoami
root (auth:SIMPLE)
groups: root
2.2 DDL命令
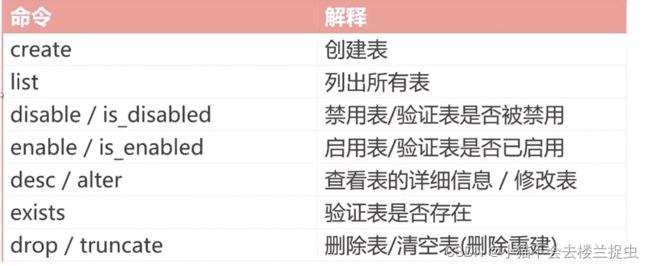
# 创建表,指定两个列族
create 'student', 'info', 'level'
# 列出所有的表
list
# 禁用表
disable 'student'
# 启用表
enable 'student'
# 查看表的详细信息
desc 'student'
# 修改列族下列保存的版本数
alter 'student',{NAME=>'level', VERSIONS=>'3'}
# 增加列族
alter 'student', 'about'
# 删除列族
alter 'student',{NAME=>'about', METHOD=>'delete'}
# 判断表是否存在
exists 'student'
# 删除表:需要禁用表才能再删除表
disable 'student'
drop 'student'
# 清空表中的数据
truncate 'student'2.3 增删改查命令
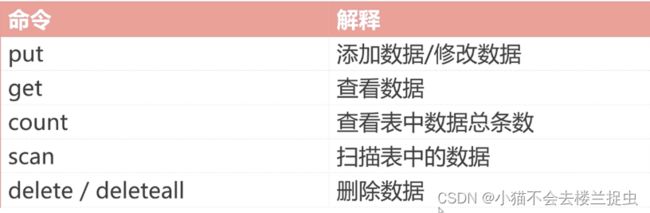
hbase是key value型数据库, rowkey为key, 其他都是value
# 添加数据
put 'student', 'jack', 'info:sex', 'man'
put 'student', 'jack', 'info:age', '22'
put 'student', 'jack', 'level:class', 'C'
put 'student', 'tom', 'info:sex', 'woman'
put 'student', 'tom', 'info:age', '23'
put 'student', 'tom', 'level:class', 'D'
# 查看数据
get 'student', 'jack'
# 查看某个列族的数据
get 'student', 'jack', 'info'
# 查看某一列的数据
get 'student', 'jack', 'info:age'
# 扫描全表
scan 'student'
# 删除某列
delete 'student', 'jack', 'info:age'
# 删除时间戳小于1665002525955的数据
delete 'student', 'jack', 'info:age', '1665002525955'
# 查看信息
help 'delete'2.4 Hbase的命令空间
Hbase的命名空间相当于MySQL的database
Hbase默认的命名空间有两个:hbase(存放系统表)和default(存放用户表)
# 查看命名空间
list_namespace
# 创建命名空间
create_namespace 'n1'
# 创建表
create 'n1:t1','info','level'
# 查看命名空间下所有的表
list_namespace_table 'n1'2.5 JavaAPI的使用
- 引入依赖
org.apache.hbase
hbase-client
1.4.10
- JavaAPI
package com.sanqian.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.List;
public class HbaseOp {
public static void main(String[] args) throws IOException {
//获取数据库连接
Connection conn = getConn();
//获取Table, 指定要操作的表名,表需要提前创建好
Table table = conn.getTable(TableName.valueOf("student"));
//put(table); // 向表中添加数据
// 修改数据--同添加数据
//get(table);
//delete(table);//删除数据
//创建表
//create_table(conn);
//删除表
delete_table(conn);
table.close();
conn.close();
}
/**
* 删除表
* @param conn
* @throws IOException
*/
private static void delete_table(Connection conn) throws IOException {
Admin admin = conn.getAdmin();
String tableName = "users";
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
}
/**
* 创建表
* @param conn
* @throws IOException
*/
private static void create_table(Connection conn) throws IOException {
//获取管理权限,负责对Hbaes中的表进行操作(DDL操作)
Admin admin = conn.getAdmin();
String tableName = "users";
if (!admin.isTableAvailable(TableName.valueOf(tableName))) {
HTableDescriptor hbaseTable = new HTableDescriptor(TableName.valueOf(tableName));
hbaseTable.addFamily(new HColumnDescriptor("info"));
hbaseTable.addFamily(new HColumnDescriptor("level"));
admin.createTable(hbaseTable);
}
}
/**
* 删除数据
* @param table
* @throws IOException
*/
private static void delete(Table table) throws IOException {
Delete delete = new Delete(Bytes.toBytes("laowang"));
//[可选] 可以在这里指定要删除指定rowkey数据哪些列族的列
//如果不指定删除整个rowkey的数据
delete.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"));
table.delete(delete);
}
/**
* 查询数据 : 只会查询最新版本的数据
* @param table
* @throws IOException
*/
private static void get(Table table) throws IOException {
Get get = new Get(Bytes.toBytes("laowang"));
//[可选] 可以在这里指定要查询rowkey数据哪些列族的中列
//如果不指定,默认查询指定rowkey所有的列的内容
get.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"));
get.addColumn(Bytes.toBytes("info"), Bytes.toBytes("sex"));
Result result = table.get(get);
// 如果明确直到Hbase中有哪些列族和列,可以使用getValue(family, qualifier) 直接获取指定列族中的指定列的数据
// 如果不清楚Hbase中到底有哪些列族和列,可以使用listCells()获取所有的cell(单元格)
byte[] age_bytes = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age"));
System.out.println("age列的值:" + new String(age_bytes));
List| cells = result.listCells();
for (Cell cell: cells){
byte[] family_bytes = CellUtil.cloneFamily(cell);
byte[] column_bytes = CellUtil.cloneQualifier(cell);
byte[] value_bytes = CellUtil.cloneValue(cell);
System.out.println("列族:" + new String(family_bytes) + ", 列名:" + new String(column_bytes) + ", 列值:" + new String(value_bytes));
}
}
/**
* 向表中添加数据
* @param table
* @throws IOException
*/
private static void put(Table table) throws IOException {
//指定rowkey 返回put对象
Put put = new Put(Bytes.toBytes("laowang"));
//在put对象中指定列族、列、值
//put 'student', 'laowang', 'info:age', '18'
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes("18"));
//put 'student', 'laowang', 'info:sex', 'man'
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("sex"), Bytes.toBytes("man"));
//put 'student', 'laowang', 'level:class', 'A'
put.addColumn(Bytes.toBytes("level"), Bytes.toBytes("class"), Bytes.toBytes("A"));
//向表中添加数据
table.put(put);
table.close();
}
/**
* 获取Hbase连接
* @return
* @throws IOException
*/
private static Connection getConn() throws IOException {
//获取配置
Configuration conf = HBaseConfiguration.create();
//指定zookeeper地址,多个用逗号隔开
conf.set("hbase.zookeeper.quorum", "192.168.21.101:2181");
// 指定hbase在hdfs上的根目录
conf.set("hbase.rootdir", "hdfs://192.168.21.101:9000/hbase");
return ConnectionFactory.createConnection(conf);
}
}
| 3. Hbase架构原理
3.1 Region概念解释
- Region可以翻译为区域,在Hbase里面,一个表中的数据会按照行被横向划分为多个Region.
- 每个Region,是按照存储的rowkey的最小行键和最大行键指定的,使用区间[startRowkey, endRowkey)
- 随着表中的数据越来越多,Region会越来越大,那么Region会自动分裂,目的保证每个Region不会太大
随着数据量增多Region就会自动分裂,产生多个Region 在这里面表示有三个Region

问题:如何知道数据在哪个region里面?
因为每个Region中都有一个最小rowkey和最大rowkey,这样就能很快判断数据是不是在这个region里面,只要和它里面最大的rowkey比一下。每个region中最大的rowkey是有地方进行维护的,Hbase默认提供了一个目录表来维护这个关系。
- 每个region内的每个列族在底层存储的时候都是一个文件
我们在后期设计的时候可以把经常读取的列放到一个列族里,不经常读取的列放到另外一个列族里。这样在读取部分列数据的时候就只需要读取列族中文件的数据就行,可以提高读取效率。
问题:如果列族中有两个列,那么这两个列会存储在两个列族文件中吗?
不会,他们会存储在一个列族文件中
问题:一行记录会不会分到多个文件中存储?
会的,因为一行文件中涉及到多个列族,每个列族底层都是一个文件。
3.2 HBase详细架构
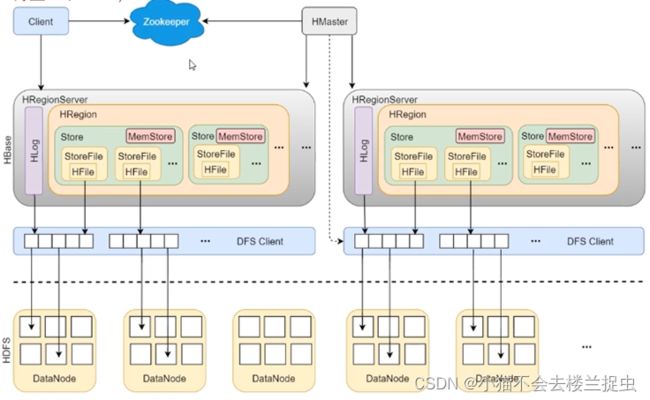
下面是HDFS架构,上面是Hbase架构
- 客户端连接Hbase会首先连接Zookeeper, 找到/hbase/meta-region-server ,里面保存了Hbase中meta表的数据,也就是region所在的regionServer节点信息。

3.3 HRegionServer详解
有了meta表信息就知道RegionServer的节点信息了

- HRegionServer由两部分组成:HLog和HRegion (Region就是HRegion的简写)
- 一个HRegionServer包含一个HLog和多个HRegion(Region)
- Hlog负责记录日志,这对这个HRegionServer里面它接收的所有操作写操作(包括put, delete等操作)。只要是对数据产生变化的操作,都会记录到这个日志中,再把数据写入到对应的HRegion中。
- HRegion就是负责存储实际数据了
3.4 HRegion详解
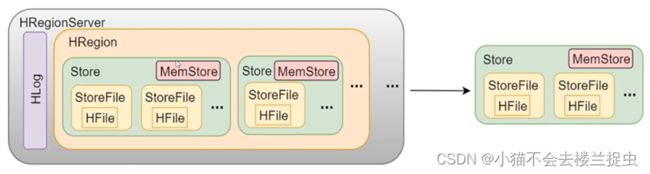
- 每个HRegion由多个Store组成,每个Store对应一个列族,所以一个HRegion里面可能有多个Store。
- 当我们向HRegionServer写数据的时候,会先写HLog,然后再往HRegion里面去写,在往HRegion里面写数据的时候会根据列族信息把数据写入到不同的Store中。
- Store包括:MemStore和HFile
- 用户真正写数据的时候会先写入MemStore(基于内存),写满MemStore以后会把MemStore数据持久化到StoreFile里面,StoreFile底层对应的是一个HFile文件。这个HFile文件最终会通过DFS Client写入到HDFS。
3.5 WAL(Write-Ahead Logging) 预写日志系统

这个WAL数据是存储在HDFS上的

3.5 HFile介绍
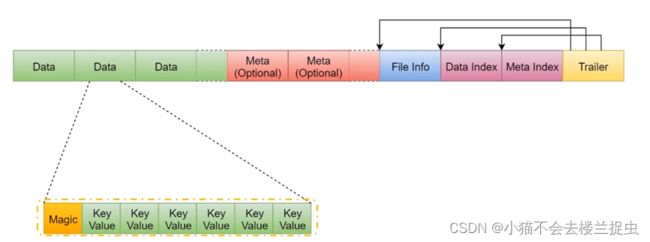
- HFile是HBase中重要的一个存在,是HBase架构中最小的结构,Hbase的底层数据都在HFile中
- HFile从根本上来说是HDFS文件,只是它有自己特殊的格式
- HFile由6部分组成
3.6 BloomFilter布隆过滤器
- 布隆过滤器是一种比较巧妙的概率型数据结构,可以用来告诉你:某样东西一定不存在或可能存在
- 布隆过滤器是Hbase中的高级功能,它能够减少特定访问模式(get/scan)下的查询时间,进而提高Hbase集群的吞吐率。
说明:
1)当采用布隆过滤器之后,Hbase会在生成HFile文件的时候包含一份布隆过滤器结构的数据,所以开始布隆过滤器会有一定的存储及内存开销。
2)在大多数情况下这些负担相对于布隆过滤器带来的好处是可以接收的
3.7 HFile compaction (合并)机制
- 当MemStore超过阈值的时候,就会持久化生成一个(StoreFile) HFile,因此随着不断写入,HFile的数据量将会越来越多,HFile数量过多会降低读性能,可以对这些HFile进行合并操作,把多个HFile合并成一个HFile。
- 合并操作需要多HBase的数据进行多次的重新读写,会生成大量的IO,这个机制的本身其实就是以IO操作换取后续读性能的提高。

注意:这个大合并,它会产生大量的IO操作对Hbase的读写性能 会产生很大的影响,对上层业务有比较打的影响,所以说线上业务一般会关闭自动触发大合并的这个功能。
3.8 Region Split (分裂)机制
- HBase默认只会给每个新创建的Table分配一个Region。此时,所有的读写请求都会访问到同一个RegionServer的一个Region中,进而出现读写热点问题。
- 为了达到负载均衡,当Region达到一定的大小时就会将一个Region分裂成两个新的子Region,并对父Region进行清除处理。
- HMaster会根据Balance策略,重新分配Region所属的RegionServer, 最大化的发挥分布式系统的优点。
触发Region Split的条件
1)ConstantSizeRegionSplitPolicy (0.94版本前)
阈值时固定的
2)IncreasingToUpperBoundRegionSplitPolicy (0.94~2.x版本默认切分策略)
阈值不是固定的,是不断自动调整的。他的这个调整规则和Region所属表在当前RegionSever上的Region个数有关
调整后的阈值 = Region个数的三次方 * flushsize * 2
在这也会通过hbase.hregion.max.filesize来进行限制,她的阈值不能超过这个参数大小。
3.9 Region Balance策略
Region分裂之后就会涉及到负载均衡了,需要把Region均匀分布到不同的RegionServer上面。保持Region对应的HDFS文件位置不变,只需要将Region元数据分配到对应的RegionServer即可。
底层数据时不需要移动的,HMaster进程会自动根据指定策略挑选一些Region并将这些Region分配到负载比较低的RegionServer上,官方目前支持两种挑选Region的策略:
1)DefaultLoadBalancer : 这种策略能够保证每个RegionServer中的Region个数基本上都相等。
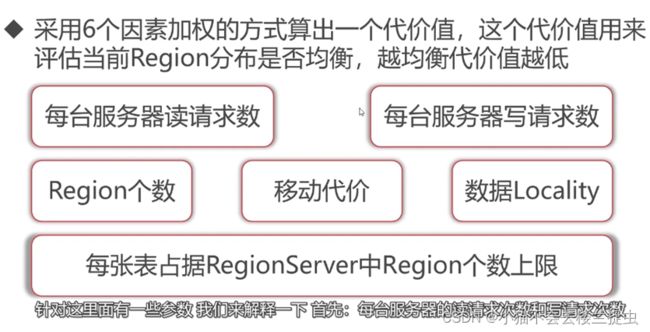
2)StochasticLoadBalancer : 这种策略非常复杂,简答来讲时一种综合权衡6个因素的均衡策略。
4. HBase高级用法
4.1 Scan全表扫描功能
HBase它不适合去做数据分析,它只适合rowkey去查询数据,这个时候我们可能就需要对Hbase里面的一批数据去做一些分析处理
Scan常用JavaAPI

4.2 Scan + Filter案例
- 创建表并初始化数据
create 's1','c1','c2'
put 's1','a','c1:name','zs'
put 's1','a','c1:age','18'
put 's1','a','c2:score','99'
put 's1','b','c1:name','jack'
put 's1','b','c1:age','21'
put 's1','b','c2:score','85'
put 's1','c','c1:name','tom'
put 's1','c','c1:age','31'
put 's1','c','c2:score','79'
put 's1','d','c1:name','lili'
put 's1','d','c1:age','27'
put 's1','d','c2:score','65'
put 's1','e','c1:name','ww'
put 's1','e','c1:age','35'
put 's1','e','c2:score','100'
put 's1','f','c1:name','jessic'
put 's1','f','c1:age','12'
put 's1','f','c2:score','77'
- 引用依赖
org.apache.hbase
hbase-client
1.4.10
- 代码
package com.sanqian.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.util.Bytes;
import sun.awt.windows.WPrinterJob;
import java.io.IOException;
import java.util.List;
/**
* 全表扫描Scan + Filter
*/
public class HbaseScanFilter {
public static void main(String[] args) throws IOException {
//获取配置
Configuration conf = HBaseConfiguration.create();
//指定zookeeper地址,多个用逗号隔开
conf.set("hbase.zookeeper.quorum", "192.168.21.101:2181");
// 指定hbase在hdfs上的根目录
conf.set("hbase.rootdir", "hdfs://192.168.21.101:9000/hbase");
//创建HBase连接
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("s1"));
Scan scan = new Scan();
//范围查询:指定查询区间,提高查询性能
scan.withStartRow(Bytes.toBytes("a"));
scan.withStopRow(Bytes.toBytes("f"));
//添加Filter对数据进行过滤:使用RowFilter进行过滤,获取Rowkey小于等于d的数据
RowFilter filter = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("d")));
scan.setFilter(filter);
//获取查询结果
ResultScanner scanner = table.getScanner(scan);
for (Result result: scanner){
//result代表一条数据
List| cells = result.listCells();
byte[] rowkey = result.getRow();
for(Cell cell: cells){
byte[] family_bytes = CellUtil.cloneFamily(cell);
byte[] column_bytes = CellUtil.cloneQualifier(cell);
byte[] value_bytes = CellUtil.cloneValue(cell);
System.out.println("rowkey:" + new String(rowkey) + ",列族:" + new String(family_bytes) + ", 列名:" + new String(column_bytes) + ", 列值:" + new String(value_bytes));
}
System.out.println("========================================================");
}
}
}
| - 运行结果
rowkey:a,列族:c1, 列名:age, 列值:18
rowkey:a,列族:c1, 列名:name, 列值:zs
rowkey:a,列族:c2, 列名:score, 列值:99
========================================================
rowkey:b,列族:c1, 列名:age, 列值:21
rowkey:b,列族:c1, 列名:name, 列值:jack
rowkey:b,列族:c2, 列名:score, 列值:85
========================================================
rowkey:c,列族:c1, 列名:age, 列值:31
rowkey:c,列族:c1, 列名:name, 列值:tom
rowkey:c,列族:c2, 列名:score, 列值:79
========================================================
rowkey:d,列族:c1, 列名:age, 列值:27
rowkey:d,列族:c1, 列名:name, 列值:lili
rowkey:d,列族:c2, 列名:score, 列值:65
========================================================4.3 HBase批量导入
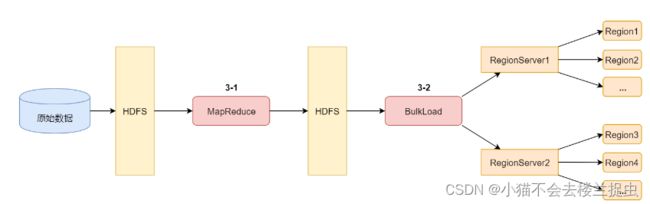
批量导入两种方式:
- 利用MapReduce中封装好的方法。在map阶段,把数据封装成Put操作,直接将数据入库。
- 利用Bulkload。首先使用MapReduce直接生成HFile文件,然后再通过Bulkload将HFile文件直接加载到表中。
Bulkload的优势:通过MR生成HBase底层HFile文件,直接加载到表中,省去了大部分的RPC和写过程。
4.3.1 批量导入之 MapReduce
准备数据并上传到HDFS
a c1 name zs
a c1 age 18
b c1 name ls
b c1 age 29
c c1 name ww
c c1 age 31
创建表
create 'batch1','c1'
引入依赖:此时项目的pom.xml文件中除了添加hbase-client的依赖,还需要添加hadoop-client和hbase-mapreduce的依赖,否则代码报错
org.apache.hadoop
hadoop-client
3.2.0
org.apache.hbase
hbase-mapreduce
2.2.7
代码:
package com.imooc.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
/**
* 批量导入:
* 1:利用MapReduce中封装好的方法。
* 在map阶段,把数据封装成Put操作,直接将数据入库
*
* 注意:需要提前创建表batch1
* create 'batch1','c1'
*
*/
public class BatchImportMR {
public static class BatchImportMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] strs = value.toString().split("\t");
if(strs.length==4){
String rowkey = strs[0];
String columnFamily = strs[1];
String name = strs[2];
String val = strs[3];
Put put = new Put(rowkey.getBytes());
put.addColumn(columnFamily.getBytes(),name.getBytes(),val.getBytes());
context.write(NullWritable.get(),put);
}
}
}
public static void main(String[] args) throws Exception{
if(args.length!=2){
//如果传递的参数不够,程序直接退出
System.exit(100);
}
String inPath = args[0];
String outTableName = args[1];
//设置属性对应参数
Configuration conf = new Configuration();
conf.set("hbase.table.name",outTableName);
conf.set("hbase.zookeeper.quorum","bigdata01:2181");
//封装Job
Job job = Job.getInstance(conf, "Batch Import HBase Table:" + outTableName);
job.setJarByClass(BatchImportMR.class);
//指定输入路径
FileInputFormat.setInputPaths(job,new Path(inPath));
//指定map相关的代码
job.setMapperClass(BatchImportMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Put.class);
TableMapReduceUtil.initTableReducerJob(outTableName,null,job);
TableMapReduceUtil.addDependencyJars(job);
//禁用Reduce
job.setNumReduceTasks(0);
job.waitForCompletion(true);
}
}
4.3.2 批量导入之 BulkLoad
创建表
hbase(main):027:0> create 'batch2','c1'
Created table batch2
Took 1.3600 seconds
=> Hbase::Table - batch2
想要实现BulkLoad需要两步
- 第一步:先生成HFile文件
package com.imooc.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 批量导入
*
* 2.利用BulkLoad
* 在map阶段,把数据封装成put操作,将数据生成HBase的底层存储文件HFile
* 再将生成的HFile文件加载到表中
*/
public class BatchImportBulkLoad {
public static class BulkLoadMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] strs = value.toString().split("\t");
if(strs.length==4){
String rowkey = strs[0];
String columnFamily = strs[1];
String name = strs[2];
String val = strs[3];
ImmutableBytesWritable rowkeyWritable = new ImmutableBytesWritable(rowkey.getBytes());
Put put = new Put(rowkey.getBytes());
put.addColumn(columnFamily.getBytes(),name.getBytes(),val.getBytes());
context.write(rowkeyWritable,put);
}
}
}
public static void main(String[] args) throws Exception{
if(args.length!=3){
//如果传递的参数不够,程序直接退出
System.exit(100);
}
String inPath = args[0];
String outPath = args[1];
String outTableName = args[2];
//设置属性对应参数
Configuration conf = new Configuration();
conf.set("hbase.table.name",outTableName);
conf.set("hbase.zookeeper.quorum","bigdata01:2181");
//封装Job
Job job = Job.getInstance(conf, "Batch Import HBase Table:" + outTableName);
job.setJarByClass(BatchImportBulkLoad.class);
//指定输入路径
FileInputFormat.setInputPaths(job,new Path(inPath));
//指定输出路径[如果输出路径存在,就将其删除]
FileSystem fs = FileSystem.get(conf);
Path output = new Path(outPath);
if(fs.exists(output)){
fs.delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
//指定map相关的代码
job.setMapperClass(BulkLoadMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
//禁用Reduce
job.setNumReduceTasks(0);
Connection connection = ConnectionFactory.createConnection(conf);
TableName tableName = TableName.valueOf(outTableName);
HFileOutputFormat2.configureIncrementalLoad(job,connection.getTable(tableName),connection.getRegionLocator(tableName));
job.waitForCompletion(true);
}
}
- 第二步:加载HFile
在HBase客户端节点上执行下面命令,把HFile数据转移到表对应的region中。
hbase org.apache.hadoop.hbase.tool.BulkLoadHFilesTool hdfs://bigdata01:9000/hbase_out batch2
查看表batch2中的数据
hbase(main):001:0> scan 'batch2'
ROW COLUMN+CELL
a column=c1:age, timestamp=1778308217857, value=18
a column=c1:name, timestamp=1778308217857, value=zs
b column=c1:age, timestamp=1778308217857, value=29
b column=c1:name, timestamp=1778308217857, value=ls
c column=c1:age, timestamp=1778308217857, value=31
c column=c1:name, timestamp=1778308217857, value=ww
3 row(s)
Took 1.0230 seconds
5. HBase调优策略
5.1 预分区
- HBase默认新建表的时候只有一个region,这个region的rowkey是没有边界的,即没有startRowkey和endRowkey,在数据写入时,所有数据都会写入这个默认的region。
- 随着数据量的不断增加,此Regiony已经不能承受不断增长的数据量,会进行split,分裂成2个Region。
在region分类的过程中会产生两个问题
1)数据前期都往一个Region上面写会有写热点问题
2)Region分裂它会消耗宝贵的集群IO资源。
我们可以控制在创建表的时候,创建多个空Region,并确定每个Region的起始和终止rowkey,这样只要我们设计的rowkey能均匀的命中各个Region,就不会存在写热点问题
这种预先给Hbase表创建多个Region的方式称为预分区
hbase(main):001:0> create 't20', 'c1', SPLITS => ['10', '20', '30', '40']
Created table t20
Took 3.3741 seconds
=> Hbase::Table - t20
5.2 rowkey的设计原则
rowkey长度原则
Rowkey底层存储是一个二进制流,可以是任意字符串,最大长度 64kb ,实际应用中一般是10-100字节,以 byte[] 形式保存,一般设计为定长。
建议越短越好,不要超过16个字节,原因如下:
1、数据的持久化文件HFile中是按照KeyValue存储的,如果Rowkey过长,比如超过100字节,1000w行数据,Rowkey就要占用100*1000w=10亿字节,将近1G数据,这样会极大影响HFile的存储效率;
2、MemStore会缓存部分数据到内存,如果Rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
3、目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性
rowkey散列原则
Rowkey散列原则,主要是为了避免数据热点问题。
虽然我们可以在建表的时候提前设计预分区,但是假设数据的Rowkey都是手机号,那么都是1开头,按照前面的设计,那么所有的数据都会写到10-20之间的Region中,仍然没有做到负载均衡。
如何保证我们的数据能够均匀的分布到预先设计好的分区中呢?
解决思路(以手机号为例):
1、手机号反转,将手机号的最后一位前置,这样第一位就是0-9之间的任意一个数字了。
2、按照一定规则使用hashCode获取余数,拼在手机号前面。
例如:根据手机号后四位使用hashCode获取余数。这里的规则一定要是可以反推出来的,这样后期还可以根据这个规则找到对应的手机号,尽量不要使用随机数。
rowkey的唯一性原则
必须在设计上保证其唯一性,因为Rowkey相同则会覆盖。
Rowkey是HBase里面唯一的索引,对于某些查询频繁的限定条件可以把它的内容存放在Rowkey里面,提高查询效率。
例如:需要经常使用姓名和年龄这两个字段进行查询,那么可以考虑把姓名和年龄拼接到一块作为Rowkey。
5.3 列族的设计原则
在设计列族的时候,建议把经常读取的字段存储到一个列族中,不经常读取的字段放到另一个列族中。
这样在读取部分数据的时候,就只需要读取一个列族文件即可,可以提高读取效率。
5.4 批处理
Table.get(Get)方法可以根据一个指定的Rowkey获取一行记录,同样HBase提供了另一个方法:通过调用Table.get(List)方法可以根据一个指定的Rowkey列表,批量获取多行记录,这样做的好处是批量执行,只需要一次网络IO开销,这样可以带来明显的性能提升。
同理 Table.delete(List) 和 Table.put(List)
如果一次操作的数据量不是特别多,例如:100~1000条左右的数据量,可以考虑这种方式。
如果是一次需要批量操作上千万的数据,建议使用前面讲的批量导入导出方法,效率更高。
5.4 Region的request计数
HBase UI界面table Regions中的Requests参数值
这个参数的意义在于,可以分析哪个Region被频繁请求,是否存在读写热点的问题。
注意:HBase集群重启之后,Requests参数值会被清空。