数据库分库分表的应用场景及方法分析
数据库分库分表的应用场景及方法分析
一. 数据库经常面临的问题

二.解决方法的思量

三.急剧膨胀的业务及数据量的影响
以电商领域为例,订单库将订单相关的数据(订单销售,订单售后,订单任务处理等数据)都放在一个数据库
中。对于订单的销售数据,性能第一,需要能够承受促销期间每分钟几万到几十万的订单压力;而售后数据,在订
单生成后,用于订单物流及订单克服等,性能压力不明显,但是需要保证及时性。将订单的销售数据与售后数据放
在同一个库中会导致促销期间数据库压力增大,影响到售后业务的进行。这个时候我们需要考虑拆分数据库。
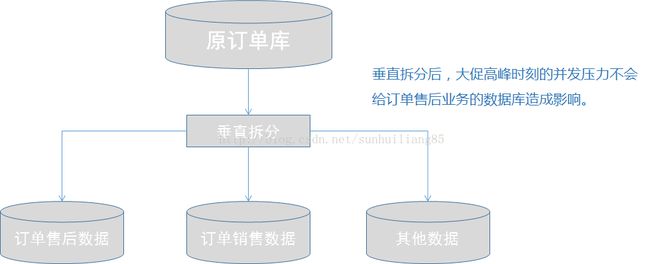
3.1数据库拆分策略|垂直分库
垂直分库在“微服务”盛行的今天已经非常普及了。基本思路就是按照业务模块来划分出不同的数据库。而
不是将所有的数据表都放在同一个数据库中。数据库层面的拆分能够使不同业务类型的数据进行独立的管理、维
护,监控和扩展。当然错误的业务拆分也会带来很多问题(跨库join,分布式事务)。
3.2数据库拆分|垂直分库的不足
垂直分库可以按照业务模块来划分出不同的数据库。将不同业务的数据表划分到不同数据中,从而解决了不同
业务系统间的热点问题。但是仍然无法解决单一业务数据库及数据表数据量过于庞大的问题。例如对于订单销售数
据,如果遇到大型的促销(如双11,618等),数据库TPS和QPS达到上限,单个销售订单库无法满足业务的需求。
当订单表相关数据量过大时也会造成单台数据库服务器硬盘容量饱和,不能满足业务需求。因此还需要进行进一步
的拆分。
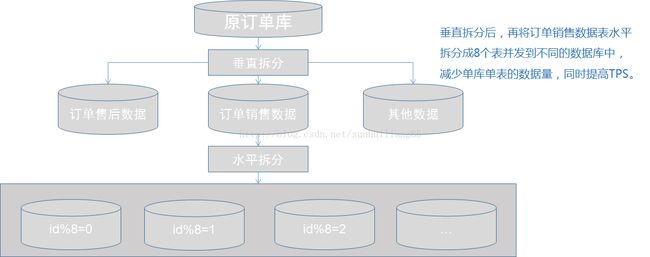
3.3数据库拆分策略|水平分表
当单表的数据量越来越大时,需要对数据库进行水平拆分。水平拆分就是将表中的数据行按照一定规律分布到
不同的数据表中。这样来降低单表数据量,优化查询性能。但是本质上这些表还是保存在同一个数据库中,所以
库级别上仍然会有IO和磁盘瓶颈。由于数据库TPS有限,所以需要考虑分库,把分表放在分库里面。减轻单库的压
力,增加总的TPS。
常见的水平切分算法有:范围法和哈希法。
3.4 数据库拆分策略|垂直水平拆分
垂直水平拆分,是综合了垂直和水平拆分方式的一种混合方式,垂直拆分把不同类型的数据存储到不同库中,再结合水平拆分,使单表数据量保持在合理范围内,提升总TPS,提升性能。
3.4.1 分库分表策略|范围法
当伴随着某一个表的数据量越来越大,以至于不能承受的时候,就需要对它进行进一步的切分。范围法是按照时间区间和ID区间来切分。如:ID 为1-10000的放到A表中,ID 为10000~20000的放到B表中。这样的扩展就是可预见的。
范围法的优点:
1.单表大小可控,天然水平扩展,扩容非常简单。
2.切分策略简单,根据主键或时间戳很容易定位到数据在哪个上
范围法的缺点:
1. 表中必须有满足自增特性的属性,例如主键必须满足递增特性或使用时间戳
2. 数据量不均衡,新扩展出的表初期数据会比较少
3. 请求量不均衡,一般来说新产生的数据往往比历史数据有更高的活跃度,更容易被访问。因此新的数据表
的负载往往比历史表要高,导致服务器利用率不均衡。
3.4.2 分库分表策略|哈希法
哈希法一般采用mod来切分,一开始就要确定要切分的数据库的个数,通过关键字hash取模来决定存储到哪个数据表中。这种方法能够平均的分配数据,但是伴随着数据量的增大,需要进行扩展的时候无法做到无线扩容。每增加节点的时候,就要对hash算法重新运算,调整数据表中的数据。
哈希法的优点:
1.切分策略简单,根据关键字,按照hash可以很容易定位到数据在哪个数据库上。
2.数据量均衡,只要关键字是均衡的,数据在各个库上的分布就是均匀的
3.请求量均衡,只要关键字是均衡的,数据在各个库上的分布就是均匀的
哈希法的缺点:
1. 扩容麻烦,如果容量不够,要增加一个库,重新hash可能会导致数据迁移,如何平滑的进行数据迁移,是
一个需要解决的问题。
3.4.3 分库分表策略|路由表
数据库进行分表分库后,大表中的数据分散存储在各个数据库中。在进行查询时往往需要通过范围法或者哈希法找到对应的数据库进行查询。但这只能满足按照关键字来进行的查询。当业务中存在按照其他属性进行查询的需求时就无法满足了,此时需要遍历全部数据库,显然不可接受。
路由表的策略是它单独维护一张路由表,根据用户的某一属性来查找路由表决定使用哪个数据库,这种方式是一种更加通用的方案。查询请求先通过属性查找路由表,找到该条数据所在的数据库,再进行查询。
3.4.4 分库分表策略|索引表
数据库进行分表分库后,大表中的数据分散存储在各个数据库中。在进行查询时往往需要通过范围法或者哈希法找到对应的数据库进行查询。但这只能满足按照关键字来进行的查询。当业务中存在按照其他属性进行查询的需求时就无法满足了,此时需要遍历全部数据库,显然不可接受。
索引表是用来维护其他属性与关键字的对应关系,当通过其他属性访问数据表时,先通过索引表找到该属性对应的关键字,在通过关键字按照范围法或者哈希法找到对应的数据库进行取数。
更优化的一种方案是将映射的结果存储在缓存中,属性与关键字的映射关系很少会发生变化,一旦放入缓存无需淘汰,缓存命中率超高。如果数据量过大,可以根据属性自动进行cache的水平切分。
3.5 如何选择分库分表策略
数据库拆分的目的是将单一数据库的大表数据拆分到不同的数据库的数据表中,从而达到消除对单一服务器磁盘容量和TPS的限制,做到可扩展。 除此之外,我们在进行数据表拆分时还需要考虑业务上的应用场景,采用合理的分库分表策略,否则会产生跨库join及分布式事务等问题。
那么,合理的分表分库策略需要如何确定呢?
1.合理分析业务场景,梳理出不同参与者对数据的需求场景以及对一致性和实时性的要求。
2.根据第一步的梳理结果,确定数据表需要支持查询的属性范围。并据此确定分库分表策略,思路是
同一维度条件的查询结果保证数据存储在同一个数据库表中,避免跨库join。
3.针对非uid属性的查询,可以采用“建立非uid属性到uid的映射关系”的架构方案。
4. 对访问量低,可用性要求不高,一致性要求没这么严格的查询业务系统,可以采用“前台与后台分离”的
架构方案,避免少数批量请求耗尽资源,导致数据库cpu瞬间占满,影响其他应用的访问。
5.针对“多key”类业务,需要采用“基因法”,“数据冗余法”,“前台与后台分离”等架构设计方法。
四.UID生成方案
UID做为数据表的主键,需要保证全局唯一。以保证分库分表后,同一业务的不同库表的数据的uid不能重复。
唯一UID的方案有很多,主流的有如下几种:
4.1 UID生成方案|Sequence
Sequence ID是数据库自增长序列或字段,最常见的方式。由数据库维护,数据库唯一。
优点:
缺点:
优化方案:
比如:Master1 生成的是1,4,7,10,Master2生成的是2,5,8,11 Master3生成的是3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
4.2 UID生成方案|UUID
UUID是一个32位16进制的序列。可以利用数据库也可以利用程序生成,一般来说全球唯一。GUID是微软对UUID标准的实现,UUID还有很多其他实现。
优点:
简单,代码方便。
全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
没有排序,无法保证趋势递增。
UUID往往是使用字符串存储,查询的效率比较低。
存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
传输数据量大
不可读。
优化方案:
为了解决UUID不可读,可以使用UUID to Int64的方法。
4.3 UID生成方案| Snowflake
Snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID,可以支持1024个节点),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生4096 个ID),最后还有一个符号位,永远是0。snowflake算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的bit数。
优点:
不依赖于数据库,灵活方便,且性能优于数据库。
ID按照时间在单机上是递增的。
缺点:
在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
4.3.1 UID生成方案| Snowflake实例
举例,假设某公司ID生成器服务的需求如下:
单机高峰并发量小于1W,预计未来5年单机高峰并发量小于10W
有2个机房,预计未来5年机房数量小于4个
每个机房机器数小于100台
目前有5个业务线有ID生成需求,预计未来业务线数量小于10个
…

分析过程如下:
高位取从2017年1月1日到现在的毫秒数(假设系统ID生成器服务在这个时间之后上线),假设系统至少运行10年,那至少需要10年*365天*24小时*3600秒*1000毫秒=320*10^9,差不多预留39bit给毫秒数
每秒的单机高峰并发量小于10W,即平均每毫秒的单机高峰并发量小于100,差不多预留7bit给每毫秒内序列号
5年内机房数小于4个,预留2bit给机房标识
每个机房小于100台机器,预留7bit给每个机房内的服务器标识
业务线小于10个,预留4bit给业务线标识
这样设计的64bit标识,可以保证:
每个业务线、每个机房、每个机器生成的ID都是不同的
同一个机器,每个毫秒内生成的ID都是不同的
同一个机器,同一个毫秒内,以序列号区区分保证生成的ID是不同的
将毫秒数放在最高位,保证生成的ID是趋势递增的
4.4 UID生成方案| Flicker
flickr开发团队在2010年撰文介绍了flickr使用的一种主键生成测策略,同时表示该方案在flickr上的实际运行效果也非常令人满意。它与一般Sequence表方案有些类似,但却很好地解决了性能瓶颈和单点问题,是一种非常可靠而高效的全局主键生成方案。整体思想是:建立两台以上的数据库ID生成服务器,每个服务器都有一张记录各表当前ID的Sequence表,但是Sequence中ID增长的步长是服务器的数量,起始值依次错开,这样相当于把ID的生成散列到了每个服务器节点上。例如:如果我们设置两台数据库ID生成服务器,那么就让一台的Sequence表的ID起始值为1,每次增长步长为2,另一台的Sequence表的ID起始值为2,每次增长步长也为2,那么结果就是奇数的ID都将从第一台服务器上生成,偶数的ID都从第二台服务器上生成,这样就将生成ID的压力均匀分散到两台服务器上,同时配合应用程序的控制,当一个服务器失效后,系统能自动切换到另一个服务器上获取ID,从而保证了系统的容错。
优点:高可用、ID较简洁
缺点:需要单独的数据库集群
4.5 UID生成方案|组合UID
组合UID,是一种带有业务属性的UID方案,取UID的前N位,再通过业务属性(其他主键)的二级制后N位来生成UID。例如:订单UID=60位全局唯一id+userid二进制末4位(如userid=666,其二级制为:0000 0010 1001 1010 ,取1010),此时省的订单id具有了用户的基因,在制定分表分库规则时,可以据此规则将同一用户的订单都放到同一张库表中。
优点:
1.解决UUID无序的问题
2.可以满足满足业务属性条件的数据都存储在同一个库表中,避免查询时的“跨库join”的情况。如分库分表时满足同一用户生成的订单都在同一个库表中。
http://blog.csdn.net/sunhuiliang85/article/details/78418004