pandas df.groupby()分组后的数据访问,set_index的用法
分组方式
注意第一种与第三种方式的区别。
import pandas as pd
dic={'省份':['A','A','A','B','C'],'城市':['a','a','a_','b','c',],'订单额':[1,2,3,4,5],'规模':[5,4,3,2,1]}
df=pd.DataFrame(dic)
# print(df)
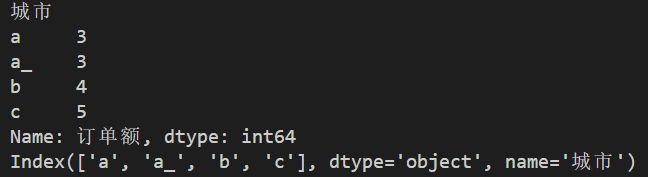
df1=df.groupby('城市')['订单额'].sum()
df2=df.groupby(['省份','城市'])[['订单额','规模']].sum()
df3=df.groupby(['城市'])[['订单额']].sum()1.df1=df.groupby('分组列名')['作用列名'].聚合函数()
此时df坍缩成一对一映射的数据集,类似于map容器。
2.df2=df.groupby(['分组列名1','分组列名2'])[['作用列名1', '作用列名2' ]].聚合函数()
仍可以看作是一般的df对象,'分组列名1'是合法的行索引。

3.df3=df.groupby(['分组列名'])[['作用列名']].聚合函数()
比第一种多了一层 [ ] ,但结构与第二种相同。

数据访问
单个值
df1['分组列名']
df2.loc['分组列名1','分组列名2']['作用列名1/2']
df3.loc['分组列名']['作用列名']
print(df1['a'])#实际上是一对一的映射关系
print(df2.loc['A','a']['订单额'])
#df2.loc['a']['订单额']报错:此对象不存在名为的'a'索引,可通过set_index解决
#df2.loc['A']['订单额']是一组只有A省份的城市的'订单额'
print(df3.loc['a']['订单额'])

单行
df1['分组列名']
df2.loc['分组列名1','分组列名2']
df3.loc['分组列名']
一整列
list(df1)
list(df2['分组列名1/2'])
list(df3['分组列名'])
print(list(df1))
print(list(df2['订单额']))
print(list(df3['订单额']))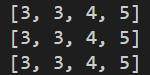
set_index的用法
#set_index用法
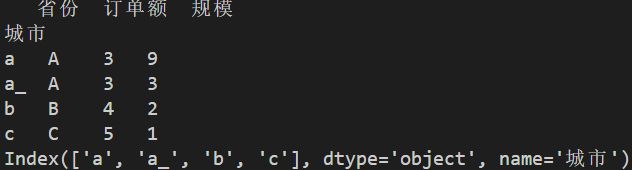
df2=df2.reset_index()#重置行索引,把原来的行索引内容变为列【此处是新增'省份'和'城市'两列数据】,行索引变为0,1,2...
df2=df2.set_index('城市')#设置行索引为'城市'
#此时的df2相当于是df3多加了'省份'这一列
print(df2)
完整代码
import pandas as pd
dic={'省份':['A','A','A','B','C'],'城市':['a','a','a_','b','c',],'订单额':[1,2,3,4,5],'规模':[5,4,3,2,1]}
df=pd.DataFrame(dic)
# print(df)
df1=df.groupby('城市')['订单额'].sum()
df2=df.groupby(['省份','城市'])[['订单额','规模']].sum()
df3=df.groupby(['城市'])[['订单额']].sum()
# 行索引
print(df1.index)
print(df2.index)
print(df3.index)
#单个值
print(df1['a'])#实际上是一对一的映射关系
print(df2.loc['A','a']['订单额'])
#df2.loc['a']['订单额']报错:此对象不存在名为的'a'索引,可通过set_index解决
#df2.loc['A']['订单额']是一组只有A省份的城市的'订单额'
print(df3.loc['a']['订单额'])
#一整列
print(list(df1))
print(list(df2['订单额']))
print(list(df3['订单额']))
#set_index用法
df2=df2.reset_index()#重置行索引,把原来的行索引内容变为列【此处是新增'省份'和'城市'两列数据】,行索引变为0,1,2...
df2=df2.set_index('城市')#设置行索引为'城市'
#此时的df2相当于是df3多加了'省份'这一列
print(df2)
记录一种修改数据的算法(可能numpy库有,但博主暂未涉猎)
对原数据集将特定区间内的数据修改成同一个值。
import pandas as pd
dic={'省份':['A','A','A','B','C'],'城市':['a','a','a_','b','c',],'订单额':[1,2,3,4,5],'规模':[5,4,3,2,1]}
df=pd.DataFrame(dic)
df_tmp=df[df['订单额'].between(1,2)]
df_tmp['订单额']=0
print(df_tmp)
df[df['订单额'].between(1,2)]=df_tmp
print(df)