从IDC到云端架构迁移之路(GITC2016)
大家好,很高兴来到GITC2016的舞台,我是来自58到家的沈剑,今天我分享的主题是《58到家从IDC到云端架构迁移之路》。
机房迁移是一个很大的动作:
15年在58同城实施过一次(“逐日”项目),几千台物理机,从IDC迁到了腾讯的天津机房,项目做了10个多月,跨所有的部门,与所有的业务都相关;
16年在58到家又实施了一次(“凌云”项目),几百台虚拟机,从IDC迁到阿里云,前后大概一个季度的时间,也是所有技术部门都需要配合的一个大项目。
“单机房架构-全连”
要说机房迁移,先来看看被迁移的系统是一个什么样的架构。

上图是一个典型的互联网单机房系统架构:
(1)上游是客户端,PC浏览器或者APP;
(2)然后是站点接入层,为了面对高流量,保证架构的高可用,站点冗余了多份;
(3)接下来是服务层,服务层又分为与业务相关的业务服务,以及业务无关的基础服务,为了保证高可用,所有服务也冗余了多份;
(4)底层是数据层,数据层又分为缓存数据与数据库;
至于为什么要做分层架构,不是今天的重点,不做展开讨论,这是一个典型的互联网单机房分层架构:所有的应用、服务、数据是部署在同一个机房,这个架构有的一个关键词,叫做“全连”:
(1)站点层调用业务服务层,业务服务复制了多少份,上层就要连接多少个服务;
(2)业务服务层调用基础服务层,基础服务复制了多少份,上层就要连多少个服务;
(3)服务层调用数据库,从库冗余了多少份,上层就要连多少个从库;
比如说,站点接入层某一个应用有10台机器,业务服务层某一个服务有8层机器,那肯定是上游的10台会与下游的8台进行一个全相连的。系统架构的可用性保证,负载均衡保证,是服务的连接池去做的。不仅仅接入层连接业务服务层是这样,业务服务层连接基础服务层,服务层连接数据库也都是这样,这就是所谓的“全连”。
“机房迁移的目标是平滑”
单机房架构的特点是“全连”,那么机房迁移我们是要做一个什么样的事情呢?先看这张图:

之前单机房架构部署在机房A内,迁移之后仍然是单机房架构,只是换了一个B机房,做完这个迁移,有什么好的方案?最容易想到的一个方案,把所有服务在新机房全部搭一套,然后流量切过来了。
当系统有几千台机器,有非常非常多的业务的时候,这是一种“不成功便成仁”的方案。做技术的都知道,设计时要考虑回滚方案,如果只有上线方案而没有回滚方案,这便是一个“不成功便成仁”的方案,根据经验,不成功便成仁的操作结果,往往就“便成仁”了。
最重要的是,全量搭建一套再流量切换,数据层你怎么搭建一套?怎么切?数据层原来都在A机房,B机房还没有全量的数据,是没办法直接切的。要做一个数据同步的方案,最简单的,停两个小时服务,把数据从旧机房导到新机房,数据导完流量再切过去,这是一个数据迁移的简单方案。这个方案对业务有影响,需要停止服务,这个是无法接受的,何况像58同城一样有两千多台机器,无限多的数据库实例,无限多的数据表的时候,停服务迁移数据根本是不可能的。
所以,机房迁移的难点,是“平滑”迁移,整个过程不停服务,整体迁移方案的目标是:
(1)可以分批迁移;
(2)随时可以回滚;
(3)平滑迁移,不停服务;
“伪多机房架构-同连”
如果想要平滑的迁移机房,不停服务,在10个月的逐步迁移过程中,肯定存在一个中间过渡阶段,两边机房都有流量,两边机房都对外提供服务,这就是一个多机房的架构了。
多机房架构是什么样的架构呢?刚刚提到了单机房架构,上层连中层,中层连下层,它是一个全连的架构,能不能直接将单机房的全连架构套用到多机房呢?在另一个机房部署好站点层、服务层、数据层,直接使用“全连”的单机房架构,我们会发现:会有非常多跨机房的连接
(1)站点层连接业务服务层,一半的请求跨机房
(2)业务服务层连接基础服务层,一半的请求跨机房
(3)基础服务层连数据层(例如从库),一半的请求跨机房
大量的跨机房连接会带来什么样的问题呢?
我们知道,同机房连接,内网的性能损耗几乎可以忽略不计,但是一旦涉及到跨机房的访问,即使机房和机房之间有专线,访问的时延可能增加到几毫秒(跟几房间光纤距离有关)。
用户访问一个动态页面,需要用到很多数据,这些数据可能需要10次的业务服务层调用,业务服务层可能又有若干次基础服务层的调用,基础服务层可能又有若干次数据层的调用,假设整个过程中有20次调用,其中有一半调用跨机房,假设机房之间延迟是5毫秒,因为跨机房调用导致的请求迟延就达到了50毫秒,这个是不能接受的。
因此,在多机房架构设计时,要尽量避免跨机房调用(避免跨机房调用做不到,也要做到“最小化”跨机房调用),会使用“同连”的系统架构。

“同连”也很好理解,在非必须的情况下,优先连接同机房的站点与服务:
(1)站点层只连接同机房的业务服务层;
(2)业务服务层只连接同机房的基础服务层;
(3)服务层只连接同机房的“读”库;
(4)对于写库,没办法,只有跨机房读“写”库了;
这个方案没有完全避免跨机房调用,但其实它做到了“最小化”跨机房调用,写主库是需要跨机房的。但互联网的业务,99%都是读多写少的业务,例如百度的搜索100%是读业务,京东淘宝的电商99%的浏览搜索是读业务,只有下单支付是写业务,58同城99%帖子的列表详情查看是读业务,发布帖子是写业务,写业务比例相对少,只有这一部分请求会跨机房调用。
迁移机房的过程使用这样一个多机房的架构,最大的好处就是,除了“配置文件”,整个单机房的架构不需要做任何修改,这个优点是很诱人的,所有的技术部门,所有的业务线,只需要配合在新机房部署应用与服务(数据库是DBA统一部署的),然后使用不同的配置文件(如果有配置中心,这一步都省了),就能实现这个迁移过程,大大简化了迁移步骤。
这个方案当然也有它的不足:
(1)跨机房同步数据,会多5毫秒(举个栗子,不要叫真这个数值)延时(主从本来会有延时,这个延时会增大),这个影响的是某一个机房的数据读取;
(2)跨机房写,会多5毫秒延时,这个影响的是某一个机房的数据写入,当然这个写请求比例是很小的;
这个“同连”架构非常适用于做机房迁移,当然也可以用作多机房架构,用作多机房架构时,还有一个缺点:这个架构有“主机房”和“从机房”的区分。
多机房架构的本意是容机房故障,这个架构当出现机房故障时,例如一个机房地震了,把入口处流量切到另一个机房就能容错,不过:
(1)挂掉的是不包含数据库主库的从机房,迁移流量后直接容错;
(2)挂掉的是包含数据库主库的主机房,只迁移流量,其实系统整体99%的读请求可以容错,但1%的写请求其实会受到影响,此时需要人工介入,将从库变为主库,才能完全容错。这个过程只需要DBA介入,不需要所有业务线上游修改(除非,除非,业务线直接使用的IP连接,这个,我就不说什么了)。
也正是因为这个原因,在机房故障的时候,有一定概率需要少量人工介入,才能容100%的机房故障,因此这个架构才被称为“伪多机房架构”,还不是完全的“多机房多活”架构。
“自顶向下的机房迁移方案”
话题收回来,机房迁移的过程中,一定存在一个中间过渡阶段,两边机房都有流量,两边机房都对外提供服务的多机房架构。具体到机房的逐步迁移,又是个什么步骤呢?通常有两种方案,一种是自顶向下的迁移,一种是自底向上的迁移,这两种方案在58到家和58同城分别实行过,都是可行的,方案有类似的地方,也有很多细节不一样,因为时间关系展开说一种,在58到家实施过的“自顶向下”的机房迁移方案,整个过程是平滑的,逐步迁移的,可回滚的,对业务无影响的。
“站点与服务的迁移”
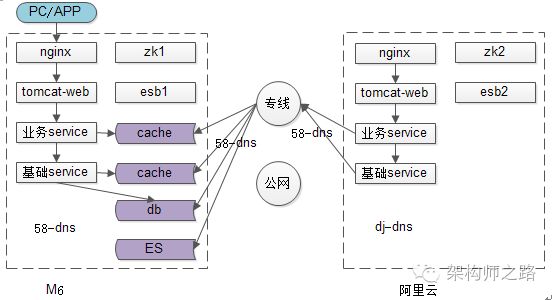
迁移之前当然要做一些提前准备,新机房要准备就绪,专线要准备就绪,这个是前提。
自顶向下的的迁移,最先迁移站点层和服务层:先在新机房,把站点层和服务层搭建好,并做充分的测试(此时数据层比如说缓存和数据库还是在原来的机房)。测试,测试,测试,只要流量没有迁移,在新机房想怎么玩都行,新机房准备的过程中,要注意“同连”,原有机房的配制文件是完全不动的,肯定也是“同连”。
站点层与服务层的迁移,也是一个业务一个业务的逐步迁移的,类似蚂蚁搬家。充分的测试完一个业务的站点层和服务层之后,为了求稳,先切1%的流量到新机房,观察新机房的站点与服务有没有异常,没有问题的话,再5%,10%,20%,50%,100%的逐步放量,直至第一波蚂蚁搬完家。
第一个业务的站点和服务迁移完之后,第二个业务、第三个业务,蚂蚁继续搬家,直至所有的业务把站点层和服务层都全流量的迁移到新机房。
在整个迁移的过程中,任何一个业务,任何时间点发现有问题,可以将流量切回,旧机房的站点、服务、配置都没有动过,依然能提供服务。整个迁移步骤,是比较保险的,有问题随时可以迁回来。
“缓存的迁移”
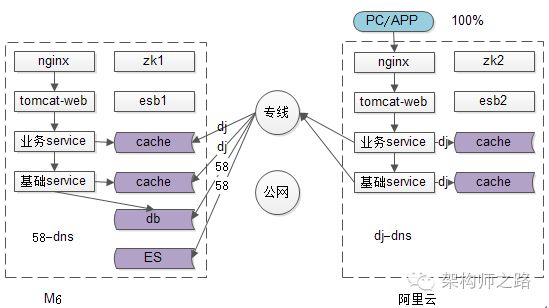
站点层和服务层迁移完之后,接下来我们迁数据层,数据层又分为缓存层和数据库层,先迁缓存。
经过第一步的迁移,所有的入口流量都已经迁到了新的机房(当然旧机房的站点和服务还是不能停,只要旧机房不停,任何时间点出问题,最坏的情况下流量迁回来),接下来迁移缓存,先在新机房要搭建好缓存,缓存的规模和体量与旧机房一样大。
流程上仍然是蚂蚁搬家,按照业务线逐步的迁缓存,使用同连的方式。这个缓存切换的步骤非常的简单:运维做一个缓存内网DNS的切换(内网域名不变,IP切到新机房),并杀掉原有缓存连接,业务线不需要做任何修改,只需要配合观察服务。运维杀掉原有缓存连接之后,程序会自动重连,重连上的缓存就是新机房的缓存了,bingo,迁移完毕。
这里要注意几个点:
(1)有些公司缓存没有使用内网域名,而是采用IP直连的话,则需要业务层配合,换新机房IP重启一下即可(如果是IP直连,说明这个架构还有改进的空间哟);
(2)这个操作尽量选在流量低峰期,旧缓存中都是热数据,而新缓存是空数据,如果选在流量高峰期,缓存切换之后,短时间内可能会有大量请求透传到数据库上去,导致数据库压力过大;
(3)这个通用步骤,适用于允许cache miss的业务场景,如果业务对缓存有高可用的要求,不允许cache miss,则需要双写缓存,或者缓存使用主从同步的架构。大部分缓存的业务场景都是允许cache miss的,少数特殊业务使用特殊的方案迁移。
缓存的迁移也是按照业务线,一步步蚂蚁搬家式完成的。在迁移过程中,任何一个业务,任何时间点发现有问题,可以将流量切回原来的缓存。所以迁移的过程中,不仅是站点层和服务层,旧机房的缓存层也是不停服务的,至少保证了流量迁回这个兜底方案。
“数据库的迁移”
站点层,服务层,缓存层都迁移完之后,最后是数据库的迁移。

数据库还是在旧机房,其他的缓存,服务,站点都迁移到新机房了,服务通过专线跨机房连数据库。
如何进行数据库迁移呢,首先肯定是在新机房搭建新的数据库,如果是自建的IDC机房,需要自己搭建数据库实例,58到家直接用的是阿里云的RDS。
搭建好数据库之后,接下来进行数据同步,自建机房可以使用数据库MM/MS架构同步,阿里云可以使用DTS同步,DTS同步有一个大坑,只能使用公网进行同步,但问题也不大,只是同步的时间比较长(不知道现能通过专线同步数据了吗?)。
数据库同步完之后,如何进行切换和迁移呢?能不能像缓存的迁移一样,运维改一个数据库内网DNS指向,然后切断数据库连接,让服务重连新的数据库,这样业务服务不需要改动,也不需要重启,这样可以么?
这个方式看上去很不错,但数据库的迁移没有那么理想:
第一,得保证数据库同步完成,才能切流量,但数据同步总是有迟延的,旧机房一直在不停的写如数据,何时才算同步完成呢?
第二,只有域名和端口不发生变化,才能不修改配置完成切换,但如果域名和端口(主要是端口)发生变化,是做不到不修改配置和重启的。举个例子,假设原有数据库实例端口用了5858,很吉利,而阿里云要求你使用3200,就必须改端口重启。
所以,我们最终的迁移方案,是DBA在旧机房的数据库设置一个read only,停止数据的写入,在秒级别,RDS同步完成之后,业务线修改数据库端口,重启连接新机房的数据库,完成数据层的切换。
经过上述站点、服务、缓存、数据库的迁移,我们的平滑机房的目标就这么一步步完成啦。
总结与问答
四十分钟很短,focus讲了几个点,希望大家有收获。
做个简要的总结:
(1)互联网单机房架构的特点,全连,站点层全连业务服务层,业务服务层全连的基础服务层,基础服务层全连数据库和缓存;
(2)多机房架构的特点,同连,接入层同连服务层,服务层同连缓存和数据库,架构设计上最大程度的减少跨机房的调用;
(3)自顶向下的机房迁移方案:先进行站点接入层、业务服务层和基础服务层的迁移,搭建服务,逐步的迁移流量;然后是缓存迁移,搭建缓存,运维修改缓存的内网DNS指向,断开旧连接,重连新缓存,完成迁移;最后数据库的迁移,搭建数据库,数据进行同步,只读,保证数据同步完成之后,修改配置,重启,完成迁移。整个过程分批迁移,一个业务线一个业务线的迁移,一块缓存一块缓存的迁移,一个数据库一个数据库的迁移,任何步骤出现问题是可以回滚的,整个过程不停服务。
主持人:讲的很细致,大家有什么问题吗,可以提一些问题,可以举手示意我。
提问:做数据迁移的时候,因为您讲的数据中心的都是在同一个老机房,同时又在做同步,我就在想这个数据库的压力是不是特别大。
沈剑:非常好的问题,这个地方一方面要考虑压力,更重要的是考虑跨机房的专线,风险最大的是在带宽这一部分,你在第一步迁移完之后,其实所有的缓存,数据库用其实都是跨机房的,都是通过专线去走的,这个专线带宽是需要重点考虑与评估的,数据库的压力其实还好。
提问:我想请教一个问题,你这个流量切换的过程中,有测试性的阶段还是直接切过去的。
沈剑:在切流量之前,肯定是有测试的,在新机房将服务搭建,在切换流量之前,测试的同学需要进行回归,回归的过程可以提前发现很多问题。逐步的切流量也是为了保证可靠性,我们不是一次性百分之百流量都切过来,先切1%的流量过来,观察服务没有问题,再逐步增大流量切换。
主持人:上午先到这里,也欢迎大家关注沈老师的“架构师之路”微信公众号,下午我们准时开始,大家注意好休息时间,谢谢大家。
帮忙随手转发哟。
==【完】==
回【钱包】入驻微信钱包的技术优化
回【消息】58到家通用实时消息平台架构细节
回【秒杀】秒杀系统架构优化思路
回【设置】线程数究竟设多少合理
回【单点】单点系统架构的可用性与性能优化
回【事务】多库多事务降低数据不一致概率
【小游戏:回大于10的整数,随机返回好文,猜猜怎么实现的】

欢迎讨论,有问必答。