智慧城市-疫情流调系列3-Prompt-UIE,生成式通用信息抽取
UIE核心思想
统一输入提示结果,统一输出解码结构,即统一了不同任务
参考文章
论文:
https://arxiv.org/pdf/2203.12277.pdf
DuUIE:
PyTorch:https://github.com/universal-ie/UIE
PaddlePaddle:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/information_extraction/DuUIE
https://aistudio.baidu.com/aistudio/competition/detail/161/0/task-definition
知乎
参考:https://zhuanlan.zhihu.com/p/495600185
事件抽取,触发词实体和论元实体的关系,就引申出了关系抽取,实际上论元角色类别就是触发词事件类别的属性。
事件抽取的目标是对于给定的自然语言句子,根据预先指定的事件类型和论元角色,识别句子中所有目标事件类型的事件,并根据相应的论元角色集合抽取事件所对应的论元。其中目标事件类型 (event_type) 和论元角色 (role) 限定了抽取的范围,例如 (event_type:胜负,role:时间,胜者,败者,赛事名称)、(event_type:夺冠,role:夺冠事件,夺冠赛事,冠军)。

触发词抽取,本质是实体抽取,实体的类型范围就是给定的事件类型,事件里面所有设计到的类别
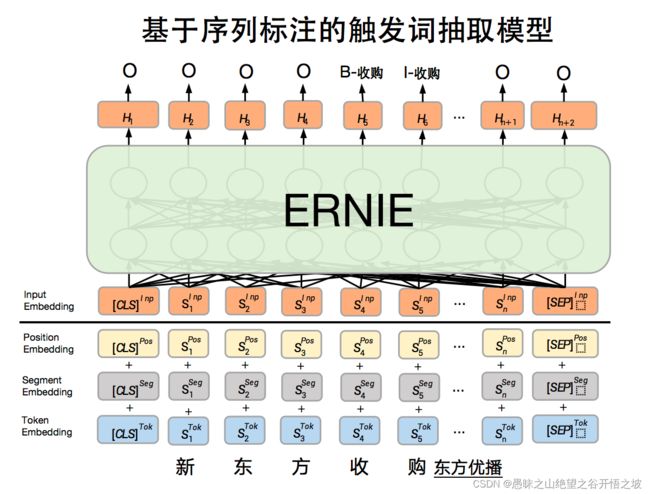
基于序列标注的触发词抽取模型是整体模型的一部分,该部分主要是给定事件类型,识别句子中出现的事件触发词对应的位置以及对应的事件类别,该模型是基于ERNIE开发序列标注模型,模型原理图如下:
论元抽取,本质是实体抽取,实体的类型范围就是给定的论元角色
同样地,基于序列标注的论元抽取模型也是基于ERNIE开发序列标注模型,该部分主要是识别出事件中的论元以及对应论元角色,模型原理图如下:

文本分类,整个事件的类别
同时,对于枚举分类数据采用的是基于ERNIE的文本分类模型,枚举角色类型为环节。模型原理图如下:

观点评论抽取,属性实体和观点实体的正向和负向的关系,引申出来了实体和实体之间的关系抽取
观点评论细粒度抽取,本质上是实体抽取
会抽取评论中的属性以及属性对应的观点,为此我们基于BIO的序列标注体系进行了标签的拓展:B-Aspect, I-Aspect, B-Opinion, I-Opinion, O,其中前两者用于标注评论属性,后两者用于标注相应观点。
拼接后再做细粒度分类
在抽取完评论观点之后,便可以有针对性的对各个属性进行评论。具体来讲,本实践将抽取出的评论属性和评论观点进行拼接,然后和原始语句进行拼接作为一条独立的训练语句。
如图2所示,首先将评论属性和观点词进行拼接为"味道好",然后将"味道好"和原文进行拼接,然后传入SKEP模型,并使用"CLS"位置的向量进行细粒度情感倾向。
uie统一
实体识别任务一般是采用span及其实体类别表示,关系抽取任务一般采用三元组(triplet)结构表示,事件抽取任务一般采用记录(record)表示,观点抽取任务采用三元组(triplet)来表示。
设计了一种结构化抽取语言(Structural Extraction Language, SEL),它能够将四种信息抽取任务的不同结构统一描述,使得模型的输出结构针对不同任务都是一致的。由于模型可以做多个任务,所以需要一种方式去指导模型做指定的任务,因此作者设计了结构化模式指导器(Structural Schema Instructor, SSI),其实这就是一种prompt。由于模型的输出都是符合SEL语法的结构化信息,而目前常用的生成式预训练模型如T5、BART都是以生成自然语言为主,若直接采用这种预训练模型会影响到模型性能,因此作者专门针对text to structure的结构来预训练了一个大模型。
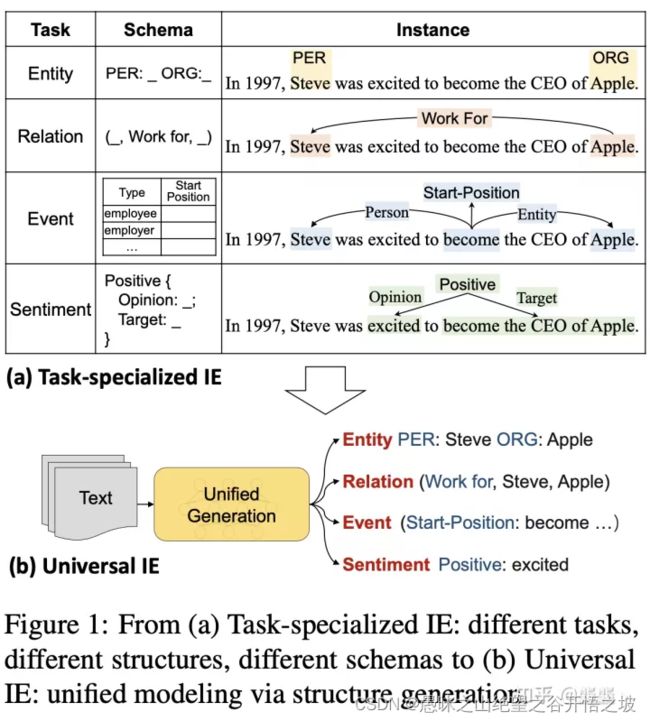
客体的类别无需定义和抽取出来,主体(触发词)的类别,关系的类别,关系映射的课题(论元)即可。

上图给出一个中文case:考察事件 为事件类型Spot Name,主角/时间/地点 为论元类型Asso Name。
事件抽取本质上,也是转换成了关系抽取而已。
实体抽取:[spot] 实体类别 [text]
关系抽取:[spot] 实体类别 [asso] 关系类别 [text]
事件抽取:[spot] 事件类别 [asso] 论元类别 [text]
观点抽取:[spot] 评价维度 [asso] 观点类别 [text]
整体架构就是:SSI + Text -> SEL,理解万事万物之规律,哪些是指定的类别,哪些是原文中就有的
1、设计结构化抽取语言(SEL,Structured Extraction Language)来统一编码异构提取结构,即编码实体、关系、事件统一表示。
2、构建结构化模式提示器(SSI,Structural Schema Instructor),一个基于schema的prompt机制,用于控制不同的生成需求。

如图2(a)所示,作者使用三种形式来表示: (1) Spot Name: 指目标信息片段的类别,在实体抽取中指实体类别,在事件抽取中可以指事件类型和论元类别。(2) Info Span: Spotting操作的输出,即原句子中的目标信息片段。 (3) Asso Name: 指两个信息片段之间的关系类型,也就是Associating操作的输出。
[spot] 实体类别 [asso] 关系类别 [text],这种形式可以告诉模型哪些做spotting操作,哪些做associating操作。第二个灰色部分是事件抽取,SSI格式是: [spot] 事件类别 [asso] 论元类别 [text]。第三个绿色部分是实体识别,SSI格式是: [spot] 实体类别 [text]
预训练
SSI+TEXT>SEL
NONE>SEL
TEXT>TEXT

win10
参考链接:https://pytorch.org/
pip3 install torch torchvision torchaudio
pip install -r requirements.txt