Windows环境中,在pycharm中安装和使用Selenium
文章目录
-
-
- 一、前言
- 二、安装浏览器驱动
-
-
- 下载浏览器驱动
- 将浏览器驱动放入python中
- 在pycharm中下载Selenium
-
- 三、使用Selenium
-
一、前言
我们在学爬虫的时候,使用Selenium库可以帮助我们更好的抓取网页中的内容,我接下介绍的是如下载浏览器驱动和使用Selenium抓取网页
二、安装浏览器驱动
-
下载浏览器驱动
我使用的是Chrome浏览器,所以我们下载chromedriver
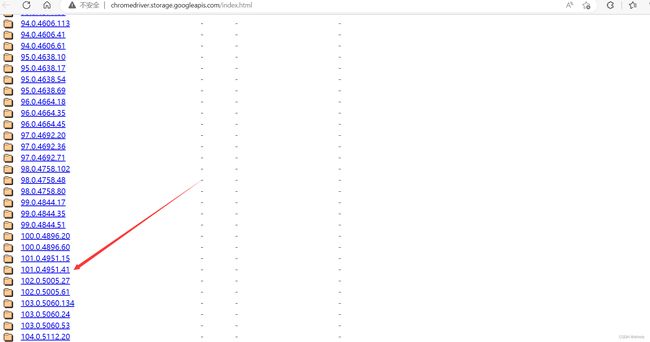
下载地址: http://chromedriver.storage.googleapis.com/index.html
下载之前我们需要知道自己的Chrome浏览器是什么版本
打开Chrome,点击主页右上角的三个点号
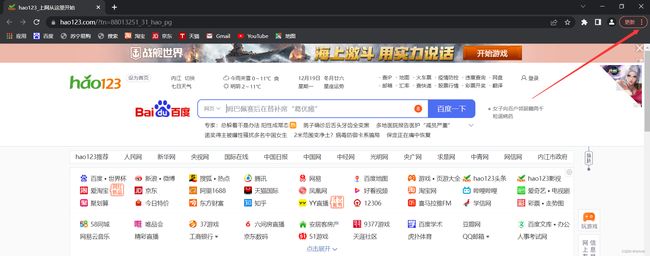
点击帮助——>点击关于Goole Chrome

在这里我们可以看到Chrome的版本信息
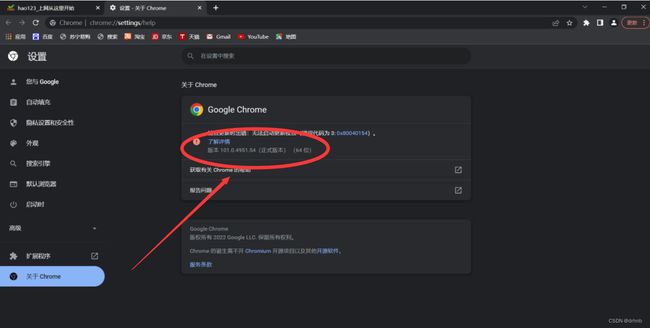
然后我们在下载地址中找到相对应的版本,下载即可(注意:win系统不区分64位和32位,直接下载32位即可,版本也不一定完全相同,小于当前版本和当前版本相兼容即可)
下载完成后将压缩包进行解压,可以得到一个chromedriver.exe可执行文件,那么我们第一就完成了,接下来进入到将浏览器驱动放入python环境中。
-
将浏览器驱动放入python中
在桌面搜索python
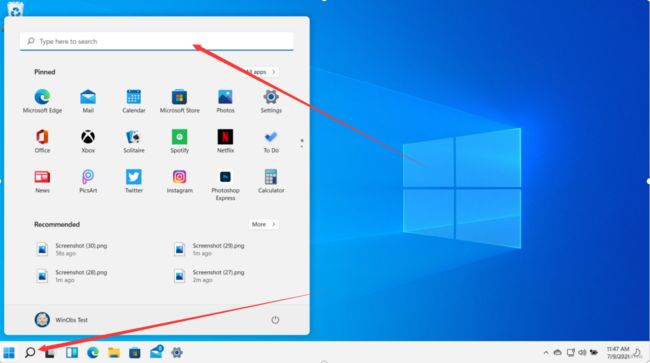
右键单击python——>点击"打开文件位置”
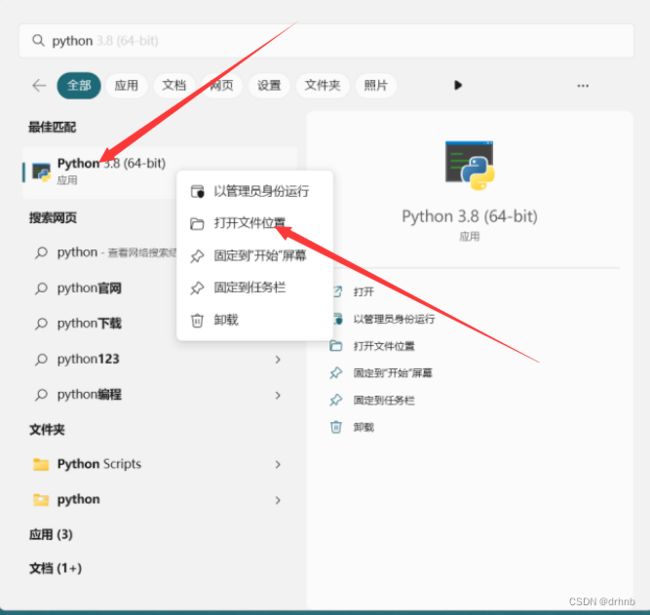
我们会发现有三个快捷方式,我们随便选择一个,左键点击选中——>然后右键单击——>点击属性
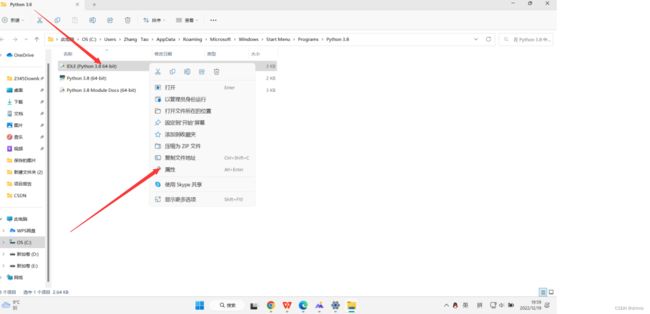
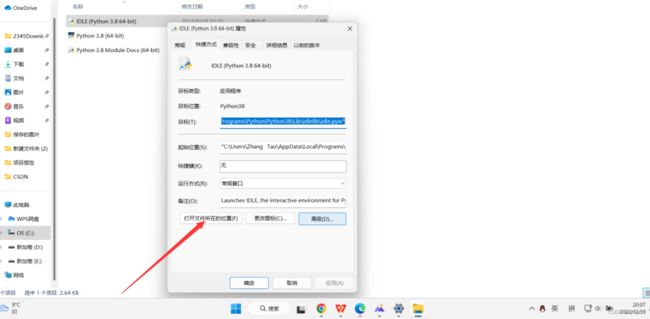
最后点击"打开文件所在的位置",就可以找到我们python文件的根目录
然后将下载的chromedriver.exe复制到python根目录下
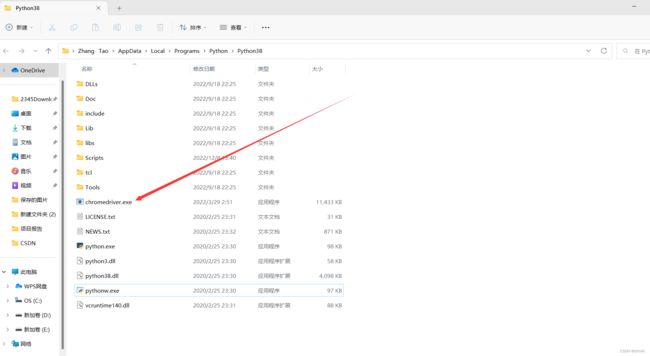
就完成了对浏览器驱动的下载
-
在pycharm中下载Selenium
打开pycharm
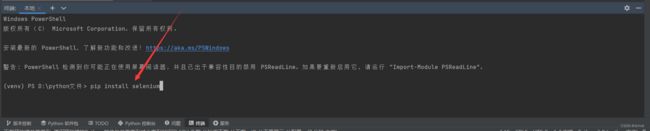
点击"终端(terminal)"
输入pip install selenium
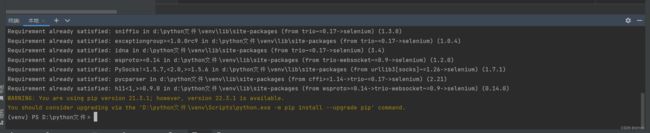
出现这个界面表示下载完成
三、使用Selenium
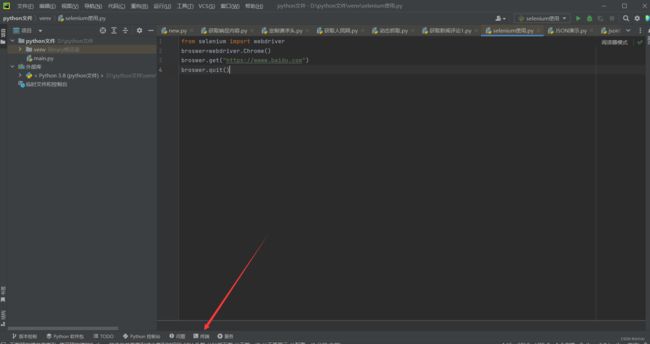
在pycharm中新建个py文件,可以运行下面的代码,来检验selenium是否可以正常运行
from selenium import webdriver
broswer=webdriver.Chrome() #声明浏览器对象
broswer.get("https://wwww.baidu.com")#访问百度页面
broswer.quit()#关闭浏览器
如果发现程序打开了Chrome浏览器,并访问了百度页面,然后关闭了页面,说明selenium可以正常使用了。