hadoop的基本概念:
-
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
-
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
-
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
-
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
准备搭建环境:
1.选择合适的操作系统(linux)和语言(java)。
2.准备虚拟机:我的电脑是windows系统还要玩游戏,当然要准备一个虚拟机。虚拟机选择VMware Workstation。首先创建新的虚拟机,分配好内存和硬盘,网络适配器调为VMNET8模式配置,方便以后对网络的使用。
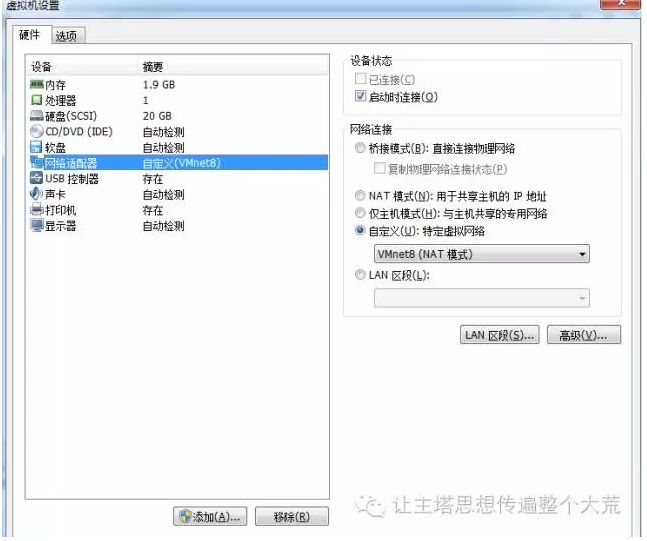
3.安装操作系统:首先得要安装linux系统吧,因为linux系统有太多可选择了,例如最著名的RedHat咱中国人开发的红旗Linux,Ubuntu、Fedora、CentOS等等,因为学习,一切为了有更多资料,安装CentOS6.4这个版本的系统。
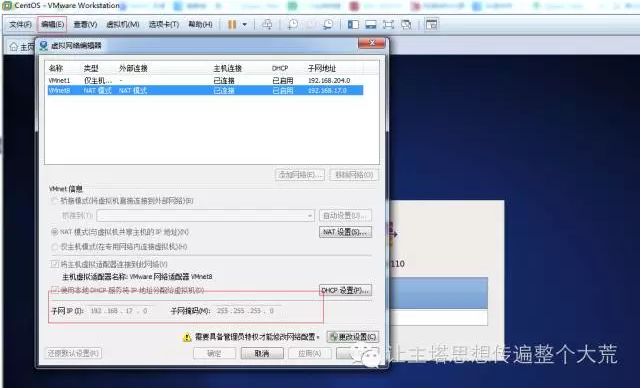
4.设置网络:点击虚拟机的编辑-虚拟网络编辑器,设置子网IP和子网掩码。子网IP:
192.168.17.0 子网掩码:255.255.255.0
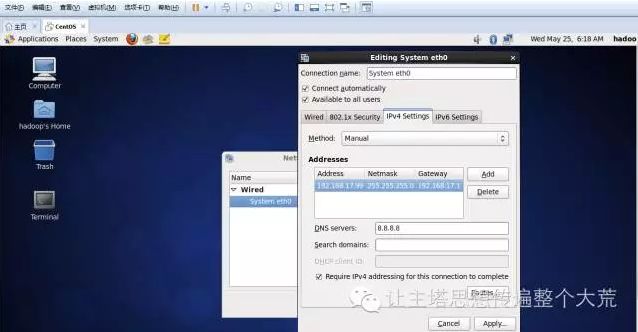
5.在系统中不要用root账号,权限太大,不安全,在实际生产环境中也不会用到root账号。创建名字为hadoop的用户,登录进去。设置网络使用和虚拟机同一子网上的IP,便于本地与虚拟机的交互通信。
6.使用Securecrt连接上虚拟机,方便在本地直接通过命令操作虚拟机。用sudo vi /etc/sysc onfig/network打开系统文件修改主机名和IP的映射关系,保存后source /etc/profile刷新配置立即生效。关闭防火墙,因为在内网环境而且学习使用,对每个端口进行配置太麻烦,
#查看防火墙状态 service iptables status
#关闭防火墙 service iptables stop
#查看防火墙开机启动状态 chkconfig iptables --list
#关闭防火墙开机启动 chkconfig iptables off
给hadoop赋予root账号权限
重启linux系统

7.使用SecureFx将要安装的软件包传到虚拟机,连接上虚拟机后,把软件包直接拖到hadoop文件夹下

8.创建一个app文件夹将解压的文件都统一放在这里(怎么创建文件夹,解压需要学习Linux基本操作,这里不多说)。
9.方便每次直接使用,需要配置环境变量。
①配置java的jdk环境变量:命令vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source /etc/profile
②配置hadoop,伪分布式需要修改5个配置文件,查找到这五个文件.
1:sudo vim hadoop-env.sh
#第27行
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
2:sudo vim core-site.xml
3:sudo vim hdfs-site.xml
虚拟机中配置一个就行了,多了浪费
4: 将mapred-site.xml.template重命名 为mapred-site.xml
(mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
5: sudo vi yarn-site.xml
③ 将hadoop添加到环境变量
命令:sudo vim /etc/proflie
Shift+G直接跳到最后添加如下配置信息
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新 source /etc/profile
10: 格式化namenode(是对namenode进行初始化,像U盘一样第一次使用需要格式化)
hdfs namenode -format (hadoop namenode -format)
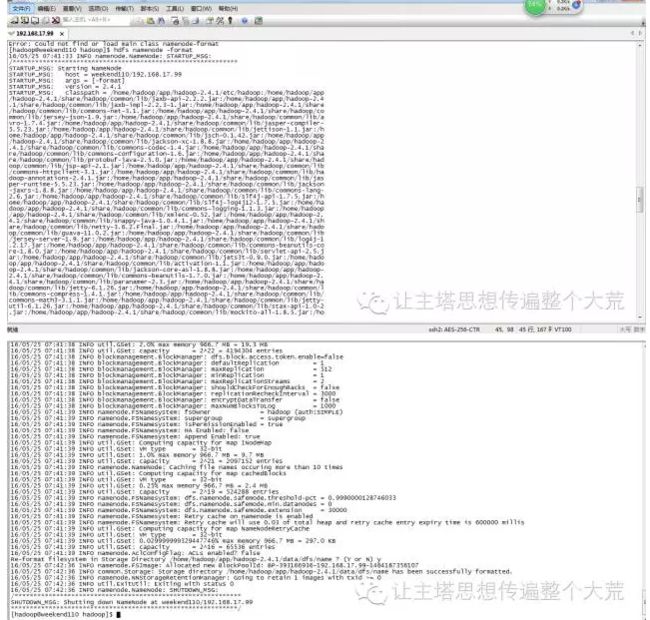
11:启动hadoop
先启动HDFS
start-dfs.sh
再启动YARN
start-yarn.sh
12.执行命名: jps验证是否启动成功。以为本机原来已经启动故有标红信息。最后看到hadoop启动成功。
