MySQL基础总结
个人主页: Java程序鱼
准备精心打造一套精品MySQL课程,大家可以持续关注
如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
有任何问题欢迎私信,看到会及时回复!
| 序号 | 内容 | 链接地址 |
|---|---|---|
| 1 | MySQL基础总结 | |
| 2 | MySQL索引 | 待分享 |
| 3 | MySQL事务 | 待分享 |
| 4 | MySQL锁机制 | 待分享 |
| 5 | MySQL JOIN 原理 | 待分享 |
| 6 | MySQL Order By 原理 | 待分享 |
| 7 | redo log、undo log、binlog | 待分享 |
| 8 | InnoDB内存结构包含四大核心组件 | 待分享 |
| 9 | 主从复制原理 | 待分享 |
| 10 | 主从延迟解决方案 | 待分享 |
| 11 | SQL语句查询原理 | 待分享 |
| 12 | MySQL海量数据优化 | 待分享 |
| 13 | SQL优化 | 待分享 |
| 14 | 数据库与缓存双写一致性方案 | 待分享 |
| 15 | 分布式锁 | 待分享 |
文章目录
- 一、安装MySQL
- 二、库操作命令
- 三、表操作命令
- 四、数据类型
-
- 1.数值类型
- 2.日期和时间类型
- 3.字符串类型
- 五、函数
-
- 1.MySQL数字函数
- 2.MySQL字符串函数
- 3.MySQL时间和日期函数
- 六、连接查询
一、安装MySQL
检查系统是否已安装mysql
rpm -qa | grep mysql
如果已经安装,可以选择卸载
rpm -e mysql // 普通删除模式
rpm -e --nodeps mysql // 强力删除模式
下载mysql
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
rpm -ivh mysql-community-release-el7-5.noarch.rpm
yum update
yum install mysql-server
权限设置:
chown mysql:mysql -R /var/lib/mysql
初始化 MySQL:
mysqld --initialize
启动 MySQL:
systemctl start mysqld
查看 MySQL 运行状态:
systemctl status mysqld
验证安装是否成功
mysqladmin --version
使用MySQL客户端
mysql
然后再输入密码,使用 mysql 命令连接到 MySQL 服务器上,默认情况下 MySQL 服务器的登录密码为空,所以本实例不需要输入密码。
查看有哪些库
mysql> SHOW DATABASES;
+----------+
| Database |
+----------+
| mysql |
| test |
+----------+
2 rows in set (0.11 sec)
设置密码
Mysql安装成功后,默认的root用户密码为空,你可以使用以下命令来创建root用户的密码:
mysqladmin -u root password "new_password";
二、库操作命令
1、创建数据库:create命令用于创建数据库。
mysql> create database <数据库名>;
2、显示所有数据库
mysql> show databases;
3、修改数据库:ALTER TABLE 语句用于在已有的表中添加、删除或修改列。
使用 ALTER 命令及 DROP 子句来删除【user_info】表的 age 字段:
mysql> ALTER TABLE user_info DROP age;
注意:如果数据表中只剩余一个字段则无法使用DROP来删除字段。
MySQL 中使用 ADD 子句来向数据表中添加列,如下实例在表 【user_info】 中添加 age 字段,并定义数据类型:
mysql> ALTER TABLE user_info ADD age INT;
如果需要修改字段类型及名称, 你可以在ALTER命令中使用 MODIFY 或 CHANGE 子句。
例如,把字段 mobile 的类型从 CHAR(1) 改为 CHAR(11),可以执行以下命令:
mysql> ALTER TABLE user_info MODIFY mobile CHAR(11);
使用 CHANGE 子句, 语法有很大的不同。 在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型。尝试如下实例:
# 修改字段名称
mysql> ALTER TABLE user_info CHANGE mobile phone CHAR(11);
# 修改字段名称+数据类型
mysql> ALTER TABLE user_info CHANGE mobile phone VARCHAR;
4、删除数据库:drop命令用于删除数据库。
mysql> drop database <数据库名>;
执行以上命令后,i 字段会自动添加到数据表字段的末尾。
5、使用数据库
mysql> use <数据库名>;
三、表操作命令
1、创建表:
创建MySQL数据表需要以下信息:
- 表名
- 表字段名
- 定义每个表字段
以下为创建MySQL数据表的SQL通用语法:
CREATE TABLE table_name (column_name column_type);
创建数据表article:
CREATE TABLE `article` (
`pk_id` int NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL COMMENT '文章标题',
`author_id` int NOT NULL COMMENT '文章作者ID',
`category_id` int NULL COMMENT '文章分类',
`reading_quantity` int NULL COMMENT '阅读量',
`status` int NULL COMMENT '文章状态,0:草稿箱 1:审核中 2:已发布',
`release_date` timestamp NULL COMMENT '文章发布时间',
`update_date` timestamp NULL COMMENT '文章修改时间',
PRIMARY KEY (`pk_id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 这里为了方便演示各种SQL语句,所以我把所有字段全部放在在一张表里
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
- ENGINE 设置存储引擎,CHARSET 设置编码。
2、插入数据
INSERT INTO `game`.`article`(`pk_id`, `title`, `author_id`, `category_id`, `reading_quantity`, `status`, `release_date`, `update_date`) VALUES (1, 'MySQL基础总结', 1, 1, 5000, 0, '2021-09-03 16:18:54', '2021-09-03 16:18:56');
INSERT INTO `game`.`article`(`pk_id`, `title`, `author_id`, `category_id`, `reading_quantity`, `status`, `release_date`, `update_date`) VALUES (2, 'MySQL索引', 1, 1, 4000, 0, '2021-09-03 16:23:32', '2021-09-03 16:23:34');
INSERT INTO `game`.`article`(`pk_id`, `title`, `author_id`, `category_id`, `reading_quantity`, `status`, `release_date`, `update_date`) VALUES (3, 'MySQL事务', 1, 1, 3000, 0, '2021-09-03 16:24:20', '2021-09-03 16:24:22');
3、查询数据
select * from article where pk_id in(1,2);

查询pk_id等于1和2的数据
4、修改数据
update article set title="MySQL基础总结(精品)" where pk_id = 1;
我们把title设置为MySQL基础总结(精品),只针对pk_id=1这行记录。
5、删除数据
delete from article where pk_id = 1;
把pk_id等于1的记录删除
6、清空表数据
truncate article;
7、修改表注释
alter table article comment '文章表';
8、表查询
我们先插入测试数据:
INSERT INTO `game`.`article`(`pk_id`, `title`, `author_id`, `category_id`, `reading_quantity`, `status`, `release_date`, `update_date`) VALUES (1, 'MySQL基础总结', 1, 1, 5000, 0, '2021-09-03 16:18:54', '2021-09-03 16:18:56');
INSERT INTO `game`.`article`(`pk_id`, `title`, `author_id`, `category_id`, `reading_quantity`, `status`, `release_date`, `update_date`) VALUES (2, 'MySQL索引', 1, 1, 4000, 0, '2021-09-03 16:23:32', '2021-09-03 16:23:34');
INSERT INTO `game`.`article`(`pk_id`, `title`, `author_id`, `category_id`, `reading_quantity`, `status`, `release_date`, `update_date`) VALUES (3, 'MySQL事务', 1, 1, 3000, 0, '2021-09-03 16:24:20', '2021-09-03 16:24:22');
(1)like,模糊查询
## 模糊查询:like,%标识匹配任意哥字符,_表示匹配一个字符
## 查询article表标题含有MySQL的文章
select * from article where title like '%MySQL%';

(2)in操作符允许您在 WHERE 子句中规定多个值。
select * from article where reading_quantity in (5000,6000);

查询阅读量是5000或者6000的文章
(3)or
select * from article where reading_quantity = 5000 or author_id = 2;

查询阅读量等于5000或者作者ID等于2的文章
(3)and
select * from article where author_id = 1 and reading_quantity >= 5000;

查询作者ID等于1且阅读量大于等于5000的文章
(4)order by,排序
select * from article order by reading_quantity asc

asc升序、desc降序排序
(5)limit,分页查询
# 从1开始,返回两条记录
select * from article limit 1,2;

limit(初始记录行的偏移量是 0,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目
(6)distinct,去重
select distinct title from article;
按title去重
(7)group by,分组查询
select author_id,count(0) from article where status = 1 group by author_id;
查询每个作者发布了多少篇文章
(8)case
select *, (
case
when reading_quantity >= 5000 then
'热点文章'
when reading_quantity >= 4000 then
'优质文章'
when reading_quantity >= 3000 then
'普通文章'
else
'低质量文章'
end
) '文章等级'
from
article

我把上述SQL语句转成Java代码大家就懂了
if(reading_quantity >= 5000){
}else if(reading_quantity >= 4000){
}else if(reading_quantity >= 3000){
}else{
}
四、数据类型
MySQL中定义数据字段的类型对你数据库的优化是非常重要的。
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
1.数值类型
(1)整数类型
- 整数类型的数,默认情况下既可以表示正整数又可以表示负整数(此时称为有符号数)。如果只希望表示零和正整数,可以使用无符号关键字“unsigned”对整数类型进行修饰。
- 各个类别存储空间及取值范围。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
(2)小数类型
- decimal(length, precision)用于表示精度确定(小数点后数字的位数确定)的小数类型,length决定了该小数的最大位数,precision用于设置精度(小数点后数字的位数)。
- 例如: decimal (5,2)表示小数取值范围:999.99~999.99 decimal (5,0)表示: -99999~99999的整数。
- 各个类别存储空间及取值范围。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| FLOAT | 4 bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
2.日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小 (bytes) |
范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
3.字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
注意:char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
五、函数
MySQL提供了众多功能强大、方便易用的函数,使用这些函数,可以极大地提高用户对于数据库的管理效率,从而更加灵活地满足不同用户的需求。本文将MySQL的函数分类并汇总,以便以后用到的时候可以随时查看。
准备工作:
创建表:
-- 文章表
CREATE TABLE `article` (
`pk_id` int NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL COMMENT '文章标题',
`author_id` int NOT NULL COMMENT '文章作者ID',
`category_id` int NULL COMMENT '文章分类',
`reading_quantity` int NULL COMMENT '阅读量',
`status` int NULL COMMENT '文章状态,0:草稿箱 1:审核中 2:已发布',
`release_date` timestamp NULL COMMENT '文章发布时间',
`update_date` timestamp NULL COMMENT '文章修改时间',
PRIMARY KEY (`pk_id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入数据
INSERT INTO `game`.`article`(`pk_id`, `title`, `author_id`, `category_id`, `reading_quantity`, `status`, `release_date`, `update_date`) VALUES (1, 'MySQL基础总结', 1, 1, 5000, 0, '2021-09-03 16:18:54', '2021-09-03 16:18:56');
INSERT INTO `game`.`article`(`pk_id`, `title`, `author_id`, `category_id`, `reading_quantity`, `status`, `release_date`, `update_date`) VALUES (2, 'MySQL索引', 1, 1, -4000, 0, '2021-09-03 16:23:32', '2021-09-03 16:23:34');
INSERT INTO `game`.`article`(`pk_id`, `title`, `author_id`, `category_id`, `reading_quantity`, `status`, `release_date`, `update_date`) VALUES (3, 'MySQL事务', 1, 1, 3000, 0, '2021-09-03 16:24:20', '2021-09-03 16:24:22');
这里为了方便演示绝对值等函数,我把pk_id等于2的阅读量设置为-4000
数据列表:

1.MySQL数字函数
(1)ABS(x)
描述:返回 x 的绝对值
案例:
select pk_id,abs(reading_quantity) from article;

pk_id等于1的记录,reading_quantity是-4000,通过abs(reading_quantity)就变成了4000
(2)AVG(expression)
描述:返回一个表达式的平均值,expression 是一个字段
案例:
select AVG(reading_quantity) from article;

(3)MAX(expression)
描述:返回字段 expression 中的最大值
案例:
select max(reading_quantity) from article;

(4)MIN(expression)
描述:返回字段 expression 中的最小值
案例:
select min(reading_quantity) from article;

(5)CEIL(x)
描述:向上取舍
案例:
SELECT CEIL(1.5)
-> 2
SELECT CEIL(-1.5)
-> -1
(6)FLOOR(x)
描述:向下取舍
案例:
SELECT FLOOR(1.5)
-> 1
SELECT FLOOR(-1.5)
-> -2
(7)ROUND(x)
描述:四舍五入
案例:
SELECT ROUND(1.4)
-> 1
SELECT ROUND(1.5)
-> 2
(8)SUM(expression)
描述:返回指定字段的总和
案例:
select sum(reading_quantity) from article;

2.MySQL字符串函数
(1)CHARACTER_LENGTH(s)
描述:返回字符串 s 的字符数
案例:
select pk_id,title,CHARACTER_LENGTH(title) from article;

(2)CONCAT(s1,s2…sn)
描述:字符串 s1,s2 等多个字符串合并为一个字符串
案例:
select pk_id,CONCAT(title,author_id) from article;

把title字段和author_id合并起来。
(3)LEFT(s,n)
描述:返回字符串 s 的前 n 个字符
案例:
select pk_id,left(title,1) from article;

(4)RIGHT(s,n)
描述:返回字符串 s 的后 n 个字符
案例:
select pk_id,right(title,1) from article;

(5)LOWER(s)
描述:将字符串 s 的所有字母变成小写字母
案例:
SELECT LOWER('JAVA')
-> java
(6)UPPER(s)
描述:将字符串转换为大写
案例:
SELECT LOWER('java')
-> JAVA
(7)LTRIM(s)
描述:去掉字符串 s 开始处的空格
SELECT LTRIM(" JAVA")
-> JAVA
(8)REPLACE(s,s1,s2)
描述:将字符串 s2 替代字符串 s 中的字符串 s1
案例:
SELECT REPLACE('abc','a','x')
-> xbc
(9)REVERSE(s)
描述:将字符串s的顺序反过来
SELECT REVERSE('JAVA')
-> AVAJ
(10)SUBSTR(s, start, length)
描述:从字符串 s 的 start 位置截取长度为 length 的子字符串
select pk_id,substr(title,1,2) from article;

3.MySQL时间和日期函数
(1)CURDATE()
描述:返回当前日期
案例:
SELECT CURDATE();
-> 2021-08-18
(2)NOW()
描述:返回当前日期和时间
案例:
SELECT NOW()
-> 2021-09-03 17:14:15
(3)MONTH(d)
描述:返回日期d中的月份值,1 到 12
案例:
select pk_id,month(release_date) from article;

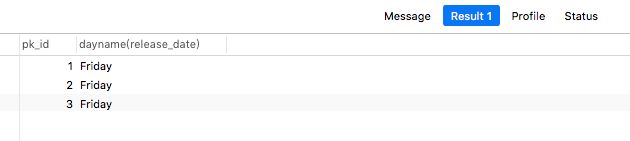
(4)DAYNAME(d)
描述:返回日期 d 是星期几,如 Monday,Tuesday
案例:
select pk_id,dayname(release_date) from article;
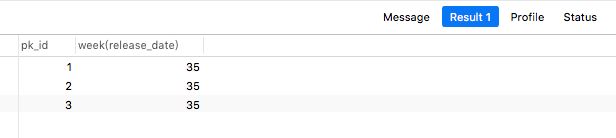
(5)WEEK(d)
描述:计算日期 d 是本年的第几个星期,范围是 0 到 53
案例:
select pk_id,week(release_date) from article;
六、连接查询
-
内连接
- 等值连接
- 非等值连接
-
外连接
- 左外连接
- 右外连接
-
自连接
准备数据:
CREATE TABLE `dept` (
`department_id` int NOT NULL AUTO_INCREMENT COMMENT '部门编号',
`dname` varchar(255) NULL COMMENT '部门名字',
`location` varchar(255) NULL COMMENT '地址',
PRIMARY KEY (`department_id`)
) COMMENT = '部门表';
CREATE TABLE `employee` (
`employee_id` int(0) NOT NULL AUTO_INCREMENT COMMENT '员工编号',
`c_name` varchar(255) NULL COMMENT '员工中文名',
`e_name` varchar(255) NULL COMMENT '员工英文名',
`hiredate` timestamp(0) NULL COMMENT '雇佣日期,入职日期',
`salary` int(11) NULL COMMENT '薪水',
`comm` int(11) NULL COMMENT '奖金',
`job_id` int(11) NULL COMMENT '所属工种',
`department_id` int(11) NULL COMMENT '部门编号',
`manager_id` int(11) NULL COMMENT '直接领导编号',
PRIMARY KEY (`employee_id`)
) COMMENT = '员工表';
-- 表中插入数据
insert into dept values(10,'财务部','北京');
insert into dept values(20,'研发部','上海');
insert into dept values(30,'销售部','广州');
insert into dept values(40,'行政部','深圳');
insert into dept values(50,'人力资源','南京');
-- 表中插入数据
insert into employee values(1,'小红','xiaohong','1980-12-17',7902,800,1,10,2);
insert into employee values(2,'铁蛋','tiedan','1981-02-20',7698,1600,3,30,3);
insert into employee values(3,'张三','zhangsan','1981-02-22',7698,1250,5,30,4);
insert into employee values(4,'李四','lisi','1981-04-02',7839,2975,2,20,5);
insert into employee values(5,'王老五','wanglaowu','1981-09-28',7698,1250,1,40,0);
insert into employee values(6,'赵六','zhaoliu','1981-05-01',7839,2850,3,50,5);
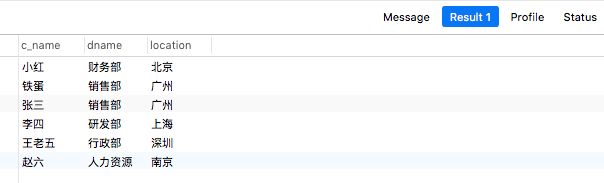
-- 内连接
select e.c_name,d.dname,d.location from employee e inner join dept d on e.department_id= d.department_id;
-- 左外连接,是指以左边的表的数据为基准,去匹配右边的表的数据,如果匹配到就显示,匹配不到就显示为null
-- 查询employee表中的所有数据和dept表中与employee中相匹配的数据,若是没有匹配的就显示null
select e.c_name,d.dname from employee e left outer join dept d on d.department_id = e.department_id ;

-- 右外连接和左外连接只不过是左右表相换也能达到同样的效果
-- 这里就是查询dept部门表对应所有部门和employee表中与之对应的数据,你会发现本来employee中有6条数据,只显示了5条数据,因为有一个人的部门60再dept中没有数据,所以就没有显示出来。
select e.c_name,d.dname from employee e right outer join dept d on d.department_id = e.department_id;

-- 自连接查询就是当前表与自身的连接查询,关键点在于虚拟化出一张表给一个别名
-- 查询员工以及他的上司的名称,由于上司也是员工,所以这里虚拟化出一张上司表
select e.c_name 员工名,b.c_name 上司名 from employee e left join employee b on e.manager_id= b.employee_id;
