openstack-nova
一、Nova介绍
Nova是Openstack最核心的服务,负责维护和管理云环境的计算资源。OpenStack作为Iaas的云操作系统,虚拟机生命周期管理就是通过Nova来实现的。
用途与功能:
- 实例生命周期管理:虚拟机从创建的动作开始,直到被删除,真个过程都是Nova负责调度的。
- 管理计算资源: cpu、内存等。
- 网络和认证管理
- REST风格的API
- 异步的一致性通信
- Hypervisor透明: 支持Xen、XenServer/XCP, kvm等
架构:

Nova的架构比较复杂,包含很多组件。这些组件以子服务(后台deamon进程)的形式运行,可以分为以下几类:
nova-api
是整个Nova组件的门户,接收和响应客户的API调用。所有对Nova的请求都首先由nova-api处理。nova-api向外界暴露若干HTTP REST API接口。在keyston e中我们可以查询nova-api的endpoints。
客户端就可以将请求发送到endpoints指定的地址,向nova-api请求操作。当然,作为最终用户的我们不会直接发送Rest API请求。Openstack CLI,Dashboard和其他需要跟Nova交换的组件会使用这些API。
Nova-api对接收到的HTTP API请求会做如下处理:
- 检查客户端传入的参数是否合法有效。
- 格式化Nova其他子服务返回的结果并返回给客户端。
Nova-api 接收哪些请求?
简单的说,只要是跟虚拟机生命周期相关的操作,nova-api都可以响应。大部分操作都可以在Dashboard上找到。打开Instance管理界面能看到,先登陆到openstack的管理后台,点击“实例”,能看到当前管理的kvm实例,在动作下拉列表能看到一组操作,这些操作都能通过调用nova-api来实现。

Nova-scheduler
虚机调度服务,负责决定在哪个计算节点上运行虚机。创建Instance时,用户会提出资源需求,例如CPU、内存、磁盘各需要多少。OpenStack将这些需求定义在flavor中,用户只需要指定用哪个flavor就可以了。
openstack是一个大的集群架构, 它下面管理很多kvm虚拟化节点,这些节点叫做“计算节点”。
我们在openstack后台可以配置实例类型(flavor),也就是一个什么样的配置是一条记录,也就是要配置一组“实例的模板”,当用户需要一个具体配置的虚机时,可以从这个实例类型列表中匹配。

下面介绍nova-scheduler是如何实现调度的。在/etc/nova/nova.conf中,nova通过driver=filter_scheduler这个参数来配置nova-scheduler。
driver=filter_schedulerFilter scheduler
Filter scheduler是nova-scheduler默认的调度器,调度过程分为两步:
- 通过过滤器(filter)选择满足条件的计算节点(运行nova-computer)
- 通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建Instance。
nova允许使用第三方scheduler,配置scheduler_driver即可。这又一次体现了Openstack的开放性。Scheduler可以使用多个filter依次进行过滤,过滤之后的节点再通过计算权重选出最合适的节点。

集群中有6个计算节点,根据用户选择的实例模板配置,筛选支持的计算节点,比如筛选出了4个。怎么获取最优的那一个节点呢?获取资源剩余做多的计算节点,用于启动虚拟机。
当Filter scheduler需要执行调度操作时,会让filter对计算节点进行判断,filter返回True或False。经过前面一堆filter的过滤,nova-scheduler选出了能够部署instance的计算节点。
如果有多个计算节点通过了过滤,那么最终选择哪个节点呢?
Scheduler会对每个计算节点打分,得分最高的获胜。打分的过程就是weight,翻译过来就是计算权重值,那么scheduler是根据什么来计算权重值呢?
目前nova-scheduler的默认实现是根据计算节点空闲的内存量计算权重值:空闲内存越多,权重越大,instance将被部署到当前空闲内存最多的计算节点上。
Nova-compute
nova-compute是管理虚拟机的核心服务,在计算节点上运行。通过调用Hypervisor API实现节点上的instance的生命周期管理。OpenStack对instance的操作,最后都是交给nova-compute来实现的。nova-compute与Hypervisor一起实现Openstack对instance生命周期的管理。
通过Driver架构支持多种Hypervisor。Hypervisor是计算节点上跑的虚拟化管理程序,虚机管理最底层的程序。不同虚拟化技术提供自己的Hypervisor。常用的Hypervisor有KVM, Xen,VMWare等。nova-compute为这些Hypervisor定义了统一的接口,Hypervisor只需要实现这些接口,就可以Driver的形式即插即用到OpenStack系统中。下面是Nova Driver的架构示意图。


上图中的yunwei4机器是一个计算节点,上面部署了nova-compute服务,kvm虚拟机。我们可以创建虚拟机,但是我们不是通过在上面直接执行kvm的命令,而是通过nova-computer。它会调用kvm提供的api去管理instance。
nova-conductor
nova-compute经常需要更新数据库,比如更新和获取虚机的状态。出于安全性和伸缩性的考虑,nova-compute并不会直接访问数据库,而是讲这个任务委托给nova-conductor。
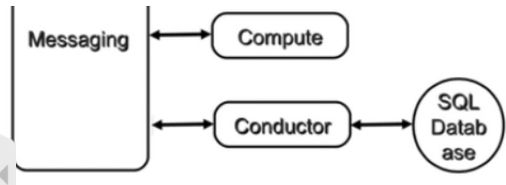
nova-console: 用户可以通过多种方式访问虚机的控制台;
nova-novncproxy: 基于Web浏览器的VNC访问;
nova-spicehtml5proxy: 基于HTML5浏览器的SPICE访问;
nova-xvncproxy:基于java客户端的VNC访问;
nova-consoleauth: 负责对访问虚机控制请求提供Token认证;
nova-cert: 提供x509证书支持;
Database
Nova会有一些数据需要存放到数据库中,一般使用Mysql。数据库安装在控制节点上。Nova使用命令为“nova”的数据库。
Message Queue
在前面我们了解到Nova包含众多的子服务,这些子服务之间需要相互协调和通信。为解耦各个子服务,Nova通过Message Queue作为子服务的信息中转站。所以在架构图上我们看到了子服务之间没有直接的连线,是通过Message Queue联系的。
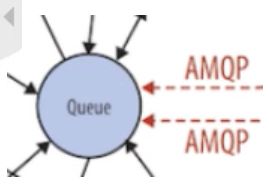
OpenStack默认是用RabbitMQ作为Message Queue。MQ是OpenStack的核心基础组件,我们后面也会详细介绍。
二、Nova组件如何协同工作

- 客户(可以是OpenStack最终客户,也可以是其他程序)向API(nova-api)发送请求:“帮我创建一个虚机”。
- API对请求做一些必要处理后,向Messaging(RabbitMQ)发送了一条消息:“让Scheduler创建一个虚机”。
- Schedule(nova-schedule)从Messaging获取到API发给它的消息,然后执行调度算法,从若干计算节点中选出节点A。
- Schedule向Messaging发送了一条消息: "在计算节点A上创建这个虚机"。
- 计算节点A的Compute(nova-compute)从Messaging中获取到Scheduler发给它的消息,然后在本节点的Hypervisor上启动虚机。
- 在虚机创建的过程中,Compute如果需要查询或更新数据库信息,会通过Messaging向Conductor(nova-conductor)发送消息,Conductor负责数据库访问。
以上是创建虚机最核心的步骤,这几个步骤向我们展示了nova~* 子服务之间的协作的方式,也体现了OpenStack整个系统的分布式设计思想,掌握了这种思想对我们深入理解Openstack会非常有帮助。
三、nova安装配置
创建mysql数据库,一共三个, nova-api、nova、nova-cell0.
创建三个mysql用户并分配权限,能访问上面三个库。
openstack创建一个用户叫nova。给nova用户添加service项目中的角色admin
创建一个nova服务。

创建nova服务端点endpoint,端口8778,要三个,分别是public、internal、admin

openstack创建一个用户叫placement。给用户添加service项目中的角色admin 。
创建服务叫placement。
给placement服务创建服务端点,端口8778,要三个,分别是public、internal、admin
当nova和placement配置好了以后,可以安装nova了。

修改配置文件 /etc/nova ,具体看官方文档说明。
启动nova相关的五个服务。
我们分为控制节点和计算节点。一个节点可以即是控制节点又是计算节点,公用nov.conf。
计算节点要配置vnc控制台地址,要确保机器上有kvm等虚拟化。