深度学习“引擎”之争:GPU加速还是专属神经网络芯片?
深度学习“引擎”之争:GPU加速还是专属神经网络芯片?
深度学习(Deep Learning)在这两年风靡全球,大数据和高性能计算平台的推动作用功不可没,可谓深度学习的“燃料”和“引擎”,GPU则是引擎的引擎,基本所有的深度学习计算平台都采用GPU加速。同时,深度学习已成为GPU提供商NVIDIA的一个新的战略方向,以及3月份的GTC 2015的绝对主角。
那么,GPU用于深度学习的最新进展如何?这些进展对深度学习框架有哪些影响?深度学习开发者应该如何发挥GPU的潜力?GPU与深度学习结合的前景以及未来技术趋势到底是怎么样的?在日前的NVIDIA深度学习中国战略发布会上,NVIDIA全球副总裁、PSG兼云计算业务中国区总经理Ashok Pandey带领其深度学习相关管理团队接受了记者的采访,就NVIDIA的深度学习战略、技术、生态、市场相关问题进行了详细的解读。
NVIDIA认为,目前是数据、模型和GPU在推动深度学习的蓬勃发展,深度学习用户可以选择不同的计算平台,但开发人员需要一个易于部署的平台和良好的生态环境,包括一些基于硬件优化的开源工具,而构建一个良好的深度学习计算生态,既是GPU现有的优势,也是NVIDIA一贯的宗旨。

NVIDIA全球副总裁、PSG兼云计算业务中国区总经理Ashok Pandey
为什么GPU与深度学习很合拍?
随着数据量和计算力的提升,Hinton和LeCun耕耘多年的大型神经网络终有用武之地,深度学习的性能和学习精度得到很大的提升,被广泛运用到文本处理、语音和图像识别上,不仅被Google、Facebook、百度、微软等巨头采用,也成为猿题库、旷视科技这类初创公司的核心竞争力。
那么为什么是GPU呢?最重要的是GPU出色的浮点计算性能特别提高了深度学习两大关键活动:分类和卷积的性能,同时又达到所需的精准度。NVIDIA表示,深度学习需要很高的内在并行度、大量的浮点计算能力以及矩阵预算,而GPU可以提供这些能力,并且在相同的精度下,相对传统CPU的方式,拥有更快的处理速度、更少的服务器投入和更低的功耗。
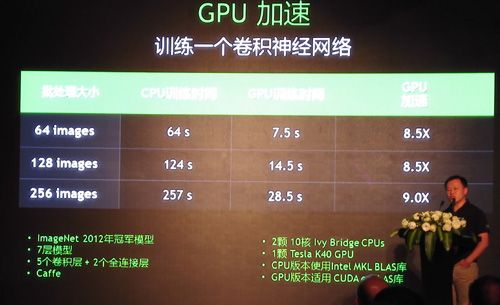
采用GPU加速与只采用CPU训练CNN的性能比较
以ImageNet竞赛为例,基于GPU加速的深度学习算法,百度、微软和Google的计算机视觉系统在ImageNet图像分类和识别测试中分别达到了5.98% (2015年1月数据)4.94%(2015年2月数据)、4.8%(2015年2月数据)、的错误率,接近或超过了人类识别水平——跑分竞赛虽然有针对已知数据集进行特定优化之嫌,但优化结果对工业界的实践仍然具有参考价值。
“人工智能从过去基于模型的方法,变成现在基于数据、基于统计的方法,主要得益于GPU高度并行的结构、高效快速的连接能力。事实证明GPU很适合深度学习。”北京航空航天大学教授、国家“十二五 863计划高效能计算机及应用服务环境”重大项目总体组组长钱德沛说。
4款新方案
NVIDIA回顾了GTC上推出的四项有助于推动深度学习发展的新产品和方案:
1、GeForce GTX TITAN X,为训练深度神经网络而开发的GPU。
TITAN X采用 NVIDIA Maxwell GPU 架构,结合 3,072 个处理核心、单精度峰值性能为 7 teraflops,加上板载的 12GB 显存,336.5GB/s 的带宽,可处理用于训练深度神经网络的数百万的数据。
NVIDIA介绍,TITAN X 在工业标准模型 AlexNet 上,花了不到三天的时间、使用 120万个 ImageNet 图像数据集去训练模型,而使用16核心的 CPU 得花上四十多天。
2、DIGITS DevBox,针对研究人员的桌边型深度学习工具。
DIGITS DevBox采用四个 TITAN X GPU,从内存到 I/O的每个组件都进行了最佳化调试,预先安装了开发深度神经网络所需要使用到的各种软件,包括:DIGITS 软件包,三大流行深度学习架构Caffe、Theano和Torch,以及 NVIDIA 完整的 GPU 加速深度学习库 cuDNN 2.0。和其他巨头一样,NVIDIA对开源的支持也是不遗余力。
NVIDIA表示,在关键深度学习测试中,DIGITS DevBox 可以提供 4 倍于单个 TITAN X 的性能。使用 DIGITS DevBox 来训练 AlexNet 只要13个小时就能完成,而使用最好的单 GPU PC 的话则是两天,单纯使用 CPU 系统的话则要一个月以上的时间。
3、下一代GPU 架构Pascal,将使深度学习应用中的计算速度相比Maxwell加快十倍。
Pascal引入了大幅加快训练速度的三项设计,包括:32GB 的显存(是GeForce GTX TITAN X 的 2.7 倍),可进行混合精度的计算任务,能够在 16 位浮点精度下拥有两倍于 32 位浮点精度下的速率的计算速度;配备 3D 堆叠显存,让开发人员能建立更大的神经网络,提升深度学习应用程序的速度性能多达5倍;另搭配 NVIDIA 的高速互连技术 NVLink 来连接两个以上的 GPU,可将深度学习的速度提升达十倍。
NVIDIA表示,现在在深度学习领域一般都用单精度进行,未来的趋势可能有人要用半精度,甚至1/4精度,所以NVIDIA需要根据用户的需求调整GPU的架构,Pascal支持FP16和FP32,可以提升机器学习的性能。
4、DRIVE PX,用于自动驾驶汽车的深度学习平台。
基于NVIDIA Tegra X1,结合最新的PX平台,可以让汽车在仪表显示和自动驾驶方面得到质的飞跃。
值得关注的NVLink和DIGITS
谈到下一代Pascal 架构的十倍性能,不得不说NVLink,它使得 GPU 与 GPU 之间、GPU 与 CPU 之间数据传输的速度,较现有的 PCI-Express 标准加快5到12倍,对于深度学习这些需要更高 GPU 间传递速度的应用程序来说是一大福音。开发者应当高兴的是,NVLink基于点对点传输形式,编程模式与 PCI-Express 相同。
NVIDIA表示,NVLink 可将系统里的 GPU 数量增加一倍,以共同用于深度学习计算任务上;还能以新的方式连接 CPU 与 GPU,在服务器设计方面提供较 PCI-E 更出色的灵活性和省电表现。
其实不管要做数据并行还是模型并行,NVLink对深度学习开发人员都带来更大的想象空间。国内语音识别领头羊科大讯飞,基于多GPGPU和InfiniBand构建了一个环形的并行学习架构,用于DNN、RNN、CNN等模型训练,效果不错,但采用InfiniBand也让其他从业者羡慕其“土豪”行径,如果有了NVLink,显然可以有别的好办法。
当然,想用NVLink也意味着新的投资,而NVIDIA现有的产品线对深度学习的支持也不错,用户可以酌情选择。更多的深度学习硬件选择知识,可以参考Kaggle比赛选手Tim Dettmers撰写的博文:《深度学习硬件指南完整版》。
另外一个是DIGITS,用于设计、训练和验证图像分类深度神经网络的多合一图形系统。DIGITS 可在安装、配置和训练深度神经网络过程中为用户提供指导,具有便于从本地和网络加载训练数据集的用户界面和工作流程管理能力,并提供实时监控和可视化功能,目前支持 GPU 加速版本 Caffe,详见Parallel Forall 博客:《DIGITs: Deep Learning Training System》。
DIGITS之所以首先选择支持Caffe,NVIDIA表示,是因为他们的客户调研结果显示这一框架目前最受欢迎(包括国内的BAT等和国外的一些用户),同理,cuDNN运算库也是最先集成到Caffe开源工具中。NVIDIA承诺,即使不能覆盖所有的工具,DIGITS后续也会对主流的开源工具提供支持,主要是前述的Theano和Torch。NVIDIA全球在DIGITS、cuDNN团队都分别投入30多人到开源工作之中,这些开发人员也在社区中与深度学习开发者保持密切的沟通。
中国生态
在NVIDIA看来,国内的深度学习研究水平与国外机构基本相当,从高校科研的角度来说,香港中文大学、中科院自动化所都获得ImageNet不错的名次,从工业界来说,BAT、乐视、科大讯飞等都在深度学习领域拥有很多年轻的工程师和不错的研究成果。NVIDIA希望加强中国生态环境的建设,推动深度学习的应用,主要方式仍然包括开源社区的投入、高校科研合作、服务器厂商的合作以及企业用户的合作。
2015年1月,NVIDIA与爱奇艺签署了深度合作框架协议,双方将在视频深度学习(deep video)和媒体云计算领域紧密合作,利用最先进的GPU和深度学习架构,搭建爱奇艺视频创作、分享、服务平台。NVIDIA表示,未来还将继续与重点客户合作建立联合实验室。

采用GPU加速的深度学习的企业
GPU还是专用芯片?
尽管深度学习和人工智能在宣传上炙手可热,但无论从仿生的视角抑或统计学的角度,深度学习的工业应用都还是初阶,深度学习的理论基础也尚未建立和完善,在一些从业人员看来,依靠堆积计算力和数据集获得结果的方式显得过于暴力——要让机器更好地理解人的意图,就需要更多的数据和更强的计算平台,而且往往还是有监督学习——当然,现阶段我们还没有数据不足的忧虑。未来是否在理论完善之后不再依赖数据、不再依赖于给数据打标签(无监督学习)、不再需要向计算力要性能和精度?
退一步说,即便计算力仍是必需的引擎,那么是否一定就是基于GPU?我们知道,CPU和FPGA已经显示出深度学习负载上的能力,而IBM主导的SyNAPSE巨型神经网络芯片(类人脑芯片),在70毫瓦的功率上提供100万个“神经元”内核、2.56亿个“突触”内核以及4096个“神经突触”内核,甚至允许神经网络和机器学习负载超越了冯·诺依曼架构,二者的能耗和性能,都足以成为GPU潜在的挑战者。例如,科大讯飞为打造“讯飞超脑”,除了GPU,还考虑借助深度定制的人工神经网络专属芯片来打造更大规模的超算平台集群。
不过,在二者尚未产品化的今天,NVIDIA并不担忧GPU会在深度学习领域失宠。首先,NVIDIA认为,GPU作为底层平台,起到的是加速的作用,帮助深度学习的研发人员更快地训练出更大的模型,不会受到深度学习模型实现方式的影响。其次,NVIDIA表示,用户可以根据需求选择不同的平台,但深度学习研发人员需要在算法、统计方面精益求精,都需要一个生态环境的支持,GPU已经构建了CUDA、cuDNN及DIGITS等工具,支持各种主流开源框架,提供友好的界面和可视化的方式,并得到了合作伙伴的支持,例如浪潮开发了一个支持多GPU的Caffe,曙光也研发了基于PCI总线的多GPU的技术,对熟悉串行程序设计的开发者更加友好。相比之下,FPGA可编程芯片或者是人工神经网络专属芯片对于植入服务器以及编程环境、编程能力要求更高,还缺乏通用的潜力,不适合普及。
作者:周建丁
文章出处:http://www.csdn.net/article/2015-05-06/2824630