使用python实现简单的词法分析器
引言
编译原理实验要求实现简单的词法分析器,正好最近在学习python,就使用python实现Java的词法分析器,功能比较简单,算是一个小小的实验吧。
1.基本符号表设计
采用字典的形式存储基本符号表,字典的键是Java的关键字,字典的值是符种,具体设计如下:
# 基本符号表
tables = {
# 关键字
'abstract': 0, 'assert': 1, 'boolean': 2, 'break': 3, 'byte': 4, 'case': 5, 'catch': 6, 'char': 7, 'class': 8,
'const': 9, 'continue': 10, 'default': 11, 'do': 12, 'double': 13, 'else': 14, 'enum': 15, 'extends': 16,
'final': 17, 'finally': 18, 'float': 19, 'for': 20, 'goto': 21, 'if': 22, 'implements': 23, 'import': 24,
'instanceof': 25, 'int': 26, 'interface': 27, 'long': 28, 'native': 29, 'new': 30, 'package': 31,
'private': 32, 'protected': 33, 'public': 34, 'return': 35, 'short': 36, 'static': 37, 'strictfp': 38,
'super': 39, 'switch': 40, 'synchronized': 41, 'this': 42, 'throw': 43, 'throws': 44, 'transient': 45,
'try': 46, 'void': 47, 'volatile': 48, 'while': 49, 'identify': 50,
# 操作符
'+': 89, '-': 90, '*': 91, '/': 92, '%': 93, '++': 94,
'--': 95, '+=': 117, '-=': 118, '/=': 120, '==': 100, '!=': 101, '>': 102, '<': 103, '>=': 104, '<=': 105,
'&': 106, '|': 107, '^': 108, '~': 109, '<<': 110, '>>': 111, '>>>': 112, '&&': 113, '||': 114,
'!': 115, '=': 116, '*=': 119, '%=': 121, '<<=': 122, '>>=': 123, '&=': 124, '^=': 125, '|=': 126, '?:': 127,
# 其他
'main': 128, 'digital': 130,
# 界符
'{': 134, '}': 135, '[': 136, ']': 137, '(': 138, ')': 139, '.': 140, ',': 141, ':': 142, ';': 143}
其中定义标识符的符种为50,定义整型数的符种为130。
2. 对需要进行编译的文件进行预处理
对Java文件进行预处理主要是对空格、换行符、缩进和界符进行处理,使用直接分割和正则表达式进行分割的方法,将文件中的空格、换行、缩进和界符进行分割,并且分割后的内容中包含空字符串,需要将空字符串处理,预处理的代码实现片段如下:
def preprocess(in_file):
content = []
# 打开文件开始预处理
with open(in_file, 'r', encoding='utf-8') as f:
content0 = f.readlines()
for i in content0:
content1 = i.split(' ') # 处理文件中的空格
for j in content1:
content2 = j.split('\t') # 处理文件中的缩进
for k in content2:
content3 = k.split('\n') # 处理文件中的换行符
for m in content3:
content4 = re.split(r'([\{,\},\[,\],\(,\),\:,\.,\;,\,])', m) # 使用正则表达式处理文件中的界符
content.extend(content4)
# 处理文件分割后的空字符串
content5 = [x.strip() for x in content if x.strip() != '']
# 关闭文件
f.close()
return content5
3. 对预处理过后的文件进行扫描
直接看代码
def main():
# 定义存储标识符的列表
identifier_list = []
# 预处理文件
preprocess_file = preprocess('test.txt')
# 开始扫描预处理过后的文件
for i in preprocess_file:
if i in tables.keys(): # 扫描到关键字,运算符,分界符
print('< {} {} >'.format(tables[i], i))
elif i.isdigit(): # 扫描到数字
a = bin(int(i)) # 转换字符串到整型
print('< {} {}>'.format(tables['digital'], a)) # 转换成二进制
else:
if i not in identifier_list:
# 扫描的标识符没有存储
identifier_list.append(i)
index = identifier_list.index(i)
print('< {} identifier_list[{}] >'.format(tables['identify'], index))
else:
# 扫描的标识符已经存储
index = identifier_list.index(i)
print('< {} identifier_list[{}] >'.format(tables['identify'], index))
4. 测试代码和测试结果
// 测试代码
public class Sum{
public static void main(String[] args) {
int x = 1,y = 2;
sum = x + y;
System.out.println(sum);
}
}
测试结果:
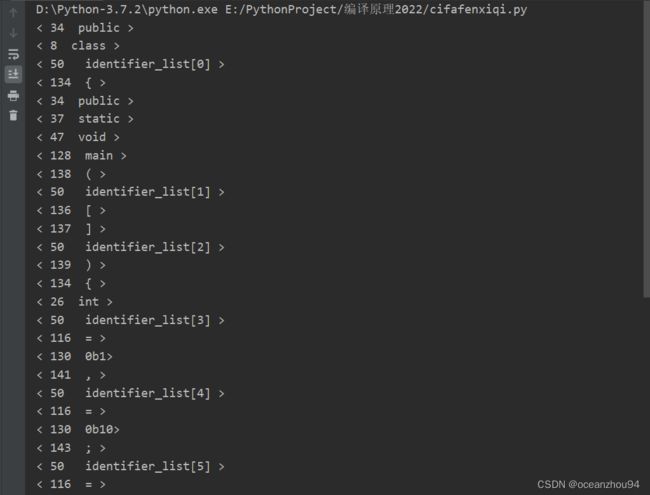
5. 完整代码
"""词法分析器:用python实现java的词法分析器"""
import re
# 基本符号表
tables = {
# 关键字
'abstract': 0, 'assert': 1, 'boolean': 2, 'break': 3, 'byte': 4, 'case': 5, 'catch': 6, 'char': 7, 'class': 8,
'const': 9, 'continue': 10, 'default': 11, 'do': 12, 'double': 13, 'else': 14, 'enum': 15, 'extends': 16,
'final': 17, 'finally': 18, 'float': 19, 'for': 20, 'goto': 21, 'if': 22, 'implements': 23, 'import': 24,
'instanceof': 25, 'int': 26, 'interface': 27, 'long': 28, 'native': 29, 'new': 30, 'package': 31,
'private': 32, 'protected': 33, 'public': 34, 'return': 35, 'short': 36, 'static': 37, 'strictfp': 38,
'super': 39, 'switch': 40, 'synchronized': 41, 'this': 42, 'throw': 43, 'throws': 44, 'transient': 45,
'try': 46, 'void': 47, 'volatile': 48, 'while': 49, 'identify': 50,
# 操作符
'+': 89, '-': 90, '*': 91, '/': 92, '%': 93, '++': 94,
'--': 95, '+=': 117, '-=': 118, '/=': 120, '==': 100, '!=': 101, '>': 102, '<': 103, '>=': 104, '<=': 105,
'&': 106, '|': 107, '^': 108, '~': 109, '<<': 110, '>>': 111, '>>>': 112, '&&': 113, '||': 114,
'!': 115, '=': 116, '*=': 119, '%=': 121, '<<=': 122, '>>=': 123, '&=': 124, '^=': 125, '|=': 126, '?:': 127,
# 其他
'main': 128, 'digital': 130,
# 界符
'{': 134, '}': 135, '[': 136, ']': 137, '(': 138, ')': 139, '.': 140, ',': 141, ':': 142, ';': 143}
# 预处理
def preprocess(in_file):
content = []
# 打开文件开始预处理
with open(in_file, 'r', encoding='utf-8') as f:
content0 = f.readlines()
for i in content0:
content1 = i.split(' ') # 处理文件中的空格
for j in content1:
content2 = j.split('\t') # 处理文件中的缩进
for k in content2:
content3 = k.split('\n') # 处理文件中的换行符
for m in content3:
content4 = re.split(r'([\{,\},\[,\],\(,\),\:,\.,\;,\,])', m) # 使用正则表达式处理文件中的界符
content.extend(content4)
# 处理文件分割后的空字符串
content5 = [x.strip() for x in content if x.strip() != '']
# 关闭文件
f.close()
return content5
def main():
# 定义存储标识符的列表
identifier_list = []
# 预处理文件
preprocess_file = preprocess('test.txt')
# 开始扫描预处理过后的文件
for i in preprocess_file:
if i in tables.keys(): # 扫描到关键字,运算符,分界符
print('< {} {} >'.format(tables[i], i))
elif i.isdigit(): # 扫描到数字
a = bin(int(i)) # 转换字符串到整型
print('< {} {}>'.format(tables['digital'], a)) # 转换成二进制
else:
if i not in identifier_list:
# 扫描的标识符没有存储
identifier_list.append(i)
index = identifier_list.index(i)
print('< {} identifier_list[{}] >'.format(tables['identify'], index))
else:
# 扫描的标识符已经存储
index = identifier_list.index(i)
print('< {} identifier_list[{}] >'.format(tables['identify'], index))
if __name__ == '__main__':
main()