信息收集“小迪安全课堂笔记”绕CDN,架构waf等信息,APP,其他资产
信息收集
- CDN 绕过
-
- 判断是否有CDN
- 目前常见的 CDN 绕过技术有哪些?
- 架构,搭建,WAF 等
-
- CMS 识别技术
- 源码获取技术
- 架构信息获取
- 站点搭建分析
-
- 搭建习惯-目录型站点
- 搭建习惯-端口类站点
- 搭建习惯-子域名站点
- 搭建习惯-类似域名站点
- 搭建习惯-旁站,C 段站点
- 搭建习惯-搭建软件特征站点,搭建习惯
- WAF 防护分析
- APP
-
- APP涉及网站
-
- APE提取一键反编译提取
- APP抓数据包进行工具配合
- App不涉及网站
- 其他资产
-
- 各种第三方应用相关探针技术
- 各种服务接口信息相关探针技术
- 资产监控拓展
-
- Github 监控
- 各种子域名查询
-
- 黑暗引擎相关搜索
- 全自动域名收集枚举脚本使用
-
- teemo
- layer子域名挖掘机
CDN 绕过
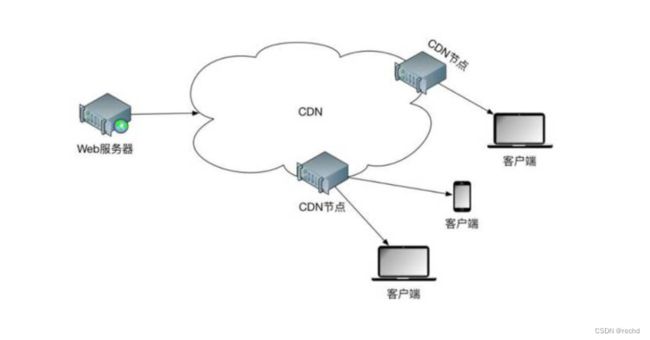
CDN 的全称是 Content Delivery Network,即内容分发网络。CDN 是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。但在安全测试过程中,若目标存在CDN 服务,将会影响到后续的安全测试过程。
判断是否有CDN
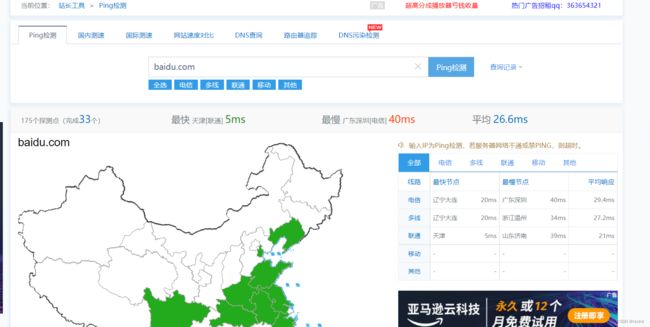
1、超级ping --https://ping.chinaz.com
2、nslookup,是否会有很多节点
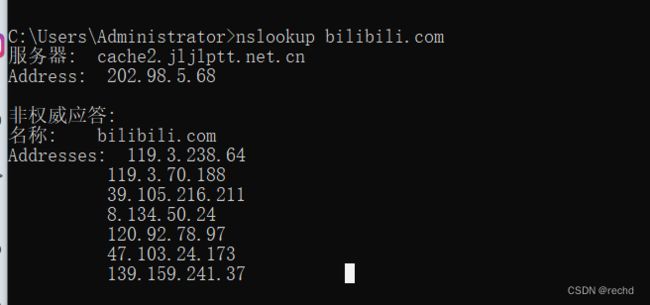
目前常见的 CDN 绕过技术有哪些?
1、子域名查询,可能出现三种情况:与主域名在 同一台服务器 |同网段不同服务器 |不同网段,
子域名技巧:由于系统管理员设置不当,可能存在二级域名三级域名ping结果不一致,可能存在www.12345.com设置了cdn,12345.com没设置cdn。手机访问域名与pc访问不一致,手机域名可能没有CDN。
2、邮件服务查询,一般不会做CDN,也存在正向逆向访问问题,反向是真实IP。可配合修改hosts文件,测试获取地址是否为真实地址。只有cdn地址和真实地址才能打开。再通过其他社会工程信息大概率可确认。
3、国外地址请求,国外一般不设CDN。789代理。https://tools.ipip.net/cdn.php在线查询cdn
4、遗留文件
5、黑暗引擎搜索特定文件,shodan,zoomeye搜索指定hash文件。脚本获取hash 。
#Python2 开发别搞错了执行环境
#安装 mmh3 失败记得先安装下这个#Microsoft Visual C++ 14.0
#https://pan.baidu.com/s/12TcFkZ6KFLhofCT-osJOSg 提取码:
import mmh3
import requests
response = requests.get(‘http://www.xx.com/favicon.ico’)
favicon = response.content.encode(‘base64’)
hash = mmh3.hash(favicon)
print ‘http.favicon.hash:’+str(hash)
6、dns 历史记录=三方接口,寻找网站之前未作CDN的网站解析地址。微步在线历史解析记录,get-site-ip.com。
7、以量打量,CDN存在流量限制,流量占满后直接访问真实IP,DDOS。
8、扫描全网,全网资源访问网站,所有地区可能性筛选,最终找到真实IP地址。fuckcdn,w8 fuckcdn,zmap等。
架构,搭建,WAF 等
CMS 识别技术
https://blog.csdn.net/weixin_42902126/article/details/124501454
源码获取技术
https://blog.csdn.net/weixin_42902126/article/details/124501454
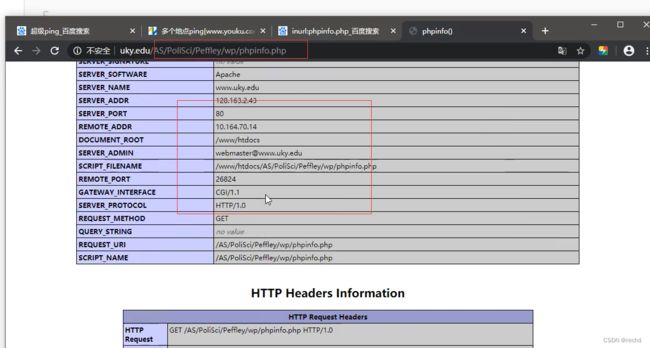
架构信息获取
https://blog.csdn.net/weixin_42902126/article/details/124501454
站点搭建分析
搭建习惯-目录型站点
网站①
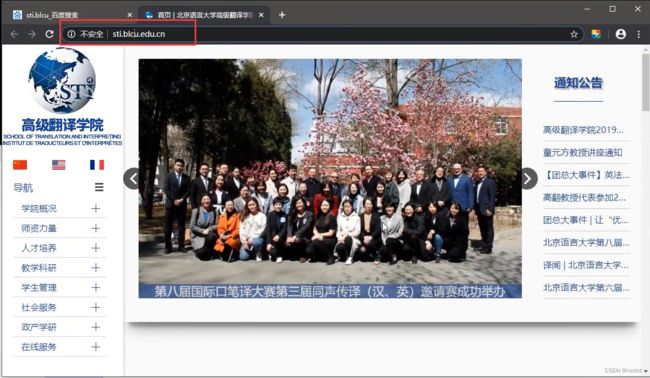
网站②,由Discuz搭建
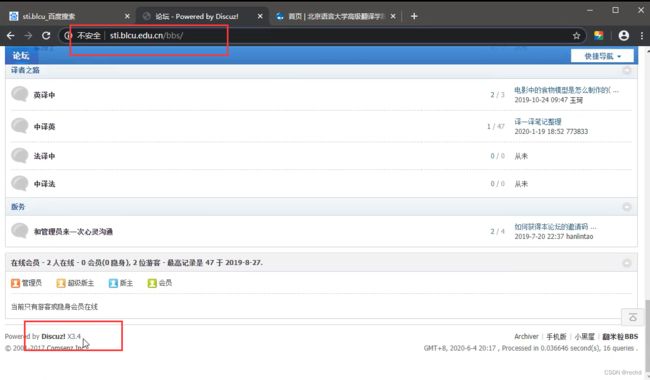
不用网站搭建在同一服务器上,不同目录下。这样就提供了两种方案进行攻击,其中一个网站沦陷另一个也会受影响。
如何发现网站存在这种漏洞?
1、工具目录遍历。
2、手动点击尝试。
搭建习惯-端口类站点
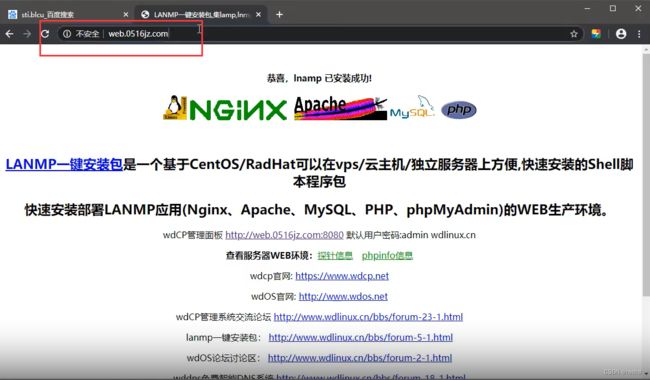
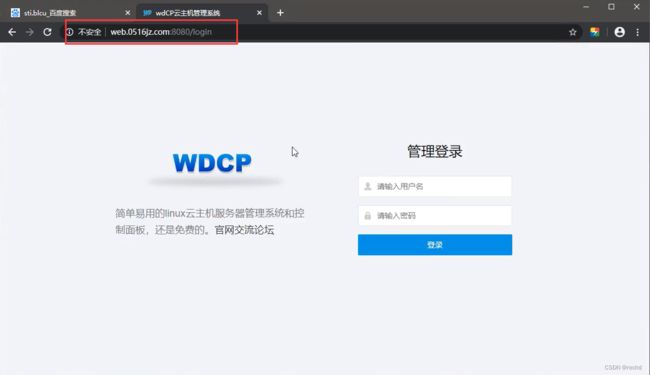
==不同端口对应不同网站,也在同一服务器上,一个网站沦陷另一个也受影响 ==
搭建习惯-子域名站点
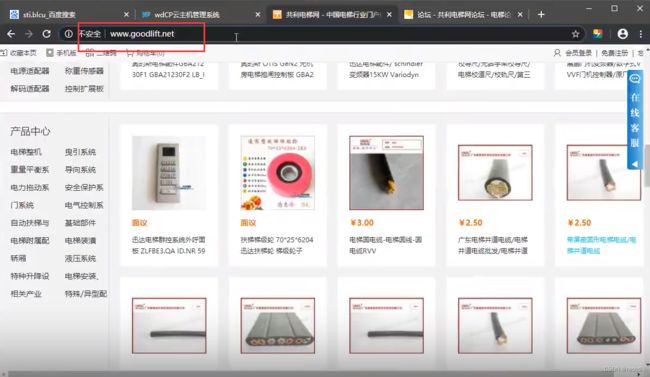
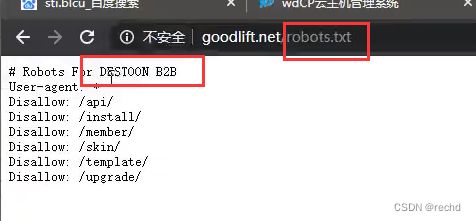

两站在同一个服务器或不同服务器,可使用ping测试。若不是同一服务器,大概率可能在同一网段
搭建习惯-类似域名站点
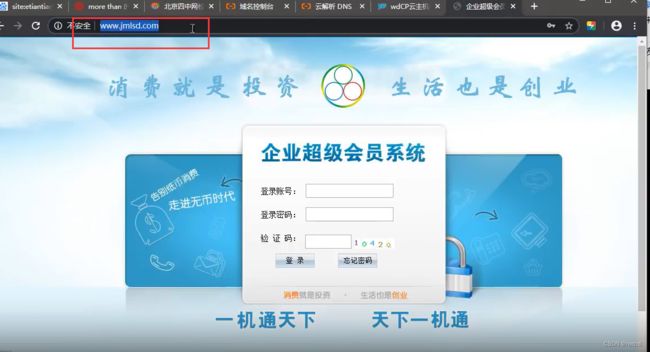
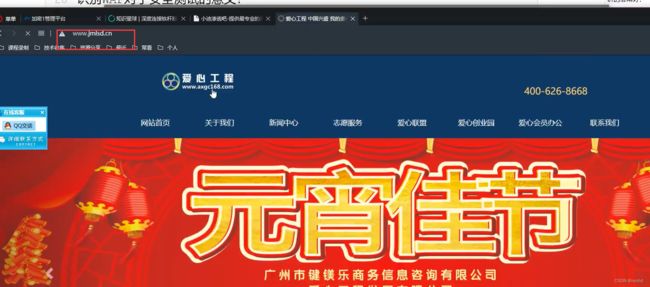

不同域名对应同一个网站,也可采用两种方案。不同域名可能存在不同功能,获取不同信息,提供两种思路。
如何判断?
编写脚本爆破
例:jsmld.com,jsmld.***
或jsmld***.com “*号”为字典
搭建习惯-旁站,C 段站点
旁站:同服务器不同站点。——旁注在线查询工具webscan
C 段站点:同网段不同服务器不同站点。——提权,内网等
搭建习惯-搭建软件特征站点,搭建习惯
搭建软件可能存在安全问题。例如phpstudy老版本,存在默认phpmyadmin弱口令,若没修改可利用。
如何识别搭建软件?
此站禁用浏览器抓包,采用burp抓包
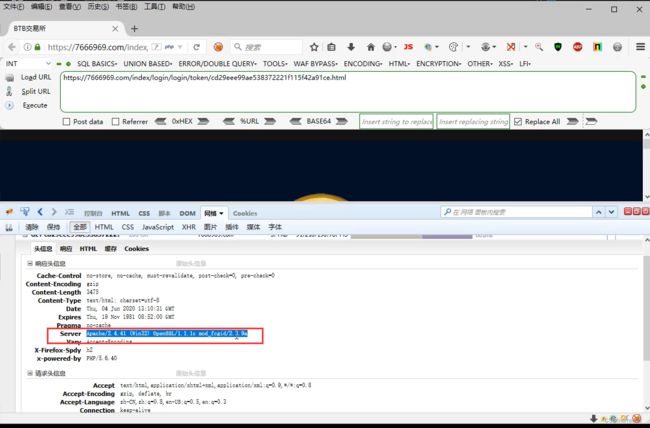
可以通过Server信息判断,一般手动搭建的网站信息显示不全。此例为宝塔搭建。
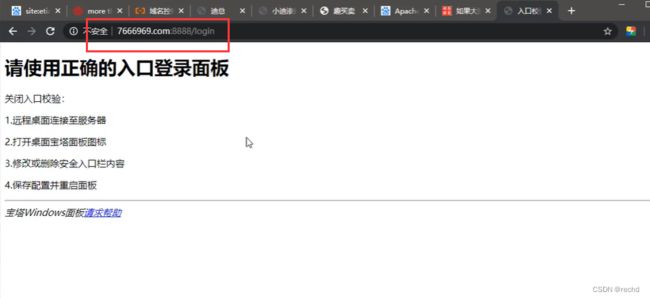
可以通过百度搜索server信息判断搭建软件
WAF 防护分析
什么是 WAF 应用?
– Web应用防护系统(也称为:网站应用级入侵防御系统。英文:Web Application Firewall,简
称: WAF)。
如何快速识别 WAF?
https://github.com/EnableSecurity/wafw00f 识别工具,并非100%识别。
在网站返回的数据包中也有可能存在waf信息。
APP
在安全测试中,若 WEB 无法取得进展或无 WEB 的情况下,我们需要借助 APP 或其他资产在进行信息收集,从而开展后续渗透,那么其中的信息收集就尤为重要。
APP涉及网站
在通过 以下两种方式 获取url后,直接采取web形式进行接下来的测试。
APE提取一键反编译提取
使用反编译工具,尝试获取包了里的源码
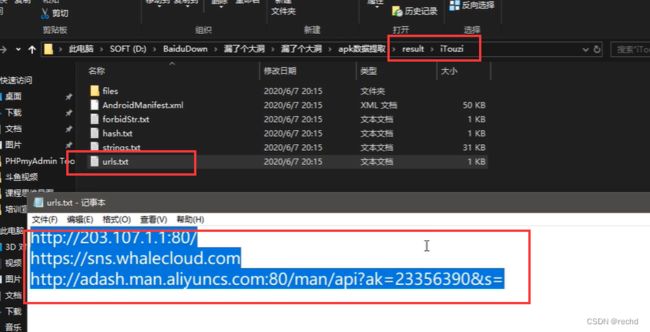
APP抓数据包进行工具配合
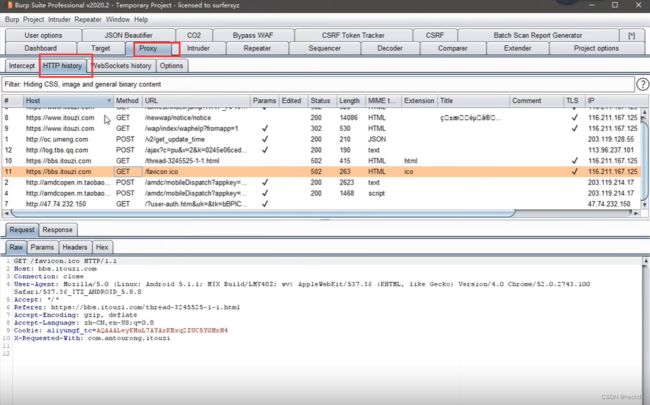
使用burp suite设置代理,或者wireshark抓数据包,进行分析。
配置代理后,打开APP点击选项,抓取数据包
通过这种方式可获取更多的地址,提供更多选择性
App不涉及网站
采取反编译逆向等方式。
其他资产
各种第三方应用相关探针技术
黑暗引擎:shodan,zoomeye搜索域名或者IP
各种服务接口信息相关探针技术
端口扫描工具nmap
资产监控拓展
Github 监控
便于收集整理最新 exp 或 poc
便于发现相关测试目标的资产
在网络上查找源码无果,github可能会源码。
监控实例 利用微信推送CVE-2020 4.0。
代码地址:https://github.com/weixiao9188/wechat_push/blob/master/wechat_push.py
微信推送:https://sct.ftqq.com/
# Title: wechat push CVE-2020
# Date: 2020-5-9
# Exploit Author: weixiao9188
# Version: 4.0
# Tested on: Linux,windows
# coding:UTF-8
import requests
import json
import time
import os
import pandas as pd
time_sleep = 20 #每隔20秒爬取一次
while(True):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}
#判断文件是否存在
datas = []
response1=None
response2=None
if os.path.exists("olddata.csv"):
#如果文件存在则每次爬取10个
df = pd.read_csv("olddata.csv", header=None)
datas = df.where(df.notnull(),None).values.tolist()#将提取出来的数据中的nan转化为None
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&per_page=10",
headers=headers)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10",
headers=headers)
else:
#不存在爬取全部
datas = []
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&order=desc",headers=headers)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&order=desc",headers=headers)
data1 = json.loads(response1.text)
data2 = json.loads(response2.text)
for j in [data1["items"],data2["items"]]:
for i in j:
s = {"name":i['name'],"html":i['html_url'],"description":i['description']}
s1 =[i['name'],i['html_url'],i['description']]
if s1 not in datas:
#print(s1)
#print(datas)
params = {
"text":s["name"],
"desp":" 链接:"+str(s["html"])+"\n简介"+str(s["description"])
}
print("当前推送为"+str(s)+"\n")
print(params)
requests.get("https://sc.ftqq.com/XXXX.send",params=params,timeout=10)#设置sendkey
#time.sleep(1)#以防推送太猛
print("推送完成!")
datas.append(s1)
else:
pass
#print("数据已处在!")
pd.DataFrame(datas).to_csv("olddata.csv",header=None,index=None)
time.sleep(time_sleep)
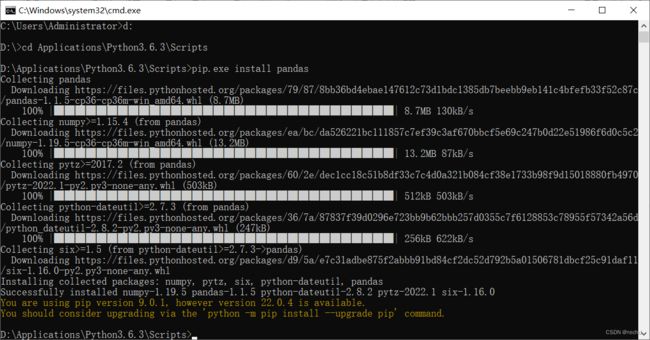
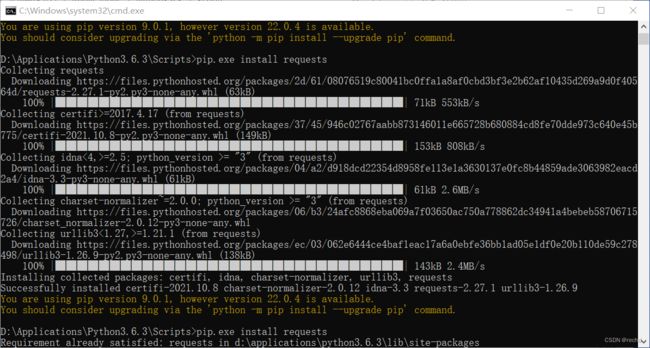
初次使用需要安装requests,pandas库。
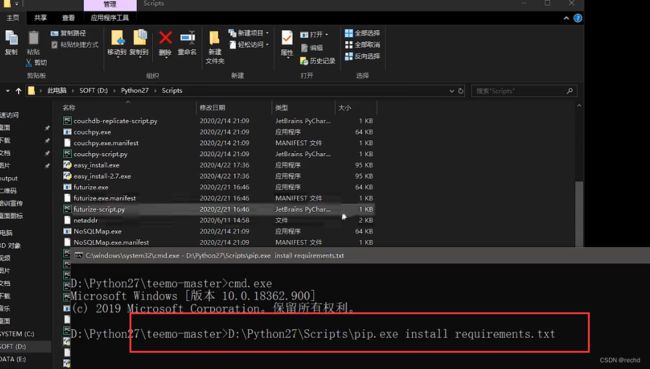
找到python路径下的pip.exe
cmd安装
各种子域名查询

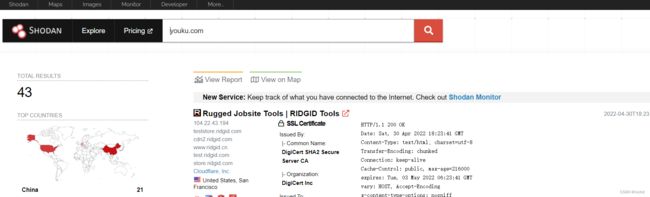
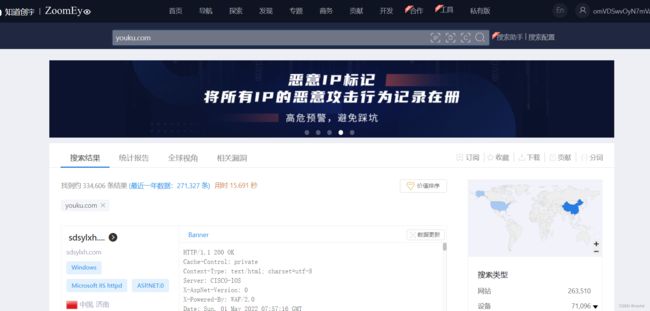
黑暗引擎相关搜索
– shodan, zoomeye搜索目标,筛选相关信息。
全自动域名收集枚举脚本使用
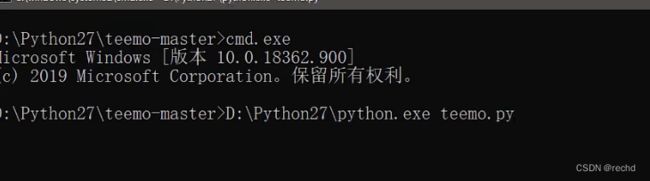
teemo
https://github.com/bit4woo/teemo
该工具主要有三大模块:利用搜索引擎,利用第三方站点,利用枚举
其中部分接口需要API Key,如果有相应账号,可以在config.py中进行配置,没有也不影响程序的使用,但是信息会缩水。
安装
执行