基于机器学习算法对电动汽车续驶里程进行估计
1.概论
本文主要通过采集大量的数据,通过对数据进行处理分析,发现SOC和总电压是影响续驶里程的主要原因。从线性关系出发,建立了SOC、总电压和续驶里程的多元线性回归。为了提高模型的准确性,将线性模型中计算得到的残差作为一个新的特征,KNN回归预测模型具有更高的精度,弥补了多元线性回归模型的不足。
2.多元线性模型
2.1模型介绍
在回归模型y=a+bx+c 中,假定c的期望值为0,方差相等且服从正态分布的一个随机变量。但是,若关于c的假定不成立,此时所做的检验以及估计和预测也许站不住脚。确定有关c的假定是否成立的方法之一是进行残差分析(residual analysis)
2.2相关性分析
with open(csv_name) as csvfile:
csv_data = pd.read_csv(csvfile) # header=1默然不读取表头
csv_data.dropna(inplace=True, subset=['SOC', '总电压']) # 删除SOC为缺失值的行
csv_data.reset_index(drop=True, inplace=True)
ls = []
ls_son = []
"""
根据充电状态来进行数据分割,一个放电过程作为一个样本,放入ls列表中
"""
for i in range(csv_data.shape[0]):
if csv_data['充电状态'][i] == 3 and csv_data['累计里程'][i] != None:
if np.isnan(csv_data['累计里程'][i]):
continue
ls_son.append(i)
elif csv_data['充电状态'][i] == 1:
# 数据量大于300加入列表
if len(ls_son) > 300:
ls.append(ls_son)
ls_son = []
mileage_soc_corr_list=[]
u_soc_corr_list=[]
for index in ls:
# 获取每一个样本
data = csv_data.iloc[index, :]
data.reset_index(drop=True, inplace=True)
data['累计里程'] = abs(data['累计里程'] - data['累计里程'].tolist()[-1])
data['SOC'] = abs(data['SOC'] - data['SOC'].tolist()[-1])
mileage_soc_corr_list.append(data['累计里程'].corr(data['SOC']))
u_soc_corr_list.append(data['累计里程'].corr(data['总电压']))
s1 = []
s2 = []
for i in range(len(index)):
s1.append(float(data['SOC'].tolist()[i] - data['SOC'].tolist()[-1]) / 0.75)
s2.append(float(data['SOC'].tolist()[i] - data['SOC'].tolist()[-1]) / 1.75)
data_new={'最大里程':s1,
'最小里程':s2,
'总电压':data['总电压'].tolist(),
'实际里程':data['累计里程'].tolist()}
data_new=pd.DataFrame(data_new)
data_new.to_csv('里程.csv', mode='a', header=False)
plt.subplot(211)
plt.plot(range(len(mileage_soc_corr_list)), mileage_soc_corr_list)
plt.ylabel('correlation')
plt.title('mileage&SoC correlation')
plt.subplot(212)
plt.plot(range(len(u_soc_corr_list)), u_soc_corr_list)
plt.xlabel('sample')
plt.ylabel('correlation')
plt.title('mileage&U correlation')
plt.show()
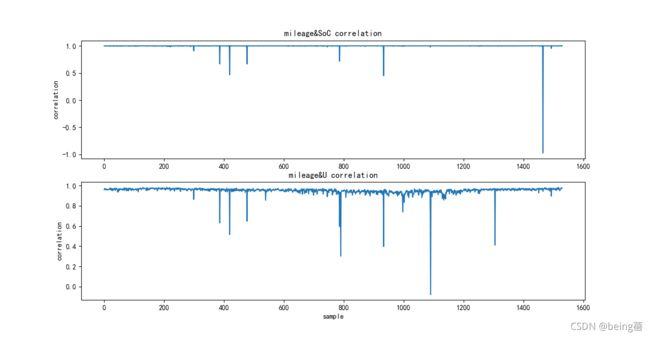
以上为每个样本中SOC和总电压与续驶里程的相关性,可以发现续驶里程和SOC、总电压有很高的相关性。
2.3模型构建
data = pd.read_csv('../data/U_SOC_mileage.csv')
print(data.head())
x = data.iloc[:, 0:2]
y = data.iloc[:, 2:]
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, random_state=6)
# 标准化处理
x_stand = StandardScaler()
x_train = x_stand.fit_transform(x_train)
x_test = x_stand.transform(x_test)
linear = LinearRegression()
linear.fit(x_train, y_train)
y_pre = linear.predict(x_test)
mse = np.sqrt(mean_squared_error(y_test, y_pre))
print("参数:", linear.coef_)
print("截距:", linear.intercept_)
print('均方误差:', mse)
print('测试集评分:', r2_score(y_test, y_pre))
x_index = [i for i in range(x_test.shape[0])]
plt.figure()
plt.title('predict mileage')
plt.plot(x_index[2000:2100], y_test[2000:2100], c='r', label="True value")
plt.plot(x_index[2000:2100], y_pre[2000:2100], c='g', label="Predict value")
plt.xlabel('sample')
plt.ylabel('mileage')
plt.legend(loc="best")
plt.show()
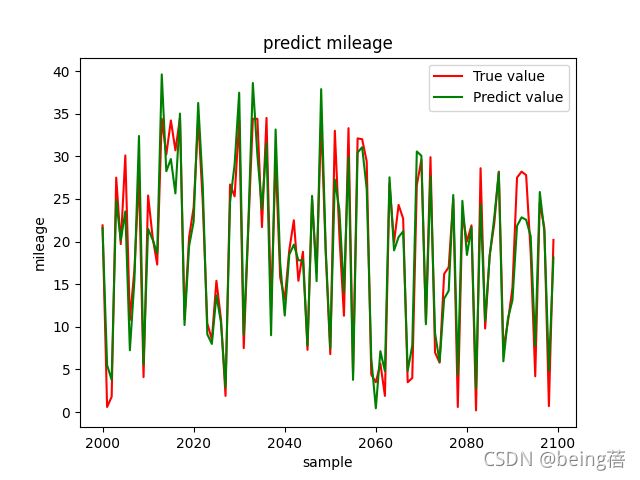
多元线性模型为y=3.99U+6.68SOC+18.6,其中R2为0.912,均方误差为3.102。
2.4残差分析
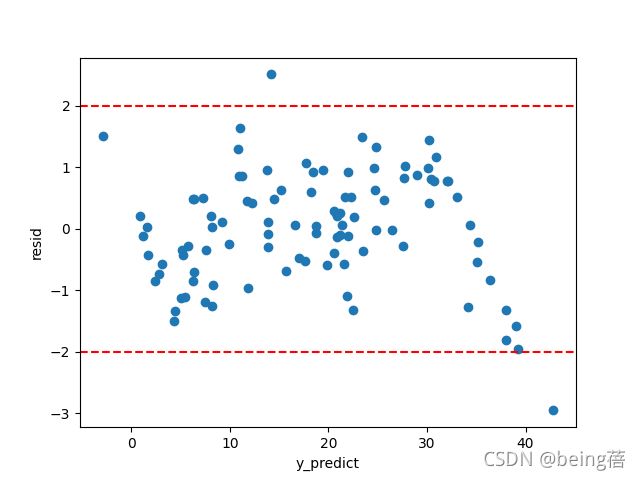
通过标准化残差,对c进行正态性检验。标准化残差(standardized residual)是残差除以其标准差后得到的数值,也称Pearson残差或半学生化残差(semi-studentized residuals)。通过计算,大约有97.5%的标准化残差在-2到2之间,所以c符合正态性这一假设。并且抽取部分数据进行展示。
resids = outliers.resid_studentized_external
ls=[1 if i>=-2 and i<=2 else 0 for i in resids]
print(np.sum(ls)/len(ls))
plt.scatter(y_predict[1000:1100], resids[1000:1100])
plt.xlabel('y_predict')
plt.ylabel('resid')
plt.axhline(y=2, color='r', linestyle='--')
plt.axhline(y=-2, color='r', linestyle='--')
plt.show()
3.KNN回归预测模型
3.1模型介绍
基于最邻近算法的分类,本质上是对离散的数据标签进行预测,实际上,最邻近算法也可以用于对连续的数据标签进行预测,这种方法叫做基于最邻近数据的回归,预测的值(即数据的标签)是连续值,通过计算数据点最临近数据点平均值而获得预测值。
3.2模型构建
data=pd.read_csv('../data/res_mile.csv')
x = data.iloc[:, 0:3]
y = data.iloc[:, 3:]
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, random_state=6)
# 标准化处理
x_stand = StandardScaler()
x_train = x_stand.fit_transform(x_train)
x_test = x_stand.transform(x_test)
kr = KNeighborsRegressor(n_neighbors=12)
kr.fit(x_train, y_train)
y_pre = kr.predict(x_test)
mse = np.sqrt(mean_squared_error(y_test, y_pre))
print('均方误差:', mse)
print('测试集评分:', r2_score(y_test, y_pre))
x_index = [i for i in range(x_test.shape[0])]
plt.figure()
plt.title('predict mileage')
plt.plot(x_index[2300:2400], y_test[2300:2400], c='r', label="True value")
plt.plot(x_index[2300:2400], y_pre[2300:2400], c='g', label="Predict value")
plt.xlabel('sample')
plt.ylabel('mileage')
plt.legend(loc="best")
plt.show()
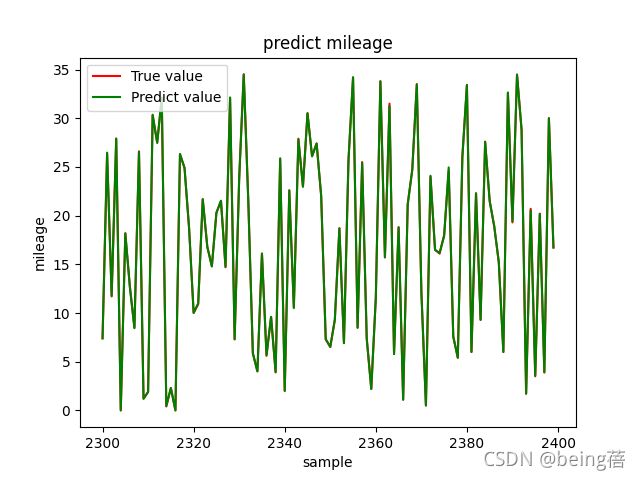
基于多元线性回归模型计算得到的残差,结合SOC和总电压对续驶里程进行预测,最终R2为0.999,均方误差为0.0798。
4.问题
模型应用的时候,残差无法得知,只能知道一个大致的范围。
机器学习主要是在某一个数据集上面建立算法,不断的优化,但不一定适用于其他数据集,有区别于数据挖掘。
数据集中的续驶里程大概在0~70的范围内,对更远距离的预测可能会存在一定的误差。