【数据挖掘与商务智能决策】红酒数据集
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 获取数据集
wine = load_wine()
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3)
# 建模
clf = DecisionTreeClassifier(criterion='entropy',random_state=30)
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test) # 分类的精确度
print(score)
0.8703703703703703
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.datasets import load_wine #导入红酒的数据
from sklearn.model_selection import train_test_split
wine=load_wine()#导入数据
wine
{'data': array([[1.423e+01, 1.710e+00, 2.430e+00, ..., 1.040e+00, 3.920e+00,
1.065e+03],
[1.320e+01, 1.780e+00, 2.140e+00, ..., 1.050e+00, 3.400e+00,
1.050e+03],
[1.316e+01, 2.360e+00, 2.670e+00, ..., 1.030e+00, 3.170e+00,
1.185e+03],
...,
[1.327e+01, 4.280e+00, 2.260e+00, ..., 5.900e-01, 1.560e+00,
8.350e+02],
[1.317e+01, 2.590e+00, 2.370e+00, ..., 6.000e-01, 1.620e+00,
8.400e+02],
[1.413e+01, 4.100e+00, 2.740e+00, ..., 6.100e-01, 1.600e+00,
5.600e+02]]),
'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2]),
'frame': None,
'target_names': array(['class_0', 'class_1', 'class_2'], dtype='from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target,test_size=0.3)
wine_model=DTC(criterion='entropy').fit(x_train,y_train) #实例化,用训练集数据训练模型
score=wine_model.score(x_test,y_test) #对模型衡量
score #0.8888888888888888 我的结果
chn_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
import graphviz
from sklearn import tree
dot_data=tree.export_graphviz(wine_model
,feature_names=chn_name
,class_names=["香槟","冰酒","雪莉酒"]
,filled=True #树的块填充颜色
,rounded=True #块的框是方圆形
)
graph =graphviz.Source(dot_data)
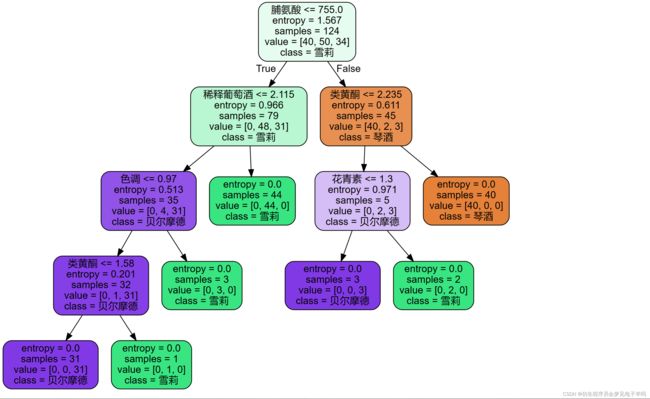
graph #画出树 ,samples 样本数 ,value根据samples 的占比分配,
test_size=0.3
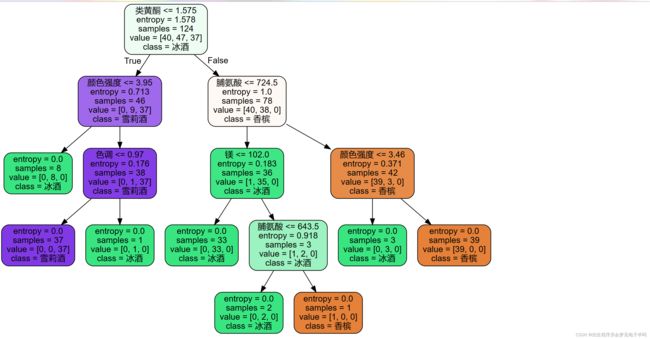
test_size=0.4
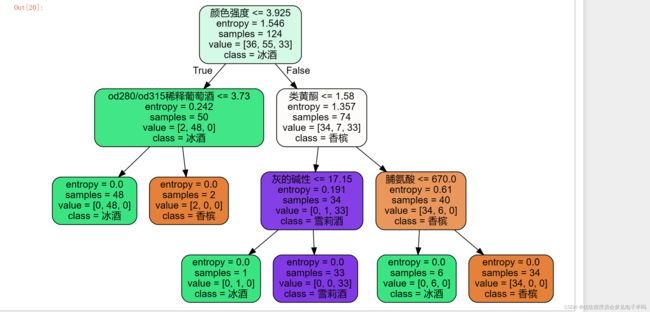
test_size=0.5
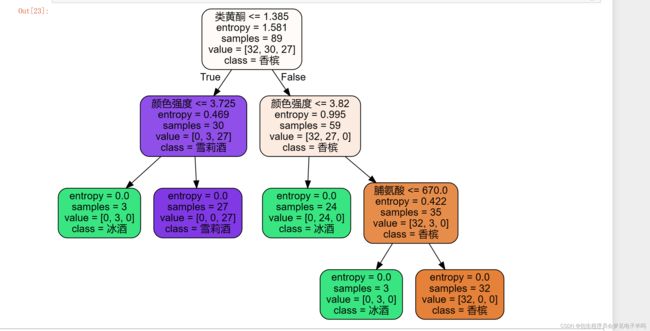
test_size=0.8

精确度:0.7692307692307693
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine = load_wine()
#区分数据集和测试集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','稀释葡萄酒','脯氨酸']
import graphviz
#输出生成的决策树
dot_data = tree.export_graphviz(clf
,feature_names = feature_name
,class_names = ["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
,out_file=None #---->(异常二的解决方法二)
)
graph = graphviz.Source(dot_data)
graph